0. 먼저 object tracking이란?
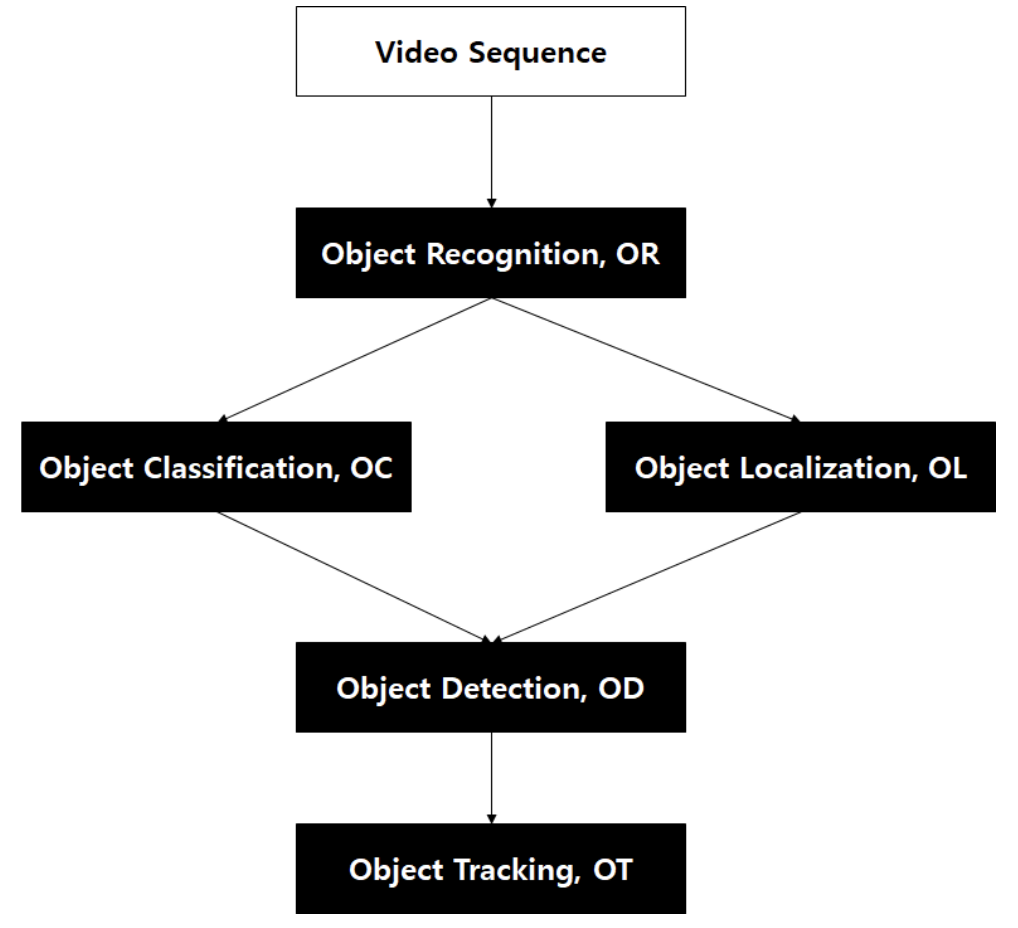
Object tracking의 순서로는 video가 들어오면 한 부분에 물체가 있다는걸 인식(Object Recognititon)하고 그 물체가 무엇인지(Object Classification)하고 정확한 위치를 나타낸다(Object Localization). 그리고 OC와 OL가 합쳐지면 Object Detection이 된다. 그리고 추후 OD의 결과로 각 Box를 이전 frame과 비교하여 ID를 매칭시키고 여러가지 기술들을 사용하는것이 Object Tracking이라고 할 수 있다.
1. Multiple Object Tracking(MOT)
다중 객체 추적(Multiple-Object Tracking)이란 다수의 object를 추적하기 위하여 detection 결과간의 연관성을 찾는 과정이다. Detection된 object 정보를 기반으로 프레임 간의 동일한 object에 대한 반응을 연관하여 object에 대한 전체 궤도를 완성한다. MOT는 현재 감지시스템, 자율 주행 시스템과 같은 실생활분야에서 광범위하게 사용되고 있다.
모델의 구조는 일반적으로 detector와 tracker 두가지로 구성되어 있다. 보통 detector는 YOLO 시리즈와 Faster R-CNN으로 사용되고 있고 현재 SOTA 논문에서는 YOLOv4,5,X를 사용하고 있다. 이러한 detector를 통해 bounding box를 얻어 tracker 모델에 넘겨주면 tracker에서는 이전 object의 bounding box와 새로운 bounding box를 통해 object를 추적한다. Tracker의 역할은 크게 2가지로 볼 수 있는데 motion과 appearance 중에 어떤것을 기준으로 object를 추적할것인지 구분된다. 먼저 motion은 이전 frame의 위치에서 얼만큼 이동했는지를 기준으로 파악하는것이고, appearance는 같은 특징을 보이는 object가 어디로 이동했는지를 보는것이다.
2. Detection
Tracking에서 가장 기본이 되는 SORT 논문에서는 Faster-RCNN detection을 사용하고 있다.
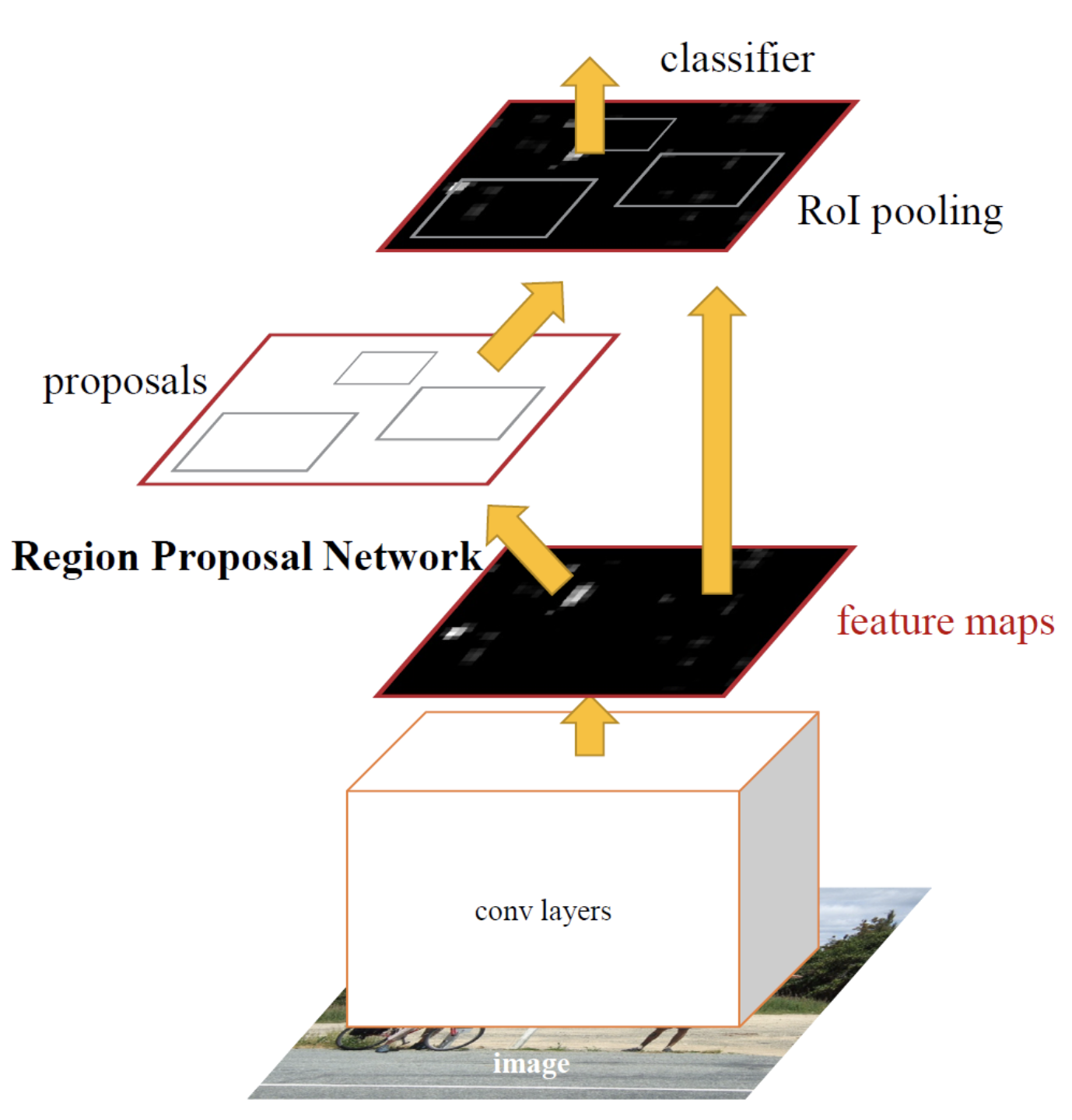
Faster-RCNN은 두가지 단계로 구성된 end-to-end framework이다. 먼저 CNN을 통해 feature를 추출하고 추출한 feature map을 region proposal network에 넣어 region proposal을 생성한다. 그리고 region proposal을 통해 bounding box regression과 classifier를 수행하게 된다.
3. Estimation Model
본 SORT 논문에서는 object tracking의 object 위치를 예측하는 기법으로 칼만 필터를 사용했다. 칼만 필터는 이전 시점의 target의 state를 통해 현재 시점의 target state를 예측하는 방법으로 현재는 RNN과 LSTM을 사용하고 있다.
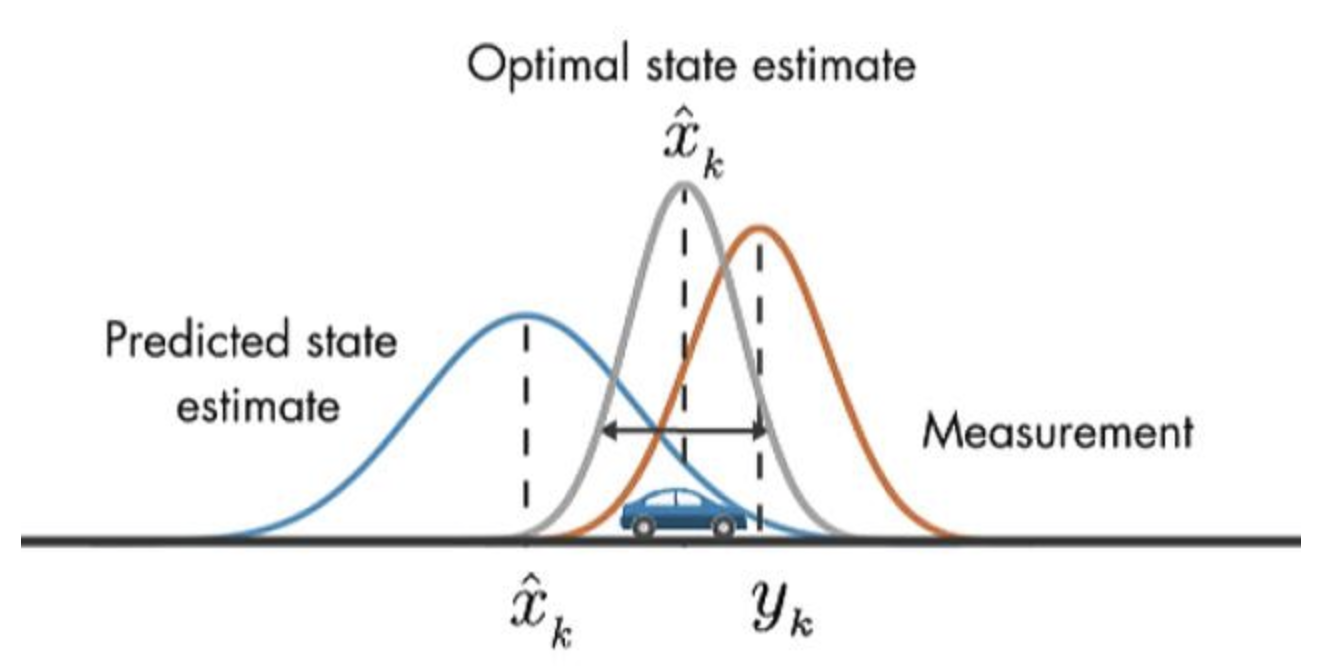
먼저 첫 번째 프레임에서 자동차를 찾았고 이 때 위치와 속도가 라고 한다면 다음 프레임에서 자동차의 위치는 라고 쉽게 예측할 수 있다. 그러나 detector의 결과상, 두 번째 프레임에서 라는 위치로 측정해서 값이 다를 수 있다. 측정의 불확실성과 이동 불확실성 등의 원인으로 값이 다를 확률이 높다. 이러한 예측과 측정을 고려할 때 생기는 불일치성을 해결하기 위해 칼만 필터에서는 가우시안 확률분포를 사용한다. 를 각각 평균으로 하는 두 가우시안 분포의 차이가 적을수록 확실한 측정 및 예측이 되는것이고, 두 분포의 차이가 적을수록 확실한 측정과 예측이 되는것이고, 차이가 클수록 불확실성이 커진다고 볼 수 있다. 이 과정에서 mahalanobis distance를 이용한다. Mahalanobis distance는 평균과의 거리가 표준편차의 몇 배인지를 나타내는 값이다. 실제로 칼만 필터를 MOT에서 사용할 땐 를 사용한다. Detector에서 얻은 bounding box를 알고 있으므로, box의 좌표, 가로, 세로 값과 각각 값들의 속도 또한 알 수 있다. 속도는 이전 프레임과 현재 프레임을 비교를 통해서 알 수 있다.

예를 들어서 짱구라는 object를 찾고 state를 정의했다고 한다면, bounding box의 중심이 (400, 180)이고 다음 (60, 60)은 bounding box의 w,h값이라고 하자. 그리고 (10, 5, 0, 0)이 bounding box의 x, y축 방향으로 속도 w, h 변화율이다. 짱구의 다음 위치는 (410, 185)로 예측할 수 있다. 그러나 실제로는 이렇게 일정한 속도로 움직이지 않는 경우가 많아 다음 프레임에서 정확하게 찾아내기 힘들다. 그렇기 때문에 확률분포(가우시안 분포)를 활용하여 다음에는 어디쯤에 있을것이다라고 예측하는것이다.

빨간색 상자가 칼만 필터로 예측한 bounding box이고, 파란색과 초록색 상자가 실제 측정한 bounding box라고 한다면 앞서 설명한 mahalannobis distance로 빨간색 상자와 각각 파란색, 초록색 상자와의 거리에 대한 cost를 구한다면 cost가 최소가 되는 방향으로 파란색 상자를 업데이트한다.
4. Data Association
Data Association은 헝가리안 알고리즘은 일반적으로 사용되는 data association 최적화 방법이다. 칼만 필터를 이용하여 확보한 예측값은 이후 프레임에서 새롭게 detection한 object와의 association에 적용된다. 이후에 기존 target들의 detection과 예측된 bounding box들 사이에서 IOU값으로 cost matrix를 계산하고 헝가리 알고맂즘을 이용하여 최적화 시킨다.
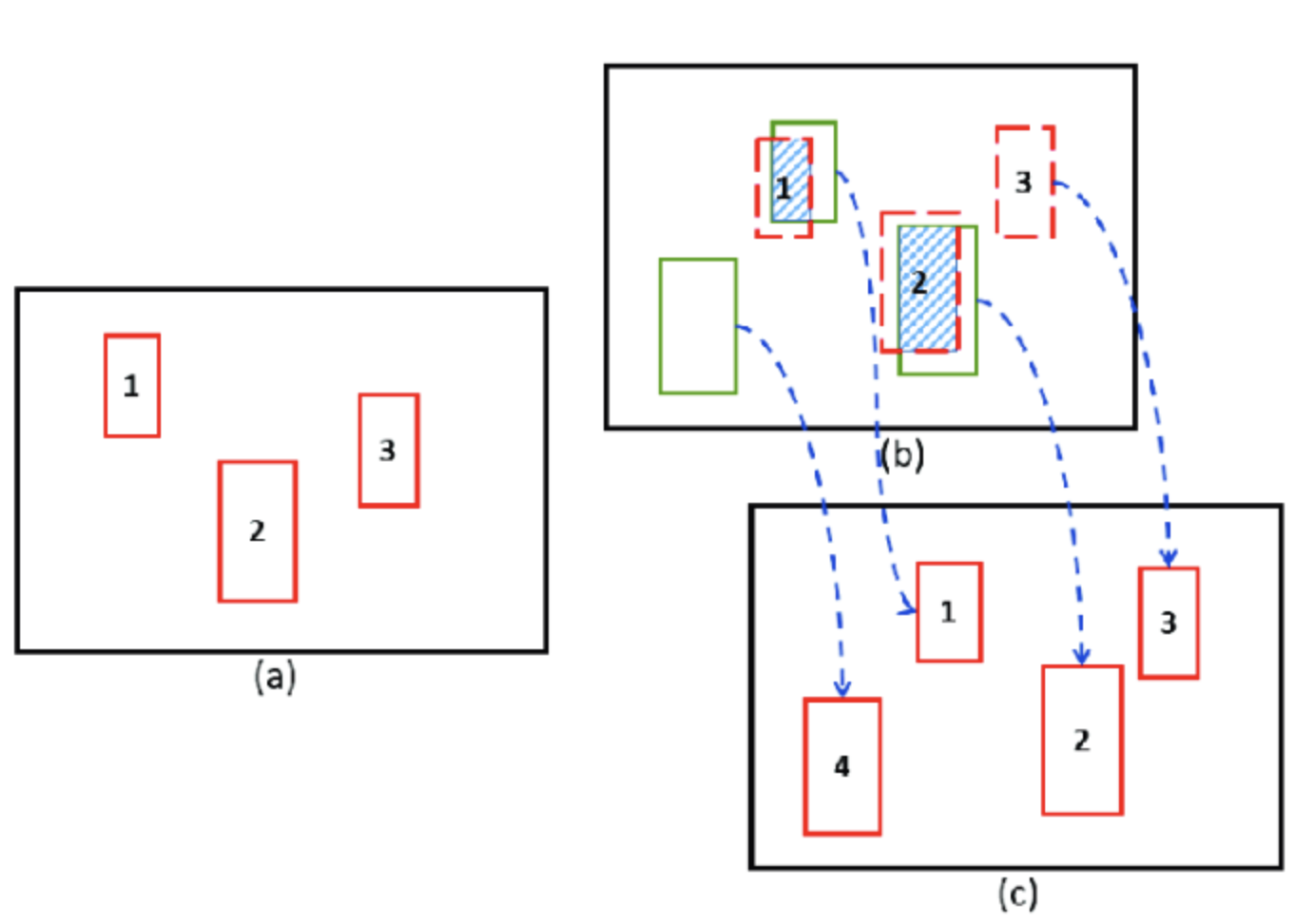
- (a) : 이전 시점의 칼만 필터 결과
- (b)의 초록색 : 현재 detector에서 나온 box
- (c) : (a)와 (b)의 IOU값을 계산하고 헝가리안 알고리즘을 통해 matching된 ID
5. SORT
SORT는 칼만 필터와 bounding box의 IOU를 이용하여 객체들을 추적하는 알고리즘이다.
SORT의 전체적인 흐름은 다음과 같다.
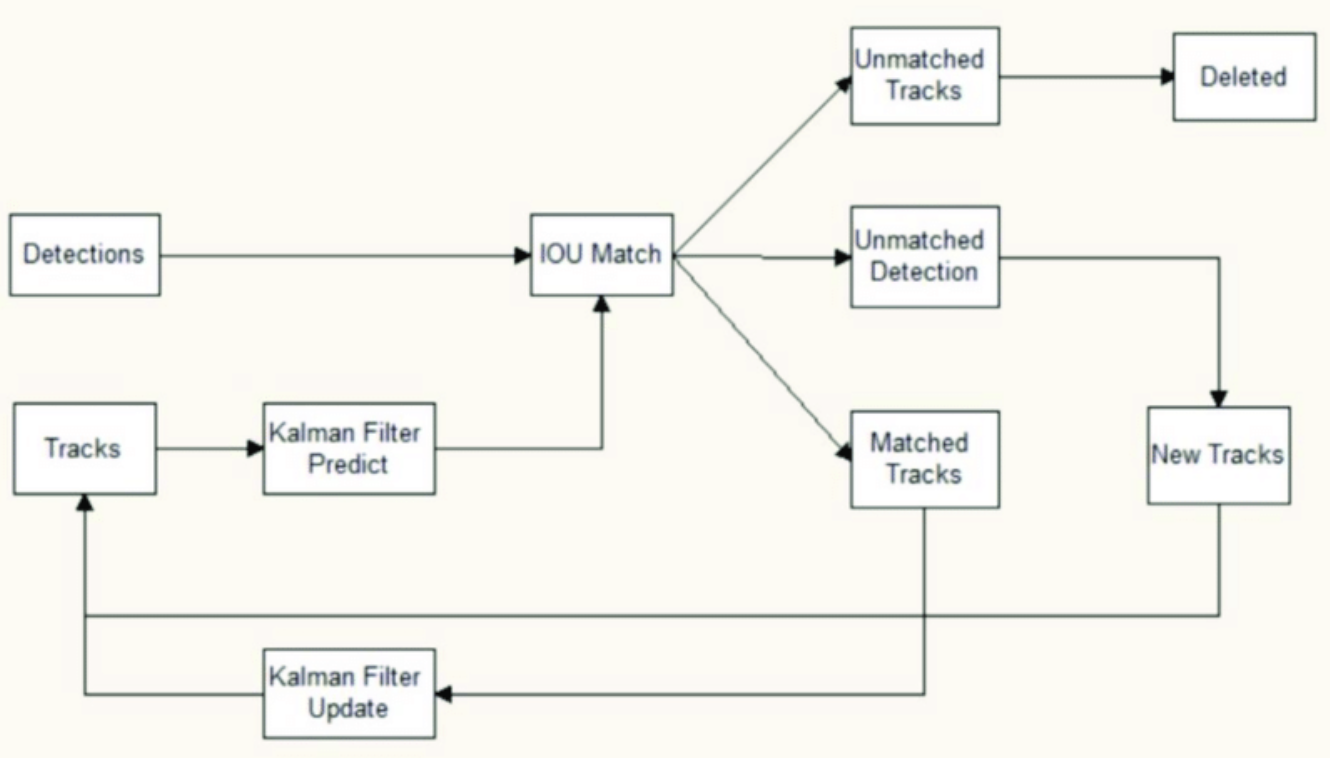
Track에 대해서 먼저 설명을 하면 frame상에서 변화가 생긴다면, 새로운 frame에서 얻은 정보를 넣어서 track을 업데이트한다. Track은 다음과 같은 특성을 가지고 있다.
- mean, covariance
- state : tenatative(tracking할 후보), confirmed(object가 frame 상에 있는것이 확실한 state), lost(object가 frame상에서 보이지 않는 state)
- initial hit : tentative state에서 confirmed state로 넘어가기 위해 필요한 최소 detection 횟수
- age : lost state가 되고나서 frame 횟수
SORT 알고리즘은 먼저 track이 가지고 있는 마지막 bounding box들에 대해 칼만 필터를 이용해서 다음 state를 예측한다. 그리고 detector에서 찾은 object들의 boundung box의 결과와 1의 결과(일치)로 나온 box에 대해서 IOU를 기준으로 matching한다. 모든 box들을 두고 global optimum을 찾도록 한다. 칼만 필터 예측값과 측정값의 차이가 매우 큰 경우는 matching하지 않는다. 이렇게 matching된 detector들의 bounding box들은 각 짝이 되는 track의 새로운 정보로 update가 진행되고 matching되지 않은 detector들의 bounding box는 새로운 track을 생성한다. 이때 track의 state는 tentative로 변하고 confirmed state는 lost로 lost state는 age의 기준을 세워 넘으면 삭제하고 tentative state는 바로 삭제한다.
아까 짱구 frame에서 SORT 알고리즘을 적용한다면 칼만 필터로 예측하고 bounding box를 기준으로 detector에서 찾은 파랑색 박스와 초록색 박스의 IOU cost를 구한다. 파란색 박스와의 IOU가 제일 높으므로 파란색과 matching되는 알고리즘이다. 이러한 과정을 지속하면서 여러 object들에 대해서 추적이 가능한다.
