Transformer기반의 모델을 많이 활용하면서 문득 multi-head attention에 대해서 의문이 들었다. 기존 model의 차원을 여러 head의 차원으로 쪼개서 전체 input sequence에 대해서 projection하는 것이 과연 어떤 효과와 역할(?)을 하는지, 이것이 single attention과 얼마나 큰 성능 차이를 보이는지 본 논문을 통해 알아보려고 한다.
0.Introduction
Multi-Head attention은 결국 multiple different subspace에 대해서 사영하는것이고 병렬적으로 계산가능하게 하는 메카니즘이다.
본 논문의 가장 큰 contribution은 attending multiple positions은 MHA
(multi-head attention)의 고유한 특성이 아닌것을 증명하는것이다. 그리고 single-head attention을 여러층 stack하는것도 multi-head attention과 큰 차이를 보이지 않는다고 주장한다.
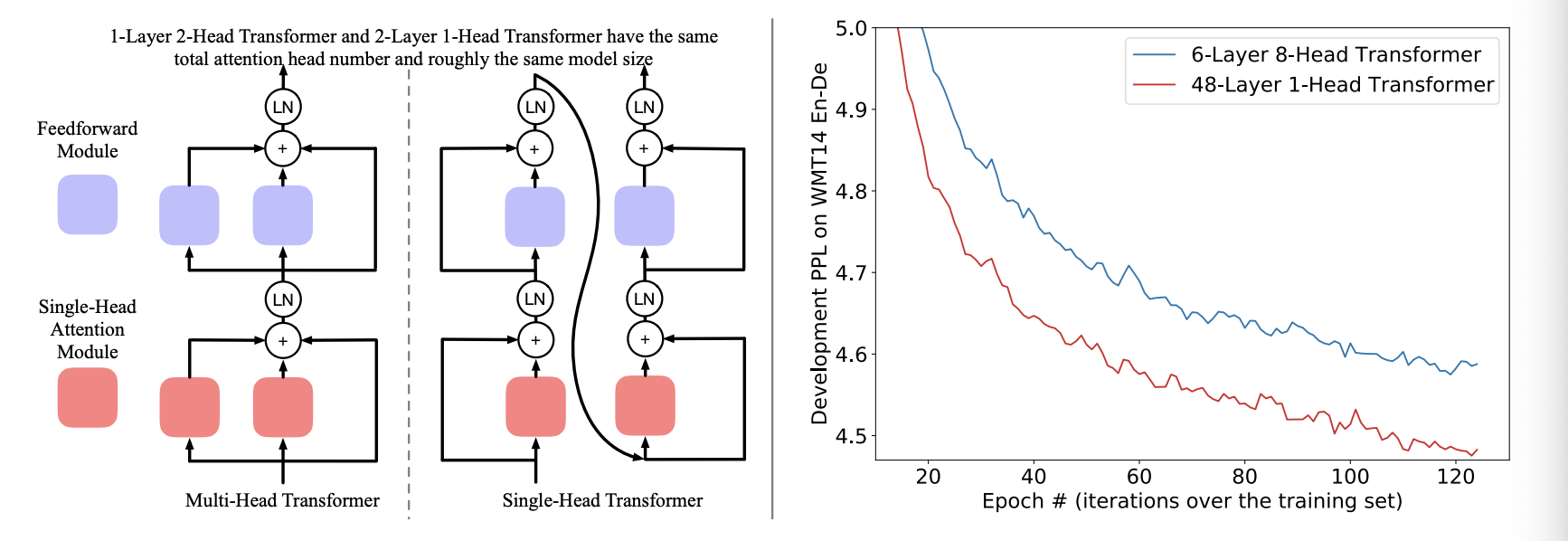
먼저 위 그림을 보면, MHA는 일종에 ensemble model처럼 보일 수 있다. 그 이유는 여러 single head attention module의 평균을 결합하는것과 비슷하기 때문이다. 그러므로 module을 다르게 결합하는것이 비슷한 효과를 가져다줄 수 있다.
우리의 실험을 통해 얉은 MHA와 깊은 SHA를 비교했을 때, SHA가 더 학습하기 어려울 수 밖에 없다. 예를 들어, 6-layer와 6-head transformer와 36-layer의 transformer를 비교해보면 쉽게 알 수 있다. 그러나 adaptive model initialization으로 인해 hyper-parameter를 조절하지 않고 안정적으로 학습이 가능하다. 결과적으로 36-layers transformer가 더 빠른 수렴을 보여주었다.
1. From Shallow Multi-Head To Deep Single-Head
4.1 Inherent Ensemble Structure within Transformer
앞서 얘기했던것처럼, MNA와 FFN의 sublayer는 작은 module을 앙상블한것과 똑같다고 했다.
위는 MHA의 수식이고 아래는 SHA의 수식이다. 둘의 큰 차이점은 을 로 decompose하고 를 로 decompose한다는 것이다.
이렇게 low rank로 decomposition될 수 있다는 것으로 인해 head의 수가 많아지더라도 연산량은 늘어나지 않는다는 것을 증명할 수 있다.
2. Multi-Head or Single-Head? Empirical Comparisons

먼저 translation에 대한 성능 비교 table이다. 약간의 더 많은 parameter로 더 좋은 성능을 보여주고 있다.(그러면 좀 낮은 layer로 설정해서 해보는건 어땠을까 하는 생각이 든다.)
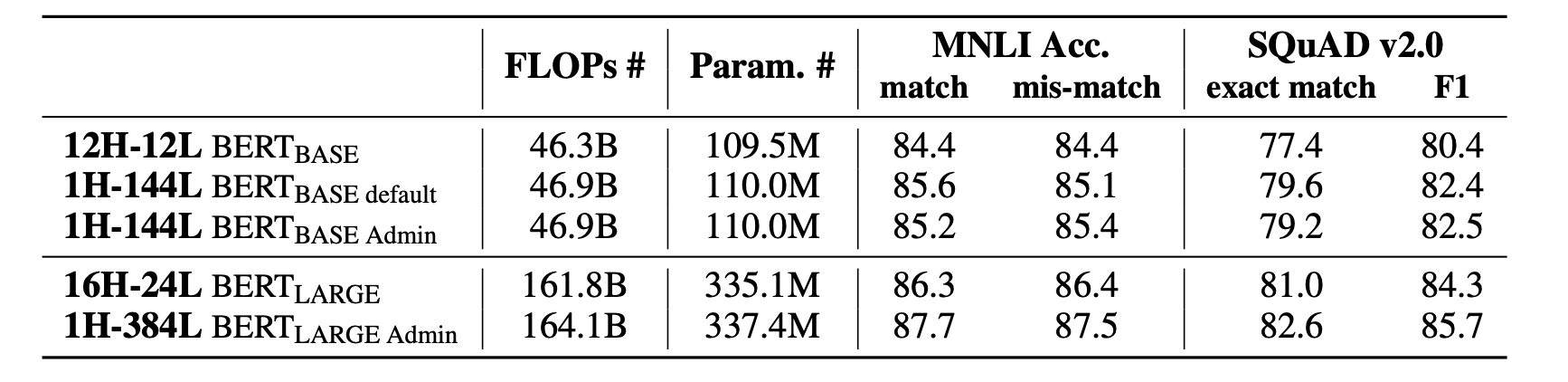
다음은 MNLI와 SQUAD dataset으로 성능을 비교해봤는데, 비슷한 FLOPs와 Params로 조금 더 높은 성능을 보여주고 있다.

GLUE dataset도 비슷한 양상이다. 결국 여러 benchmark dataset으로 single head의 여러 layer를 stacking하는것도 비슷한 성능을 보인다.
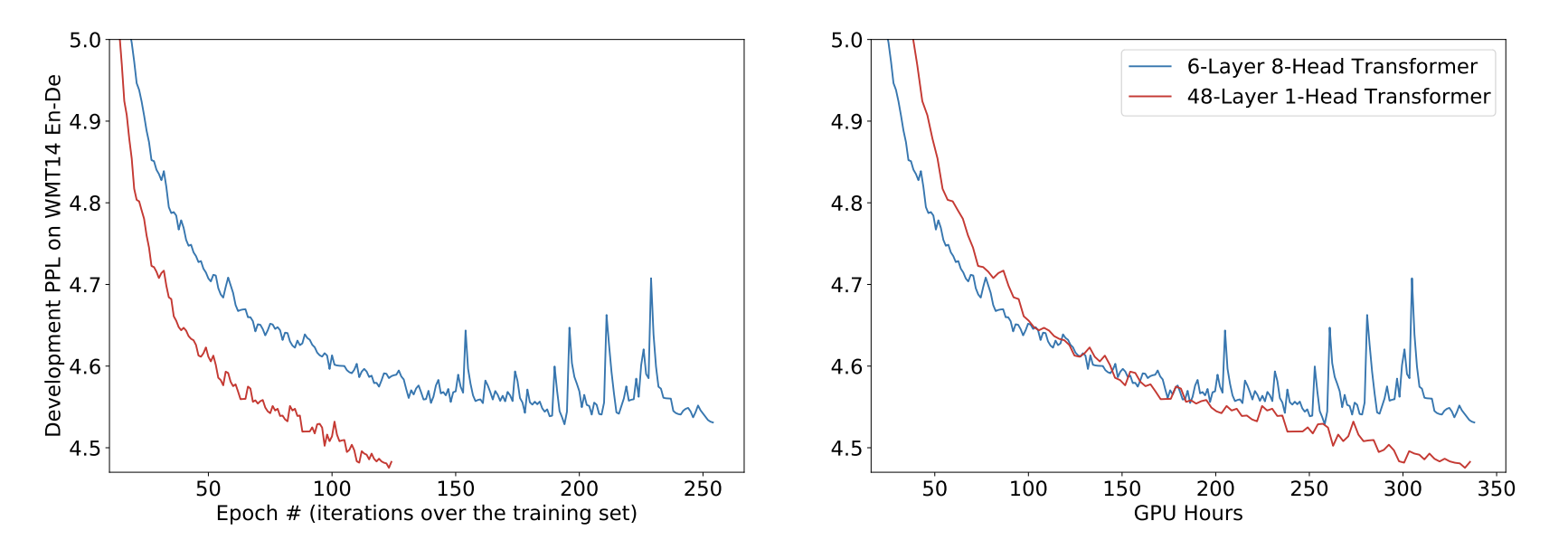
다음은 batch size와 sequence length가 증가할 때의 cost를 나타내는 그래프이다. Batch_size와 seq_len가 낮을 때는 MHA가 더 좋은 효율의 비용을 보이지만, 길어질수록 SHA가 더 좋은 효율을 보여주고 있다.
