0.Abstract
Sentence embedding을 학습하기 위해서는 label된 큰 규모의 data가 필요하다. 그러나 대부분의 task와 domain에서는 당연히 큰 규모의 data를 구하기는 쉽지 않다. 따라서 본 논문에서는 unsupervised 기반의 새로운 SOTA model인 TSDAE를 소개한다.(6.4% 향상) 또한 이 model은 domain의 supervised approach에서는 93.1%정도의 성능을 자랑한다. 게다가 논문에서는 TSDAE가 domain adaptation, 즉 특정 domain에서도 성능이 잘 나올 수 있고 pre-train 방법에서도 좋은 성능을 자랑한다. 결국 pre-train과 fine-tuning 둘 다 좋은 성능을 보여준다는것 같다.
본 논문의 또 하나의 중요한 점은 이전 연구에서는 모두 narrow evaluation, 즉 domain의 정보가 전혀 중요하지 않은 STS single task로만 평가를 진행했던 부분을 다른 domain의 4가지의 추가적인 dataset을 사용하면서 극복했다고 한다.
1. Introduction
Sentence embedding은 dense vector space에 의미가 비슷한 문장들은 가깝게 위치하며 문장을 하나의 vector로 압축한다. 이전 좋은 성능을 보여줬던 InferSent, USE(Universal Sentence Encoder), SBERT(SentenceBERT) 모두 label된 data를 사용했다. 그러나 대부분의 task와 domain에서는 label된 data는 구하기 힘들다. 이러한 한계점을 극복하기 위해서 unsupervised기반의 방법론들이 제안되기 시작했다.
본 논문에서는 Transformer-based Sequential Denoising Auto-Encoder (TSDAE)을 제안했고 이것은 encoder-decoder 기반의 architecture에서 SOTA를 달성했다. 훈련하는 과정에서 TSDAE는 corrupt된 문장을 하나의 fixed-sized vector로 encode했고 decoder를 통해 sentence embedding을 통해서 기존, 원본 문장으로 복구했다. 좋은 질의 문장으로 복구하기 위해서 semantic은 encoder로 부터 sentence embedding을 잘 capture되어야 한다. 그리고 inference 단계에서, 논문에서는 encoder만을 사용하여 sentence embedding을 만든다.
이전 연구들의 한계점으로는 unsupervised approach를 평가하는데 있다. SemEval의 STS를 주로 평가하는데 사용했지만 이것은 충분한 평가지표로 사용하기는 힘들다. STS dataset은 domain의 정보를 담고있지 않은 dataset이고 인위적인 score distribution이기 때문에 성능을 평가하는데에 상관관계가 있지 않다. 즉, STS로 평가를 진행하는데는 task에 얼마나 잘녹아드는지 확인하기가 어렵다는 뜻이다.
이러한 질문에 대한 답으로 논문에서는 TSDAE를 세가지 다른 task(Information Retrieval, Re-Ranking, Parapharse Identification)의 domain과 다른 text style을 비교했다. TSDAE는 6.4정도의 점수를 올리며 SOTA를 달성했고 큰 규모의 label된 data로 학습된 USE-large보다 더 좋은 성능을 보여줬다.
게다가 본 논문에서는 TSDAE가 domain adaptation에 뛰어나고 MLM을 포함한 여러 다른 pre-training방법도 좋다는것도 증명했다.
- Denoising auto-encoder를 사용하여 unsupervised method에서 6.4 point의 성능을 올려 SOTA를 달성
- 다양한 domain에 대한 여러 task에서 unsupervised method를 통해 sentence embedding을 비교
- Pre-training과 domain adaptation이 다른 방법보다 더 좋은 성능을 보여줌
2. Related Work
2.1 Supervised Sentence Embedding
대부분의 sentence embedding은 sentence pair의 유사성을 고려하는데 사용되기 때문에 가장 직접적인 방법으로는 훈련 data에 labeling을 부여한다. 많은 연구들 또한 NLI(Natural Language Inference), Q&A, conversational context의 dataset을 통해 sentence embedding을 훈련한다. 최근에 제안된 Sentence-BERT는 sentence embedding을 위해 pre-trained Transformer를 제안했다. 좋은 quality의 sentence embedding이 supervised 학습을 통해 생성될 수 있지만, 실용적인 측면에서 바라봤을 때 이는 한계점이 존재한다.
2.2 Unsupervised Sentence Embedding
최근에 많은 연구들은 pre-train된 Transformer기반의 LM으로 sentence embedding을 뽑는데 SOTA를 달성했다. 그중에서도 Contrastive Tension(CT), 동일하거나 다른 의미의 문장들을 positive pair 혹은 negative pair로 보고 두개의 독립적인 encoder를 학습하는 방법, BERT-flow, Gaussian분포로 embedding distribution을 debiasing하면서 학습하는 방법, SimCSER,contrastive learning을 기반으로 동일한 문장에 대해서 dropout masking을 다르게 하여 positive example, batch안에 다른 문장을 negative pair로 설정하여 학습하는 방법이 있었는데 이러한 방법은 모두 독립적인 문장을 요구했다. 그러나 DeCLUTR, 문장 길이의 context를 학습에 활용하는 방법과 함께 본 논문에서는 하나의 문장을 사용하는 방법을 적용했다.
대부분의 다른 연구에서는 STS를 통해서 sentence embedding을 평가했다. 그러나 unsupervised approach이 STS를 통해 학습되지 않아도 out-of-the-box 사전학습된 supervised model보다 성능이 좋지않다. 게다가 STS에서 좋은 성능을 가져도 downstream task에서 안좋은 성능을 보일 수 있다. 이는 아직 검증이 많이 필요한 단계인데, 이를 위해 3가지 unsupervised method를 기반으로 한 모델과 성능을 비교했다.
3. Sequential Denoising Auto-Encoder
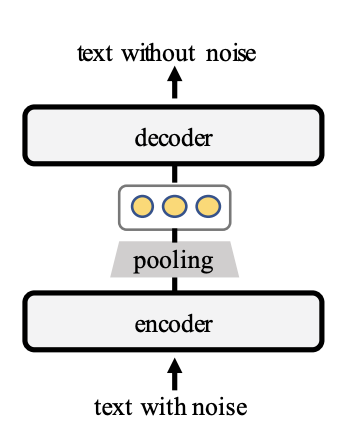
Sequential Denoising Auto-Encoder(SDAE)는 머신러닝에서 자주 사용되는 unsupervised approach지만 sentence embedding을 학습하기 위해 사전 학습된 어떻게 Transformer 기반의 architecture와 결합하는지는 아직 명확하지 않다. 본 논문에서는 처음으로 TSDAE의 training objective에 대해 소개하고 최적의 configuration을 제공한다.
3.1 Training Objective
TSDAE는 input sentence에 특정 noise(deleting or swapping words)를 주면서 손상된 input sentence를 fixed-sized vector로 encoding한다. 그리고 vector를 기존 sentence로 복구하는 과정을 거치게 된다.
- D : training corpus
- : input sentence의 token(개)
- : denoised sentence
- : 의 sentence embedding
- : vocab_size
- : hidden state(decoding time-step -> t)
기존 transformer와 다른 차이점은 decoder 단계에서 정보를 이용할 수 있다는점이다. TSDAE의 decoder는 encoder에서 만들어진 fixed-sized vector만을 사용하여 decoding을 진행한다. Encoder에서 모든 contextualized word embedding을 사용하지 않는다. 그리고 decoder에서 bottleneck을 유발하여 encoder가 의미있는 문장을 만들 수 있게 한다.
기존 auto-encoder에서도 입력 데이터의 압축된 knowledge를 만들기 위해 network에 bottleneck을 둔다. 병목현상은 전체 네트워크를 통과할 수 있는 정보의 양(fixed-sized vector)을 제한하여 입력 데이터의 학습된 압축을 이끌어 내는 역할을 한다.
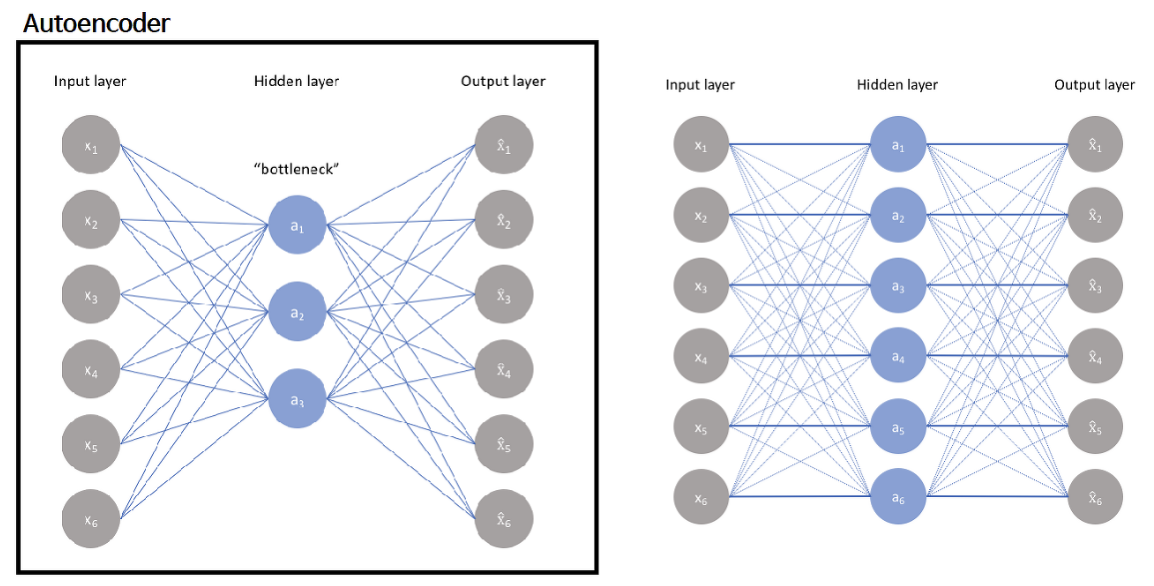
그림을 보면 auto-encoder는 왼쪽 그림과 같이 label이 없는, unlabeled dataset인 를 가지고 를 만든다고 학습하면 reconstruction error, 입력데이터와 재건한 데이터의 차이를 최소화되도록 학습한다. 이 네트워크에서 bottleneck이 핵심인데 이가 없다면 오른쪽 그림처럼 그저 간단하게 암기하여 모델이 제대로 학습되지 않는다.
3.2 TSDAE
TSDAE의 architecture는 encoder-decoder Transformer를 수정했으며, key와 value는 모두 sentence embedding의 cross-attention을 이용했다.
- : decoder에서 k번째 layer의 hidden state (d = embedding dimension)
- : sentence embedding vector를 포함하는 one-row matrix
STS dataset에 대한 다양한 실험 결과를 통해 최적의 조합은 다음과 같이 정리할 수 있다.
(1) Deletion ratio 0.6
(2) [CLS] token을 fixed-sized sentence representation으로 활용
(3) Encoder와 Decoder parameter tying
4. Evaluation
이전 unsupervised sentence embedding learning approach를 평가하기 위해서는 주로 SemEval의 STS를 통해 Pearson이나 Spearman's rank의 correlation을 통해 진행했다.
본 논문에서는 STS로만 평가하는데 있어 문제점을 발견했다. 먼저 STS dataset은 downstream task의 performance와는 correlate되어 있지 않다. 여기에는 다수의 이유가 존재한다. 먼저 STS datasets은 domain knowledege가 필요없는 뉴스 자막이나 image caption으로 구성되어있다. 두번째는 STS datasets은 similar pair와 dissimilar pair가 인위적으로 구성되어있다. 마지막으로 보통 similar에 대한 rank가 중요하지만 STS에서는 dissimilar와 similar 두가지에 대한 rank가 중요하다.
이러한 평가방법의 단점으로는 이전 평가방법은 오로지 unsupervised learning에 대한 경우에만 setup으로 labeled data를 무시한다. 그러므로 우리는 unsupervised sentence embedding에 대한 세가지 setup에 대하여 평가를 진행했다.
Unsupervised Learning
- 특정 task에 대하여 labeled sentence가 있다고 가정하고 이러한 문장에 맞추어 진행
Domain Adaptation
- 특정 task에서 unlabeled sentence를 NLI dataset와 STS benchmark에서 unlabeled sentence가 있다고 가정하고 두가지 setup에 대해서 test를 진행
1) NLI + STS data를 통해 train하고 target domain에 unsupervised training을 진행
2) unsupervised train하고 NLI + STS를 통해 supervised train 진행
Pre-training
- target task에 대하여 큰 unlabeled data가 있고 target task에 대하여 작은 labeled sentence가 있다고 가정
4.1 Datasets
본 논문에서는 3가지 다른 task의 setting에 대하여 평가를 진행했다.
AskUbnuntu (RR task)
모델은 20개의 후보 질문을 input으로 들어가고 유사한 순서대로 다시 ranking된다. 이때 MAP를 이용하여 평가 진행했다.
CQADupStack(IR task)
Stack-Exchange에서 다양한 topic에 대하여 forum post로 구성된 question-retrieval dataset이다. 구체적으로 12개의 forum을 가지고 있고 모델은 주어진 pool에서 질문을 찾아내야한다. 마찬가지로 MAP를 평가지표로 사용했고 모든 forum에 대해서 하나의 모델을 학습하게된다.
TwitterPara(PI task)
Twitter Paraphrase Corpus와 Twitter News URL corpus로 데이터셋이 구성되어있다. Dataset은 모두 tweet, sentence 쌍으로 구성되어 있고 paraphrase에 대하여 score가 labeling되어 있다. 평가지표로는 model이 산출한 similarity와 정답에 대한 confidence score에 대하여 average precision을 사용했다.
SciDocs(RR task)
여러 scientific papers로 구성된 task에 대한 benchmark dataset이다. Papers의 제목에 대해 자주 인용(co-cited, -read, -veiwed)되는 paper를 찾는 task이다. 이때 papers의 제목이 query로 주어지게되고 모델은 제목 후보 30개 중에서 5개의 관련 논문 제목을 식별하게된다. 평가지표로는 MAP를 사용했다.
모든 평가에서 sentence는 fixed-sized vector로 encoding되고 cosine-similarity를 통해 유사도를 계산했다.
5. Experiments
이 section에서 앞서 설명한 task에 대하여 여러 다른 unsupervised pre-trained model과 성능을 비교했다. 비교를 위해서 CT, SimCSE, BERT-flow를 선택했고 논문에 기반하여 hyper-parameter를 지정했다. Randomness를 줄이기위해 5개의 random seed에 대하여 평균을 계산했다.
5.1 Baseline Methods
- GLoVe, Sent2Vec을 사용
- BERT-based-uncased with mean pooling
- Universal Sentence Embedding(USE) : NLI dataset과 Q&A를 포함하여 supervised learning을 진행
- SBERT-base-NLI-v2 : SNLI + MultiNLI data를 사용해서 Nultiple-Negative Ranking Loss(MNRL)을 통해 학습했다.
- SBERT-base-stsb-v2 : STS benchmark dataset에 대해 학습했다.
- BM25
Relative performance에 대하여 보다 더 자세히 이해하기 위해 SBERT model을 in-domain supervised 방법을 통해 훈련했고 이 score를 upperbound로 간주했다.
MNRL은 batch-negative의 cross-entropy loss이다. Sentence pair의 batch 에서 label된 문장을 positive로 다른 batch안의 조합을 negative로 간주한다.
- : vector의 similarity function
- : sentence embedding을 진행하는 encoder
5.2 MLM
MLM은 BERT에서 사용된 pre-train objective function이다. Sentence embedding을 계산하기 위해서 output token embedding에 mean-pooling을 적용했다.
