0.Abstract
본 논문에서는 sentence embedding을 얻기 위해 unsupervised contrastive learning framework를 제안했다. DiffCSE는 기존 문장과 mlm을 통해 masking을 통해 처리된 문장사이에서의 sensitive를 통해 생성된 sentence embedding을 학습한다. DiffCSE는 equivariant contrastive learning의 한 예시다. 여기서 equivariant contrastive learning이란 contrastive learning을 일반화하고 특정 종류의 augmentation으로부터 insensitive하거나 다른 종류의 augmentation으로부터 sensitive한 representation을 학습하는것이다. 본 논문의 실험은 DiffCSE로 unsupervised sentence-representation의 SOTA를 달성했고 이전 SimCSE의 성능을 넘어섰다.
1. Introduction
특정 fine-tuning을 하지않고 downstream하여 'Universal'한 sentence representation을 학습하는것은 NLP에서 중요한 issue가 되고 있다. 최근 연구는 contrastive learning을 통해 PLM을 label없이 fine-tuning하면서 좋은 sentence embedding을 학습하는 방향으로 진행되고 있다. Contrastive learning은 single data를 다양한 augmentation을 통해 유사한 data끼리 positive pair를 설정하고 유사하지 않은 data끼리 negative pair를 설정하여 학습하는 것을 의미한다. Vision에서는 이러한 data augmentation을 통해 굉장한 성능을 달성했지만, sentence embedding을 얻는데는 실패해왔다. 실제로, Gao et al. (2021)에서 단어 삭제, 유사어 대체, 등 augmentation보다 오히려 단순한 dropout을 통해 positive pair를 설정하는것이 더 성능이 좋았다. 이것은 아마 representation을 더 잘 학습하기 위해 설정된 objective function인 contrastive learning에서 실행한 data augmentation이 문장의 의미를 바꿔서 그렇다. 즉, 이상적인 sentence embedding은 이러한 trasformation(data augmentation)과는 invariant해야한다.
본 논문에서는 deletion, replacement와 같은 augmentation을 통해 sentence representation을 학습방법을 제안했다. 이것은 equivariant contrastive learning의 한 예시로, insensitive한 image transformtaion에 contrastive loss를 부여하고 sensitive image transformation에 prediction loss를 vision representation을 학습한다. 본 논문에서는 equivariant contrative learning을 이전 SimCSE에서 dropout을 통한 augmentation을 insensitive transformation을 진행했고 MLM기반의 방법을 통해 sensitive transformation을 진행했다. 이러한 결과는 이전 문장과 변형된 문장의 추가적인 cross-entropy loss로 이어졌다.
논문에서는 7가지의 STS task의 실험과 7가지의 SentEval 실험을 진행했고 기존 contrastive learning의 성능을 넘어섰다. 우리의 DiffCSE 방법은 SOTA를 달성했다
2. Background and Related Work
2.1 Learning Sentence Embeddings
<이 부분은 이전 SimCSE를 리뷰했으므로 생략.>
2.2 Equivariant Contrastive Learning
Input transformation, 입력값을 변환하는것은 contrastive learning에 있어서 가장 중요한 역할을 한다. NLP에서 dropout과 같은 transformation은 실제로 효과가 있다고 증명되었다. 그러나 SimCSE에서는 MLM과 같은 transformation은 실제로 embedding의 성능을 저하시켰다고 증명했다. Contrastive learning은 이러한 transformation에 insensitive 해야하고 encoder는 이러한 transformation으로부터 invariant하게 학습된다.
여기서 (in)sensitivity는 수학에서의 equivariance의 성질로 해석 가능하다. 만약 T가 group G로부터 나오는 transformation이고 x라는 input sentence가 있을 때, T(x)는 x가 transformation을 거치고 나온 문장으로 볼 수 있다. 여기서 equivariance를 통해 output feature에 대해서 동일한 값을 취할 수 있는 T'라고 볼 수 있다. 특별한 상황에서 T'가 identity transformation이 될 수 있고, 이러한 상황을 encoder f가 'invariant to T'하게 학습되었다고 한다. 그러나 invariance는 equivarince에서 아주 사소한 상황이고, 우리는 T'가 dropout과 같은 identity 성질을 가지고 있는 transformation에서 identity를 갖지 않는 MLM과 같은 objective function에서도 확장하여 적용할 수 있다.
Key observation은 encoder가 MLM-based augmentation과 equivariant해야한다. 그러기 위해 변환된 문장의 embedding을 결합하는 conditional discriminator를 사용했고 기존 문장과 변환된 문장의 차이를 예측했다. ELECTRA는 generator와 discriminator로 이루어진 model로 본 논문에서는 conditional한 discriminator를 사용했다고 했는데, 기존과는 달리 독립적으로 encoder에서 생성된 sentence embedding vector를 discriminator를 input으로 넣는것이라고 한다.
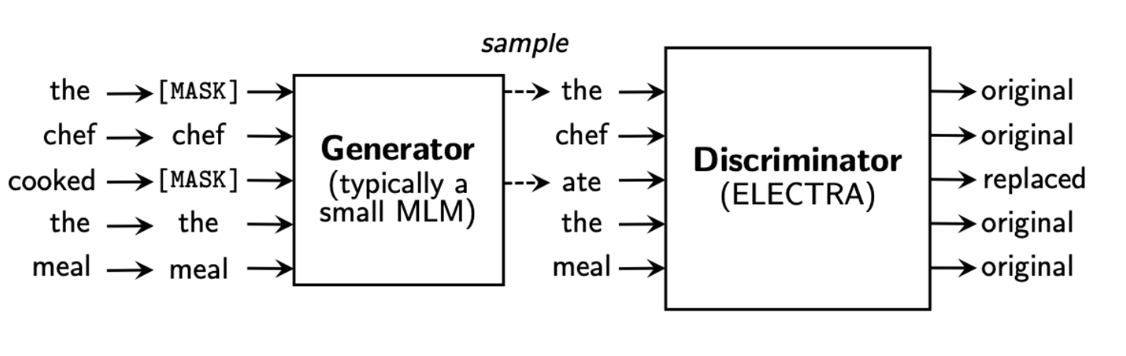
3. Difference-based Contrastive Learning
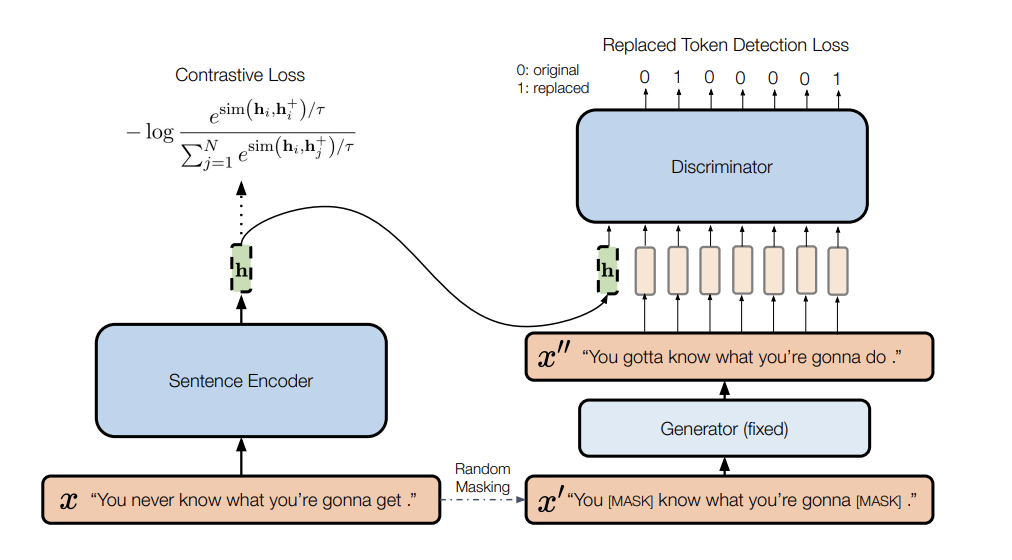
DiffCSE는 기존 SimCSE의 contrastive learning objective function과 difference prediction objective을 이었다고 볼 수 있다. Unlabel된 문장 와 dropout mask를 통해 생성된 을 encoder(BERT-base)를 거쳐 생성된 hidden vector를 positive pair로 보고 N size만큼의 batch에서 다른 문장의 관계를 negative pair로 설정하여 학습을 진행한다.
그리고 다른 PLM를 generator로 사용하여 masking을 진행하고 discriminator D는 RTD task를 진행한다. Model은 각각 생성된 token이 진짜인지 아닌지를 cross-entropy를 사용하여 예측한다.
결국 DiffCSE에서는 contrastive learning loss와 cross-entropy 2개의 loss를 같이 사용한다.
기존 ELECTRA와 우리와 다른점은 conditional discriminator를 사용한다는 점이다. 여기서 condition이란 SimCSE를 통해 나온 hidden vector가 discriminator의 condition으로 들어간다는 점이다. (cGAN이랑 동일한 구조인가..?)Generator에서 original sentence의 15%를 masking 해주고 SimCSE를 거쳐 생성된 sentence representation의 hidden vector를 condition으로 discriminator에 input으로 넣어 RTD로 학습을 진행한다.(cross-entropy)
그리고 기존 ELECTRA와는 다르게 generator를 freeze하고 discriminator만을 학습한다. Discriminator의 condition으로 들어간 hidden vector를 통해, gradient는 SimCSE를 진행한 sentence encoder f까지 역전파되어 학습이 진행된다. 결국 기존 문장의 의미를 잘 반영할 수 있게 학습이 가능하고 discriminator 또한 기존 문장 x와 generator로 생성된 x''의 사소한 차이를 구분할 수 있게 학습이 진행된다.
DiffCSE를 학습할 때, generator를 고정하고 sentence encoder f와 D를 optimize한다. 학습을 하고나서 sentence embedding을 evaluate할 때, D를 버리고 sentence encoder f만을 이용한다.
4. Experiments
4.1 Setup
- Checkpoint of BERT and RoBERTa initialization
- Add MLP layer and Batch Normalization on top of [CLS] representation
- Discriminator에서도 같은 model을 사용
- Generator에서는 DistilBERT와 DistilRoBERTa를 사용
4.2 Data
SimCSE에서 사용한 data를 똑같이 사용했다.(English Wikipedia) 7가지의 STS(Semantic textual similarity)와 7가지의 SentEval을 사용하여 model을 평가했다.
4.3 Results
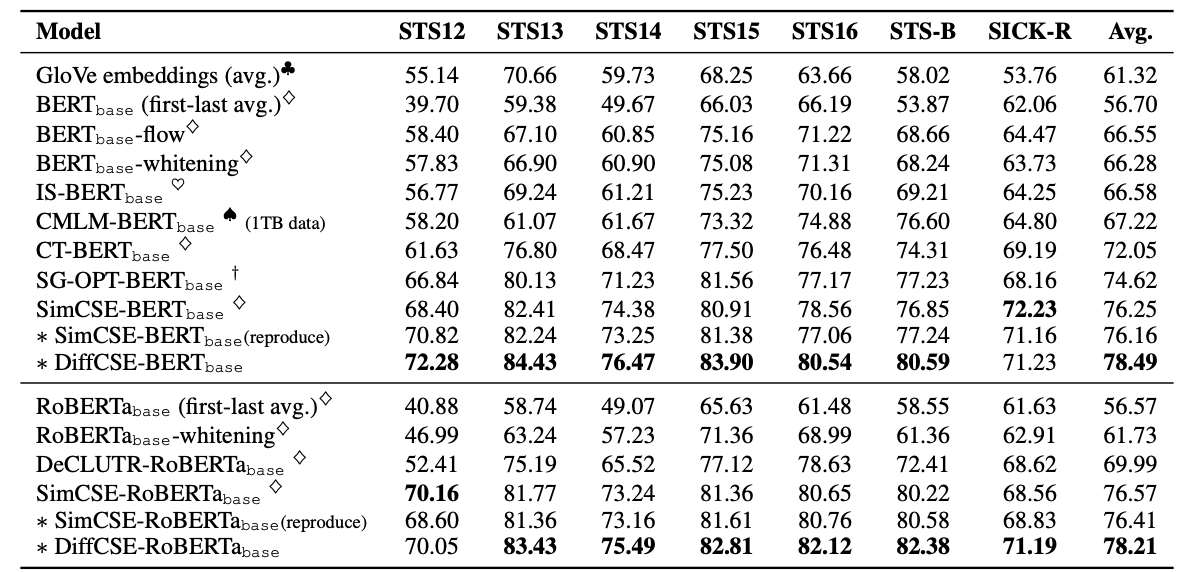
Baseline
우리는 많은 다른 SimCSE를 포함하여 다른 strong model과 비교를 진행했다.
- IS-BERT
- CMLM
- CLUTR
- CT-BERT
- SG-OPT
- BERT-flow
- BERT-whitening
- GloVe
Semantic Textual Similarity(STS)
BERT-base와 RoBERTa-base를 포함하여 STS의 결과를 보여주고있고, 이전 SOTA model인 SimCSE의 성능을 넘어섰다. DiffCSE-BERT-base의 성능은 SimCSE-BERT-base의 성능을 넘어섰고 Spearman's correlation의 평균 점수는 76.25%에서 78.29%까지 올렸다. 또한 RoBERTa의 성능은 76.59%부터 77.80%까지 향상시켰다.
Transfer Tasks
Transfer Task에서는 BERT-base의 경우 85.56%에서 86.86%로 성능을 향상시켰고 RoBERTa의 경우에는 84.84%에서 87.04%까지 성능을 향상시켰다.CMLM-BERT-base는 DiffCSE보다 성능이 더 좋았지만, CMLM-BERT는 1TB정도의 data로 학습을 했고 DiffCSE는 115MB data로 학습했기 때문이다.
5. Ablation Studies
본 논문에서는 model을 설계할 때, 추가적인 ablation studies를 진행했다. 먼저 contrastive loss 부분을 제거했는데 이는 곧 성능 저하로 이어졌으며, 이는 objective function에 꼭 필요한 요소임을 알 수 있다. STS-B task에서는 약 30%의 성능 저하가 생겼으며 평균 성능은 약 2%가 감소했다. 만약 RTD loss를 제거하면 결국 SimCSE와 다를게 없기 때문에 이에대한 실험은 진행하지 않았다.
다음으로는 discriminator에 same sentence hidden vector가 아닌 next sentence hidden vector를 condition으로 주었을 때의 결과를 확인했다. 결국 이는 다른 문장, 의미가 같지 않은 문장의 vector가 들어가는것으로 equivariant contrastive learning과는 전혀 다른것이라고 볼 수 있다. 밑에 table을 통해 STS-B의 성능이 매우 감소한것을 확인할 수 있다.
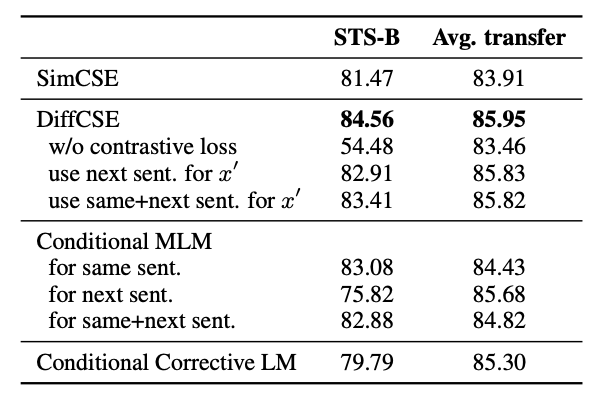
다음은 pretraining task로 다른 task를 수행할 때의 결과이다. 기존 binary difference prediction loss를 사용하는것이 아닌, conditional MLM objective과 corrective LM을 사용했을 때, 결과는 위의 table을 통해 알 수 있다. Same sentence에 대하여 conditional MLM을 적용했을 때, transfer task와 STS-B 둘다 성능 향상이 없었다. Conditional MLM을 next sentence에 적용했을 때 역시 성능은 하락했지만, same sentence에 적용하는것 보다 성능은 높았다. Corrective LM 또한 성능은 하락했다.
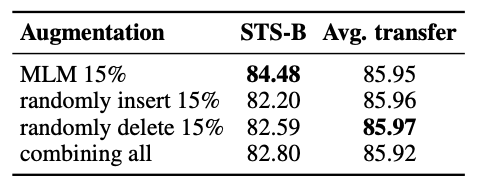
다음은 augmentation 방법을 바꾼것을 적용했다. DiffCSE에서는 MLM token replacement를 equivariant를 augmentation 방법으로 사용했지만 random insertion, deletion을 사용해서 결과를 확인했다. 위의 table에 이에대한 결과를 나타냈는데, 기존 문장에서 random하게 15%의 token을 지우거나 삽입했고 이에 대한 예측을 task로 진행했다. STS-B에 대한 성능은 약 15% 감소했고 transfer task에 대한 성능은 비슷했다. 결국 MLM replacement augmentation에 대한 성능이 제일 좋은것으로 확인됐다.
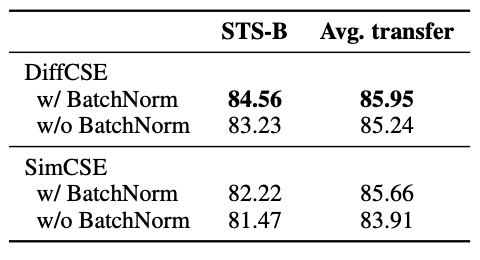
다음 ablation 연구로는 pooler choice에 대한 실험이다. 기존 SimCSE에서 저자들은 BERT의 기존 pooler를 사용하여 feature들을 추출하여 contrastive loss를 계산했다. 그러나 우리는 batch-normalization을 사용한 two-layer pooler를 사용했고 더 좋은 성능을 이끌었다.
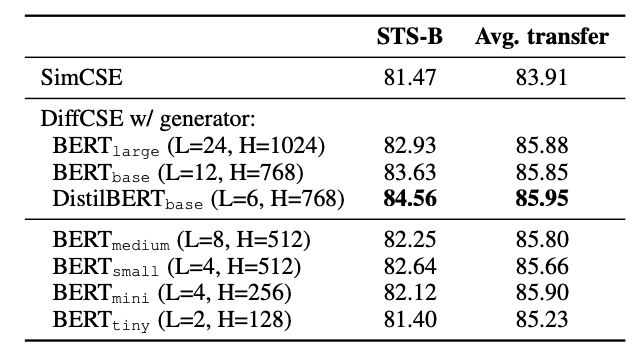
다음은 Generator의 size를 다양하게 사용해보며 성능을 비교했다. 기존 ELECTRA에서는 discriminator의 1/4부터 1/2까지의 size가 적절했지만 본 연구에서는 size가 작아질수록 더 안좋은 성능을 STS-B에서 보여줬다. 그러므로 큰 generator(BERT-base, DistilBERT-base)는 RTD를 더 어렵게 하여 discriminator를 더 잘 학습시킬 수 있다. 그러나 BERT-large와 같은 더 큰 model을 사용하면, discriminator는 너무 어려운 task가 될 수 있다. 따라서 본 논문에서는 적절하고 제일 성능이 좋았던 DistilBERT-base를 사용했다.

다음은 masking ratio에 대한 실험도 진행했는데, 30%일 때 STS-B 성능이 제일 좋았다.
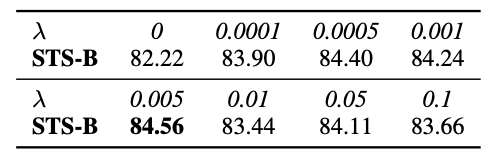
다음은 total loss에 적용되는 lambda값에 대한 실험이다. Contrastive learning이 RTD task보다 더 학습하기 용이하기에 생성되는 loss의 scale은 차이가 심하다. 그러므로 이에 대한 balance를 위해 lambda를 곱해줬는데 0.005일 때, 성능이 제일 좋았다.
6. Analysis
6.1 Qualitative Study
Sentence embedding의 성능을 가장 잘 확인할 수 있는 방법은 retrieval task이다. 본 연구에서는 STS-B에서 2758개의 문장을 test set으로 사용했고 코사인 유사도를 계산했다. SimCSE는 Query : "you can do it, too"와 "you can use it, too."와 같이 거의 비슷한 의미의 문장 유사도를 구분하지 못했지만, DiffCSE는 아주 작은 차이라도 잘 잡아낼 수 있었다. 그러나 SimCSE와 DiffCSE 둘다 이중 부정에 대한 정확한 답을 알아낼 수 는 없었다.
6.2 Retrieval Task
다음은 정성평가와 같은 실험은 정량평가로 판단하기 위해서 top-1/5/10에 대한 recall값을 나타냈을 때, DiffCSE가 더 좋은 성능을 보여줬다.
6.3 Distribution of Sentence Embeddings
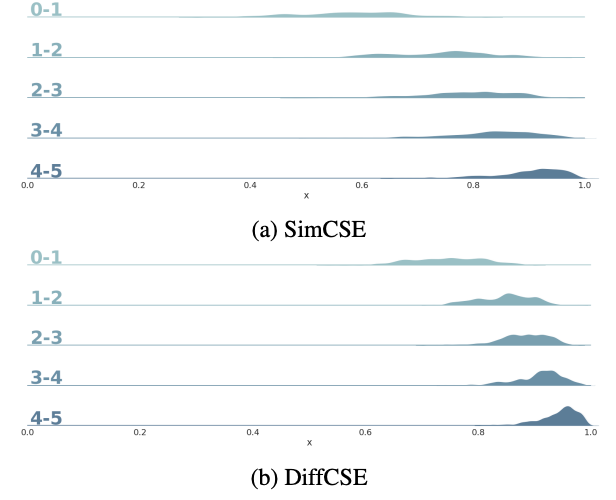
DiffCSE의 representation space를 확인하기 위해 코사인 유사도를 plot으로 확인했다. DiffCSE가 SimCSE보다 더 높은 코사인 유사도값을 보여줬고 alignment와 uniformity에 대한 비교실험도 진행했다. DiffCSE에서는 높은 alignment값을 보여줬고 SimCSE에서는 높은 uniformity를 보여줬다. 이는 SimCSE를 거쳐 나온 sentence embedding의 vector값이 squeezing되었기 때문이라고 한다. Transformer 모델의 한계점으로는 representation vector가 squeezing됨에 따라, uniformity가 낮아진다고 선행연구 결과가 있었고 Transformer의 contextualized representation은 low layer에서 isotropic한 성질을 갖지만 layer를 쌓을수록 anistropic한 성질을 갖게 된다.
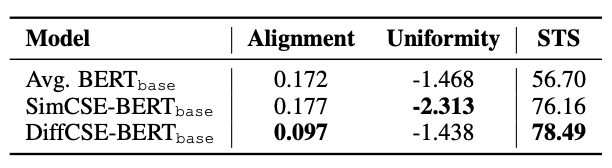
위의 table은 alignment와 uniformity를 기준으로 성능을 비교한 결과이다.
7. Conclusion
본 논문을 통해 DiffCSE란 framework를 제시했고, SOTA를 달성했다. MLM-based word replacement를 통해 sentence embedding을 생성했고 다른 augmentation에 대한 실험도 진행하여 유의미한 연구라고 생각한다. 그러나 SimCSE와 동일한 구조와 dataset을 사용했다는점이 한계점이라고 논문에서 밝히고 있다.
