
데이터 전처리(Data Preprocessing)는 ML 알고리즘 만큼 중요하다
어떠한 데이터에 기반하고 있느냐에 따라 결과도 크게 달라지기 때문이다
ML 알고리즘을 적용하기 전에 데이터에 대해 미리 처리해야할 사항
1. 결손값, 즉 Null 값은 허용되지 않음 . 따라서 이러한 Null 값을 다른 값으로 변환해야하는데 평균값으로 대체하거나 더 정밀한 대체값을 선정해야함
2. 모든 문자열 값은 인코딩 돼서 숫자형으로 변환해야 한다
데이터 인코딩
대표적인 방법으로는 레이블 인코딩(Label encoding) 과 원-핫 인코딩(One Hot encoding) 이 있다.
레이블 인코딩 (Label encoding)
- 카테고리 피처를 코드형 숫자 값으로 변환하는 것
예를 들어 데이터의 상품 구분이 냉장고, TV, 전자레인지 등으로 돼 있다면 냉장고:1, TV:2, 전자레인지 :3 이런식으로 숫자형 값으로 변환해준다from sklearn.preprocessing import LabelEncoder items = ['TV','냉장고','전자레인지','컴퓨터','선풍기','믹서','믹서'] encoder = LabelEncoder() encoder.fit(itmes) labels = encoder.transform(items) print('인코딩 변환 값 :',labels)
이런식으로 사용이 가능며 각각 카테고리별로 인코딩 된 것을 확인할 수 있다.인코딩 변환값: [0,1,4,5,3,2,2]
invers_transform() 을 통하여 인코딩된 값들을 다시 디코딩할 수 있다print('디코딩 원본값:',encoder.inverse_transform([4,5,2,0,1,1,3])
레이블링은 이렇게 간단하게 문자열 값을 숫자형 카테고리 값으로 변환한다디코딩 원본값: ['전자레인지','컴퓨터','믹서','TV','냉장고','냉장고','선풍기'])
하지만 몇몇 ML 알고리즘에 이렇게 적용할 경우 예측 성능이 떨어질 수 있다
숫자 값으로 변환이 되며 크고 작은 숫자의 특성이 작용하기 때문이다
따라서 레이블 인코딩은선형회귀와 같은 ML 알고리즘에는 적용하지 않아야 한다 !
트리계열의 알고리즘은 이러한 특성을 반영하지 않으므로 레이블 인코딩에도 별 문제는 없다
원 핫 인코딩 (One - Hot Encoding)
- 피처 값의 유형에 따라 새로운 피처를 추가하여 고유 값에 해당하는 칼럼에만 1을 표시하고 나머지 칼럼에는 0을 표시하는 방식
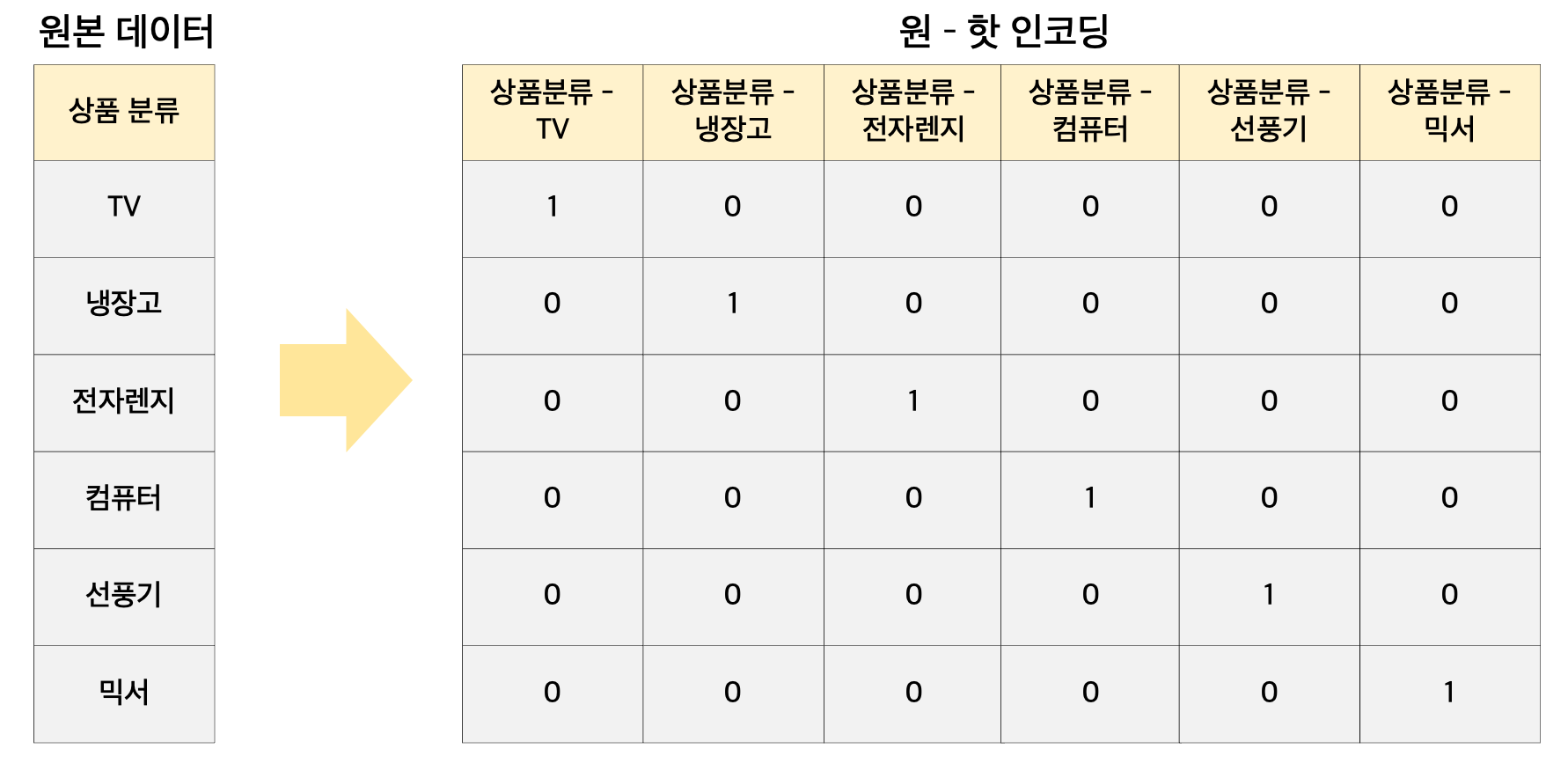
해당 고유값에 매칭되는 피처만 1이되고 나머지 피처는 0을 입력하며, 이러한 특성으로 원 - 핫 인코딩으로 불린다
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import LabelEncoder
import numpy as np
items = ['TV','냉장고','전자레인지','컴퓨터','선풍기','선풍기','믹서','믹서']
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
#2차원 데이터로 변환
labels = labels.reshape(-1,1)
oh_encoder = OneHotEncoder()
oh_encoder.fit(labels)
oh_labels=oh_encoder.transform(labels)
print('원 핫 인코딩데이터')
print(oh_labels.toarray())
print('원 핫 인코딩 차원')
print(oh_labels.shape)
판다스에는 원 핫 인코딩을 더 쉽게 지원하는 API 가 있다 . get_dummies()를 이용하여 쉽게 원 핫 인코딩을 할 수 있다
피처 스케일링과 정규화
서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업을 피처 스케일링 (feature scaling)이라고 한다
대표적인 방법으로는 표준화(Standardization) 와 정규화(Nomalization) 이 있다.
- 표준화는 데이터 피처 각각이 평균이 0이고 분산이 1인 가우시안 정규 분포를 가진 값으로 변환하는 것을 의미
- 정규화는 서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 개념
StandardScaler
StandardScaler는 표준화를 쉽게 지원하기 위한 클래스
즉, 개별 피처를 평균이 0이고, 분산이 1인 값으로 변환
서포트 벡터 머신, 선형회귀, 로지스틱 회귀는 데이터가 가우시안 분포를 가지고 있다고 가정하고 구현됐기 때문에 사전에 표준화를 적용하는것이 중요할 수 있다
from sklearn.preprocessing import StandardScaler
#StandardSCcaler객체 생성
scaler= StandardScaler()
scaler.fit(iris_df)
iris_scaled=sclaer.transform(iris_df)
iris_df_scaled=pd.DataFrame(data=iris_scaled.columns= iris, feature_names)MinMaxScaler
데이터 값을 0과 1사이의 값으로 변환 , 데이터의 분포가 가우시안 분포가 아닌 경우 Min, Max, Scale을 적용해 볼 수 있다
from sklearn.preprocessing import MinMaxScaler
scaler=MinMaxScaler()
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
iris_df_scaled=pd.DataFrame(data=iris_scaled,columns= iris.feature_names)유의할점
- 가능하다면 전체 데이터 스케일링 변환을 적용한 뒤 학습과 테스트 데이터로 분리
- 1이 여의치 않다면 테스트 데이터 변환시에는 fit()이나 fit_transform()을 적용하지 않고 학습 데이터로 이미 fit()된 Scaler 객체를 이용해 transform()으로 변환
참고/레퍼런스
파이썬 머신러닝 완벽가이드 책을 참고하였습니다
