Sparse Transformer Review
Vanilla Transformer's self-attention's complexity :
Sparse Transformer's self-attention's complexity :
Abstract
- Introduce Attention Sparse Factorization
- Introduce variation of architecture and initialization
- Recompute of attention matrices to save memory
- Fast attention kernels for training
Attention Sparse Factorization
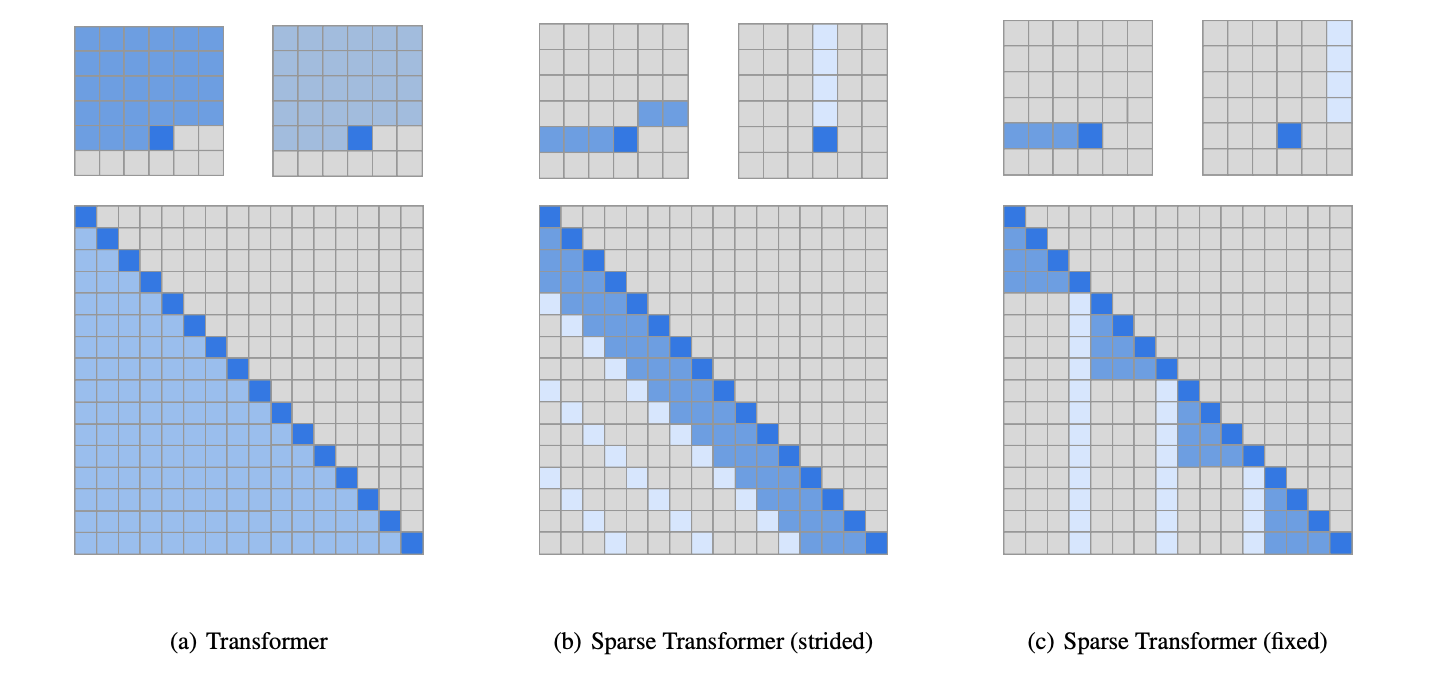
(a)는 기존 vanilla transformer의 attention, (b)는 특정한 길이(주파수)가 의미를 갖는 만큼의 attention, (c)는 text처럼 의미 없는 길이만큼의 attention.
주기성을 가지고 있는 경우(image, audio)
1) 이전 index부터 현재 index까지, K개까지 만큼 attention
2) Sparse한 attention
두개를 합쳐 strided attention으로 정의
주기성이 없는 경우(text)
strided attention을 적용할 경우, 성능이 좋지 못함
1) 일정 길이 K만큼 모두 attention
2) 특정 토큰에서부터 모든 index를 attention
Factorized Attention Heads
앞서 설명한 factorized attention을 head에 따라 3가지 방법으로 적용.
1) 두가지 factorized attention 방법 중 하나만 적용
2) 두가지 factorized attention 방법 중 하나만 Single head를 통해 적용
3) Head별로 서로 다른 attention 적용
Scaling to hundreds of layers
Layer를 거치기 전 활성화 함수(activation function)을 먼저 거치는 pre-activation residual block을 적용
Saving memory by recomputing attention weights
Gradient checkpointing을 통해 긴 sequence를 self-attention에 적용하는 것에 대한 효율성을 챙김
Efficient block-sparse attention kernels
자체적으로 효율적인 gpu kernerl을 적용했다.
