머신러닝
1.파이썬 머신러닝 완벽가이드 -데이터 전처리

데이터 전처리(Data Preprocessing)는 ML 알고리즘 만큼 중요하다어떠한 데이터에 기반하고 있느냐에 따라 결과도 크게 달라지기 때문이다ML 알고리즘을 적용하기 전에 데이터에 대해 미리 처리해야할 사항 1\. 결손값, 즉 Null 값은 허용되지 않음 . 따
2.분류 - (1) 결정트리 (Decision Tree)
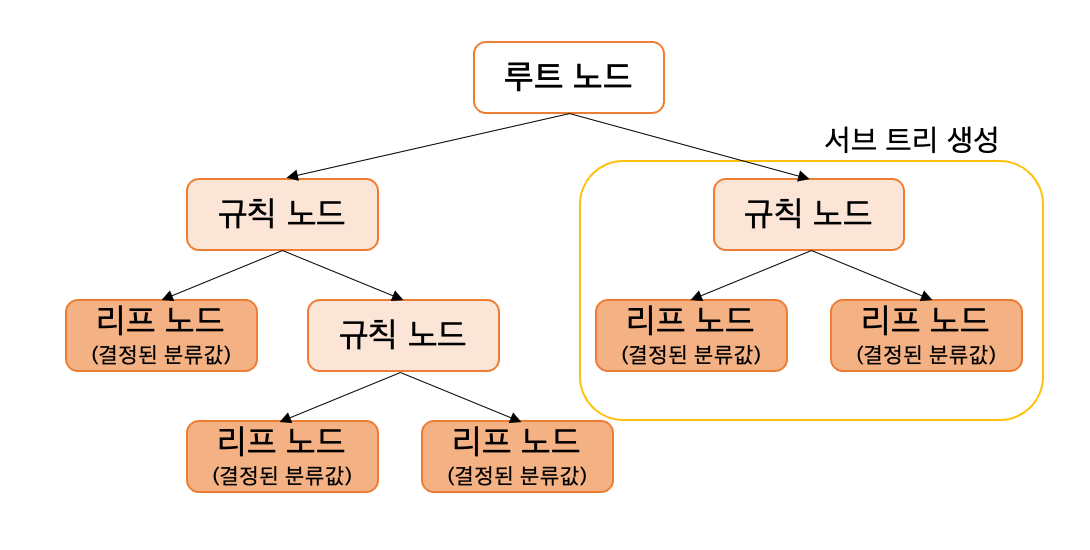
지도학습의 대표적인 유형인 분류(Classification) 은 학습 데이터로 주어진 데이터의 피처와 레이블 값을 머신러닝 알고리즘으로 학습해 모델을 생성하고, 이렇게 생성된 모델에 새로운 데이터 값이 주어졌을 때 미지의 레이블 값을 예측 하는 것베이즈(Bayes) 통
3.분류 -(2) 앙상블 학습: 보팅(Voting)

앙상블 학습 분류는 여러개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출해내는 기법 → 다양한 분류기의 예측 결과를 분석함으로써 단일 분류기보다 신뢰성을 높이는 것이 목적앙상블 학습 유형은 전통적으로 보팅(Voting),
4.[머신러닝] 랜덤 포레스트 (Random Forest)
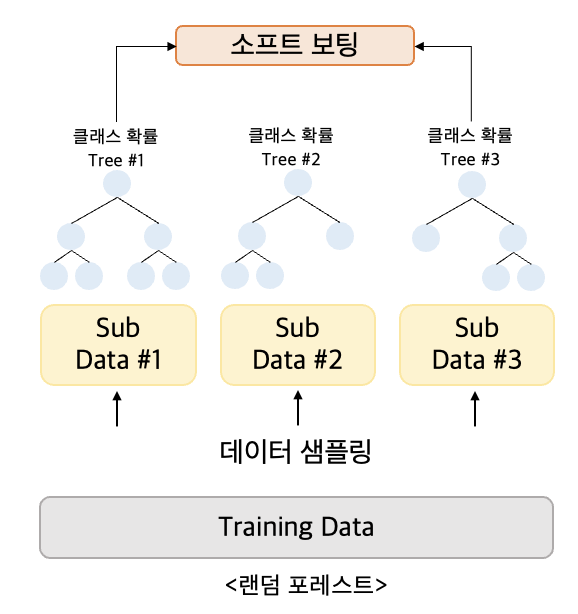
랜던 포레스트는, 배깅의 대표적인 알고리즘이다.✔️ 앙상블 알고리즘 중 비교적 빠른 수행 속도를 가지고 있으며, 다양한 영역에서 높은 예측 성능을 보이고 있다.✔️ 랜덤 포레스트의 기반 알고리즘은 결정 트리로 결정 트리의 쉽고 직관적인 장점을 그대로 가지고 있다. →
5.[머신러닝] GBM (Gradient Boosting Machine) - 그라디언트 부스팅
부스팅 알고리즘은 여러 개의 약한 학습기를 순차적으로 학습 - 예측하며 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식이다.앞장에 배깅 알고리즘의 대표적인 모델로는 랜덤포레스트가 존재하고 부스팅 알고리즘의 대표적인 모델로 그라디언트 부스팅
6.[머신러닝] 선형 회귀 분석 (Linear Regression)
→ 결과를 일으키는 원인을 찾아가는 과정 종속 변수 : 실험에서 결과에 해당하는 값, 1차 방정식으로 이해하면 y 값에 해당독립 변수 : 원인에 해당하는 개념→ 과거 현상이 어떤 원인 때문에 발생하였는지 밝혀내고 이해하는데 사용 한다. 예시로 기본 금리 상승과 이자율
7.[머신러닝] SVM (Support Vector Machine)- 분류, 회귀
→ 서포트 벡터 머신은 매우 강력하고 선형이나 비선형 분류, 회귀, 이상치 탐색에 사용할 수 있는 다목적 머신러닝 모델\- 결정 경계를 기준으로 데이터를 분류하는 것→ SVM 분류기를 클래스 사이에 가장 폭이 넓은 도로를 찾는 것으로 생각할 수 있음서로 다른 클래스 두
8.[머신러닝] 릿지 회귀 (Ridge Regression)
→ 규제가 추가된 선형 회귀 이다. 이 규제항은 학습 알고리즘을 데이터에 맞추는 것뿐만 아니라 모델의 가중치가 가능한 작게 유지되도록 한다.
9.[머신 러닝] 라쏘 회귀(Lasso Regression)
→ 라쏘 회귀는 선형 회귀의 또 다른 규제된 버전릿지 회귀처럼 비용 함수에 규제항을 더하지만 릿지 회귀와 다르게 가중치 벡터 $l_1$ 노름을 사용한다