🍐 앙상블 학습
앙상블 학습 분류는 여러개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출해내는 기법
→ 다양한 분류기의 예측 결과를 분석함으로써 단일 분류기보다 신뢰성을 높이는 것이 목적
앙상블 학습 유형은 전통적으로 보팅(Voting), 배깅(Bagging), 부스팅(Boosting) 의 세가지로 나눌 수 있음
보팅과 배깅은 여러 개의 분류기가 투표를 통해 최종 예측 결과를 산정하는 방식이다
⚪️ 보팅 :
서로 다른 알고리즘을 가진 분류기를 결합하는 것 (ex; 선형회귀, 서포트 벡터 머신)
🟣 배깅:
분류기가 같은 유형의 알고리즘 기반이지만, 데이터 샘플링을 다르게 학습하여 수행하는 것 (ex; 랜덤포레스트 알고리즘)
- 개별 Classifier에게 데이터를 샘플링해서 추출하는 방식을 부트스트래핑(Bootstraping) 분할 방식이라 함
- 배깅 방식은 중첩을 허용함
🟠 부스팅 :
여러 개의 분류기가 순차적으로 학습을 수행하되, 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해서는 올바르게 예측할 수 있도록 다음 분류기에는 가중치(weight)를 부여하여 학습과 예측을 진행하는 것
(ex;그래디언트 부스트, XGBoost , LightGBM)
보팅 - 하드 보팅과 소프트 보팅
하드 보팅 (Hard Voting) : 예측한 결괏값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결과값으로 선정
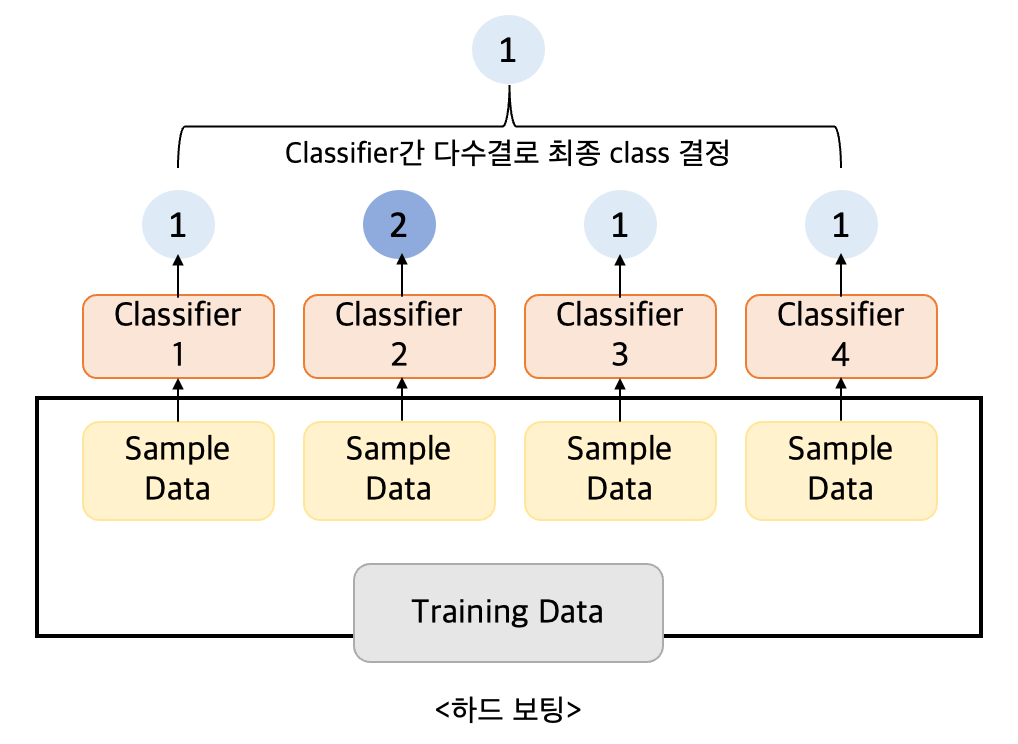
소프트 보팅 (Soft Voting) : 분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균하여 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결과값으로 선정
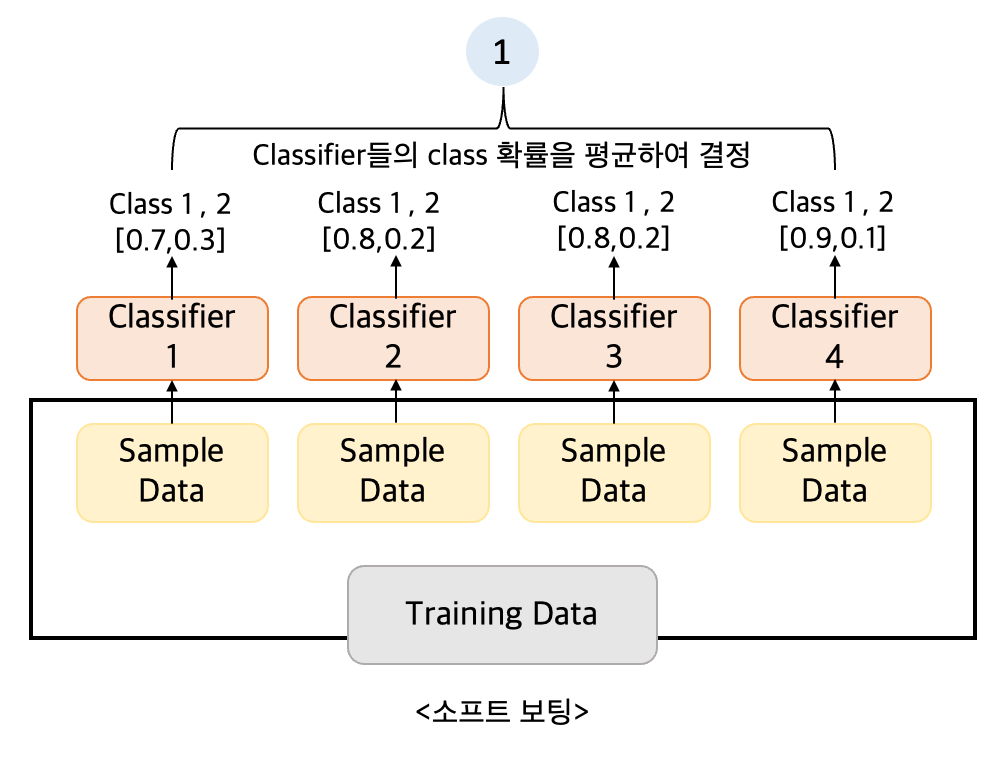
→일반적으로 소프트 보팅이 보팅 방법으로 적용
보팅 분류기(Voting Classifier)
사이킷런은 보팅 방식의 앙상블을 구현한 VotingClassifier 클래스를 제공 중
보팅 방식의 앙상블을 이용한 위스콘신 유방암 데이터 분석
위스콘신 유방암 데이터 세트 : 유방암의 악성종양, 양성종양 여부를 결정하는 이진 분류 데이터 세트
→ 로지스틱 회귀과 KNN을 기반으로 보팅 분류기 생성
import pandas as pd
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
cancer=load_breast_cancer() #위스콘신 유방암 데이터 세트 불러오기
data_df=pd.DataFrame(cancer.data,columns=cancer.feature_names)
data_df.head(3)
#개별 모델은 로지스틱 회귀와 KNN
lr_clf = LogisticRegression()
knn_clf = KNeighborsClassifier(n_neighbors=8)
#개별 모델을 소프트 보팅 기반의 앙상블 모델로 구현한 분류기
vo_clf = VotingClassifier(estimators=[('LR',lr_clf),('KNN',knn_clf)],voting='soft')
X_train,X_test,y_train,y_test=train_test_split(cancer.data,cancer.target,test_size=0.2,random_state=156)
#VotingClassifier 학습/예측/평가
vo_clf.fit(X_train,y_train)
pred = vo_clf.predict(X_test)
print('Voting 분류기 정확도 :{0:.4f}'.format(accuracy_score(y_test,pred)))
classifiers = [lr_clf,knn_clf]
for classifier in classifiers:
classifier.fit(X_train,y_train)
pred = classifier.predict(X_test)
class_name = classifier.__class__.__name__
print('{0} 정확도 : {1:.4f}'.format(class_name,accuracy_score(y_test,pred)))
로지스틱 회귀와 KNN을 기반으로 소프트 보팅방식으로 새롭게 보팅 분류기를 만들어 보았다.
보팅 분류기가 정확도가 조금 높게 나타났는데, 보팅으로 여러개 기반 분류기를 결합한다고 해서 무조건 예측 성능이 향상 되는 것은 아님
보팅과 스태킹 등은 서로 다른 알고리즘을 기반으로 하지만, 배깅과 부스팅은 대부분 결정 트리 알고리즘을 기반으로 함, 앙상블 학습에서는 결정트리의 과적합 문제 등의 단점을 수십 ~ 수천개의 분류기 결합을 통하여 보완
본 포스팅은 파이썬 머신러닝 완벽가이드를 바탕으로 작성되었습니다
