🌳 랜덤 포레스트 (Random Forest) 란?
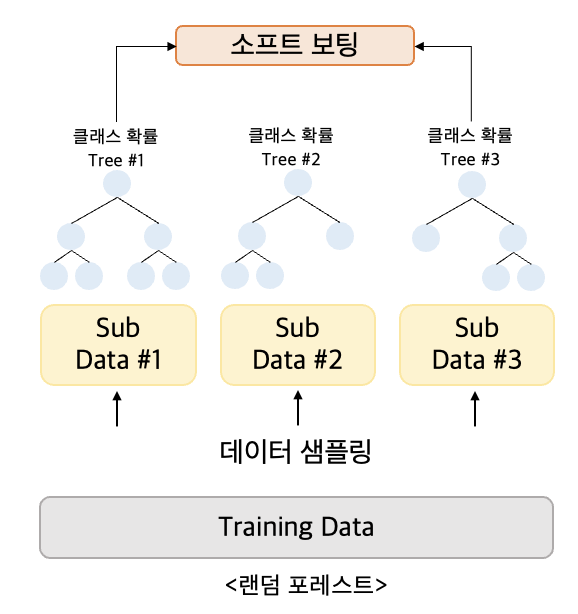
랜덤 포레스트는, 배깅의 대표적인 알고리즘이다.
✔️ 앙상블 알고리즘 중 비교적 빠른 수행 속도를 가지고 있으며, 다양한 영역에서 높은 예측 성능을 보이고 있다.
✔️ 랜덤 포레스트의 기반 알고리즘은 결정 트리로 결정 트리의 쉽고 직관적인 장점을 그대로 가지고 있다.
→ 그라디언트 부스팅보다 성능은 약간 떨어지더라도 병렬처리 학습으로 시간이 오래걸리지는 않아 랜덤 포레스트를 기반으로 구축하는 경우가 많음
여러 개의 결정 트리 분류기가 전체 데이터에서 배깅 방식으로 각자의 데이터를 샘플링해 개별적으로 학습을 수행한 후 최종적으로 모든 분류기가 보팅을 통해 예측 결정을 진행
- 개별 트리가 학습하는 데이터셋은 전체 데이터에서 일부가 중첩되게 샘플링된 데이터
- 이렇게 여러 개의 데이터 셋을 중첩도게 분리하는 것을 부트 스트래핑 (bootstrapping) 분할 방식이라 함
🧚🏻 랜덤 포레스트의 장점
Classification(분류) 및 Regression(회귀) 문제에 모두 사용 가능
Missing value(결측치) 를 다루기 쉬움
대용량 데이터 처리에 효과적
모델의 노이즈를 심화시키는 Overfitting(오버 피팅) 문제를 회피하여, 모델 정확도를 향상시킴
Classification 모델에서 상대적으로 중요한 변수를 선정 및 Ranking 가능
😶🌫️ RandomForest 실습
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
X_train, X_test, y_train,y_test = get_human_dataset()
rf_clf = RandomForestClassifier(random_state=0)
rf_clf.fit(X_train,y_train)
pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test,pred)
print('랜덤 포레스트 정확도: {0:.4f}'.format(accuracy))→ 0.9108
🍃 랜덤 포레스트 하이퍼 파라미터
트리 기반의 앙상블 알고리즘의 단점은 , 하이퍼 파라미터가 너무 많고, 그로 인해서 튜닝을 위한 시간이 많이 소모된다는 것 또한 많은 시간을 소모했음에도 불구하고 튜닝 후 예측 성능이 크게 향상되는 경우가 많지 않음
랜덤 포레스트는 결정 트리에서 사용되는 하이퍼 파라미터와 같은 파라미터가 대부분임 !
- n_estimators : 랜덤 포레스트에서 결정트리의 개수를 지정, 디폴트는 10
- max_features : 결정 트리에 사용된 max_features 파라미터와 같음 , 디폴트는 ‘auto’ ( = sqrt)
- max_depth나 min_samples_leaf와 같이 결정 트리에서 과적합을 개선하기 위해 사용되는 파라미터가 랜덤 포레스트에서도 똑같이 적용될 수 있음 !
🧚🏻 GridSearchCV 를 이용한 하이퍼 파라미터 튜닝
GridSearchCV 란?
사이킷 런에서 분류나 회귀 알고리즘에 사용되는 하이퍼 파라미터를 순차적으로 입력해 학습을 하고 측정을 하며 가장 좋은 파라미터를 알려준다 ! 최적화된 파라미터를 뽑아낼 수 있다 .
[GridSearchCV 생성자 정리]
- estimator : classifier, regressor, pipline 등 가능
- param_grid : 튜닝을 위해 파라미터, 사용될 파라미터를 dictionary 형태로 만들어 넣는다
- scoring : 예측 성능을 측정할 평가 방법을 넣는다. 보통은 accuracy로 지정
- cv : 교차 검증에서 몇 개로 분할되는지 지정
- refit : True 가 디폴트, 최적의 하이퍼 파라미터를 찾아서 재학습
😶🌫️ GridSearchCV 실습
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100],
'max_depth':[6, 8, 10, 12],
'min_samples_leaf':[8, 12, 18 ],
'min_samples_split':[8, 16, 20 ]
}
rf_clf = RandomForestClassifier(random_state = 0, n_jobs = -1)
grid_cv = GridSearchCV(rf_clf, param_girid = parms, cv = 2, n_jobs = -1)
grid_cv.fit(X_train,y_train)
print('최적의 하이퍼 파라미터:\n',grid_cv.best_params_)
print('최고 예측 정확도:{0:.4f}'.format(grid_cv.best_score_))→ 최적의 하이퍼 파라미터 : { ‘max_depth’: 10 ,’min_samples_leaf’:8, ‘min_samples_split’:8, ‘n_estimators’:100 }
최고 예측 정확도 : 0.9168
🙇 참조/레퍼런스
파이썬 머신러닝 완벽 가이드 책을 참조하여 작성하였습니다
