구글에서 발표한 BERT language model에 대한 리뷰이다.
0. Abstract
BERT는 이전 language representation model과 달리 unlabeld corpus를 통해 모든 layer에서 bi-directional 문맥을 이용해 deep bidirectional representations를 미리 학습한다. 그리고 이렇게 pre-trained된 BERT를 하나의 layer를 추가하면서 task에 맞게 학습시킨 결과, 수많은 task에서 SOTA를 달성했다. (Google의 역작이자 현재 많은 model의 base가 되고 있는듯 하다.)
1. Introduction
이 시점의 NLP분야에서 language model의 pre-training은 여러 task에서 좋은 성능을 보여줬다. Pre-trained된 representation을 downstream task에 적용하기 위한 두가지 방법이 있다.
1.1 Feature-based approach
먼저 이전 language model인 ELMO는 feature-based 방법을 사용하는 대표적인 model인데, pre-trained된 representation을 추가적인 feature로 사용하는 방법이다. 쉽게 말하면, embedding은 update 하지않고 그 위에 추가된 layer만 따로 학습시키는 방법이다.
1.2 Fine-tuning approach
Fine-tuning을 사용한 language model로는 GPT가 있는데, 이는 fine-tuning할 때, task에 사용되는 parameter가 적으므로 pre-trained된 parameter를 fine-tuning함으로 써 downstream-task를 학습하는 방식이다. 다시 말하면, 모든 paramter를 미세하게 조정하고, embedding까지 update하는 방법이다.
BERT는 대용량의 unlabeled corpus로 pre-train하고 task에 맞게 transfer-learning을 진행한다.
2. Related Work
2.1 Unsupervised Feature-based Approaches
BERT 이전에 word 단위의 representation을 학습하는 방법은 neural 방법(Word2Vec, FastText, Glove...)과 non-neural 방법이 존재했다. 이러한 pre-trained word embedding은 NLP분야에서 엄청난 성능 향상을 가져왔고 이러한 word embedding vectors를 학습하기 위해서는 left-to-right LM objective가 사용되었다.
그러나 ELMO는 regressive하게 학습되는것이 아닌, 양방향으로 학습되어 문맥을 모두 고려한 word embedding을 제공할 수 있었다. 이러한 학습방법으로 ELMO는 여러 task에서 SOTA를 달성할 수 있었다.
또한, 2016년에 Melamud et al.는 LSTM을 통해 양방향으로 contextual한 representation을 학습하는 방법을 제안했는데, 이 방법 또한 역시 ELMO와 비슷하게feature-based한 방법론이다.
2.2 Unsupervised Fine-tuning Approaches
이전 feature-based 방법과 달리 최근에는 unlabeled corpus를 통해 pre-trained된 contextual representation을 만들고, downstream task에 맞게 fine-tuning하는 방법이 등장했다. 이러한 방법의 장점은 학습의 시작부터 종료까지 적은 수의 parameter를 학습시키면 되고, GPT는 이러한 방법을 이용해 많은 benchmark에서 SOTA를 달성했다.
2.3 Transfer Learning from Supervised Data
대규모의 dataset을 가지고 있는 task인 natural language inference, machine translation
뿐만 아니라, Computer vision에서도 transfer-learning이 두각을 드러내고 있다.
3. BERT
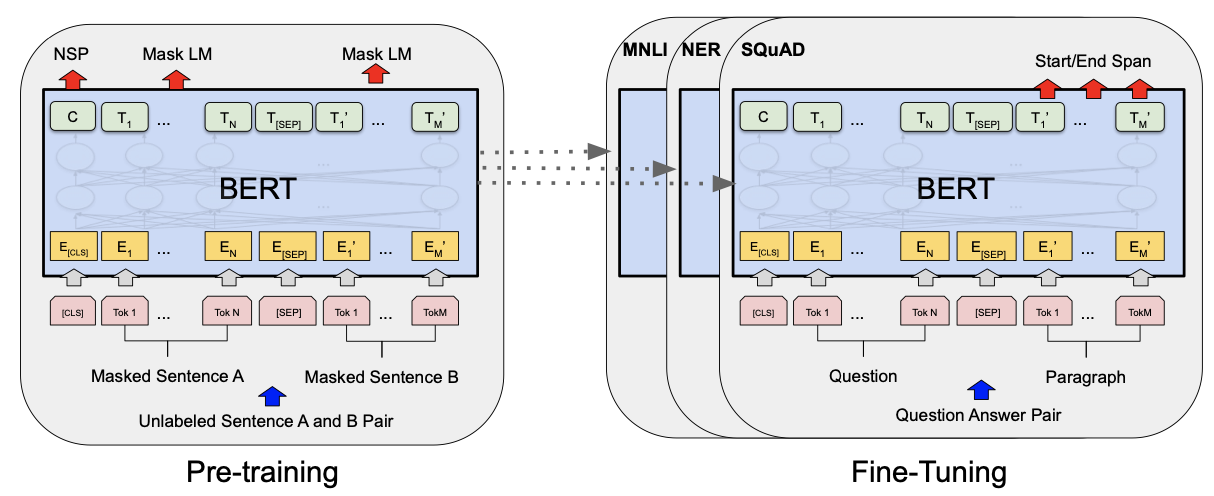
먼저 BERT의 학습 방법은 unlabeled corpus로 pre-train하여 contextual representation을 학습한 후, 각 downstream task에 맞게 fine-tuning한다. 이때, fine-tuning과정에서 BERT는 pretrain된 parameter를 initial weight로 갖고 훈련을 시작한다. 그리고 fine-tuning을 진행하면서 parameter는 task에 맞게 update된다. 결론적으로 pre-trained된 BERT와 fine-tuning된 BERT는 구조적인 차이는 없다.
3.1 Model Architecture
BERT는 기본적으로 multi-layer bidirectional Transformer encoder구조를 가지고 있다. 그리고 본 논문에서는 두가지 크기의 BERT를 제안했다.
L : Transformer-Encoder Block Layers
H : Hidden Size
A : Number of Self-Attention Heads
는 Open-API의 GPT와 똑같은 크기로 만들어졌다. 여기서 GPT와 BERT의 차이점으로는 GPT는 transformer의 decoder로 구성된 LM으로 auto-regressive하지만, BERT는 transformer의 encoder로 구성되어있어 bi-directional하게 학습된다는 점이다.
3.2 Input / Output Representations
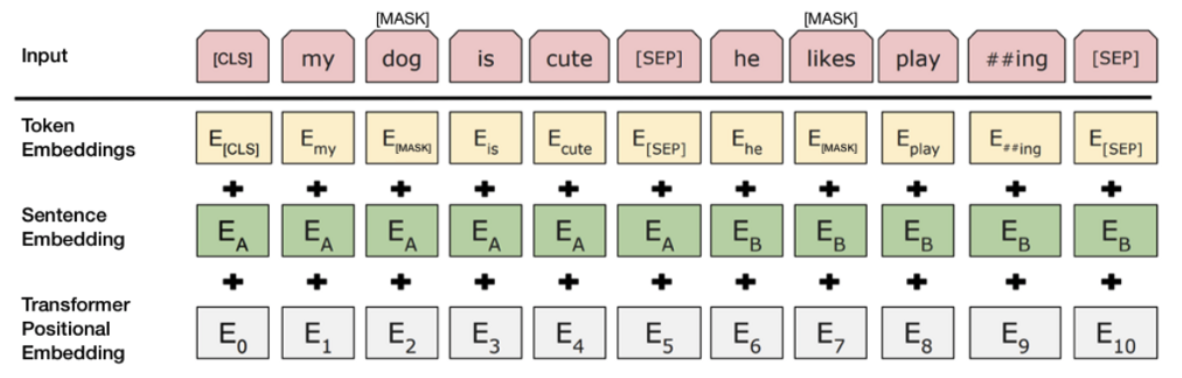
BERT의 input은 Token Embedding, Segment Embedding, Position Embedding이다. Token embedding은 실제 단어에 대한 embedding이고 segment embedding은 몇번째 sentence인지에 대한 embedding이고 position embedding은 몇번째 token인가에 대한 embedding이다.
기존 transformer는 RNN과 달리 병렬처리로 이루어져있기 때문에 순서에 대한 정보를 추가하기 위해 position embedding을 추가했다.
BERT는 input으로 최대 2개의 sentence를 넣을 수 있는데 이를 위해 [SEP] token을 추가했다. 이는 task 중에서 Q/A와 같이 두개의 sentence에 대한 task도 처리할 수 있게 하기 위함이다.
본 논문에서는 3만개의 token을 가진 WordPiece embeddings를 사용하고 모든 sequence의 첫 번째 token은 [CLS]이다. 이 [CLS] token을 통해 마지막 layer의 최종 output에서 [CLS] token과 대응되는 값은 classification을 처리하기 위해 sequence representation을 종합해서 담게 된다.
4. Pre-trainig BERT
기존 학습 방법인 left-to-right, right-to-left LM과는 다르게 BERT는 2개의 unsupervised task를이용해 학습한다.
4.1 Masked LM
기존의 pre-train 방법인 left-to-right, right-to-left LM은 단순하게 연결했기 때문에 제대로 된 bi-directional context를 반영하지 못했다. Bi-directional하게 학습하려면 앞선 단어를 참조하게 되고 multi-layered 구조에서는 해당 token을 예측할 수도 있기 때문에 어려웠다. 그래서 BERT에서는 일정 비율의 token을 MASK 처리하고 학습을 진행했다. 논문에서는 전체 token의 15%를 MASK 처리했다.
이러한 task는 pre-train할 때, contextual하게 잘 학습할 수 있지만, 실제로 fine-tuning할 때는 [MASK] token이 존재하지 않기 때문이다. 이러한 불일치 문제를 해결하기 위해서 15%의 token 중 80%를 [MASK] token으로 치환하고 10%는 random token으로 치환하고 나머지 10%는 기존의 token을 그대로 사용했다. 최종적으로 실제 token인지 아닌지를 cross-entropy loss를 통해 학습된다.
4.2 Next Sentence Prediction (NSP)
두 문장 사이의 관계와 이해를 학습해야하는 task인 Question-answering(QA), Natural Language Interference(NLI)에서는 기존 LM의 학습 방법으로는 제대로 된 학습이 쉽지 않다. 그래서 BERT는 NSP라는 task로 sentence level에서도 학습을 진행한다. NSP란 두 문장이 서로 연결된 문장인지 아닌지를 binary classification으로 학습이 진행된다. 50%의 확률로 Next, not Next의 data를 생성한 뒤, [CLS] token을 통해 학습된다.
4.3 Pre-training data
본 논문에서는 BERT를 pre-train하기 위해 BookCorpus와 Wikipedia data를 사용했다. Wikipedia의 경우 text passage만을 사용했고 content, table의 경우는 모두 제거했다. 또한 긴 context를 학습하기 위해 Billion Word Benchmark와 같이 섞인 sentence를 가진 data도 제거했다.
5. Fine-tuning
Fine-tuning은 pre-train과 달리 빠른 학습 시간을 가진다.(해당 논문에서는 Gloud의 TPU에서 1시간 혹은 GPU에서 짧은 시간내에 처리할 수 있다고 한다.) 이 과정으로는 먼저 input의 개수에 따라 sentence를 하나의 sequence로 넣게 된다. 두 문장이 input으로 들어가면, 하나의 sequence이기 때문에 그 두 문장 사이에서 self-attention을 진행하게된다. Fine-tuning하는 방법으로는 task에 맞게 input과 output을 model에 집어넣고 parameter를 task에 맞게 조정한다. Token representation은 token level task의 입력으로 들어간다. [CLS] token은 classification task를 수행하기 위해 사용된다.
6. Experiments
6.1 GLUE benchmark
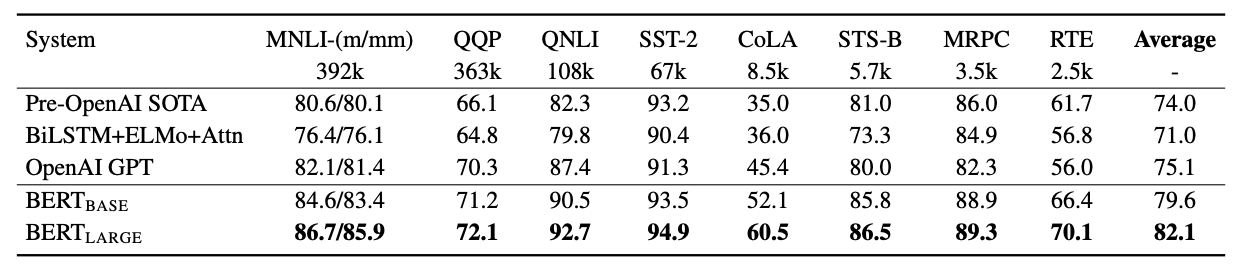
본 논문에서는 11개의 downstream task에 대해서 fine-tuning을 진행했다.
GLEU(General Language Understanding Evaluation) benchmark dataset는 다양한 language understanding task를 포함하고 있다. BERT가 모든 task에서 좋은 성능을 보여줬다.
6.2 SQuAD
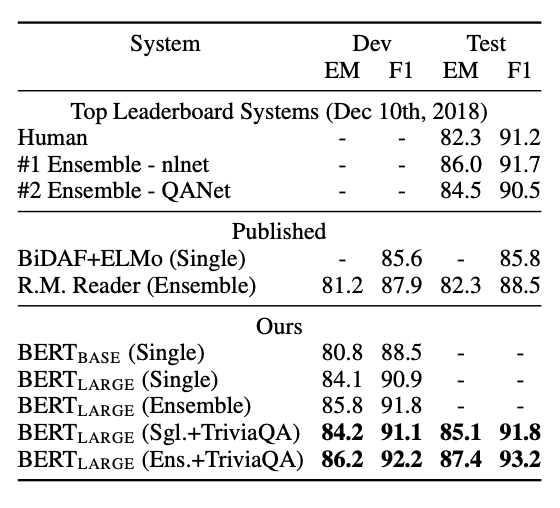
두 번째 실험은 question & answering benchmark dataset인 SQuAD에서 실험한 결과입니다. 이 실험에서는 Wikipedia의 dataset에서 답을 포함하고 있고 context의 지문을 통한 task를 진행합니다.
BERT는 기존의 모델보다 더 좋은 성능을 보여줬고, 가장 성능이 좋았던 모델은 Trivia Q&A dataset을 fine-tuning한 모델이다.
6.3 SQuAD 2.
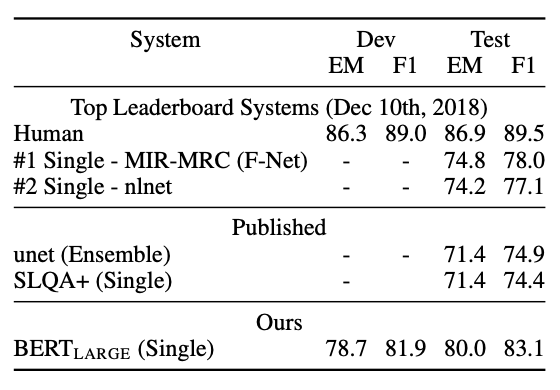
다음은 SQuAD 2.0 dataset에서 진행한 실험으로 답이 지문에 존재하지 않는 실험이다.
인간의 성능보다는 부족하지만 좋은 성능을 보여줬다.
6.4 SWAG
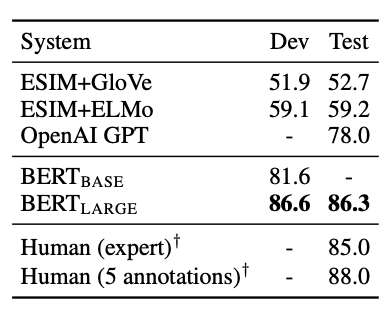
다음 실험은 SWAG(Situations With Adversarial Generation) dataset에 대한 실험으로 문장의 pair를 추론하는 task이다. 본 실험은 위해 4개의 input sequence를 구성했다고 한다. (두개의 문장과 CLS token과 SEP token)
BERT는 전문가를 뛰어넘는 성능을 보여줬다.
6.5 Ablation Study
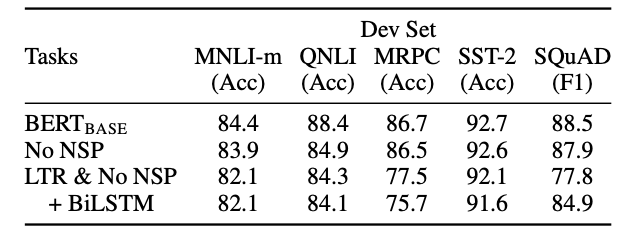
다음 실험은 Ablation study로 3가지 설정을 나누어 성능을 비교했다.
- BERT-base (NLN & NSP)
- No NSP(MLM)
- LTR & No NSP (no BERT, Left to Right)
모든 검증 dataset에서 BERT(MLM & NSP)가 가장 우수한 성능을 보여준다.
6.6 Effect of Model Size
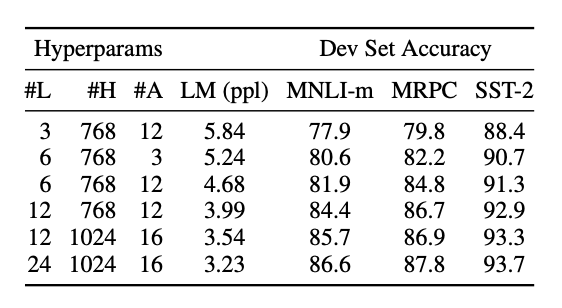
L : Numbers of Layer
H : Hidden size
A : number of attention head
LM : perplexity
Model의 size가 커질수록 더 좋은 성능을 보여주고 있다. 그러나 1024 size보다 커진다면..?
6.7 Feature-based Approach with BERT
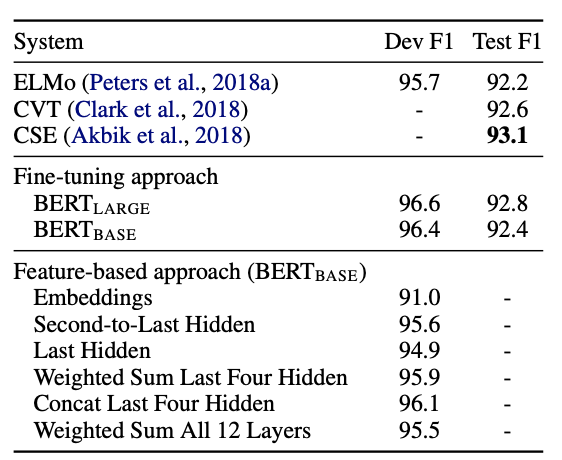
마지막 실험은 BERT를 fine-tuning 방법을 사용했을 때와 feature-based 방법을 사용했을 때 결과를 비교한 실험이다.
- only Embedding
- 뒤에서 두번째 Hidden
- 마지막 Hidden
- 마지막 4개의 Hidden weight sum
- 마지막 4개의 Hidden concat
- 모든 layer weight sum
Feature-based 방법에서 실험을 진행했을 때, 마지막 4개의 layer를 concat했을 때 성능이 제일 좋았다. 비슷한 성능을 보여주므로, BERT는 두개의 접근 방법에서 모두 우수한 model임을 알 수 있다.
