🚲 [Kaggle] 자전거 수요 예측 - 빅분기 실기 연습
🤔 특정 시간대에 얼마나 많은 사람들이 자전거를 대여하는가?
⚪️ 데이터 설명
Datetime : 시간(YYYY-MM-DD 00:00:00)
Season : 봄(1), 여름(2), 가을(3), 겨울(4)
Holiday : 공휴일(1),그외 (0)
Workingday : 근무일(1), 그외(0)
Weather : 아주 깨끗한 날씨(1), 안개와구름(2) 눈비 (3) 아주 많은 비와 우박(4)
Temp : 온도(섭씨)
Atemp : 체감온도(섭씨)
Humidity : 습도
Windspeed : 풍속
Casual : 비회원의 자전거 대여량
Registered : 회원의 자전거 대여량
Count : 총 자전거 대여량(비회원+회원)
⬜️ 사용 라이브러리 import
import pandas as pd
import seaborn as sn
from datetime import datetime
import matplotlib.pyplot as plt
import warnings
import numpy as np
from scipy import stats⬜️ 데이터 불러오기
train = pd.read_csv("tain.csv")
test = pd.read_csv("test.csv")
submission = pd.read_csv("SampleSubmission.csv")⬜️ 데이터 확인
train 데이터 확인

test 데이터 확인
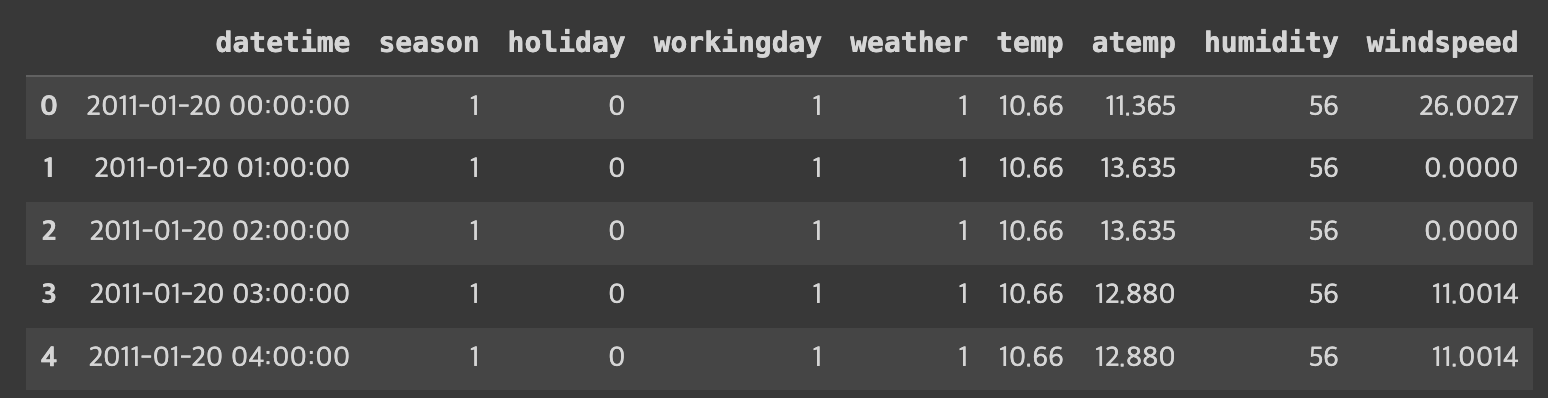
-> test 데이터에는 causal, registered, count 변수가 없다. (registered+causal = count) 이기 때문에 예측해야 하는 값이 test임을 알 수 있음
⬜️ 데이터 타입 확인
데이터 타입을 확인하였을 때 datetime 컬럼이 object 타입이므로 이를 datetime으로 변환한다.
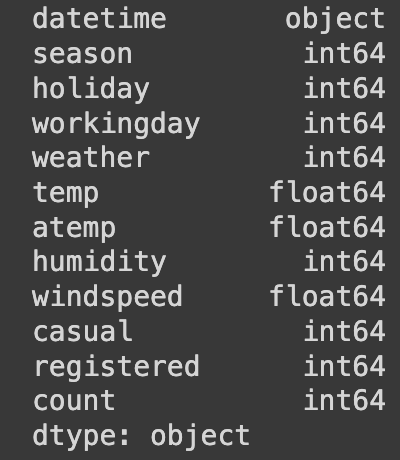
train['datetime'] = pd.to_datetime(train['datetime'])
test['datetime'] = pd.to_datetime(test['datetime'])
⚪️ 데이터 탐색
데이터를 좀더 자세히 뜯어보기 위해 년, 월, 일, 시간대로 구분해주었다! 추가로 dayofweek 을 사용하여 월 - 금 요일을 컬럼도 추가해주었다.
train['year'] = train['datetime'].dt.year
train['month'] = train['datetime'].dt.month
train['day'] = train['datetime'].dt.day
train['hour'] = train['datetime'].dt.hour
train['dayofweek'] = train['datetime'].dt.dayofweek
test['year'] = test['datetime'].dt.year
test['month'] = test['datetime'].dt.month
test['day'] = test['datetime'].dt.day
test['hour'] = test['datetime'].dt.hour
test['dayofweek'] = test['datetime'].dt.dayofweek
⬜️ 월별 count
sns.barplot(data = train,x = 'month',y = 'count')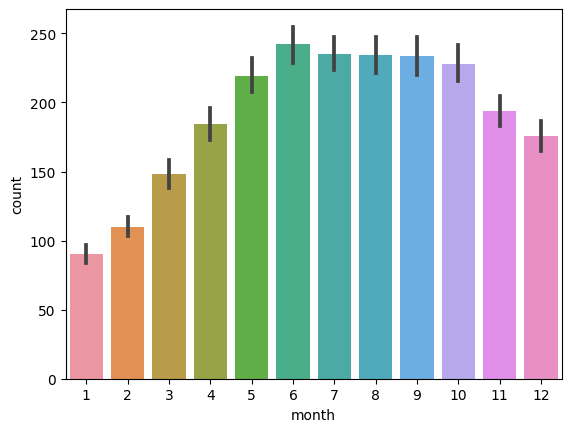
- 비교적 겨울철에는 자전거 수요량이 적음
- 6,7,8,9월에 자전거 수요량이 가장 많다!(날씨가 좋으면 역시 영향이 있는 듯 싶다??)
- 예측에 유의미한 변수로 사용할 수 있겠음
⬜️ day별 count
sns.barplot(data = train,x = 'day',y = 'count')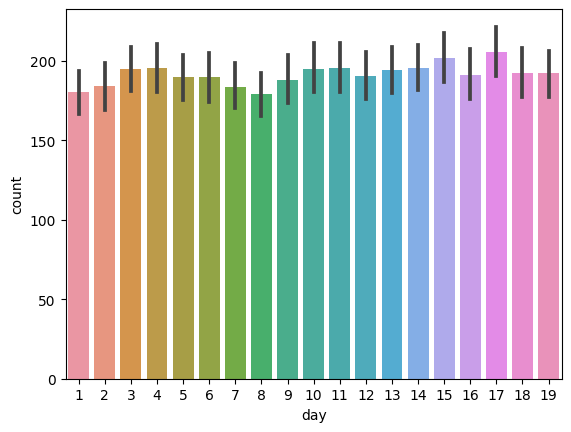
- day 별로 자전거 수요량이 달라질 수 있겠으나 엄청난 차이는 없어 보인다
⬜️ 시간대별 count
sns.barplot(data = train,x = 'hour',y = 'count')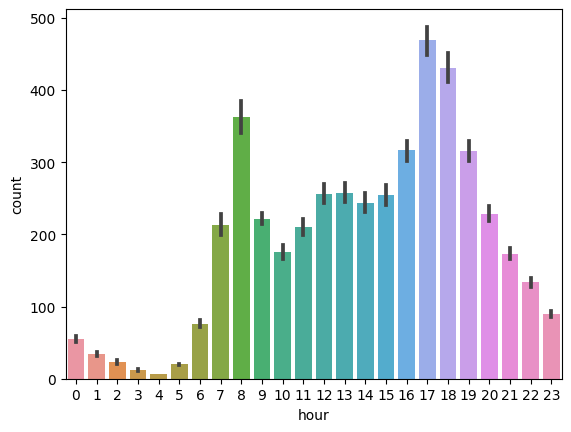
- 시간대별로 보았을 때 8시 ! 17,18시가 가장 수요량이 많다
- 출퇴근시간에 영향을 많이 받아 사람들이 많이 이용하는 것임을 알 수 있음
- 예측에 사용할 수 있겠다 !
⬜️ 계절별
sns.barplot(data = train,x = 'season',y = 'count')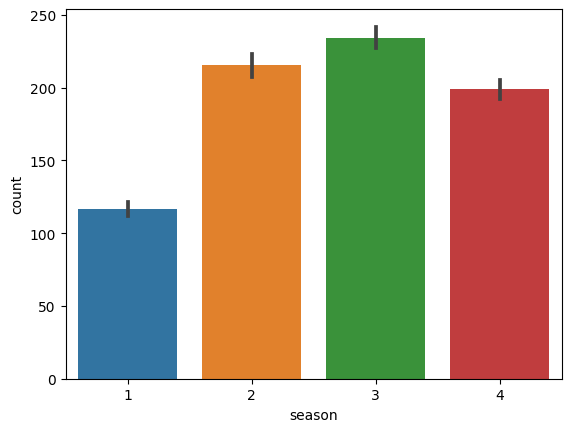
season 1: 1,2,3월
season 2: 4,5,6월
season 3: 7,8,9월
season 4: 10,11,12월
- 역시나 날씨가 선선할 즈음(?) 많이 탐
- 계절에 따른 수요량의 차이가 존재!
⬜️ workingday
sns.pointplot(data = df, x = 'hour', y = 'count', hue = 'workingday')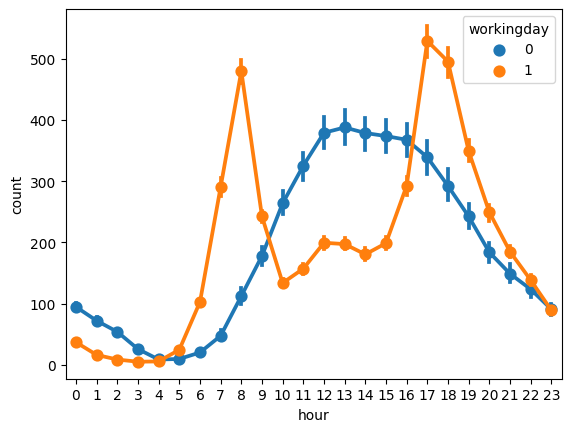
- 1: 근무일, 0: 근무일이 아닐 때
- 근무일에는 출퇴근시간에 확실히 수요가 증가한다!
- 근무일이 아닐때는 오후 시간대에 증가한다!
⬜️ holiday
sns.pointplot(data = df, x = 'hour', y = 'count', hue = 'holiday')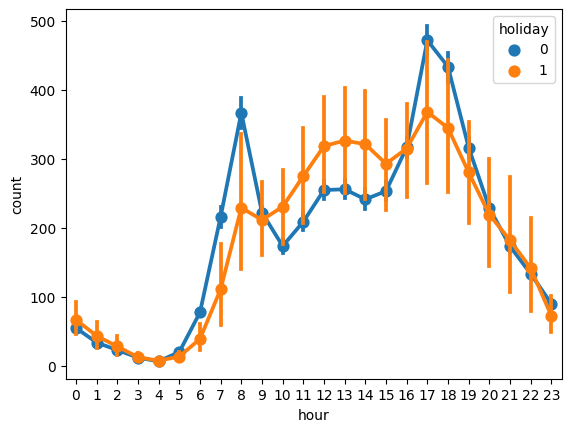
- 1: 휴일, 0: 휴일이 아닐때
- 휴일이 아닐때 출퇴근 시간에 수요가 증가
- 휴일일 때는 오후 시간대에 증가
⬜️ 계절별 시간대별
fig, ax1 = plt.subplots(1,1)
fig.set_size_inches(20, 5)
sns.pointplot(data = df, x = 'hour', y = 'count', hue = 'weather', ax = ax1)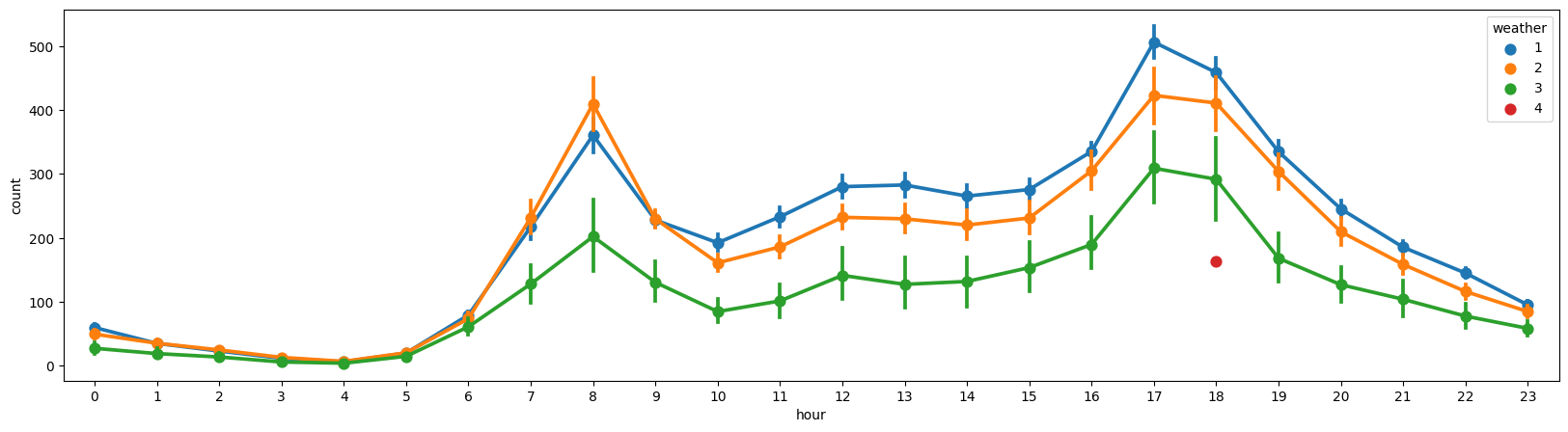
- 대~부분 비슷한 양상을 보인다
- 4(아주 많은 비와우박)은 데이터가 거의 없음! (-> 수요 자체가 많이 발생하지 않아서 그런거 같다)
⬜️ 요일별 시간대별
fig, ax1 = plt.subplots(1,1)
fig.set_size_inches(20, 5)
sns.pointplot(data = df, x = 'hour', y = 'count', hue = 'dayofweek', ax = ax1)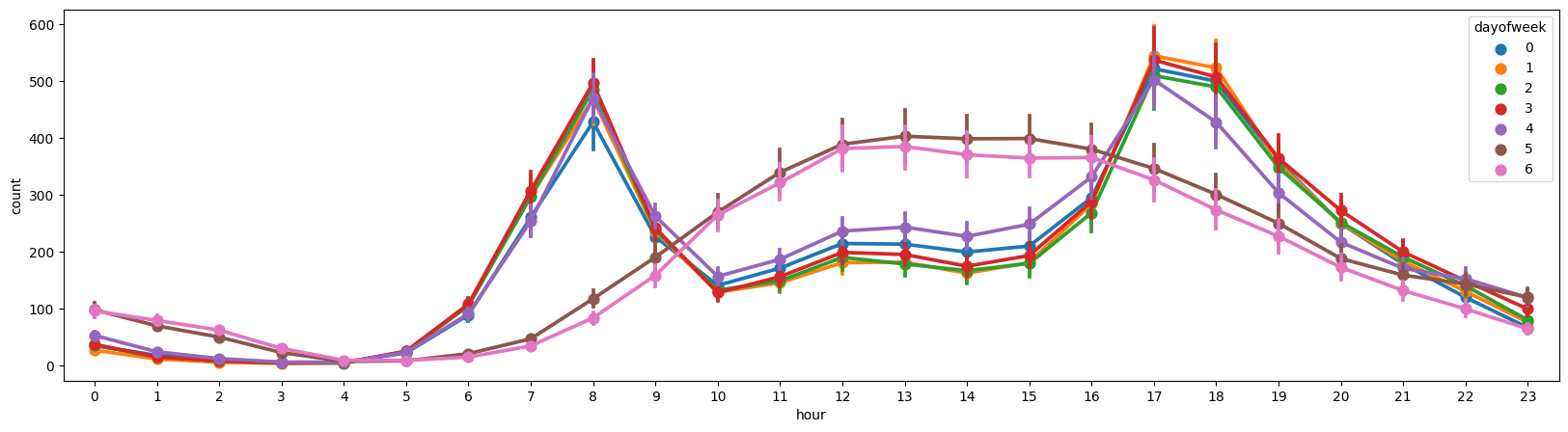
- 주말과 평일로 나뉘어 비슷한 양상을 보인다
- 근무날/근무가 아닌날의 변수와 비슷한 역할을 할거같다
- 일단 예측에는 사용해보는걸로
⬜️ 변수들 간의 상관관계 보기
corrMatt = df.corr()
mask = np.array(corrMatt)
mask[np.tril_indices_from(mask)] = False
fig,ax= plt.subplots()
fig.set_size_inches(20,10)
sns.heatmap(corrMatt, mask=mask,vmax=.8, square=True,annot=True)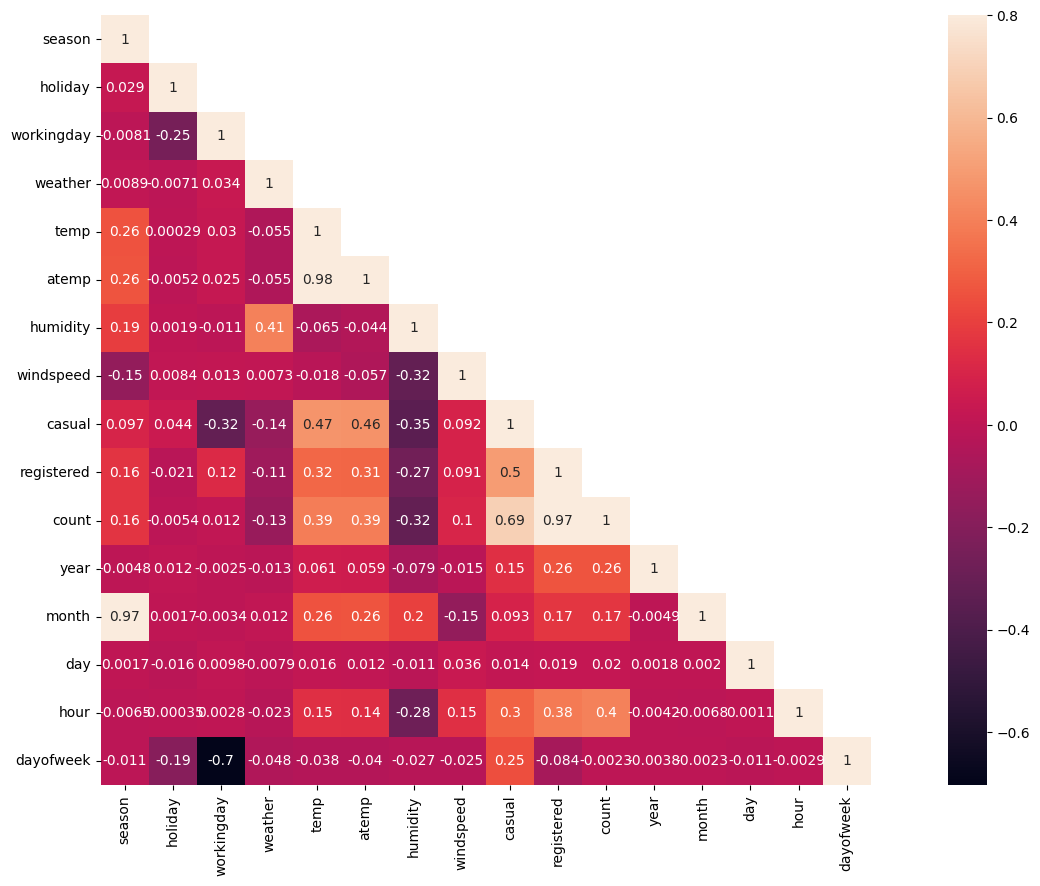
- season과 month의 상관관게는 아아아주 강하다(어쩌면 당연한 것 ㅎ)
- dayofweek 과 workingday도 아주 강력한 상관관계(당연함, 일하는 날과 아닌 날로 구분함 핫핫)
- temp와 atemp도 강력하다ㅏ
- 따라서 temp, workingday, season 이렇게 세 개만 사용하고 너무 강력한 상관성을 띄는 나머지는 제외해야겠다
train.drop(columns=["month","dayofweek","atemp"],inplace = True)
test.drop(columns=["month","dayofweek","atemp"],inplace = True)⬜️ temp, windspeed, humidity 탐색
fig,(ax1,ax2,ax3) = plt.subplots(ncols=3)
fig.set_size_inches(12, 5)
sns.regplot(x="temp", y="count", data=df,ax=ax1)
sns.regplot(x="windspeed", y="count", data=df,ax=ax2)
sns.regplot(x="humidity", y="count", data=df,ax=ax3)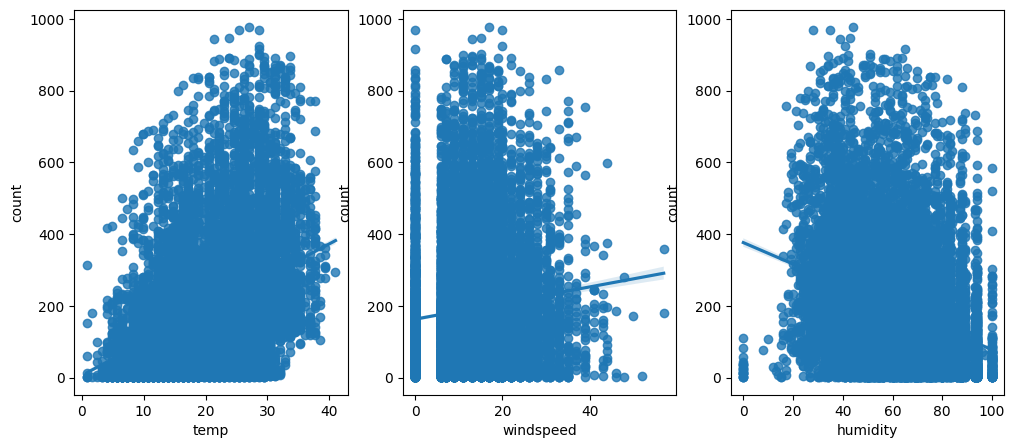
차례대로 temp, windspeed, humidity 에 대한 데이터 분포이다.
windspeed를 보면 엄청난 인사이트가 있음
✅ 바람의 세기가 0인경우가 있을 수가 있나??
-> 따라서 이 windspeed값이 0임을 대체하는 feature engineering 과정이 필요함
⚪️ Feature Engineering
⬜️ 이상치 제거
fig, (ax1, ax2, ax3, ax4, ax5, ax6) = plt.subplots(nrows = 6, figsize = (12,10))
sns.boxplot(data = df, x = 'windspeed', ax = ax1)
sns.boxplot(data = df, x = 'humidity', ax = ax2)
sns.boxplot(data = df, x = 'temp', ax = ax3)
sns.boxplot(data = df, x = 'casual', ax = ax4)
sns.boxplot(data = df, x = 'registered', ax = ax5)
sns.boxplot(data = df, x = 'count', ax = ax6)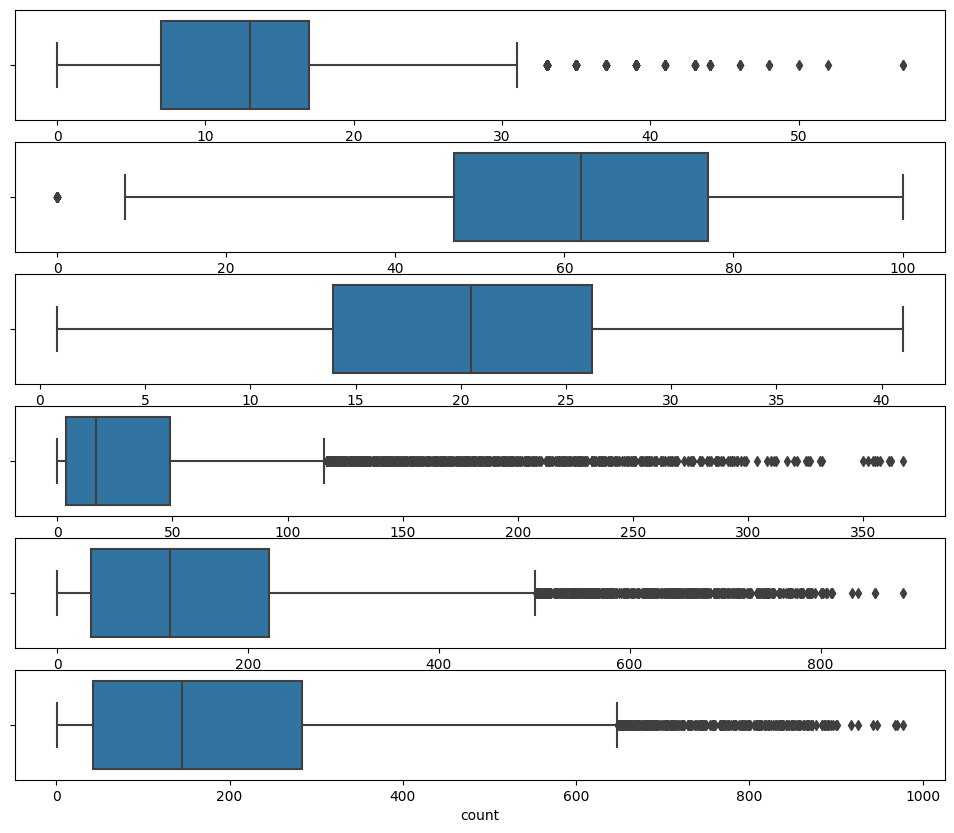
cols = ['windspeed','humidity','temp','casual','registered','count']
def outliers(col,df):
df = df[np.abs(df[col]-df[col].mean())<=(3*df[col].std())]
return df
for col in cols:
df = outliers(col,df)이상치 제거 전 10886-> 이상치 제거 후 10212로 제거하였다
fig,axes = plt.subplots(ncols=2,nrows=2)
fig.set_size_inches(12, 10)
sns.distplot(df["count"],ax=axes[0][0])
stats.probplot(df["count"], dist='norm', fit=True, plot=axes[0][1])
sns.distplot(np.log(df["count"]),ax=axes[1][0])
stats.probplot(np.log1p(df["count"]), dist='norm', fit=True, plot=axes[1][1]) ⬜️ count 변수 정규화
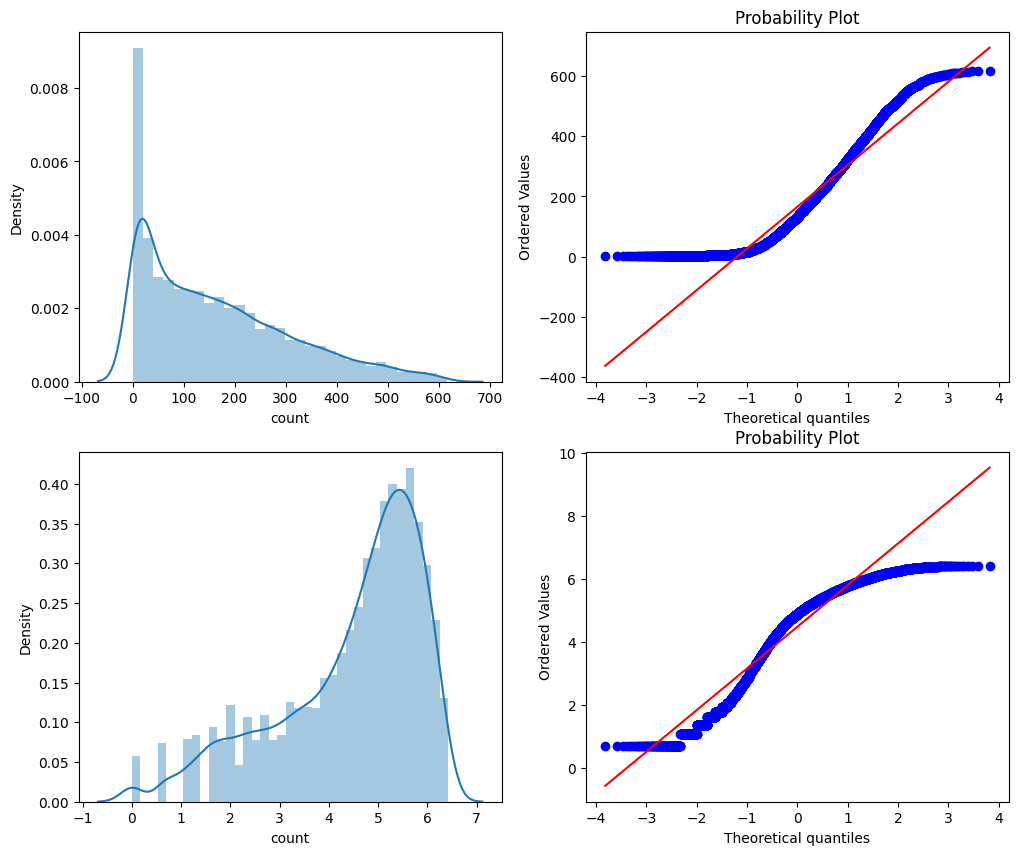
count 값이 0에 많이 치우쳐져 있으므로 log 값 적용을 통해 정규화를 진행하였다.
😶🌫️ windspeed 를 대체할 값 찾기!
- RandomForest를 활용해서 windspeed를 예측하는 값을 찾아준다
- wind는 날씨 변수이므로 날씨 변수인 season,weather, temp, humidiry, day,year 를 활용하여 예측해준다!
from sklearn.ensemble import RandomForestRegressor
data = train.append(test)
datawind = data[data["windspeed"]==0]
datawindnot = data[data["windspeed"]!=0]
rf_clf = RandomForestRegressor()
wind_columns = ["season","weather","humidity","temp","year","day"]
rf_clf.fit(datawindnot[wind_columns],datawindnot["windspeed"])
wind_values = rf_clf.predict(X=datawind[wind_columns])
datawind["windspeed"] = wind_values
data = datawindnot.append(datawind)
data.reset_index(inplace=True)
data.drop('index',inplace = True,axis = 1)⬜️ 범주형 변수 처리
- 원핫 인코딩을 통해 범주형 변수 처리를 해주었다!
- 값이 실제 수치를 의미하는 것이 아닌 애들을 전부 원핫 인코딩으로 처리
data = pd.get_dummies(data, columns = ['holiday','weather','season', 'hour','year','day'])⚪️ 모델 학습
dropFeatures = ['casual',"count","datetime","registered"]
## 이전에 합쳤던 데이터들을 count 값의 유무로 train과 test로 다시 분기
dataTrain = data[pd.notnull(data['count'])].sort_values(by=["datetime"])
dataTest = data[~pd.notnull(data['count'])].sort_values(by=["datetime"])
datetimecol = dataTest["datetime"] ## 나중에 제출할 파일 생성할 때 필요하다
yLabels = dataTrain["count"]
dataTrain = dataTrain.drop(dropFeatures,axis=1)
dataTest = dataTest.drop(dropFeatures,axis=1)# 캐글의 평가지표는 rmsle를 사용하고 있으므로 똑같이 사용한다.
def rmsle(y, y_,convertExp=True):
if convertExp:
y = np.exp(y),
y_ = np.exp(y_)
log1 = np.nan_to_num(np.array([np.log(v + 1) for v in y]))
log2 = np.nan_to_num(np.array([np.log(v + 1) for v in y_]))
calc = (log1 - log2) ** 2
return np.sqrt(np.mean(calc))
🌳 Random Forest
from sklearn.ensemble import RandomForestRegressor
rfModel = RandomForestRegressor()
rfModel.fit(dataTrain,y)
preds = rfModel.predict(X= dataTrain)
print ("RMSLE Value For Random Forest: ",rmsle(np.exp(y),np.exp(preds),False))
- Randomforest를 사용했을 경우 RMSLE 점수가 0.026
🎯 Gradient Boosting
from sklearn.ensemble import GradientBoostingRegressor
gbm = GradientBoostingRegressor(n_estimators=4000,alpha=0.01);
gbm.fit(dataTrain,y)
preds = gbm.predict(X= dataTrain)
print ("RMSLE Value For Gradient Boost: ",rmsle(np.exp(y),np.exp(preds),False))
- Gradient Boosting을 사용했을 경우 RMSLE 점수가 0.19
😛 랜덤 포레스트 모델을 활용하여 테스트 데이터를 넣어 제출할 파일을 생성하자!
preds = rfModel.predict(X= dataTest)submission = pd.DataFrame()
submission['datetime'] = datetimecol
submission['count'] = np.exp(preds)
submission
예측값은 로그를 취한 값이므로 거꾸로 exp를 취해준다
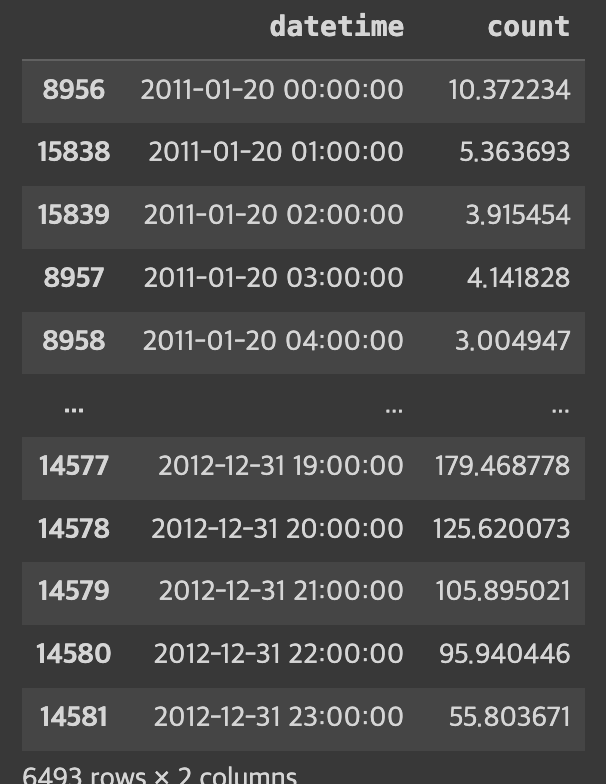
이제 캐글에 submission 파일을 제출하면 된다!
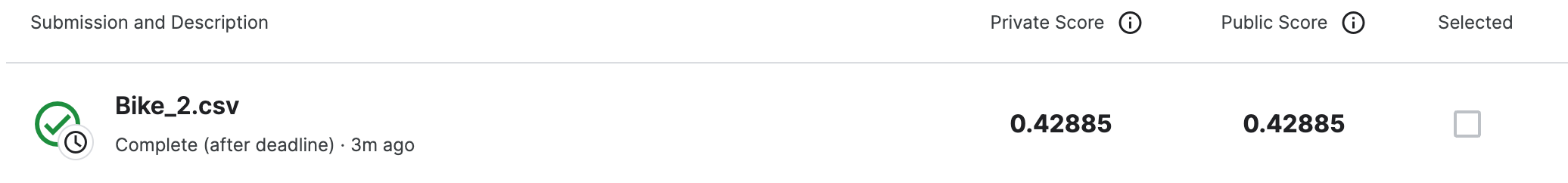
점수는 0.428... 이 나왔다 (ㅎ)
조금더 데이터를 다루며 새로운 변수를 생성하든.. 새롭게 전처리를 하면 조금더 잘나오지 싶다 .
https://www.kaggle.com/competitions/bike-sharing-demand/overview
