오늘 가져온 논문은 2017년 구글팀이 발표한 Get to the Point : Summarization with Pointer-Generator Networks 입니다.
0. Introduction
먼저 summarization이란 글에서 중요한 정보를 뽑아 간략하게 간추리는 task를 의미합니다. summarization에는 기본적으로 두가지 methods가 존재합니다.
-
Extractive Method : Source text에 나와있는 word를 선택하고 추출해서 요약하는 방법
-
Abstractive Method : 자연어 생성 기술을 활용하여 기존 text에 문장을 새로운 문장으로 생성해 요약하는 방법
당시에는 RNN을 기반으로 하는 Abstractive Method가 등장하기 시작했습니다. 그러나 기존의 Methods들은 몇가지 문제점을 가지고 있었습니다.
-
부정확한 내용
-
corpus에 등장하지 않는 단어를 사용했을 때 out-of-vocabulary 문제
-
동일한 구문 반복

위에서 보면 oov를 해결하지 못해 'UNK UNK'가 나와있는것을 확인할 수 있고 'in the northeast part of nigeria'가 반복적으로 사용되어 요약의 질이 안좋은것을 확인할 수 있다.
이 논문에서는 Pointer-Generator Network를 통해 out-of-vocabulary 문제를 해결하려고 했고 Coverage Mechanism을 이용하여 특정한 단어와 문장이 반복되는 문제를 해결하려고 했습니다.
1. Pointer Generator Networks
1.1 Sequence-to-sequence attentional model
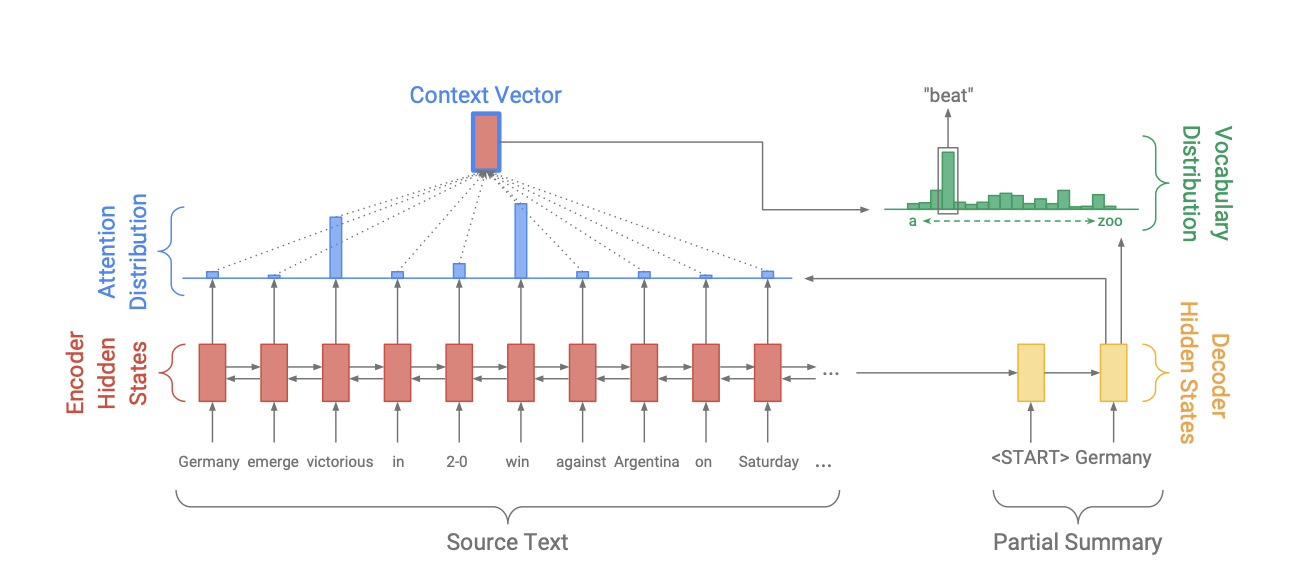
먼저 baseline model로 이용되는 seq2seq attention model를 간략하게 설명하겠습니다. 이 model은 encoder, decoder, attention distribution와 context vector, vocabulary distribution으로 구성되어있습니다.
단일 layer 양방향 LSTM을 사용하는 encoder는 토큰()을 하나씩 입력 받아서 encoder의 hidden state()의 sequence를 만듭니다. 단일 layer 단방향 LSTM으로 구성된 decoder는 이전에 만든 단어의 embedding과 decoder의 hidden state()를 입력으로 받아 다음 단어를 출력합니다.
Attention의 경우 바다나우(Bahdanau)어텐션을 이용합니다. decoder의 기준으로 attention distribution()는 다음과 같습니다.
(, , , 은 학습가능한 parameter입니다.)
(는 decoder 시간의 attention weight입니다.)
이렇게 얻은 decoder는 현재 어디에 집중을 해야될지에 대한 정보가 담긴 와 encoder의 hidden state와 가중합을 통해 context vector()를 만듭니다.
context vector는 현재 시점에서 source로부터 어떤 토큰을 받았는지에 대한 vector로 t시점 decoder의 hidden state와 합쳐 두 선형 layer를 거쳐 최종적인 단어 분포 을 만듭니다.
1.2 Pointer generator network
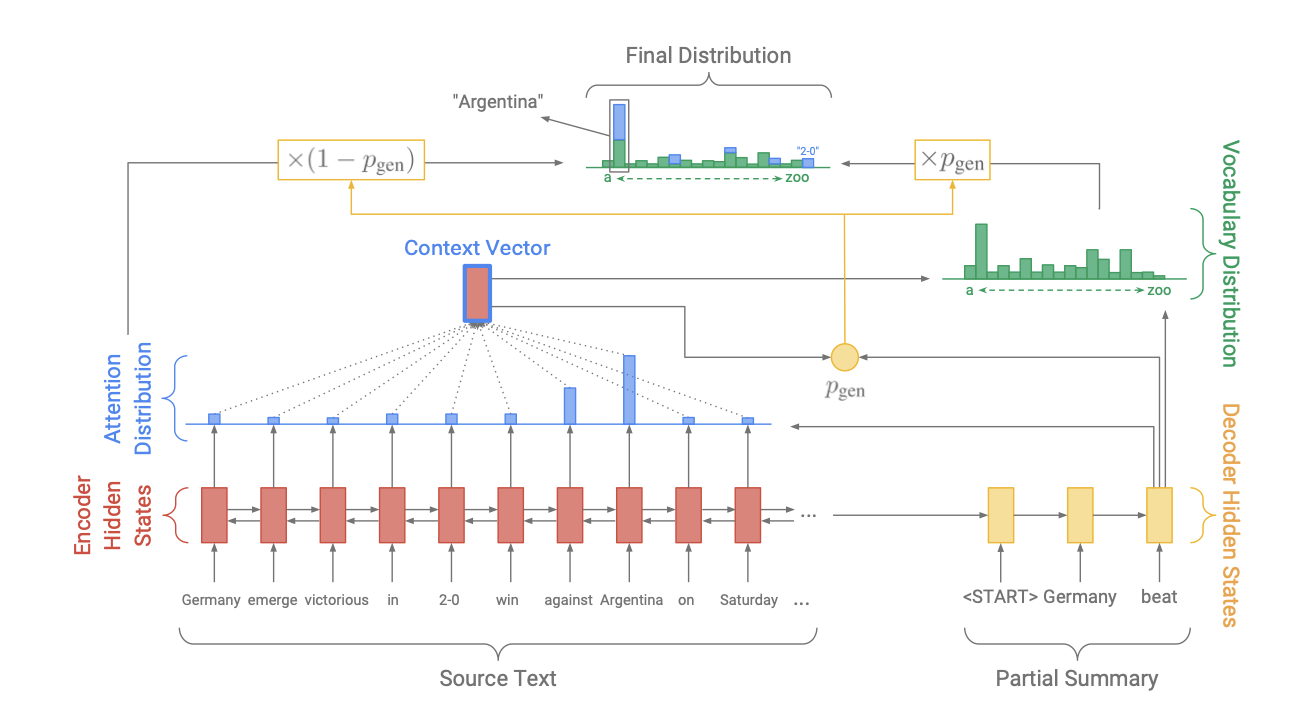
이 논문에서는 baseline model만 사용했을시에 발생하는 oov 문제를 해결하기위해 pointer-generator-network를 도입했습니다. 앞선 baseline model에 사용한 attention distribution과 context vector는 동일하게 사용했고 이것을 기반으로 t시점의 생성확률 generatoinal probability() 생성합니다. 는 context vector, 는 decoder의 hidden state, 는 decoder input값이고 는 sigmoid 함수입니다.
generatoinal probability()은 model을 기반으로 한 단어 목록에서 다음 토큰을 만들(abstractive summarization) 확률이라고 생각하시면 됩니다. 반대로 은 source에서 단어를 그대로 가져오는 (extractive summarization) 확률을 의미합니다. generatoinal probability는 soft-switch 역할을 하게 되는데 다시말하면 이 1에 가까우면 encoder-decoder 기반의 model로 생성된 단어들을 통해 summarization을 수행하도록 하고 0에 가까우면 source로 부터 summariation을 하게됩니다. 이 확률을 최종적으로 다음과 같이 활용합니다.
가 어떤 단어가 올지에 대한 확률이고 만약 가 out-of-vocabulary라면 값은 0이 되고 가 source document에 없는 단어라면 동일한 단어가 등장할 합이 0이됩니다.
기존에는 vocabulary distribution만 고려하여 단어가 없으면 밑에 그림을 보시면 고유명사와 같은 oov가 발생했지만 pointer-generator network를 이용해서 oov의 문제가 있을경우 source document에서 단어를 가져오게 됩니다.

2. Coverage Mechanism
본 논문에서는 특정한 단어와 문장들이 반복되는 문제를 해결하기위해 coverage mechanism을 이용해 일종의 penalty을 걸어 loss에 반영했습니다.
먼저 decoder의 t시점에서 coverage vector는 시점까지 사용한 모든 attention 분포의 합으로 정의합니다. coverage vector는 t시점까지의 해당 단어가 얼마나 많은 attention을 받았는지에 대한 정보라고 볼 수 있습니다.
기존 decoder의 attention weight를 구하는 구조는 t 이전 시점에 대한 attention 정보가 없었는데 이 구조에 coverage vector를 추가하게 되면 이전시점 까지의 attention이 반영되기 때문에, 반복되는 문제를 해결할 수 있습니다.
이 penalty를 loss에 적용할 수 있습니다. t시점의 coverage loss는 그 시점의 각attention 원소와 각 coverage vector 원소의 최소의 합으로 구할 수 있습니다. 특정 단어가 많이 사용되어 coverage vector값이 높아도 attention mechanism에 coverage vector가 들어가있어 penalize되어 attention 값이 고르게 분포하게 됩니다.
t시점의 전체 loss는 기존 loss에 하이퍼파라미터 람다의 곱으로 정의됩니다.
3. Experiments
3.1 Dataset
본 논문에서는 CNN과 Mail Data를 사용했습니다. 이 data는 276,226개의 train data와 13,368개의 vaidation data, 그리고 11,490개의 test data로 이루어져있습니다. 이 논문에서는 어떤 종류의 전처리도 사용하지 않았습니다.
3.2 Model Specifications
실험을 위해 다음과 같은 설정을 했습니다.
- 256차원의 hidden state, 128차원의 word embedding
- Pointer model은 50k의 단어를 사용
- pretraining 하지 않은 word embedding
- adagrad(learning rate = 0.15, initial accumulator = 0.1)로 학습
- gradient clipping(maximum norm2) 적용 -> gradient exploding을 방지
- early stopping을 사용
- train과 test중 입력되는 글의 토큰은 최대 400개로 앞에서부터 추출
- 요약문의 학습은 최대 100토큰, test는 최대 120 토큰으로 설정
- Tesla k40m GPU, batch size 16
- test는 beam size4, beam search 적용
3.3 Metrics
< Rogue >
-
summuraization에서 성능을 평가하기 위한 지표
-
model이 생성한 summary와 reference를 대조하여 scoring
-
precision과 recall을 이용하여 scoring
-
ROGUE-1 : 겹치는 unigram의 수
-
ROGUE-2 : 겹치는 bigram의 수
-
ROGUE-L : 최장 길이로 matching되는 문자열 측정
< METEOR >
- 생성된 text와 reference를 단어의 일대일 mapping을 계산
- 이러한 mapping을 기반으로 F-score를 계산
3.4 Evaluate
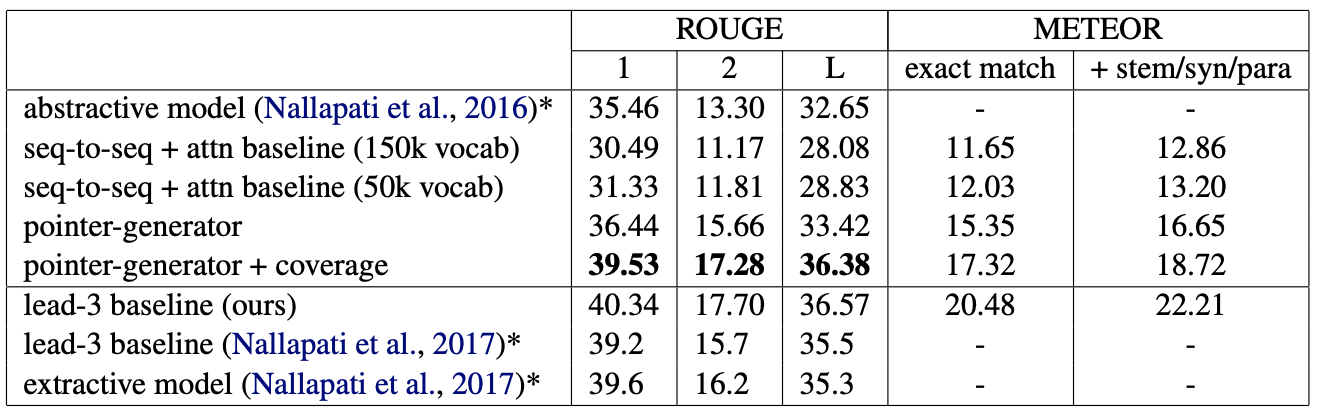
pointer-generator network model 외에 몇가지 모델들이 추가되어 비교되었습니다.
- 글의 첫 세 문장을 요약으로 가져오는 lead-3 baseline
- extractive method models
- abstractive method models
위에 표는 몇가지의 결과를 시사한다.
-
seq-to-seq + attenion mechanism model의 성능 < pointer generator network model의 성능 < pointer generator network + coverage mechanism model의 성능
-
Abstractive model의 성능 증가폭이 extractive model의 성능 증가폭보다 크다.
Experiments에서 사용한 baseline model과 비교해서 ROGUE와 METEOR에서 모두 pointer generator model이 더 높았습니다.
4. Implication & Conclusion
4.1 Abstractive
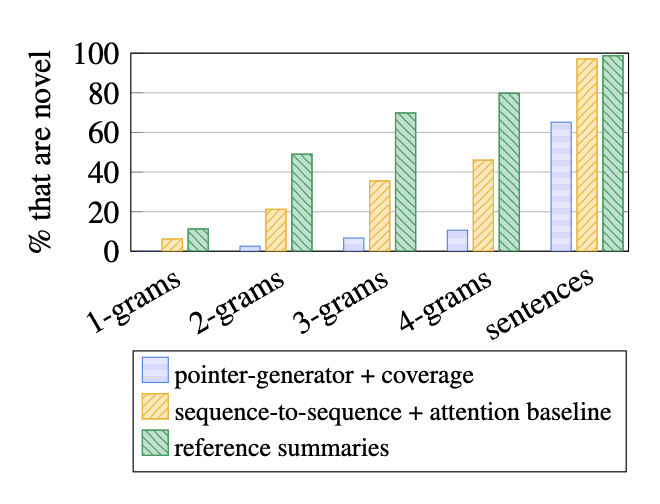
위의 그림은 얼마나 reference에 없는 단어를 생성했는지 보여주고 있습니다.위 막대 그래프는 reference에서 가져온 단어의 비율을 보여주는데 pointer-generator + coverage모델이 제일 적은것을 확일할 수 있습니다.
4.2 Coverage Mechanism
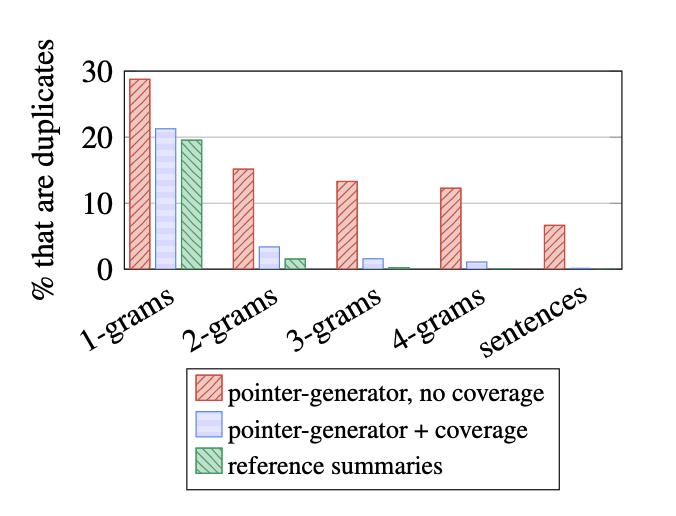
그래프를 보면 coverge mechanism을 사용하면 coverage를 도입한 모델이 실제 label과 비슷하다는것을 확인할 수 있습니다.
4.3 Abstractive vs Extractive
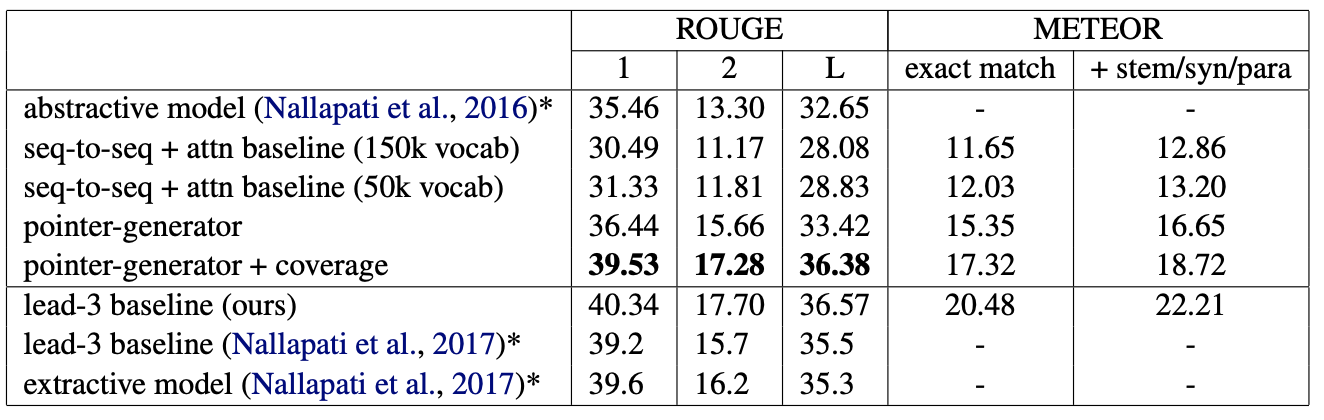
pointer generator network와 coverage mechanism까지 도입한 model이 lead-3 baseline(ours)와 extractive model보다 점수가 낮은것을 확인할 수 있었다. 논문에서는 뉴스는 두괄식으로 앞부분에 중요한 단어와 문장들이 있어 lead-3 model의 점수가 높게 나온다는 점과 앞서 설명한 ROGUE Metrics는 겹치는 토큰에 대해서 점수를 부여하기 때문입니다. 그러한 이유로 METEOR Metrics도 관찰하였지만 lead-3 model의 점수가 역시 높았는데 뉴스 데이터의 style 때문이라고 합니다.
4.4 conclusion
pointer generator network + coverage mechanism model이 요약의 질을 높여주고 seq-to-seq + attenion mechanism model보다 성능이 좋은것은 맞지만 다른 extractive model보다 성능이 안좋은것으로 보아 항상 좋다고 보는것은 어렵다고 생각이 들고 각 topic과 document style에 맞게 요약 방법론을 채택하여 사용하는것이 바람직하다고 생각합니다.
5.reference
https://www.youtube.com/watch?v=jjzGrz_plbk&t=802s
https://www.koreascience.or.kr/article/CFKO201832073078595.pdf
https://3-24.github.io/machine%20learning/PGN/
https://research.google/pubs/pub46111/
