
💭 하둡(Hadoop)이란?

하나의 성능 좋은 컴퓨터를 이용하여 데이터를 처리하는 대신 적당한 성능의 컴퓨터 여러 대를 클러스터화하고 큰 크기의 데이터를 클러스터에서 병렬로 동시에 처리하여 처리 속도를 높이는 것을 목적으로 하는 분산처리를 위한 오픈소스 프레임워크
하둡 소프트웨어 라이브러리는 간단한 프로그래밍 모델을 통하여 여러 대의 컴퓨터 클러스터에서 대규모 데이터 세트를 분산처리할 수 있게 해주는 프레임워크
- 단일 서버에서 수천 대의 머신으로 확장할 수 있도록 설계되어 있음
- 일반적으로 하둡 분산처리시스템(HDFS)과 맵리듀스(MapReduce) 프레임워크로 시작되었으나, 여러 데이터 저장, 실행 엔진, 프로그래밍 및 데이터 처리 등 하둡 생태계 전반을 포함하는 의미로 확장되고 있음
✔️ 하둡의 동작 흐름
데이터가 들어오면, 데이터를 쪼개고 그 데이터를 분리해서 저장한다.
따라서 데이터를 쪼갠 후에 어느 데이터 노드에 저장되어 있는지 기록해 놓는 메타 데이터가 필요하다.
→ 하둡에서 데이터를 저장하기 전 네임노드에서 분산을 하고 저장 위치를 분배한다. 그 후에 여러개 중 지정된 데이터 노드에 저장을 한다.
⬜️ HDFS(Hadoop Distributed FileSystem)
HDFS는 하둡 네트워크에 연결된 기기에 데이터를 저장하는 분산형 파일시스템으로 실시간 처리보다 배치처리를 목적으로 설계 되었음 ! 따라서 작업량이 작거나 빠른 데이터 응답이 필요한 작업에서는 적합하지 않음
📍 HDFS의 특징
-
데이터를 블록 단위로 나누어 저장한다.
따라서 큰 데이터를 나누어 저장하므로 큰 파일도 저장 가능하다. 만약 블록 단위보다 작은 크기라면 나누지 않고 그대로 저장 -
블록을 복제하여 중복 저장한다.
블록에 문제가 생겨 데이터가 손실되는 경우를 막기 위해 복제하여 중복 저장한다. 즉 하나의 블록은 3개의 블록으로 복제되어 저장된다. 따라서 저장공간이 3배 더 필요함 -
HDFS는 읽기 중심의 목적으로 만들어졌기 때문에 파일 수정은 지원하지 않는다 -
데이터의 지역성을 이용하여 처리 속도를 증가시킨다.
데이터 처리 시, 데이터를 이동시켜 처리하지 않고 데이터의 위치에서 알고리즘을 처리하여 데이터를 이동시키는 비용을 줄일 수 있다.
⚪️ HDFS 의 구조
기본적으로 마스터 슬레이브 구조이다.
- 마스터 슬레이브 구조: 장치나 프로세스가 하나 이상의 다른 장치나 프로세스를 통제하고 통신 허브 역할을 하는 비대칭 통신 및 제어 모델
⇒ 분산 되어져 있는 것들을 관리한 마스터가 필요하다고 생각하면 된다! (일을 시킬 컴퓨터가 있어야 함)
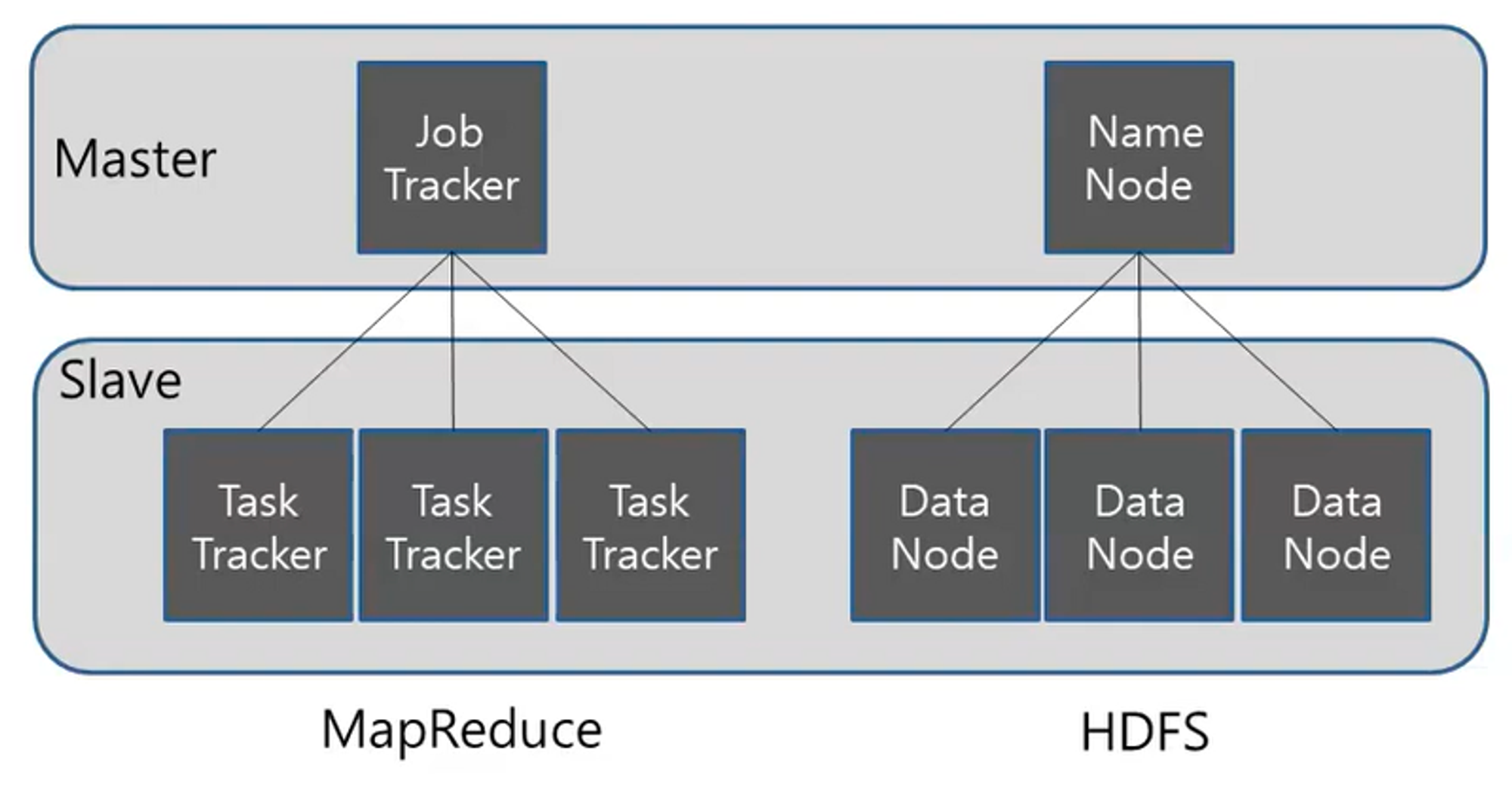
- HDFS는 마스터 슬레이브 구조로 하나의 네임노드와 여러 개의 데이터 노드로 구성된다.
- 네임노드는 메타 데이터를 가지고 있고, 데이터는 블록 단위로 나뉘어 데이터 노드에 저장된다.
🔸 네임 노드(namenode)
네임노드는 분산 처리 시스템에서 마스터를 담당하며 메타데이터 와 데이터 노드를 관리 한다.
- 각 데이터 노드에서 전달하는 메타 데이터를 받은 후에 전체 노드의 메타데이터 정보와 파일 정보를 묶어서 관리
- 파일 시스템을 유지하기 위해 메타데이터 관리
- 데이터를 저장할 때 기본적으로 블록 단위로 들어온다. 이때 들어온 블록들을 어떤 데이터 노드에 저장할지 정해줌 !!
- 네임 노드와 데이터 노드는 3초마다 하트 비트를 주고 받는데, 이러한 알림이 오지 않으면 문제가 생겼다고 판단하여 다른 데이터 노드에 복제된 블럭을 가지고 와서 사용한다.
- 메타데이터 : 파일이름, 크기, 생성시간, 접근권한, 소유자 및 그룹 소유자 등으루 구성
🔸 데이터 노드(datanode)
데이터들이 저장되는 컴퓨터, 파일을 저장하는 역할을 하며 이 때 파일은 블록 단위로 저장된다. 주기적으로 네임노드에 하트 비트와 블록 리포트를 전달
- 하트 비트: 데이터 노드의 동작 여부를 판단하는데 이용하는 것
- 블록 리포트 : 블록의 변경사항을 확인하고 네임노드의 메타데이터를 갱신한다.
⇒ 데이터 노드의 상태
활성 상태와 운영 상태를 확인할 수 있다.
활성 상태
- Live : 하트비트를 통해 활성 상태가 확인 되는 경우
- Stale : 문제가 발생하여 지정 시간동안 하트비트를 받지 못할 경우
- Dead : 지정한 시간동안 응답이 없을 경우
운영 상태
- 데이터 노드의 업그레이드나 작업을 하기 위해 서비스를 잠시 멈춰야 할 경우 블록을 안전하게 보관하기 위해 설정
- NORMAL : 서비스 상태
- DECOMMISSIONED : 서비스 중단 상태
- DECOMMISION_INPROGRESS : 서비스 중단 상태로 진행 중
- IN_MAINTENANCE : 정비 상태
- ENTERING_MAINTENANCE : 정비 상태로 진행 중
⚪️ HDFS 파일 읽기
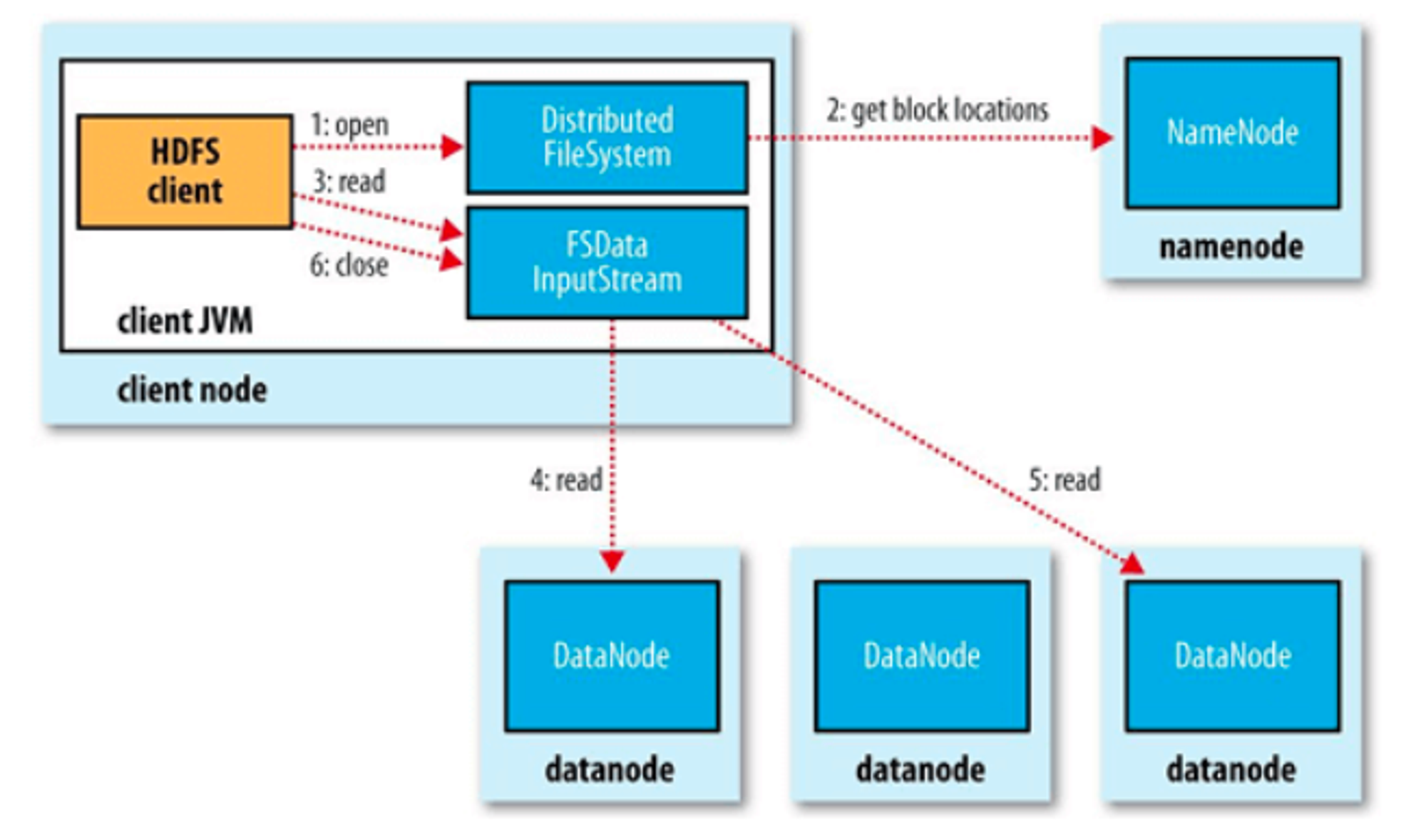
📍 파일을 읽는 순서
- open() 명령어를 통해 DistributedFileSystem에 있는 FileSystem의 파일을 연다
- PRC() 를 NameNode를 호출하여 저장되어있는 블록이 저장된 DataNode의 주소를 받는다
- Client가 데이터를 검색할 수 있도록 검색을 지원하는 입력 스트림인 FSDataInputStream을 Client에게 준다. 이걸 통해서 찾고자 하는 DataNode와 DFSInputStream이 맵핑된다. 그리고 검색 후 read() 명령어를 통해 호출
- datanode 주소가 저장된 DFSInputStream은 datanode에 대한 연결되고, 데이터는 datanode에서 클라이언트로 간다.
- 블록 끝에 도달하면 DFSInputStream은 데이터 노드에 대한 연결을 닫고, 다음 블록에 가장 접합한 데이터 노드를 찾는다.
- 읽기가 끝나면 FSDataInputStream에서 close()를 호출한다.
⚪️ 블록
Hadoop의 HDFS는 파일을 데이터 블록이라고 하는 작은 블록으로 나눈다. 지정한 크기의 블록으로 나누어 각각 독립적으로 저장된다. 지정한 크기보다 크면 나눠서 저장되고, 작으면 실제 파일 크기 그대로 저장된다.
따라서 마지막 블록을 제외하고는 모두 동일한 크기이다.
→ 검색 및 네트워크 트래픽 비용을 줄여준다.
⚪️ HDFS Federation
디렉토리 단위로 네임노드를 등록하여 사용하는 것으로 파일이 많아짐에 따른 메모리 관리 문제를 해결하기 위해 생긴 기능, 디렉토리 단위로 네임 노드를 실행하여 파일을 관리한다. 각각 독립적으로 관리하기 때문에 하나의 문제가 발생하더라도 다른 네임 노드에 영향을 주지 않는다.
⚪️ HDFS High Availability (고가용성)
네임 노드에 문제가 발생하면 모든 작업이 중지되어 파일을 읽거나 쓸 수 없다. 이 문제를 해결하기 위하여 생긴 기능 , HDFS 고가용성은 이중화된 두 대의 서버인 액티브 네임노드와 스탠바이 네임 노드를 이용하여 지원한다. 액티브 네임노드와 스탠바이 네임 노드는 데이터 노드로부터 블록 리포트와 하트비트를 모두 받아서 동일한 메타 데이터를 유지하고, 공유 스토리지를 사용하여 에디트 파일을 공유한다.
✔️
액티브 네임 노드는네임 노드의 역할 수행스탠바이 네임 노드는액티브 네임노드에 문제가 발생하면스탠바이 네임노드가액티브 네임노드로 동작
액티브 네임노드가 문제가 발생하는걸 자동으로 확인할 수 어려워 보통 주키퍼를 사용해서 장애 발생 시 자동으로 스탠바이 네임노드로 변경될 수 있도록 해준다.
⬜️ 맵리듀스(Map Reduce)
구글에서 만든 Map Reduce 알고리즘에서 탄생했다.
정리하자면, 하둡은 분산처리가 가능한 시스템과 분산되어 저장된 데이터를 병렬로 처리가능하게 하는 맵리듀스 프레임워크의 결합 단어라 할 수 있음 !!!!
🤔 하둡(Hadoop) = HDFS + Map Reduce
하둡 분산 파일 시스템(HDFS) 는 대용량 파일을 지리적으로 분산되어있는 수많은 서버에 저장하는 솔루션, 맵 - 리듀스는 분산되어 저장된 대용량 데이터를 병렬로 처리하는 솔루션이다.
⇒ 맵- 리듀스는 대용량 데이터 처리를 위한 분산 프로그래밍 모델 !!
특정 데이터를 가지고 있는 데이터 노드만 분석하고 결과만 받는 것, 통합 분석이 아닌 개별 분석 후 결과를 취합한다고 생각 !!!!
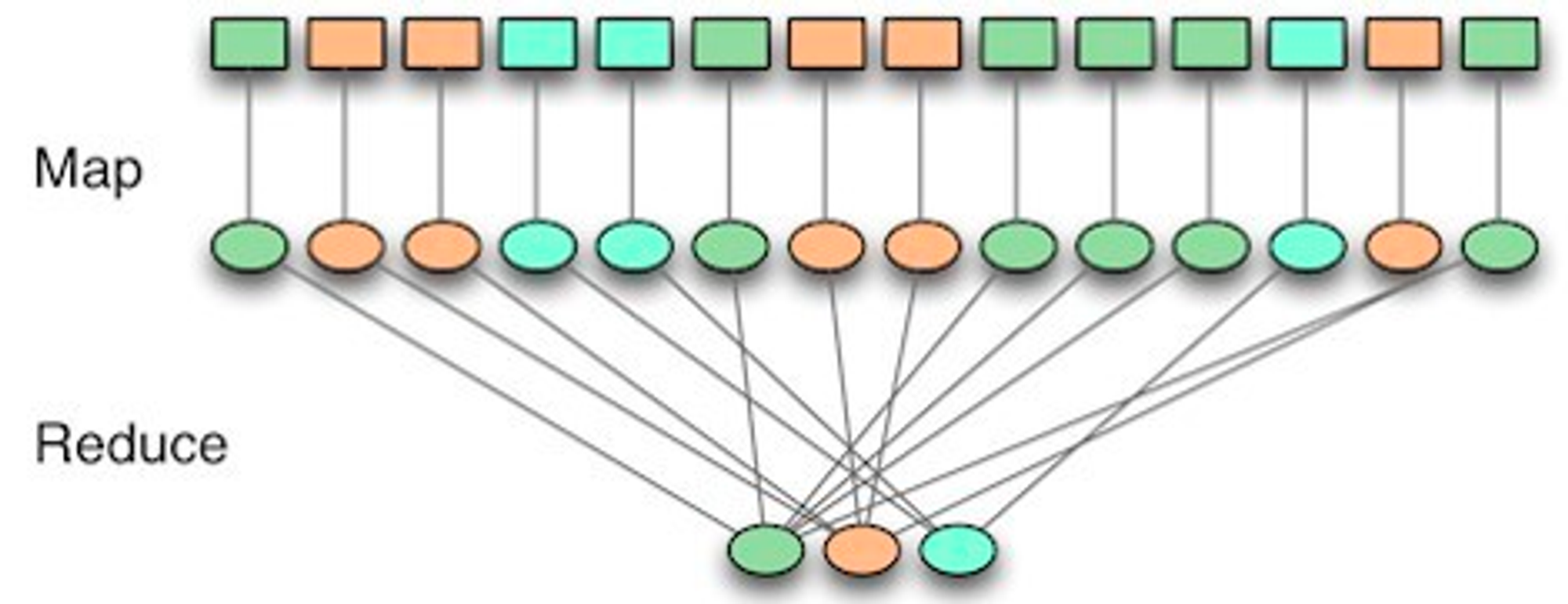
⚪️ MAP
흩어져 있는 데이터를 Key, Value의 형태의 연관성 있는 데이터 분류로 묶는 작업
- 분산되어 있는 컴퓨터에서 처리
- 흩어져 있는 데이터를 key,value로 데이터를 묶어준다
- key는 몇 번째 데이터인지, value는 값을 추출한 정보를 가진다.
⚪️ Reduce
Filtering , Sorting을 거쳐 데이터를 추출, 중복데이터를 제거하고 원하는 데이터를 추출하는 작업
- 최종적인 통합관리를 위해 Reduce를 해주는 것
- MAP 단계의 Key를 중심으로 필터링 및 정렬한다. 하둡에서는 이 Map과 Reduce를 함수를 통해 구현하고 맵리듀스 잡을통해 제어
- 맵 리듀스 잡 : Client의 수행 작업 단위
맵 리듀스 시스템은 Client,JobTracker, TaskTracker로 구성된다.
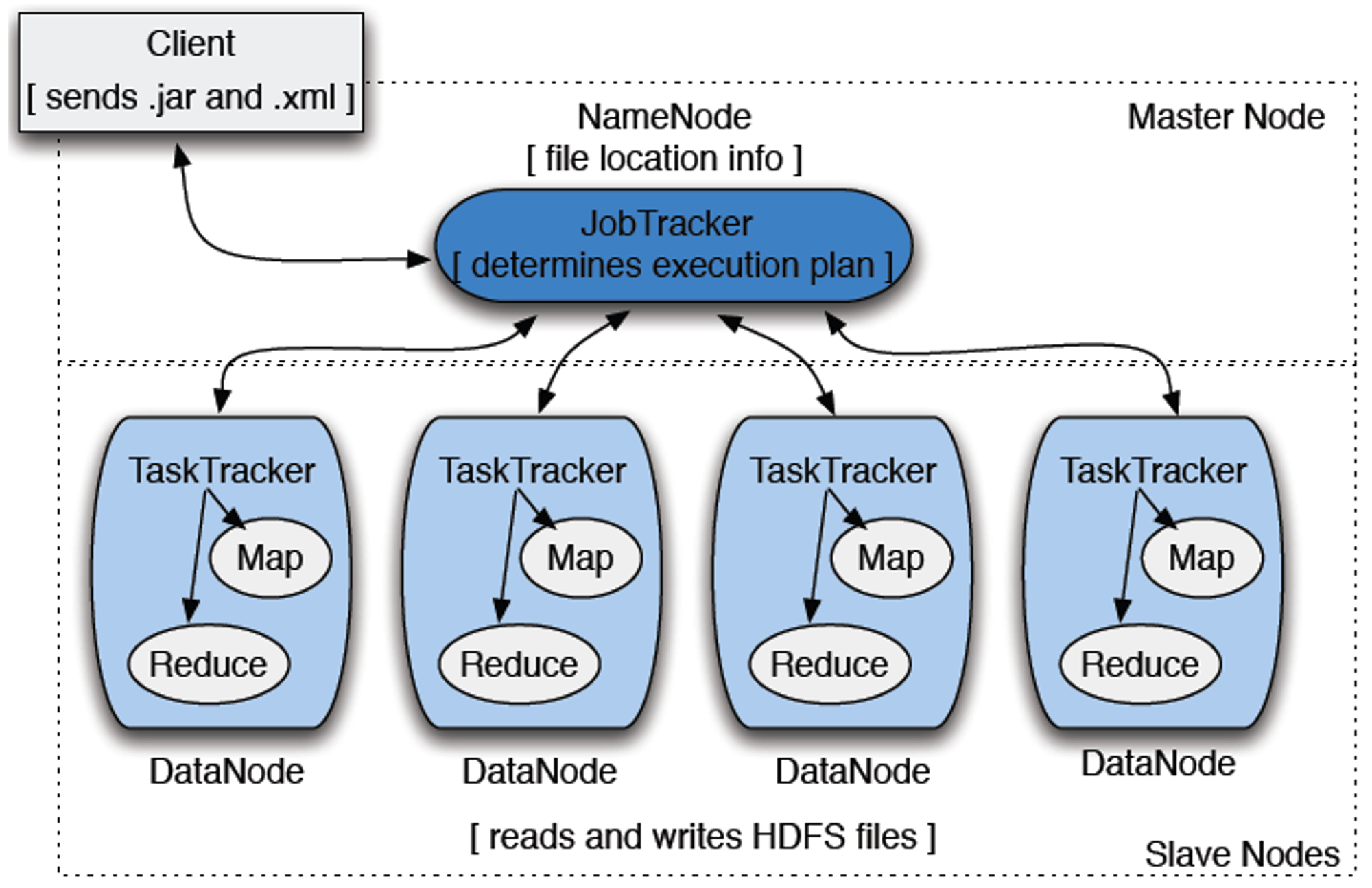
클라이언트: 분석하고자 하는 데이터를 잡(JOB)의 형태로 JobTracker에게 전달잡 트래커: 네임노드에 위치, 하둡 클러스터에 등록된 전체 잡(JOB) 을 스케줄링하고 모니터링태스크 트래커: 데이터 노드에서 실행되는 데몬, Task를 수행하고, 잡 트래커에게 상황을 보고
⬜️ 하둡 에코시스템(Hadoop EcoSystem)
하둡의 코어 프로젝트는 HDFS와 MapReduce 이지만 그 외에도 다양한 서브 프로젝트들이 있음
하둡 에코 시스템이란, 그 프레임워크를 이루고 있는 다양한 서브 프로젝트들의 모임
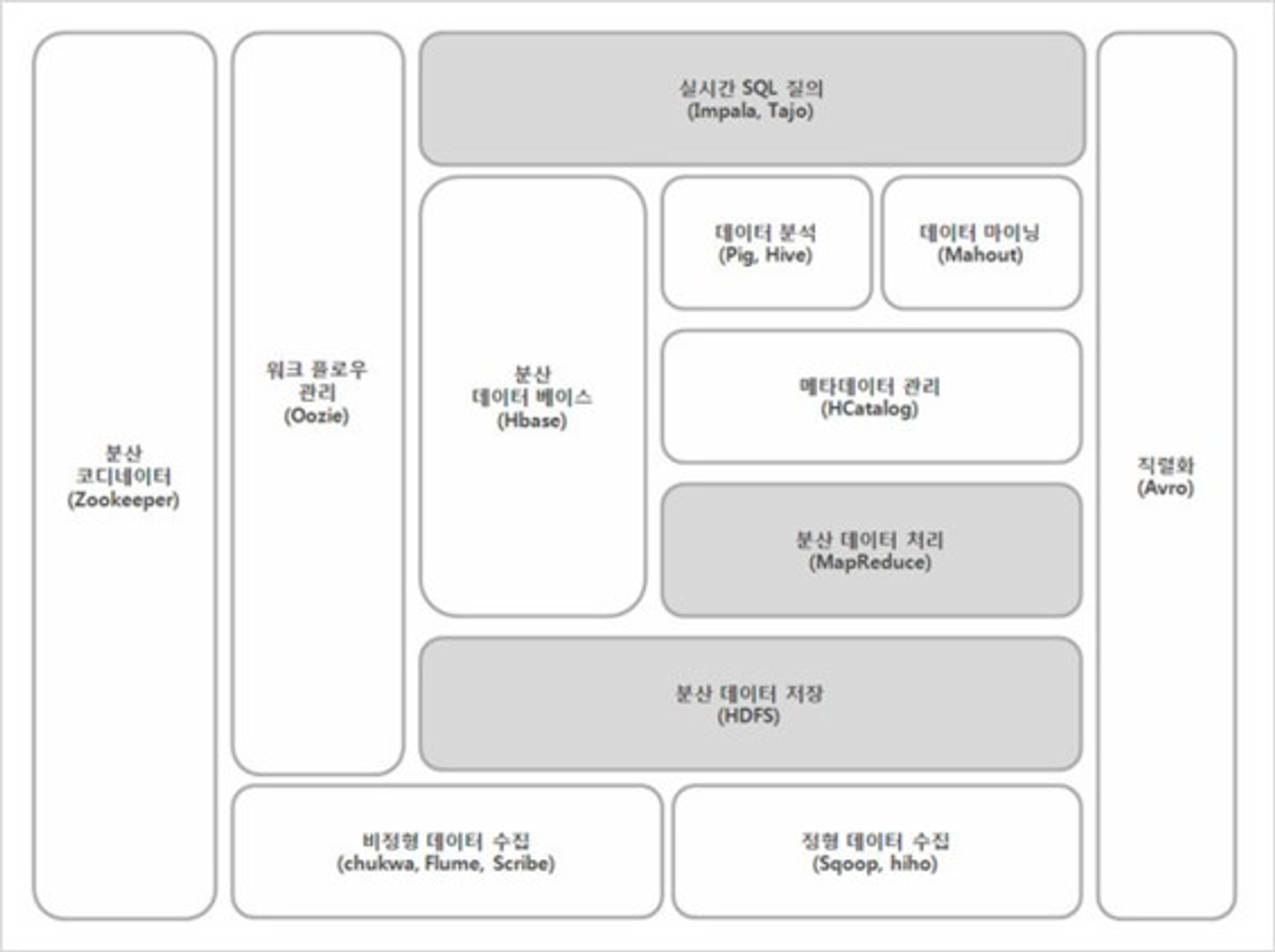
⚪️ 분산 코디네이터
ZooKeeper
- 분산 환경에서 서버 간의 상호 조정이 필요한 다양한 서비스를 제공하는 시스템
- 분산 동기화 제공, 그룹 서비스를 제공하는 중앙 집중식 서비스로 알맞은 분산처리 및 분산환경을 구성하는 서버 설정을 통합적으로 관리
⚪️ 분산 리소스 관리
YARN
- 작업 스케줄링 및 클러스터 리소스 관리를 위한 프레임워크
- 맵리듀스, 하이브, 임팔리, 스파크 등 다양한 어플리케이션들은 얀에서 작업 실행
Mesos(클라우드 환경에 대한 리소스 관리)
- Mesos 는 리눅스 커널과 동일한 원칙을 사용하며 컴퓨터에 API(Hadoop, Spark, Kafka, Elasticsearh)를 제공
- 페이스북, 트위터, 이베이 등 다양한 기업들이 메소스 클러스터 자원 관리
⚪️ 데이터 저장
HBase(분산 데이터 베이스)
- 구글 Bigtable을 기반으로 개발된 비관계형 데이터 베이스
- Hadoop 및 HDFS 위에 Bigtable 과 같은 기능 제공
HDFS(분산 파일 데이터 저장)
- 어플리케이션 데이터에 높은 처리량의 액세스를 제공하는 분산파일 시스템
Kudu(컬럼 기반 스토리지)
- 컬럼 기반 스토리지로 하둡 에코 시스템에 새로 추가되어 급변하는 데이터에 대한 빠른 분석을 위해 설계
- 클라우드데라에서 시작된 프로젝트, 2015년 말 아파치 인큐베이션 프로젝트로 선정
⚪️ 데이터 수집
Chuckwa
- 분산 환경에서 생성되는 데이터를 안정적으로 HDFS에 저장하는 플랫폼
- 대규모 분산 시스템을 모니터링하기 위한 시스템으로, HDFS 및 MapReduce에 구축되어 수집된 데이터를 최대한 활용하기 위한 모니터링 및 유현한 툴킷 포함
Flume
- 많은 양의 데이터를 수집, 집계 및 이동하기 위한 분산형 서비스
Scribe
- 페이스북에서 개발한 데이터 수집 플랫폼, Chuckwa와 다르게 데이터를 중앙 서버로 전송하는 방식, 최종 데이터는 다양한 저장소로 활용
Kafka
- 데이터 스트리밍을 실시간으로 관리하기 위한 분산시스템, 대용량 이벤트 처리를 위해 개발
⚪️ 데이터 처리
Pig
- 하둡에 저장된 데이터를 맵리듀스 프로그램으로 만들지 않고 SQL과 유사한 스크립트를 이용해 데이터를 처리, 맵리듀스 API를 매우 단순화한 형태로 설계
Mahout
- 분석 기계학습에 필요한 알고리즘을 구축하기 위한 오픈소스 프레임워크
- 클러스터링, 필터링, 마이닝, 회귀 분석 등 중요 알고리즘 지원
Spark
- 대규모 데이터 처리를 위해 빠른 속도로 실행시켜주는 엔진
- 스파크는 병렬 어플리케이션을 쉽게 만들 수 있는 고급 연산자를 제공하며 Python, R등에서 대화형으로 사용 가능
Impala
- 하둡 기반 분산 엔진으로, 맵리듀스를 사용하지 않고 C++로 개발한 인메모리 엔진을 사용하여 빠른 성능을 보여줌
Hive
- 하둡 기반 데이터 솔루션으로, 페이스북에서 개발한 오픈소스
- SQL 과 유사한 HiveQL이라는 언어를 제공하여 쉽게 데이터 분석을 할 수 있도록 도와줌
MapReduce
- 대용량 데이터를 분산처리하기 위한 프로그램으로 정렬된 데이터를 분산처리(Map)하고, 이를 다시 합치는(Reduce) 과정을 거친다. 하둡에서 대용량 데이터 처리를 위한 기술 중 가장 큰 인기를 누리고 있음
⬜️ 하둡의 장점과 단점
장점
- 오픈 소스로 라이선스에 대한 비용 부담이 적다
- 시스템을 중단하지 않고, 장비의 추가가 용이하다
- 일부 장비에 장애가 발생하더라도 전체 시스템 사용성에 영향이 적다
- 저렴한 구축 비용과 비용대비 빠른 데이터 처리
- 오프라인 배치 프로세싱에 최적화
단점
- HDFS에 저장된 데이터를 변경 불가하다.
- 실시간 데이터 분석같이 신속하게 처리해야하는 작업에는 부적합
- 너무 많은 버전과 부실한 서포트
참조
