분류란?
지도학습의 대표적인 유형인 분류(Classification) 은 학습 데이터로 주어진 데이터의 피처와 레이블 값을 머신러닝 알고리즘으로 학습해 모델을 생성하고, 이렇게 생성된 모델에 새로운 데이터 값이 주어졌을 때 미지의 레이블 값을 예측 하는 것
분류는 다양한 머신러닝 알고리즘으로 구현 가능
- 베이즈(Bayes) 통계와 생성모델에 기반한 나이브 베이즈
- 독립변수와 종속 변수의 선형관계성에 기반한 로지스틱 회귀
- 데이터 균일도에 따른 규칙 기반의 결정 트리
- 개별 클래스 간의 최대 분류 마진을 효과적으로 찾아주는 서포트 벡터 머신
- 근접 거리를 기준으로 하는 최소 근접 알고리즘
- 심층 연결 기반의 신경망
- 서로 다른 머신러닝 알고리즘을 결합한 앙상블
🍎 결정 트리
결정 트리(Desicion Tree)는 ML 알고리즘 중 직관적으로 이해하기 쉬운 알고리즘
데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만드는 것
가장 쉽게 표현하는 방법은 If-else를 기반으로 나타내는 것, 따라서 데이터의 어떤 기준을 바탕으로 규칙을 만들어야 가장 효율적인 분류가 될 것인가가 알고리즘의 성능을 크게 좌우함
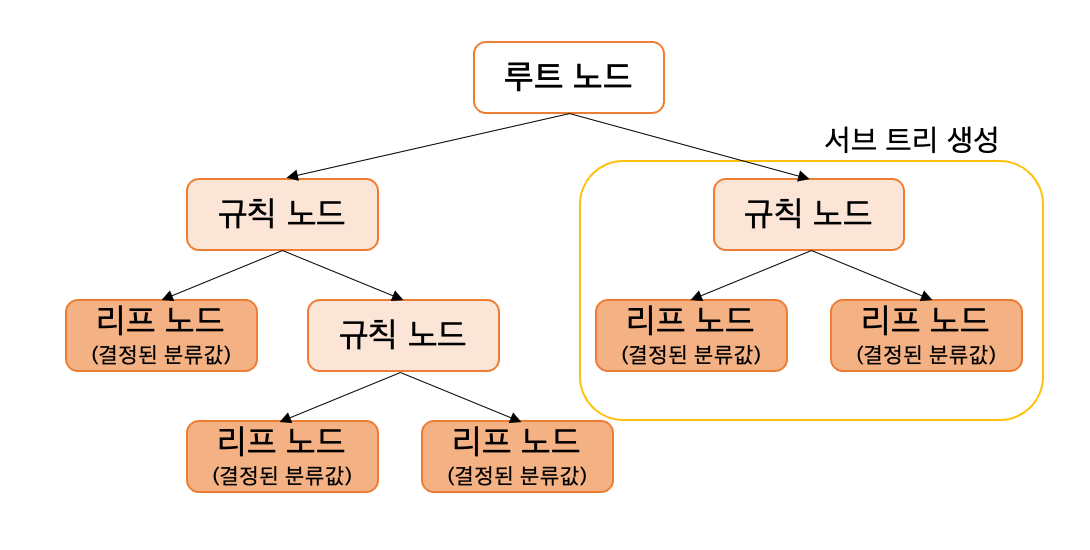
-
규칙 노드 (Decision Node) : 규칙 조건이 되는 것
-
리프 노드 (Leaf Node) : 결정된 클래스 값
→ 새로운 규칙 조건마다 서브 트리가 생성된다. 규칙 조건을 만들때마다 규칙 노드가 생성됌.
하지만, 많은 규칙이 있다는 것은 train 데이터에 맞게 분류를 결정하는 방식이 복잡해진 다는 것이고, 과적합으로 이어지기 쉬움 . 트리의 깊이가 깊어질 수록 결정트리의 예측 성능이 저하될 가능성이 높음
가능한 적은 결정 노드로 높은 예측 정확도를 가지려면 데이터를 분류할 때 최대한 많은 데이터 세트가 해당 분류에 속할 수 있도록 결정 노드의 규칙이 정해져야 함 → 이를 위해서 최대한 균일한 데이터 세트를 구성할 수 있도록 분할하는 것이 필요
정보의 균일도를 측정하는 대표적인 방법으로 정보 이득 지수와 지니 계수가 있음
🟣 정보 이득 지수 :
엔트로피 개념을 기반으로 하여 1에서 엔트로피 지수를 뺀 값 (1-엔트로피 지수)
⚪️ 지니 계수:
경제학자 코라도 지니의 이름에서 딴 계수로서 0이 가장 평등하고 1로 갈수록 불평등함, 머신러닝에 적용될 때는 지니 계수가 낮을수록 데이터의 균일도가 높은것으로 해석되어 지니계수가 낮은 속성을 기준으로 분할
→ 사이킷런에서 구현한 DecisionTreeClassifier은 기본으로 지니 계수를 이용해 데이터 세트를 분할함
❄️ 결정 트리 모델의 특징
장점
- 알고리즘이 쉽고 직관적이다
- 피처의 스케일링이나 정규화 등 사전 가공 영향도가 크지 않다
단점
- 과적합일 경우 알고리즘 성능이 떨어진다
- 트리의 크기를 사전에 제한하는 튜닝 필요
🧚🏻 결정 트리 파라미터
min_samples_split :
- 노드를 분할하기 위한 최소한의 샘플 데이터 수로 과적합을 제어하는 데 사용
- 디폴트는 2, 작게 설정할수록 분할되는 노드가 많아져 과적합 가능성 증가
min_samples_leaf :
- 말단 노드가 되기 위한 최소한의 샘플 데이터 수
- 과적합 제어 용도
max_features :
- 최적의 분할을 위해 고려할 최대 피처 개수, 디폴트는 None
- int 형으로 지정하면 대상 피처의 개수, float 형으로 지정하면 전체 피처 중 대성 피처의 퍼센트
- None은 전체 피처 선정
max_depth :
- 트리의 최대 깊이를 규정
max_leaf_nodes :
- 말단 노드의 최대 개수
🤯 결정 트리 과적합(Overfitting) 해결
from sklearn.datasets import make_classification
import matplotlib.pyplot as plt
%matplotlib inline
plt.title("3 Class values with 2 Features Sample data creation")
#2차원 시각화를 위해 피처는 2개, 클래스는 3가지 유형의 분류 샘플 데이터 생성
X_features , y_labels =make_classification(n_features=2,n_redundant=0,n_informative=2, n_classes=3,n_clusters_per_class=1,random_state=0)
#그래프 형태로 2개의 피처로 2차원 좌표 시각화, 각 클래스 값은 다른 색깔로 표시
plt.scatter(X_features[:,0],X_features[:,1],marker='o',c=y_labels,s=25,edgecolor='k')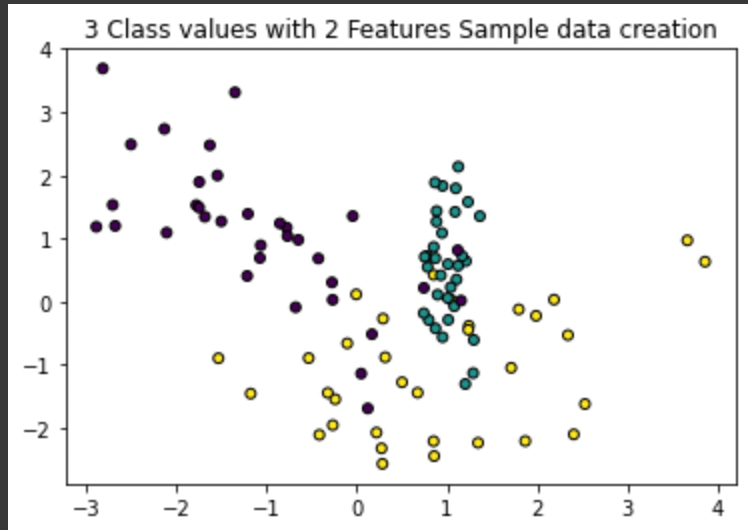
특정한 트리 생성 제약 없이 결정트리 학습을 진행하여 결정 경계가 어떻게 되는지 시각화를 진행하였다.
from sklearn.tree import DecisionTreeClassifier
#특정한 트리 생성 제약 없는 결정 트리의 학습과 결정 경계 시각화
dt_clf = DecisionTreeClassifier().fit(X_features,y_labels)
visualize_boundary(dt_clf,X_features,y_labels)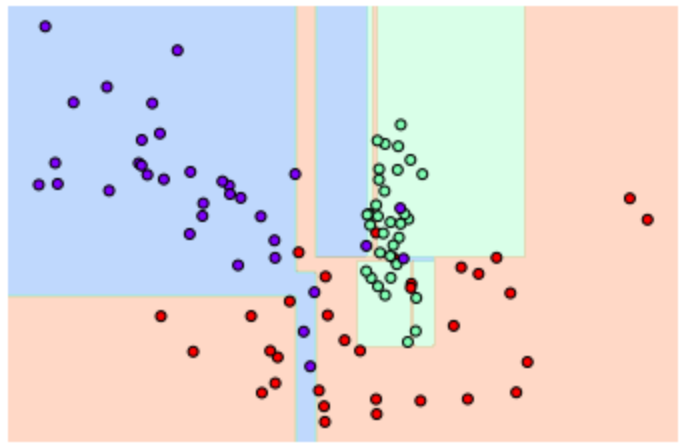
→ 일부 이상치 데이터까지 분류하기 위해 분할이 자주 일어나서 결정 기준 경계가 매우 많아졌다. 따라서 이 경우 다른 데이터 셋을 예측하면 예측 정확도가 떨어짐 (과적합)
따라서 min_samples_leaf=6을 설정하며 결정기준 경계가 변하는지 확인
#min_samples_leaf=6 으로 트리 생성 조건을 제약한 결정 경계 시각화
dt_clf = DecisionTreeClassifier(min_samples_leaf=6).fit(X_features,y_labels)
visualize_boundary(dt_clf,X_features,y_labels)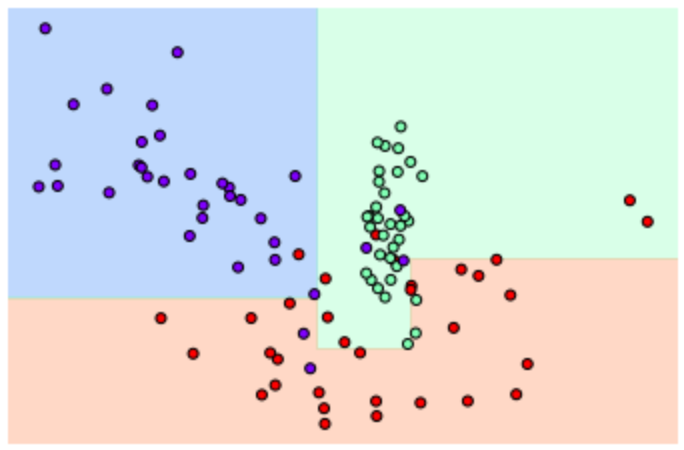
이상치에 크게 반응하지 않으며 일반화된 분류 규칙에 따라 분류 됐음을 알 수 있음
-> 따라서 다른 데이터 셋을 넣어도 과적합 되지 않고 정확도가 더 높아질 것임을 알 수 있다
본 포스팅은 파이썬 머신러닝 완벽 가이드 책을 기반으로 작성하였습니다
