Transformer 경량화 개인 연구에 clustering을 기반으로 한 attention을 추가할 계획으로 본 논문 리뷰를 진행했다.
0. Abstract
최근, Transformer의 Self-Attention의 연산량을 효과적으로 줄일 수 있는 방법으로 "sparse pattern based"방법이 많이 사용되고 있다. 그러나 보통 이러한 방법은 유사도를 고려하지 않고 고정된 pattern을 기반으로 token을 선택한다. 또한 이전 방법은clustering process가 train 과정에 포함되어 있지 않아 "효율"적인 방법과는 거리가 멀었다. 본 논문은 앞서 설명한 한계점을 해결하기위해 neural clustering method를 설계했다. Clustering task와 target task는 joint되어서 학습이 진행되고 각각 서로에게 benefit을 주며 최적화된다. 추가적으로, 본 논문의 방법은 단어를 group(clustering)할 때, 서로 연관성이 많은 단어들끼리 clustering하고 각 cluster를 독립적으로 attention 연산을 진행하면서 성능을 끌어올렸다. 다양한 task에서 성능을 검증했으며, 다른 effcient기반의 transformer 모델과도 성능을 비교했다.
1. Introduction
Transformer는 NLP뿐만 아니라 다른 domain에서도 좋은 성능을 보여주고 있지만, 효율적인 모델로 보기는 힘들다. (Self-Attention의 연산량이 가장 큰 이유)
먼저 이러한 연산량을 low-rank approximation 기반의 방법을 통해 선형으로 증가하는 연산량의 attention 방법이 많이 연구되었다. 그 중 가장 대표적인 모델로 Linformer로 key와 value의 길이를 낮은 차원으로 로 projection하여 연산량을 로 감소시켰다. 그러나 이러한 방법은 low dimension으로 projection할 때 고정된 상수 길이의 data가 필요하기 때문에 다양한 길이의 데이터에 대해서는 적용하기 어렵다는 한계점이 존재한다.
다음으로 Sparse pattern based 방법으로 key와 query vector의 개수를 제한하면서 일부만 attention 연산을 거치며 연산량을 줄이는 방법이다. 대표적으로 Sparse Transformer가 있는데, 이는 query의 고정된 interval에 존재하는 key vector와만 attention을 진행하는 방법을 사용한다. 이러한 pattern은 query와 key의 유사도를 전혀 고려하지 않으므로 성능이 많이 떨어진다.
더 최근에는 clustering sparse pattern을 사용하는 Reformer와 Route Transformer가 등장했다. 이는 각각 LSH(Locality Senstive Hashing)과 K-Means 알고리즘을 통해 전체 sequence를 각각 다른 cluster로 나누고 attention 연산을 진행한다. 이러한 방법을 통해 각각 와 의 연산량으로 attention을 진행할 수 있다. 그러나 이러한 방법에도 한계점이 존재하는데 network를 학습하는데 있어 clustering과 attention이 각각 따로 진행된다는 점이다.
또한, LSH와 K-Means는 attention과 clustering하는데 기준이 되는 유사도의 기준이 다르다는 점이다. Attention은 dot-product를 통해 유사도를 계산하지만, LSH는 무작위 값인 hash로 partioning하고 K-means는 유클리디안 거리로 유사도를 계산하기 때문이다. 결론적으로 효율적으로 보기 어렵다.
따라서 본 논문에서는 sparse attention 또한 효율적으로 학습이 가능한, Neural Clustering Method를 도입했다. 본 논문에서는 cluster의 center(centroid)가 word의 hidden state의 weighted sum으로 update된다. 같은 시점에 cluster의 member는 하위 matrix(centroid, word hidden state)로 나뉘어진다. 따라서 모델의 cluster loss를 optimize할 때, word의 hidden state도 같이 optimize할 수 있다.
기존 Reformer와 Route Transformer의 메모리 사용량이 53.8%, 60.8%일 때, ClusterFormer는 31.8%이다.
2. Model
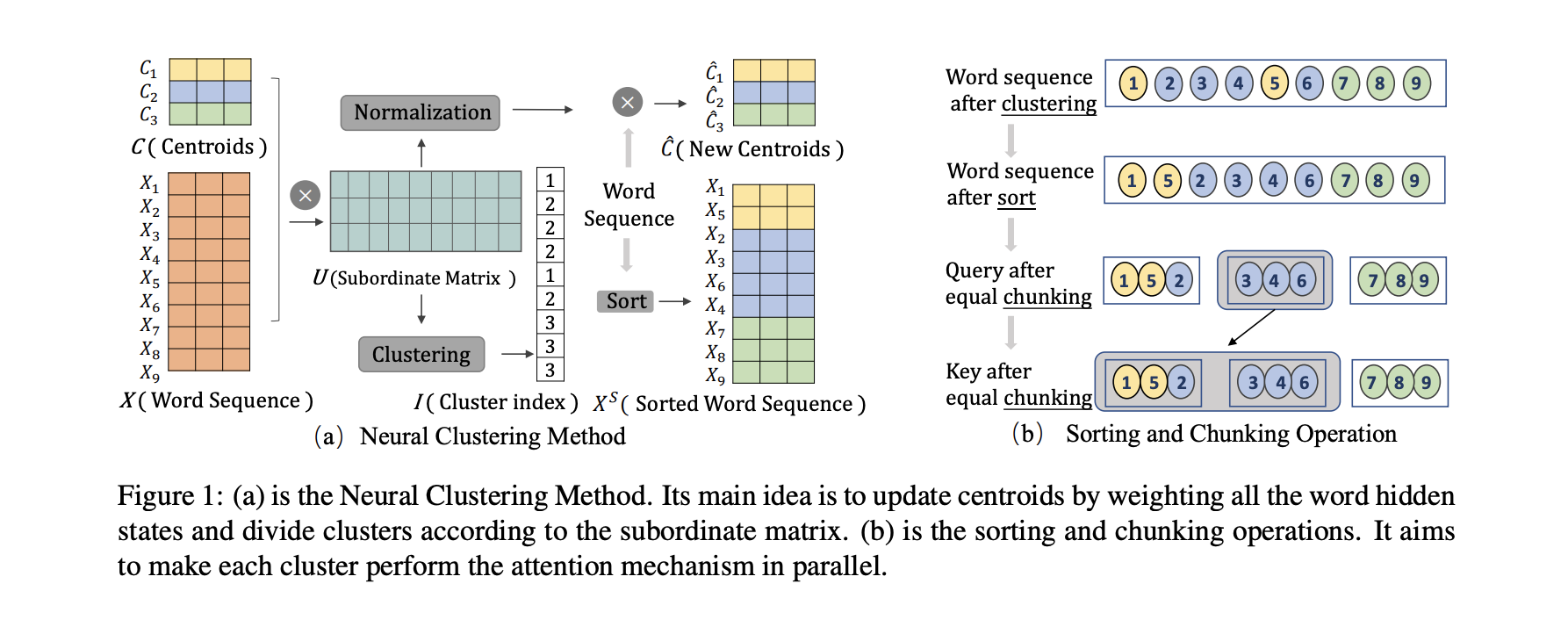
이 파트에서는 Clustering Attention과 Self-Attention의 mechanism을 결합한 Neural Clustering Attention Mechanism에 대해서 소개한다.
2.1 Neural Clustering Mechanism
본 논문의 model은 input으로 word hidden state 와 centroid hidden state 가 들어간다. 이때 는 first layer에서 random으로 초기화된다. 다음으로 하위 matrix 는 와 의 유사도로 정의된다.
이때 는 cluster의 개수, 은 sequence의 length, 는 weight, 는 dot-product operation이다. 는 의 번 째 row matrix, 는 의 번 째 row matrix이다. 그리고 하위 matrix 는 centroid와 word의 유사도를 나타낸다.
다음으로 모든 word hidden state를 weighting하면서 update centroid를 얻을 수 있다.
다음으로 에 따라서 word vector들을 grouping한다.
는 matrix 의 번 째 column이고 는 vector의 값을 최대화하여 word hidden state를 cluster에 할당한다.
다음으로 word vector들을 Sort함수를 통해 같은 cluster들 끼리 나열될 수 있게 한다.
Clustering Loss
Clustering loss 은 word hidden state와 centroid의 negative similartity score의 평균이다.
이때 와 는 각각 번 째 word hidden state와 update된 centroid를 의미한다.
2.2 Neural Clustering Attention Mechanism
이전 section에서 Neural Clustering Method는 word vector들을 강력한 dependency를 기반으로 grouping한다. 그 결과값인 를 이후 , , 로 projection한다.(query, key, value)
이때 self attention을 병렬적으로, 즉 multi-head self attention을 하기 위해선 cluster 내 member의 개수가 같아야하지만, 다를 수 밖에 없어 그대로 진행하기는 힘들다. 병렬적으로 계산하기 위해서 word hidden vector를 arranging한 후 동일한 block에 chunking한다.
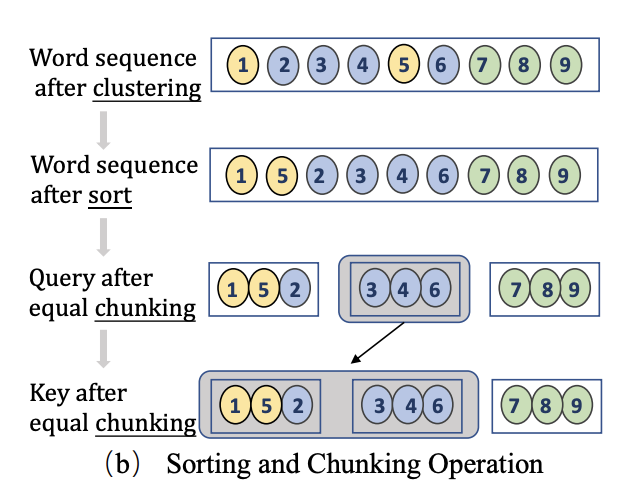
그림과 같이 block내 같은 수 만큼 word vector를 chunking한다.
이때 이고 는 각각 query와 key의 block을 나타낸다. 이때 key가 인 이유는 그림 상 첫 번째 block에는 서로 다른 cluster가 들어가 있기 때문으로 본다.
다음으로 attention 연산이 진행되고 concat된다.
마지막으로 sort된 sequence를 shuffle한다.
이때 는 sort된 sequence를 기존 sequence의 순서로 맞추기위한 함수로 position이 기록된 를 통해 진행된다.
Clustering Sorting Loss
Centroid Sorting Loss는 adjacent centroid pair에 대한 negative similarity scores의 평균이다.
위와 같은 식을 통해 하나의 query block이 두개의 연속된 block의 token에 대해서 집중할 수 있게 한다. 는 같은 인접한 cluster와 더 가깝게 만들어 줄 수 있다.
2.3 Analysis of Complexity
본 논문의 Neural Clustering Attention Mechanism은 두개의 part로 complexit를 설명할 수 있다.
-
Neural Clustering Method : 하위 matrix의 centroid hidden states 와 word hidden states 의 dot product로 연산량은 로 정의할 수 있다.
-
Attention Mechanism : Query block 과 key block
따라서 총 연산량은 이다. 이때 가 이라면 이다.
3. Experiments
Reformer와 Routing Transformer와의 확실한 비교를 위해서 attention mechanism이외의 다른 layer들을 통일했다.
3.1 Machine Translation
두개의 Dataset에 대해서 성능을 검증했다.
- IWSLT14(German - English)
- WMT14(English - German)
IWSLT14의 경우 160k의 training sentence pairs를 포함하고 있고, WMT의 경우 4.5 million training sentence pairs를 포함하고 있다.

Encoder와 decoder의 경우 6개 layer를 배치했고 centroid는 3개로 설정했다. Model의 dimension은 512이고 head의 개수는 8개이다. BLEU score로 성능을 비교했을 때 더 좋은 성능을 보여줬다.(연산량이나 parameter수도 비교했으면 좋았을듯...)
3.2 Text Classification
분류 task에서는 5가지 dataset에 대해서 실험을 진행했다.
- CR: Customer Review(positive or negative)
- MR : Movie Review(positive or negative)
- SUBJ : Subjectivity dataset(subjective or objective)
- MPQA : Opinion polarity detection subtask
- 20NEWS : A international standard dataset for text classification
Encoder layer 2개, model dimension은 300, head는 4, centroid의 개수는 max_length의 square root로 설정했다.
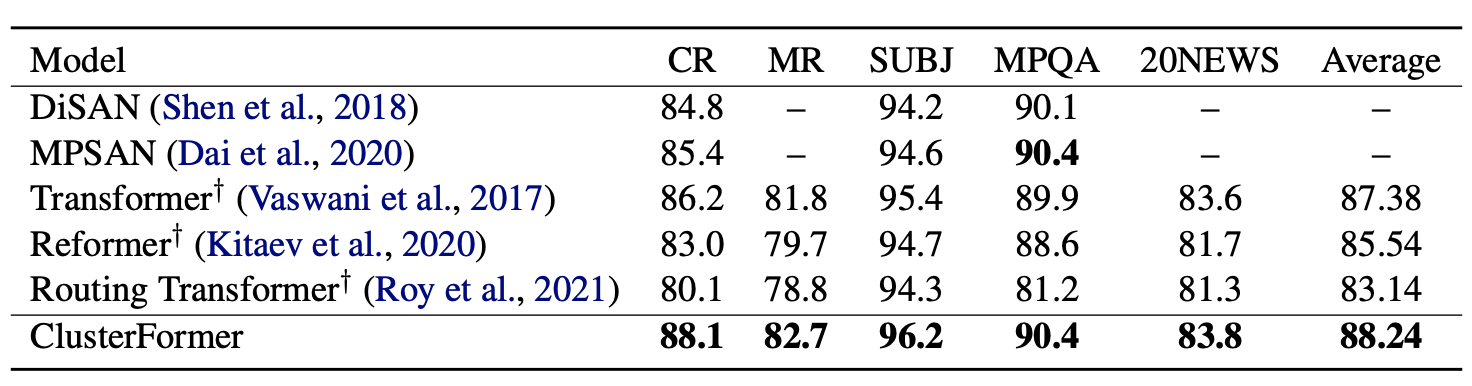
모든 dataset에서 여타 다른 model보다 좋은 성능을 보여줬다.
3.3 Natural Language Inference (NLI) and Text Matching
먼저 NLI task dataset으로 SNIL, SciTails datasets을 사용했고 Text Matching dataset으로 Quora, WikiQA dataset을 사용했다. Model setting으로는 model dimension 300, layer는 1개, head는 6개, centroid의 개수는 3개로 설정했다.
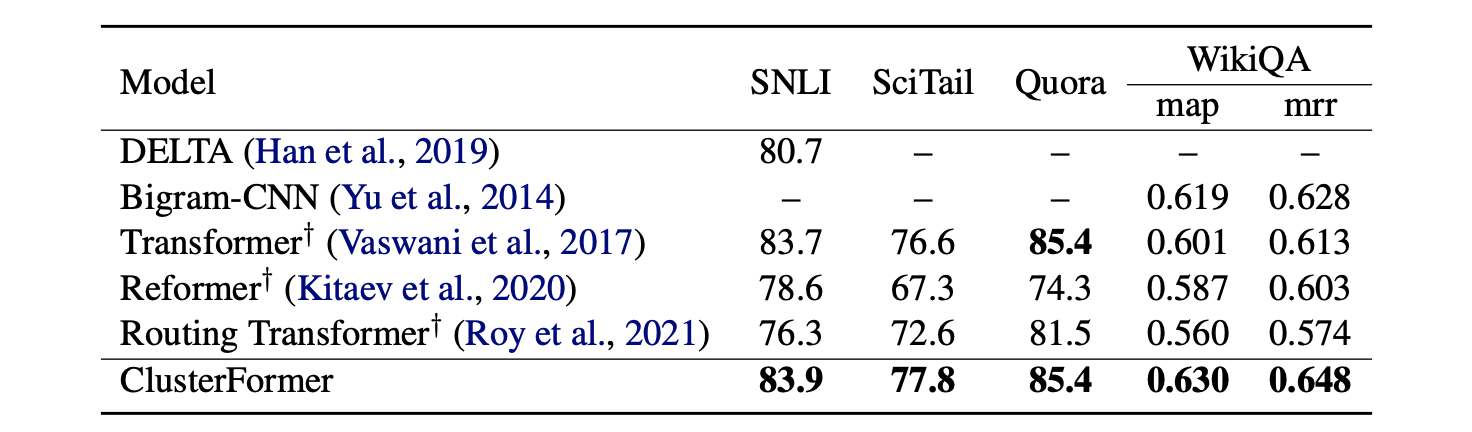
이 또한 모든 dataset에서 비교 model들보다 더 좋은 성능을 보여준다.
(성능이 정말 하나도 빠짐없이 좋다...)
3.4 The choice of clustering numbers of k
다음으로는 20 NEWS dataset을 사용했을 때, cluster의 개수 를 다르게 했을 때 성능을 비교한 실험이다.
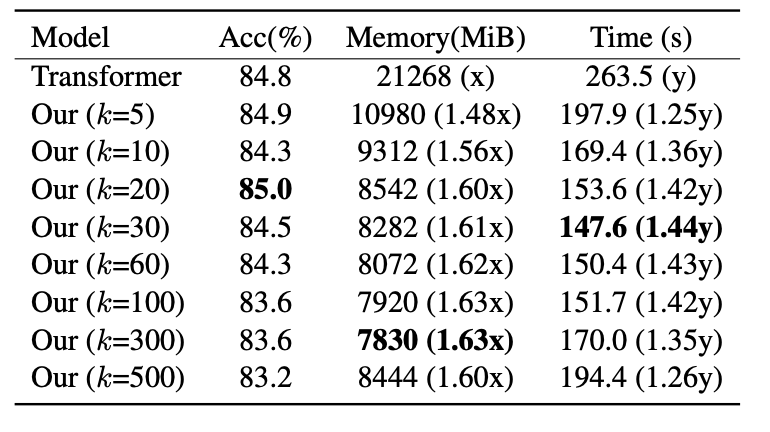
일정 수준까지 의 개수가 늘어나도 성능은 stable한 것을 볼 수 있다. 일정 수준을 넘어가면(k=20) 모델의 성능이 하락하는 것을 볼 수 있다.
Memory차원에서 본다면, 모델의 memory cost가 감소하다가 일정 수준을 넘어서면 증가하는 것을 볼 수 있다.(k=300)
Training time차원에서 본다면, memory와 마찬가지로 감소하다가 증가한다.
따라서 본 논문의 방법은 적절한 를 찾을 수 있다면, 모델의 효율성을 얻을 수 있다.
(그러나 적절한 를 찾아야 한다는 것은 그만큼 실험을 돌려야하기 때문에 꼭 좋은 점이라고 보기 어렵다, 즉 최적의 를 찾는 elbo method가 들어가 있으면 좋겠다는 생각을 했다.)
3.5 Ablation studies for Clustering Loss
이 section에서는 두 개의 loss에 대해 실험을 진행했다. 밑에는 어떤 loss가 모델의 성능에 효과적인지 나타낸 표이다.
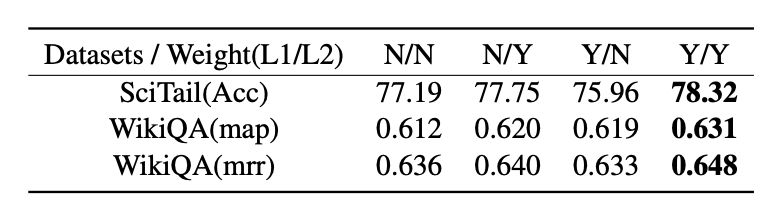
SciTail의 성능은 두 개의 loss를 함께 썻을 때 가장 높았고 loss1보다 loss2가 더 모델의 성능을 높이는 것을 확인할 수 있다. WikiQA의 경우 마찬가지로 두 개의 loss를 함께 쓰는 것이 성능이 제일 높았고 loss2가 더 효과적임을 알 수 있다.
3.6 Time and Memory Analysis
마지막으로 time과 memory의 cost에 대한 실험이다. 이 실험 마찬가지로 20NEWS data에 대해 진행했고 평균 seq_len은 280부터 10000으로 설정했다. Time과 memory에 대해서 비교하기위해 0부터 2000까지 seq_len을 설정했고 batch_size를 20으로 설정했다. GPU는 NVIDIA V100 GPU를 사용했고 1000step가량 forward를 진행했다.
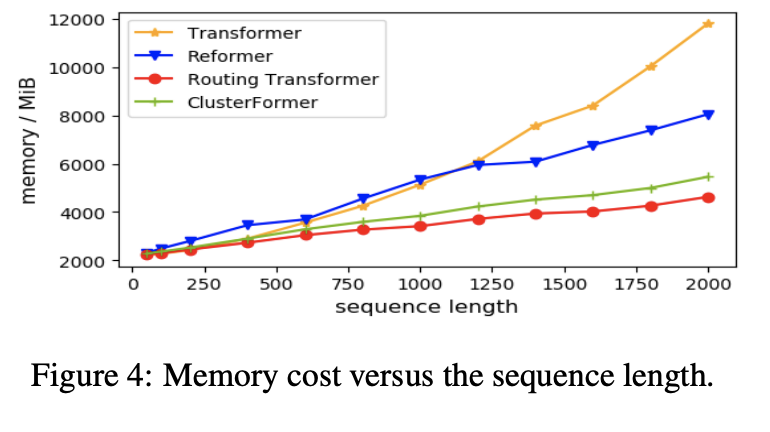
Figure 4를 보면, sequence length N이 증가 할때, 기존 transformer에 비해 cost가 줄어들고 N이 2000을 넘어가면서 Our model, Routing Transformer, Reformer의 cost는 각각 53.8%, 60.8%, 31.8% 줄어든다. Routing Transformer가 input length에 비례해서 cost reducing은 제일 높다.
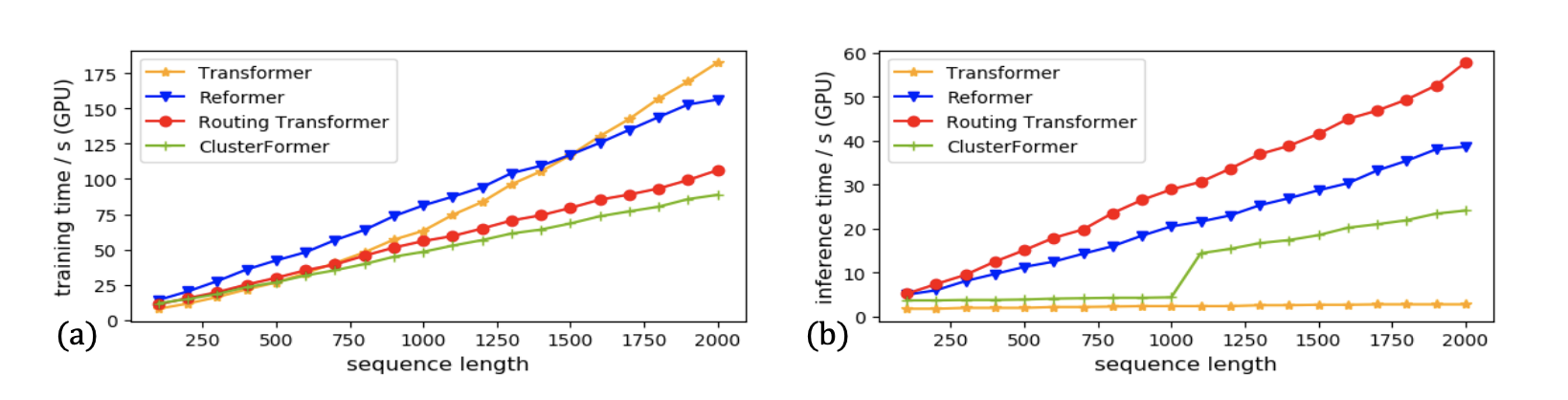
Figure 3을 보면, Routing Transformer와 Our model은 input length가 길어져도 GPU 사용량이 상대적으로 조금 올라간다. N이 2000일때, Our model, Routing Transformer, Reformer의 training time은 각각 51.4%, 41.8%, 14.4% 줄어드는 것을 확인할 수 있다. 그러나 inference time은 보다 열등한데, 이는 모델의 병렬적 구조의 감소했기 때문이라고 저자는 밝혔다.
