Transformer의 경량화에 대한 개인 연구를 진행하면서, 비슷한 메카니즘에 대한 논문을 찾아 리뷰하고자 한다.
0.Introduction
여전히 Transformer는 domain에 국한되지 않고 좋은 성능을 보여주고 있다. Transformer의 가장 핵심이 되는 메카니즘인, Attention은 전체 sequence에 대해서 모든 timestep마다 pairwise interaction을 통해contextual information을 capture할 수 있다. 그러나, Transformer의 공통적인 약점은 당연히 quadratic time과 memory를 많이 잡아 먹는다는 것이다. Self-Attention의 계산량은 총 sequence length의 제곱이다.(Query dot product with Key)
이에 따라, 위 계산량을 감소시킨 선행 연구가 여럿 존재한다. 이 중 대표적으로 attention matrix를 low-rank approximation한 "Linformer"라는 모델이 있다. 이는 projection, 즉 차원 축소를 했을 때 sample간의 거리가 보존되는 사영이 존재한다는 것을 실험을 통해 증명했다. 결국 self-attention의 matrix는 low-rank 행렬이니, SVD를 통해 저차원을 근사해도 정보를 잃어버리지 않는다고 주장했다. 그러나, attention matrix에 SVD분해를 진행하는 것은 굉장히 비효율적이기 때문에, Key와 Value matrix를 사영시키는 방법으로 연산량을 감소시켰다. (이때, model의 hidden dimension이 아닌, length를 축으로 사영하기 때문에, 고정된 길이의 input을 사용해야함.)
본 모델은 긴 input sequence에 반비례하게 복잡해지지만, 성능과 효과는 좋다고 주장한다.
본 논문에서는, a linear unified nested attention mechanism (Luna)를 제시한다. 두개의 nest된 activation function을 통해 softmax function의 근사하는 방법이다.
먼저, Luna 모델은 input sequence를 고정된 길이로 잘라 attention이 진행된다.(Packed) 다음으로 pack된 sequence를 두번재 attention을 통해 unpack 과정을 진행한다.
Luna는 extra input을 같이 학습하면서, ouput으로도 extra sequence를 출력한다. 또한 Linformer와 마찬가지로 linear한 attention을 진행하면서 적절한 information을 store한다. 또한 Linformer의 한계점인, variable한 길이의 sequence에 대해서 autoregressive한 attention을 못한다는 점도 개선했다.
1. Linear Unified Nested Attention(Luna)
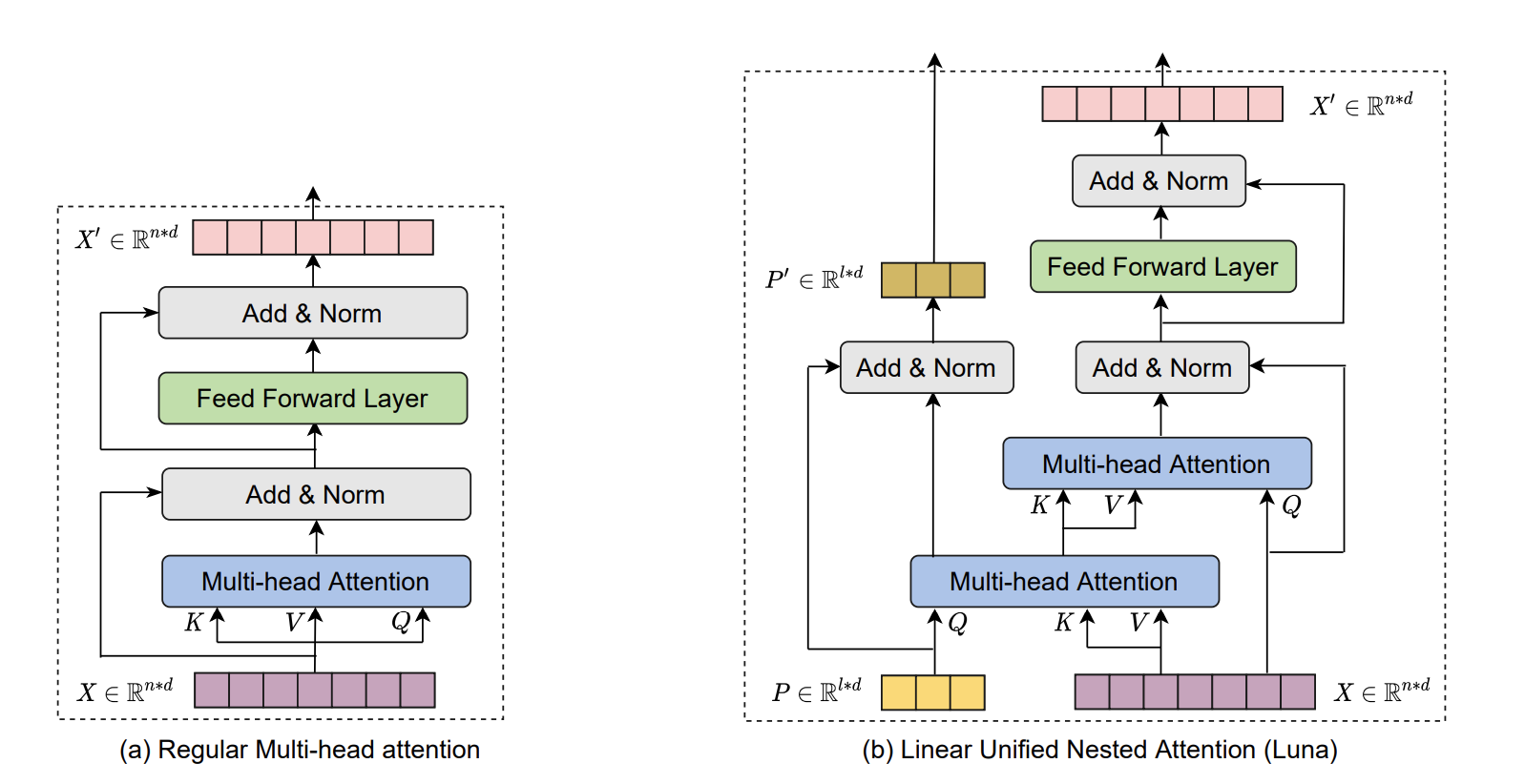
1.1 Pack and Unpack Attention
두개의 attention 모두 linear attention을 적용했다. 먼저 query를 sequence보다 짧은 고정된 길이로 설정하고 전체 sequence(key)와 attention을 진행된다. 이때 연산량은 아래와 같다.
(l은 query의 길이, m은 전체 sequence의 길이)
이때 pack attention의 output shape인 packed context의 shape은 가 된다. 두 번째 attention인, unpacked attention에서는 packed context를 key로 설정하고 전체 input sequence를 query로 하여, unpacked attention을 진행한다. 이때 unpacked attention의 연산량은 다음과 같다.
Encoding Contextual Information in P
하나의 단점으로 는 어떠한 contextual한 정보를 담고 있지 않다. 이러한 단점을 극복하기 위해, packed attention의 output을 다음 layer의 로 사용하면서 이를 극복했다.
Reducing the Number of Parameters
또한 두개의 attention을 진행하는데 있어, 기존 transformer보다 두배의 parameter를 사용하게 되지만, weight sharing을 통해 이를 해결했다.
1.2 Luna Layers
Pack attention의 output인 와 unpacked의 output인 에 대해서 둘다 layer normalization을 진행했지만, FFN은 오직 에 대해서만 진행했다.
1.3 Luna Causal Attention
기본적으로 Decoder의 autoregressive self attention에서는 과거의 정보로만 attention을 진행한다. 그러나, pack attention에서의 고정된 길이의 짧은 sequence가 사용되기 때문에 이를 기존 casual attention 방식을 사용하기 어렵다.
따라서 본 저자들은 가 의 정보를 가지고 있지 않다고 가정하고 의 미래 정보를 누출하지 않는다고 가정했다. 먼저 casual function은 아래와 같다.
여기서 는 의 t번째 행을 의미한다. 다음의 식을 통해 는 오직 과거와 현재의 , , 의 row만 참조한다.
Luna causal attention을 실행하기 위해, pack attention의 pack attention을 진행한다.
우리는 미래를 참조하지 않으려면 softmax를 사용할 수 없다. 따라서 우리는 두개의 activation function을 활용했다.
1) w(.) = elu(.) + 1
2) w(.) = softplus(.)
그리고 unpack attention에 대해서는 softmax함수를 활용할 수 있는데, l-dimension에 대해서 normalization이 적용되었기 때문이다.
또한 Luna는 only-decoder모드에서도 활용될 수 있는데, 이때 는 learnable parameter로 활용될 수 있다.
2. Experiments
먼저 byte-level text classification task 다양한 level의 input length에 대해 실행한 결과이다.
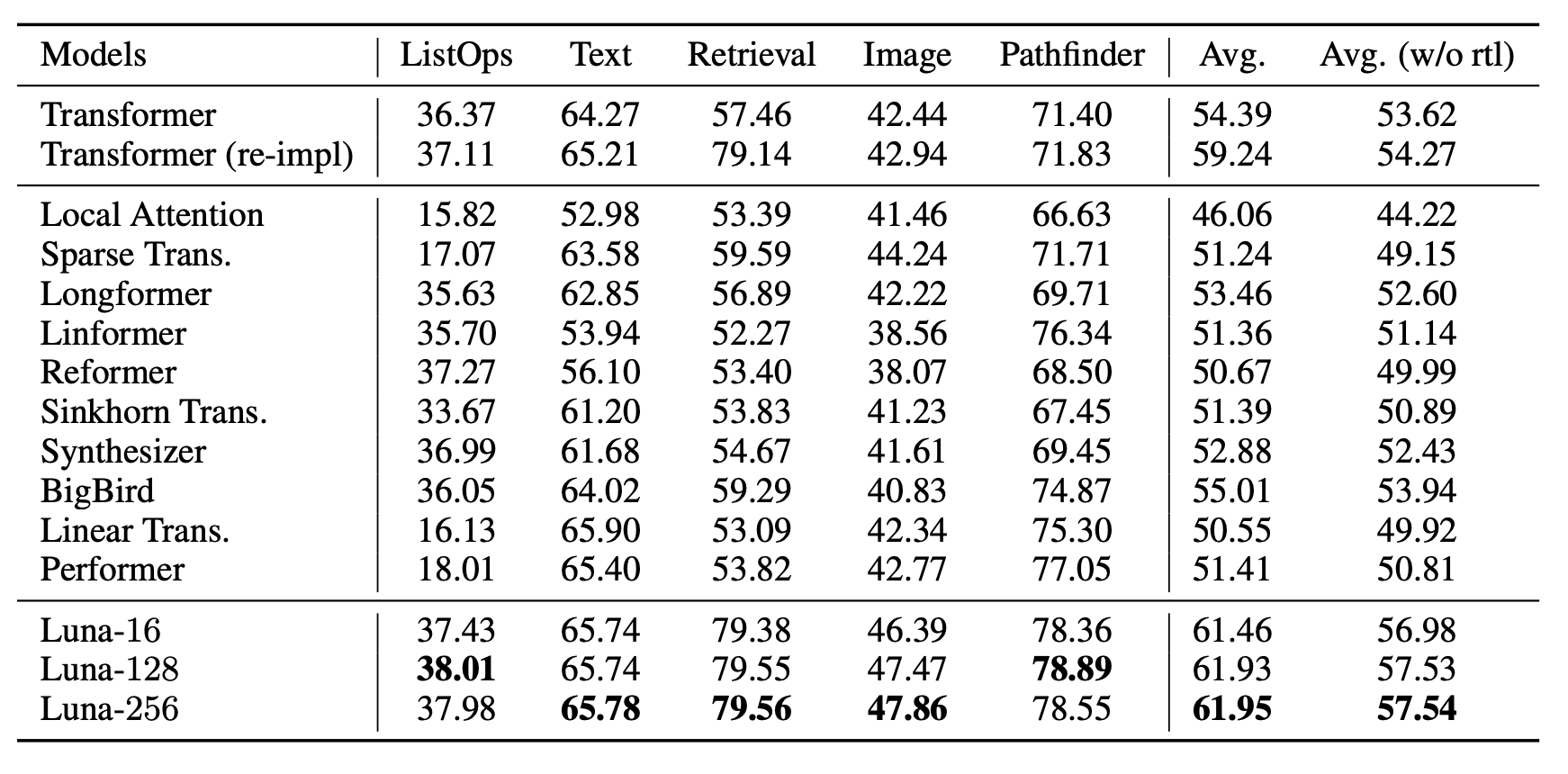
저자는 proeject dimension을 3가지로 나누어 진행했다. 3가지 모두 좋은 성능을 보여줬고 기존 baseline 모델보다 더 좋은 성능을 보여줬다.
Memory and Speed Efficiency
다양한 input length(1k, 2k, 3k, 4k)에 대해서 speed와 memory foot print에 대해 조사했다.
먼저 memory efficiency에 대해서 Luna는 를 16 dimension으로 맞출경우, 기존 transfomrer보다 10%의 memory를 사용한다. 128, 256차원으로 projection해도 여전히 기존 vanilla transformer보다 효율적인 memory를 사용한다.
다음 speed 측면에서는 Luna-16은 기존 transformer보다 1.2~5.5배 더 빠른 속도를 보여준다. LRA benchmark 데이터셋에서 여타 다른 model과 비교해도 가장 빠르고 효율적이며 좋은 성능을 보여준다.
2.1 Machine Translation
Luna의 seq2seq modeling에서 WMT machine translation(EN -> DE) dataset에서 성능을 비교했다.
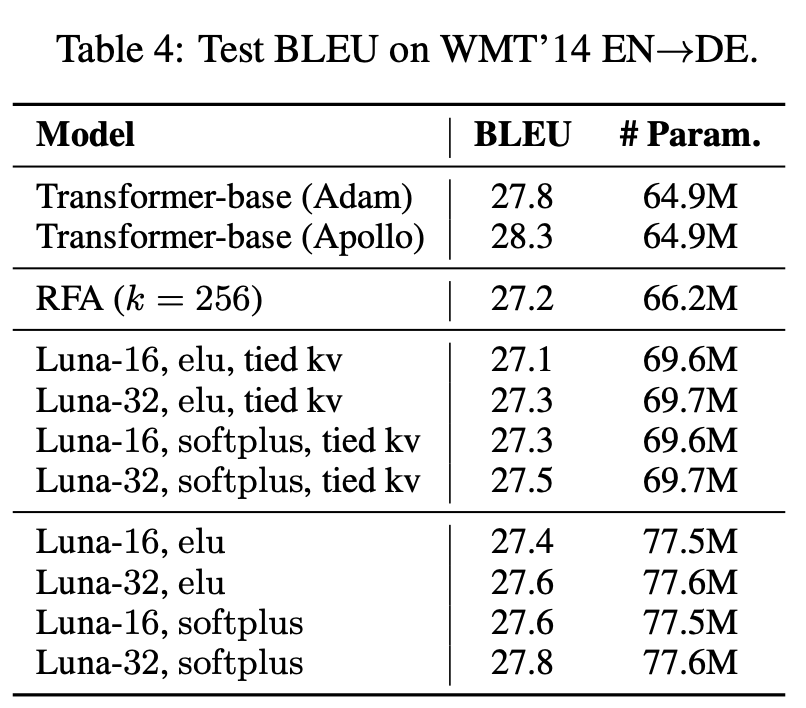
두번의 attention을 진행하기 때문에, parameter수는 많지만 그럼에도 좋은 결과를 보여준다.
본 논문을 리뷰한 이유는 현재 진행하고 있는 transformer 경량화 연구와 비슷한 메카니즘을 가지고 있기 때문이다. Luna는 많은 연산량을 보이고 있는 attention 연산을 두번으로 나누어 효율적으로 attention을 진행하는것이 현재 내가 연구하고 있는것과 비슷한 양상이다. 연구를 진행함에 있어 성능에 대한 우려가 있었지만, 본 논문을 읽으면서 성능이 크게 떨어지지 않을 수 있다는 생각도 들었다.
