0. Abstract
Deep Convolution Neural Networks(DCNNs)를 통해 pixel 단위의 classification 문제를 해결하기 위하여 사용한다. DCNNs의 마지막 layer에서느 object segmentation을 포착하기 어렵고 이러한 원인은 DCNNs의 invariance한 특징 때문이다. 본 논문에서는 이런 부정확한 localzation문제를 DCNNs의 마지막 layer에서 responses와 fully connected conditional randaom field(CRF)를 결합하여 해결하려고 한다.
1. Introduction
DCNNs은 end-to-end 모델이고 invariance 특징을 통해 image classification과 object detection, 등에서 좋은 performance를 보여주고 있지만 오히려 invariance는 semantic segmentation에서는 성능을 저하시킨다고 한다. Semantic image segmentation에 적용하기 위해서는 총 3가지의 challenge가 존재한다.
- Reduced feature resolution
- Existence of objects at multiple scales
- Reduced localization accuracy dut to DCNN invariance
본 논문에서는 DeepLab을 통하여 세가지의 과제를 해결한다.
먼저 reduced feature resolution은 max-pooling을 반복하면서 down-sampling 때문에 작은 feature map이 출력되게 된다. 이러한 문제점을 해결하기위해 DCNNs의 마지막 max-pooling layer들을 filter up-sampling으로 non-zero filter taps에 구멍을 넣ㅇ는 atrous convolution을 사용한다. 이를 통해 parameter의 개수나 연산량을 증가시키지 않으면서 filter의 view를 증가시킬 수 있다.
다음 existence of objects at multiple scales의 경우, 기존에는 원본 이미지의 크기를 여러개로 scaling하면서 feature map의 크기를 합하는 방식으로 진행되었다. 이럴경우 연산량이 급증한다는 단점이 있는데 이를 극복하고자 논문에서는 spatial pyramid pooling을 통해 극복한다. 여러 병렬로 이루어진 atrous convolution layer들에 서로 다른 sampling rate를 적용했다.
마지막 reduced localization accuracy due to DCNNs invariance는 skip layer를 사용하는 방법이 있다. 본 논문에서는 fully connected conditional random field를 도입했다.
1.1 Reduced feature resolution
DCNN에서 우리가 down-sampling을 통해 stride와 max-pooling을 진행하는데 이렇게 되면 spatial resolution은 계속 줄어든다. 마지막 layer에서는 spatial resolution은 원본 input image에 비해 많이 작아져 segmentation이 불가능해진다.
이러한 문제점을 해결하고자 max-pooling layer를 대신하여 up-sampling filter를 추가했다. 여기서 up-sampling을 담당하는것이 atrous filer이다.
Atrous Convolution은 특정 층에서 원하는 해상도로 조정이 가능하다. 1차원의 이미지가 들어왔을 때, 식은 아래와 같다.
- y[i]는 atrous convolution layer의 output
- x[i]는 일차원의 input
- w[k]는 길이 k의 filter
- r은 input을 sampling하는 stride(r=1이면 일반 convolution layer)
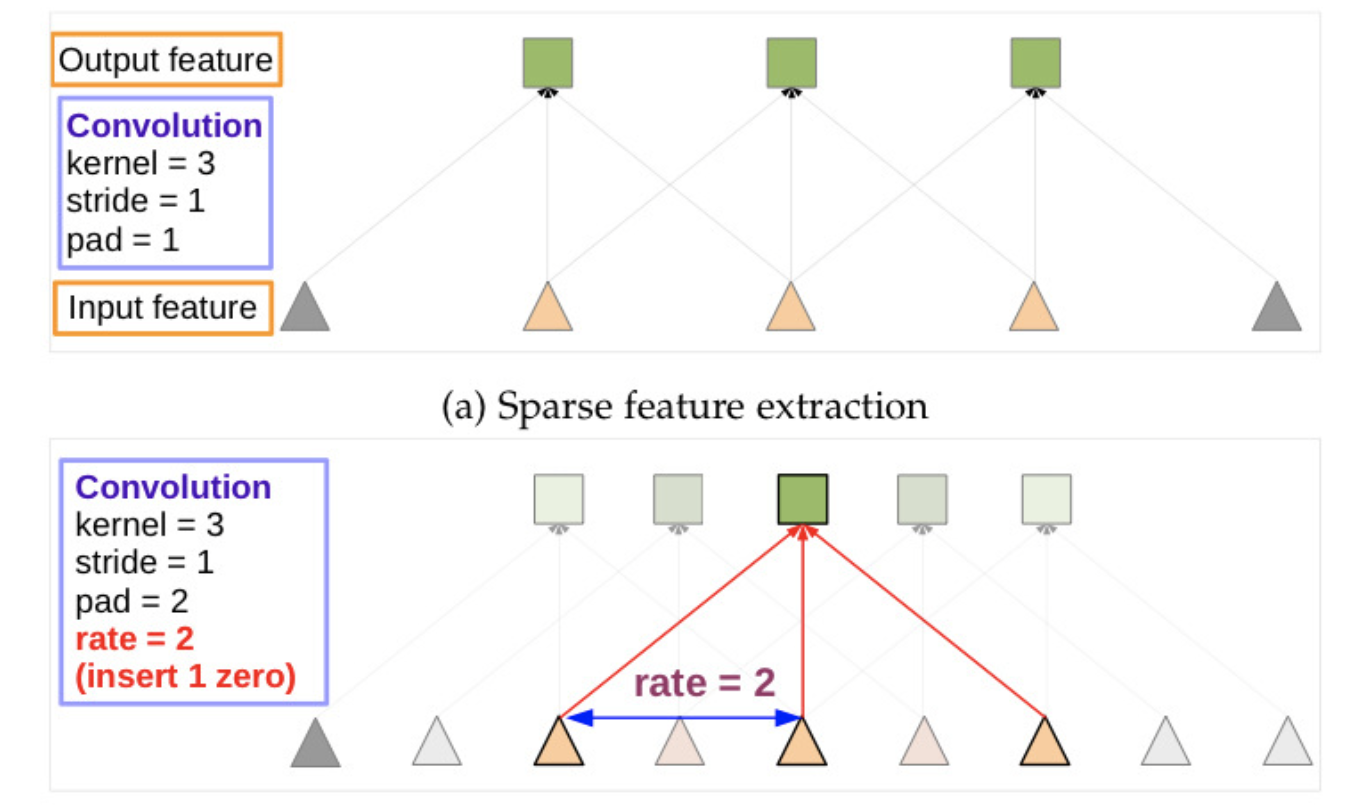
위 그림에서 (a)는 r=1일 때, (b)는 r=2일 때를 나타낸다. 아래 그림은 r=2로 설정했기 때문에 0이 하나 생기게되고 stride = 1로 유지되어서 receptive field가 더 커지게 된다.
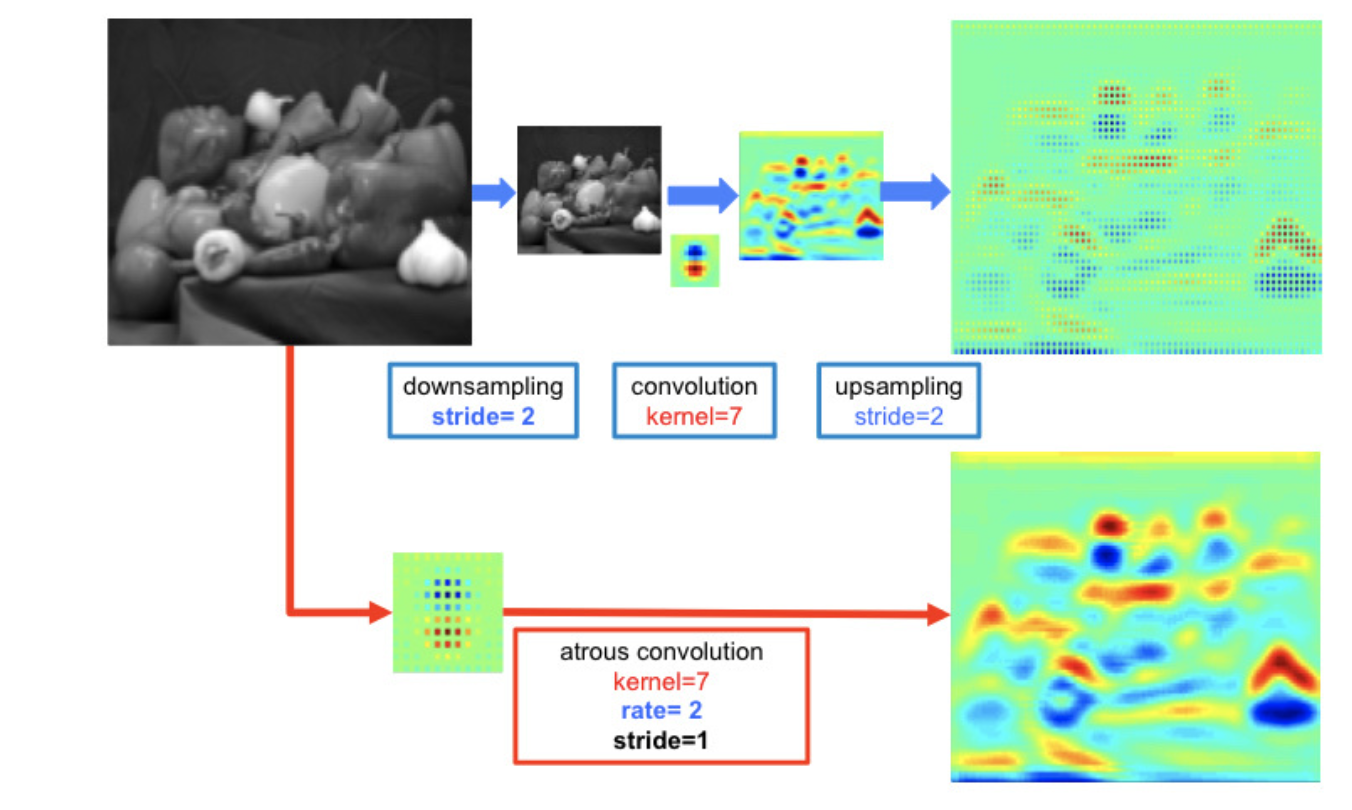
2차원에서는 위의 그림과 같이 이루어진다. 파란색 과정이 r=1일 때 sparse feature extraction with standard convolution이고 빨간색 과정이 r=2일 때 dense feature extraction with atrous convolution이다.
Atrous convolution을 사용하여 feature map을 커지게하고 이를 bilinear interpolation을 통해 featur map을 확장할 수 있다.
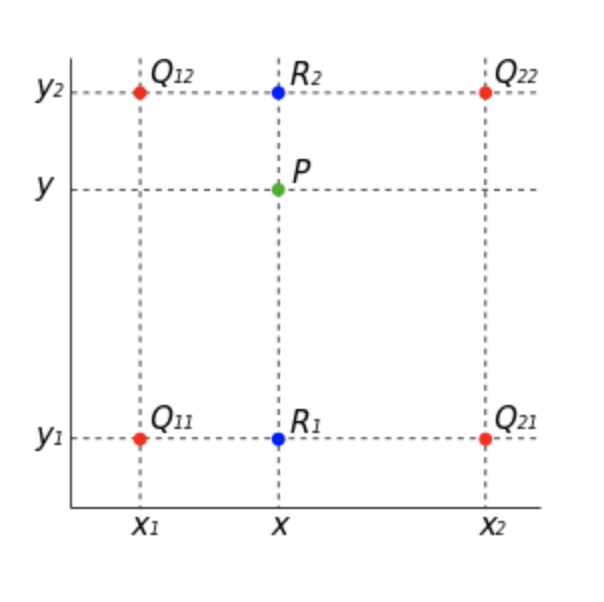
Bilinear Interpolation은 x, y의 2차원에 대해 선형 보간법을 통해 필요한 값을 채우는 방식입니다.
위처럼 2x2 matrix를 4x4 size로 upsampling하고 싶을 때, 빈 값을 채워야 하는데 이때 축을 두 가지 interpolation을 적용한 것을 Bilinear Interpolation이라고 합니다.
R1이 Q11, Q21의 x축 방향 interpolation 결과이고, R2는 Q12, Q22의 x축 방향의 interpolation 결과입니다. 이러한 방법을 통해 up-sampling이 가능하다라고 이해했다.
Atrous convolution의 계산 방법은 다음과 같다.
보통 DCNN에서 kernel size는 3x3이고 atrous filter size가 2라고 한다면 다음 그림과 같다.
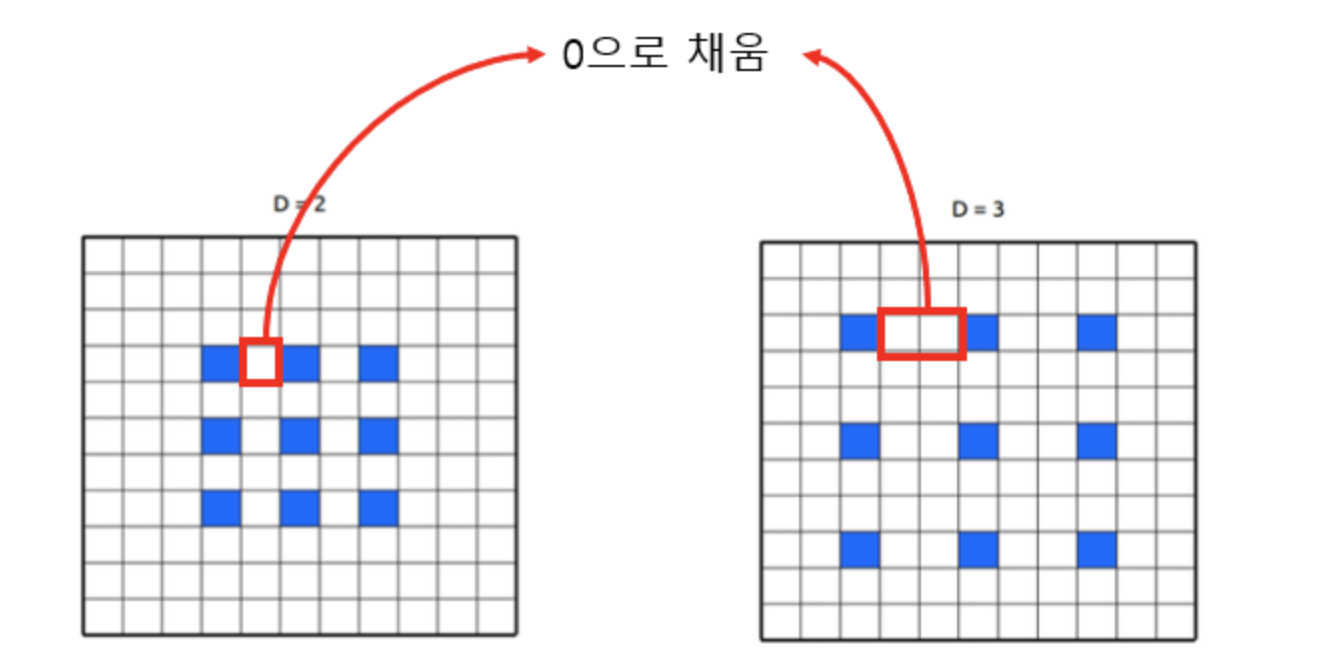
파란색 pixel 사이에 0이 들어간다고 생각하면 된다. Atrous filter의 size가 2이라면 다음과 같은 식을 통해 window size가 1인것을 알 수 있다.
1.2 Existence of objects at multiple scales
Input image를 DCNN에 넣으면 input image에 대한 여러가지 rescaled된 filter가 나오게 된다. 이 filter의 feature와 score map을 종합하여 object를 탐지한다. 이러한 과정에서 엄청난 연산량이 요구되고 시간이 오래걸리게 된다. 상호보완적인 여러 filter를 사용하여 input image의 정보와 object를 가져오는 방식이다.
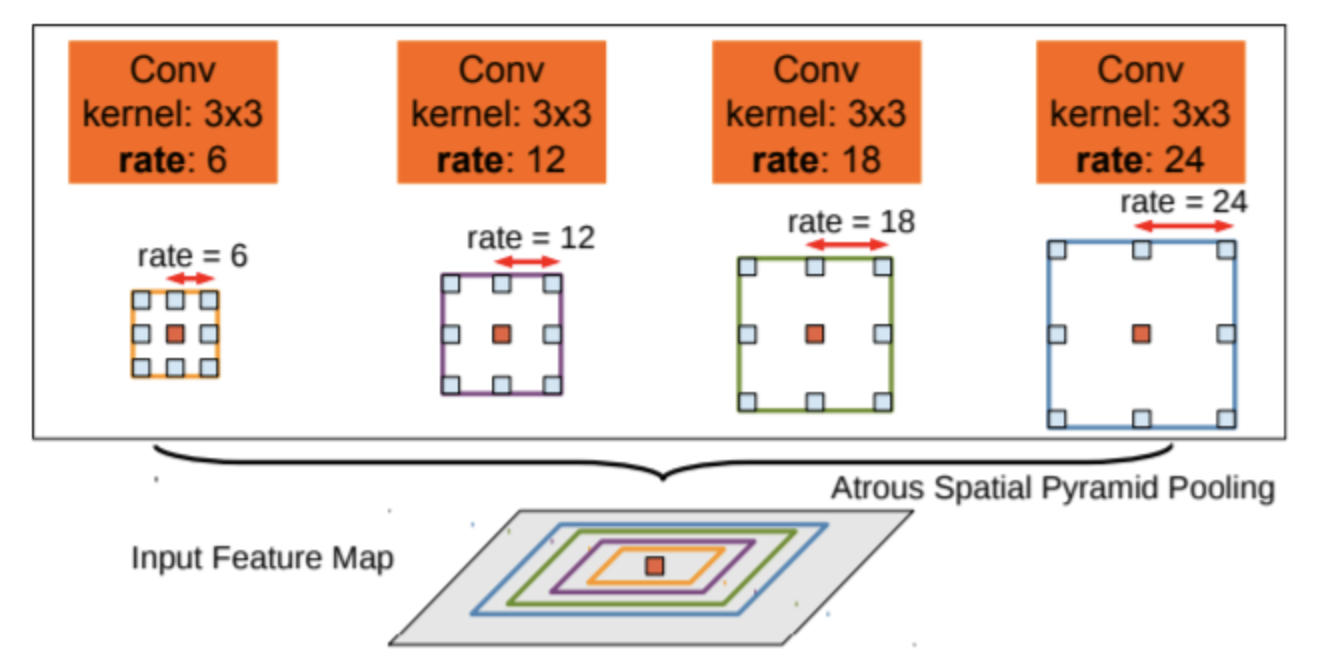
동일한 parameter를 공유하는 병렬 DCNN을 사용하여 여러 size의 DCNN score map을 추출한다. 여러 DCNN에서 원래 이미지의 해상도로 up-sampling하기 위해 bilinear interpolation을 적용하고 각 위치에서 서로 다른 scale의 최대 값을 합한다.
이 방식은 R-CNN의 spatial pyramid pooling 방법과 유사하고 window size가 다른 여러 atrous convolution을 적용한다.
1.3 Reduced localization accuracy
DeepLAB에서는 atrous convolution과 함께 CRF 후처리 과정을 사용하여 예측 정확도를 높혔다. Semantic segmentation에서는 pixel단위의 조밀한 예측이 필요하지만 classificaiton layer로 segmentation을 진행하게 되면 feature-map 크기가 줄어들어 detail한 정보를 얻을 수 없다.
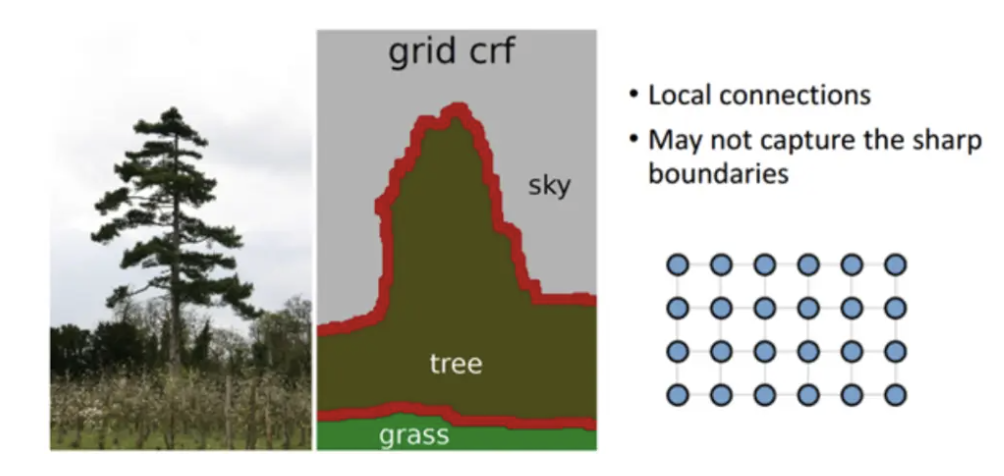
기존의 short-range CRF의 경우는 local connection 정보만을 사용하게 되어서 segmentation이 뭉게지고 noise에 강한 효과를 얻을 수 있었다.
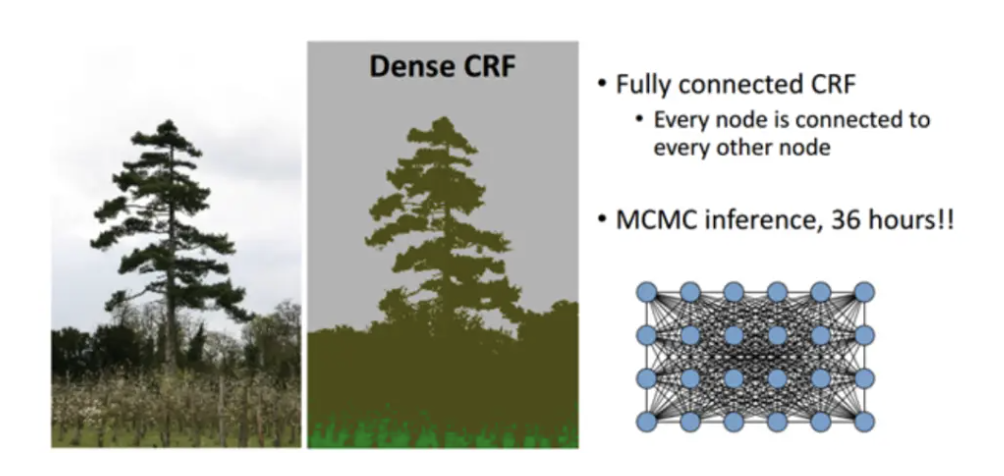
이를 Fully-Connected CRF를 통해 pixel-by-pixel로 fully connected graph로 연결했고 mean field approximation 방법을 적용하여 효과적으로 fully connected CRF를 수행했다. Mean field approixmaation은 수 많은 변수들로 이루어진 복잡한 관계에서 특정 변수와 다른 변수들의 관계의 평균을 취해서 더 단순화된 모델을 사용하는 방법이다.
2. DeepLAB
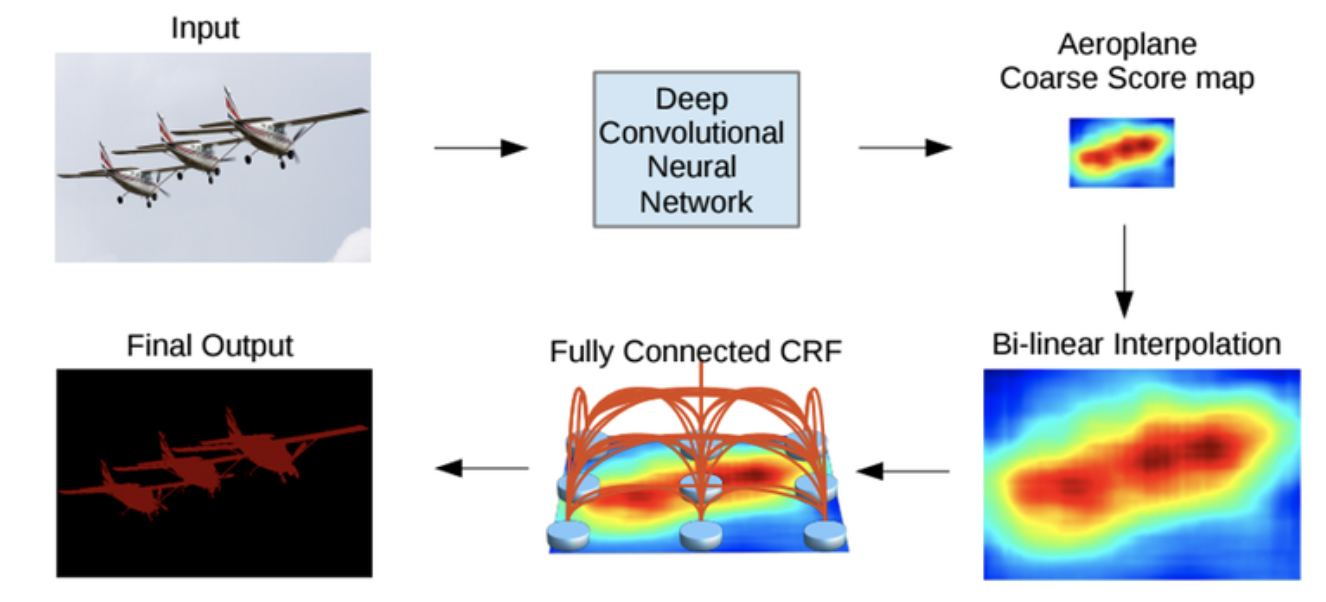
DeepLAB의 최종 아키텍쳐는 위 그림과 같다. DCNN을 통해 1/8 크기의 coarse score-map을 구하고 이것을 bilinear interpolation을 통해 upsampling을 진행한다. 그리고 fully connected CRF를 통해 localization을 정교화하게 만든 후에 output을 산출한다.
