1. Introduction
NLP domain에서 Transformer는 기존 RNN module의 한계점을 극복하면서 현재 거의 모든 language model의 기본으로 사용되고 있다. 최근에는 Vision Transformer가 등장하면서 Vision domain에서도 CNN module 없이도 좋은 성능을 보여줬다.
1.1 Vision Transformer
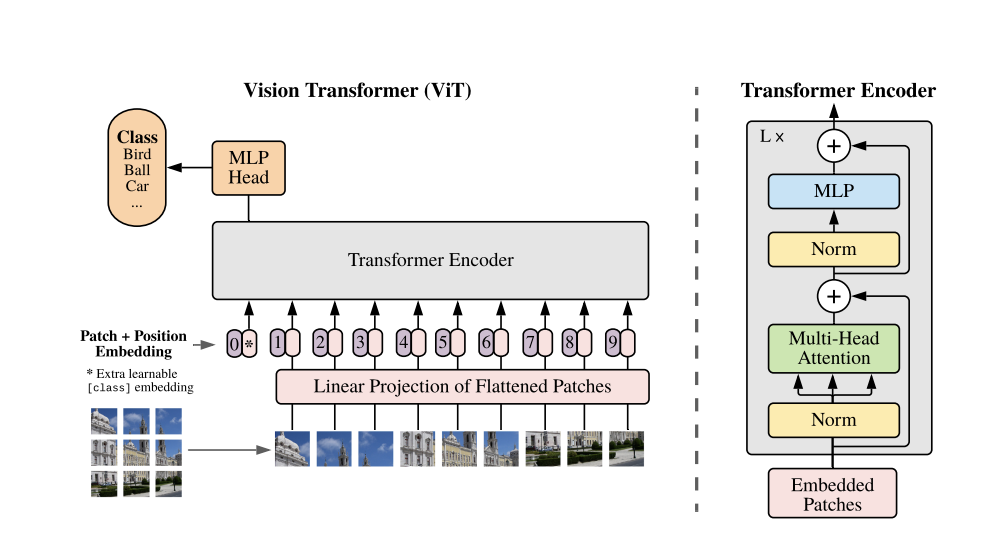
먼저 ViT(Vision Transformer)는 Transformer Encoder block을 그대로 가져와서 사용했으며 input image를 patch(16x16)단위로 쪼개서 1차원으로 flatten한다. 다음으로 d차원으로 projection한 patch embedding을 input으로 넣게되고 encoder 층을 거치면서 output을 만들어낸다.
그러나 이런 ViT에도 한계점이 드러나는데, 기존 NLP에서 사용되는 Transformer와도 연결되는 점으로 'Inductive Bias'가 부족한다는 점이다.
기존 NLP에서도 Transformer기반의 여러 Language Model은 대부분 큰 dataset을 사용하고 많은 수의 parameter를 가지고 있다. 예를 들어, BERT-large는 340M parameters를 가지고 있고 BART-large는 400M parameters, T5-large는 770M parameters, 등 굉장히 무거운 model임을 알 수 있다. 그렇다면 왜 이렇게 model이 무거운것일까? 바로 model의 Inductive Bias가 부족하기 때문이다. 기존 RNN module의 bias는 sequential한 data가 들어왔을 때, 가까운 sequence들 끼리는 더 많은 영향을 주고 받게 되는데, 긴 문장이 들어왔을 때 dependency가 부족하여 이를 transformer의 Self-Attention과 Positional Encoding을 통해 극복한것이다. 따라서 기존 RNN의 bias를 채우기 위해 큰 데이터셋과 많은 parameter를 통해 이를 극복했다라고 생각할 수 있다.
그렇다면 Vision domain에서도 CNN module은 locality에 대한 가정이 들어가있는데, 이는 Convoluiton 연산과정을 생각해보면 쉽게 이해할 수 있다. 따라서 기존 CNN은 local representation에 대해서는 잘 학습했지만 global representation에 대해서는 학습이 어려웠기 때문에 이를 ViT를 통해 극복했다라고 볼 수 있다. 그러나 기존 CNN의 bias를 채우기 위해서 마찬가지로 큰 dataset과 많은 parameter를 사용할 수 밖에 없다.
ViT의 결과를 보면 큰 dataset(14M ~ 300M)에서 성능이 잘 나오고 대규모 train을 통해 극복한것을 확인할 수 있다.
2. MobileViT version 1
MobileViT는 결국 모델이 많이 무거워지면서 효율성을 잃기 때문에 CNN과 ViT를 결합하여 local representation과 global representation을 동시에 학습하여 inductive bias의 부족함을 극복할 수 있는 모델을 제시했다.
MobileViT-1 architecture은 아래 그림과 같다.
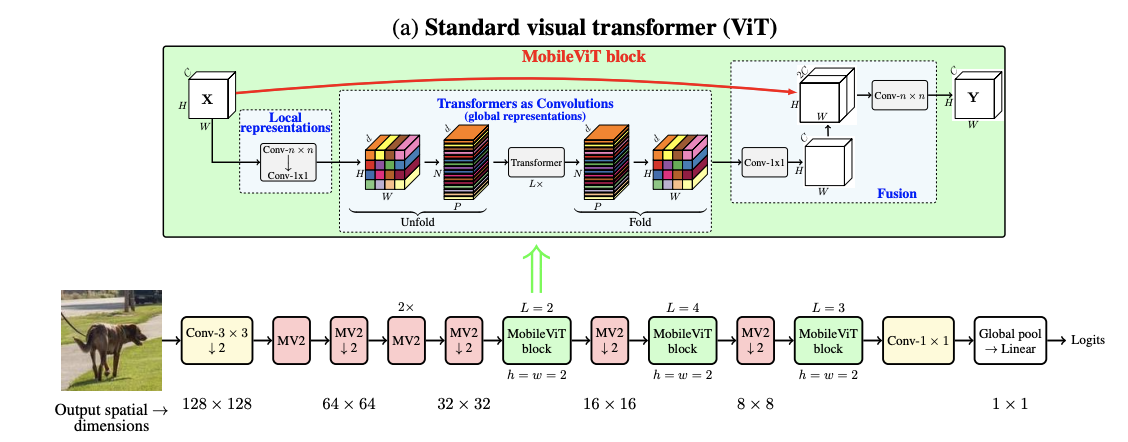
위의 그림이 본 논문에서 제시한 CNN과 ViT를 결합한 MobileViT block이다. 먼저 연산과정을 정리하면 다음과 같다.
- Input tensor에 nxn convolution layer 적용 - local representation 학습
- Point-wise convolution layer를 통해 high dimension으로 projection
- Transformer encoder layer 적용 - global representation 학습
- Point-wise convolution layer를 통해 low dimension으로 projection
- nxn convolution layer 적용 - local과 global information fusion
Input tensor의 dimension이 일 때 1번과 2번 연산을 거치면 의 output을 가지게된다.

Local Representation을 학습한 output 을 3번 연산(Vision Transformer block)을 진행하기 전에 unfold를 진행한다. 이는 input tensor를 서로 겹치지 않는 patch로 만드는 과정으로 unfolding을 통해 으로 만든다.
( patch의 가로, patch의 세로 크기)
(로 input tensor내에 존재하는 패치의 수)

Transformer가 local spatial information과 inner patch information을 모두 학습하기 위해서는 patch의 size가 convolution layer kernel의 크기보다 작아야한다.
각 patch 안의 relationship, 즉 local representation을 nxn convolution layer을 통해 학습한다. 이후, L개의 Transformer layer를 거치면서 각 patch간의 relation ship, global representation을 학습한다.
결국 는 local information을 학습한 결과이며 는 다른 patch들과의 global information을 학습한 결과이다.
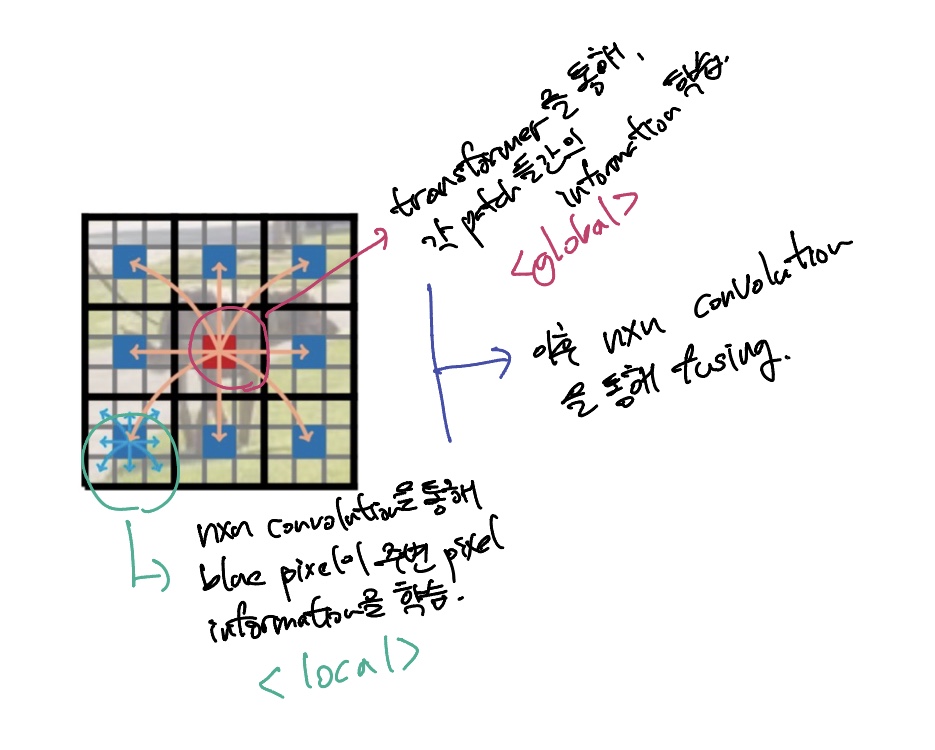
이후, 를 다시 fold하여 를 얻는다. 그리고 이전 point-wise convolution layer를 통해 Channel dimension으로 맞춰주고 input tensor와 concat하여 nxn convolution layer로 fusing해준다.
아래 fowarding code를 보면 progress를 쉽게 이해할 수 있다.

3. MobileViT version 2
다음은 MobileViT version 2로 논문의 제목은 "Separable Self-attention for Mobile Vision Transformers"로 기존 MobileViT의 attention module을 변화 시킨것을 알 수 있다.
Transformer에서 가장 연산량과 시간을 많이 잡아먹는 곳은 아무래도 Multi-headed self-attention이다. Token이 k개가 있다고 가정할 때, 각 token마다 의 연산량과 시간이 소요된다.
따라서 본 논문에서는 separable self-attention을 도입해 기존 연산량을 linear complexity로 해결했다. 단순하지만 효과적인 self-attention은 element-wise operation을 활용하고 edge device에서도 본 모델을 활용 가능하다.
3.1 Multi-headed self-attention
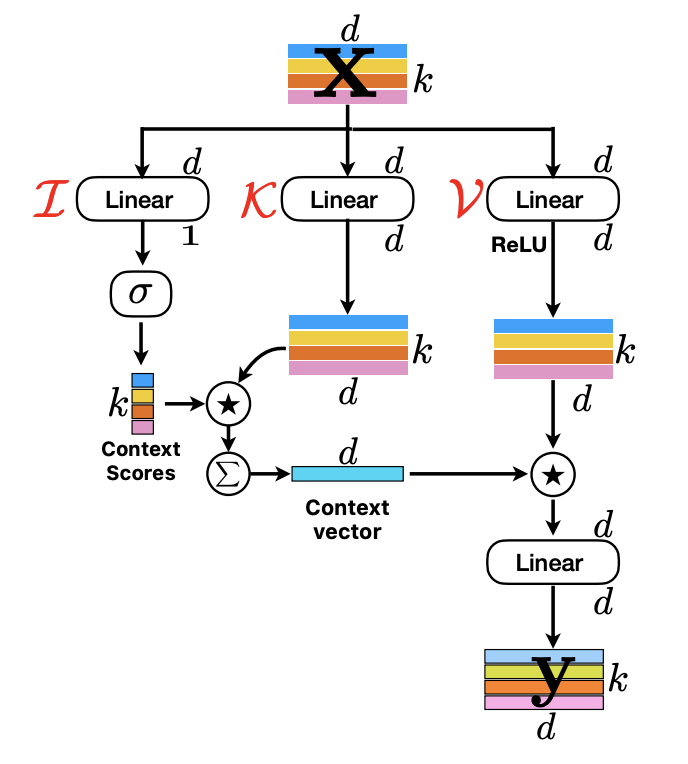
기존 multi-headed self-attention은 input이 일 때, query, key, value 3가지 branch로 들어간다. 3가지 branch는 모두 linear layer로 이루어져있고 각 head를 통해 multiple view를 학습가능하게 한다. 모든 head에서 동시에 query와 key의 dot product를 진행하고 softmax 함수를 지나면서 attention matrix 를 생성한다. 다음으로 와 value의 linear layer와의 dot product를 통해 weigted sum output인 을 생성하고 concat한 다음 linear layer를 하나더 지나면서 MHA 최종 output 를 생성한다.
3.2 Separable self-attention
구조는 기존 MHA와 비슷하다. Input 가 input(), key(), value() 3개의 branch로 나누어진다. Input branch는 linear layer를 통해서 안에 d-dimension을 가지는 token을 projection한다. 특이한 점은 이 linear layer는 inner product(내적)을 통해서 latent vector 과 의 거리, '유사도'를 구하게 되고 k-dimension을 가지게 된다. 다음 softmax함수를 통해 context score를 계산한다.
기존 Transformer는 각 token이 모든 k개의 token과의 context score를 계산하지만 본 논문에서 제시한 방법은 latent token 이랑만 context score를 구한다.
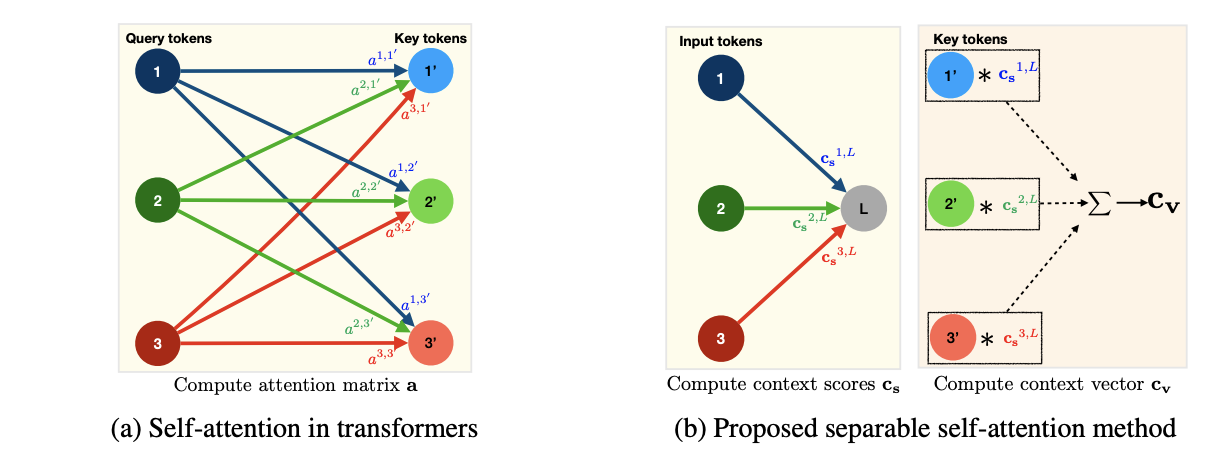
결과적으로 계산 비용은 에서 로 줄어들게 된다.
이렇게 구한 context score 와 branch에 있는 linear layer를 통해 input 를 d-dimension으로 projection하여 를 가중합을 통해 를 생성한다.
는 안에 있는 모든 token의 contextual information을 encode하고 있다. 다음으로 branch 의 가중치 를 통해 d-dimension으로 projection하고 ReLU 함수를 통해 를 생성한다.
다음으로 는 broadcasted element-wise multiplication operation를 통해서 로 전파된다. 의 dimension은 로 차원이 와 다르기 때문에 broadcasting element-wise multiplication operation을 통해 계산된다.
- broadcasting element-wise multiplication operation
그리고 다른 가중치 를 가진 linear layer를 통해 최종 output인 가 생성된다.
다음으로는 Separable self-attention을 forwarding 함수로 정리한것이다.

먼저 size가 [Batch, Input Channel, numbers of pixels, numbers of patches]인 input x를 projection한다. self.qkv_proj는 다음과 같다.

1x1 Convolution layer(= linear layer)를 통해 1 + (2 embed_dim)으로 projection하고 torch.split을 통해 나누어준다. (1 = query, (2 embed_dim) = key, value)
numbers of patches에 대해서 softmax를 취해주고 dropout을 진행한다.
특이했던 점은 가중합을 곱하고 torch.sum을 통해 나타낸것이였다. 먼저 key와 context_scores를 곱하면 shape가 [B, d, P, N]가 되고 이후 torch.sum을 통해 N축에 대해서 합을 진행한다.
이후 ReLU를 통과한 value와 expand_as를 통해 broadcast를 통해서 연산을 진행하고 마지막 linear layer를 통과해서 최종 output을 산출한다.
또한 본 논문에서는 skip-connection과 fusion block을 사용하지 않았을 때 성능이 조금이나마 상승했다. 또한 모델의 width을 multiplier 로 조정했다. 이는 MobileNet에서 사용된 방법으로 input channel과 output channel에 상수 를 곱해서 channel을 감소시키는 역할을 한다.
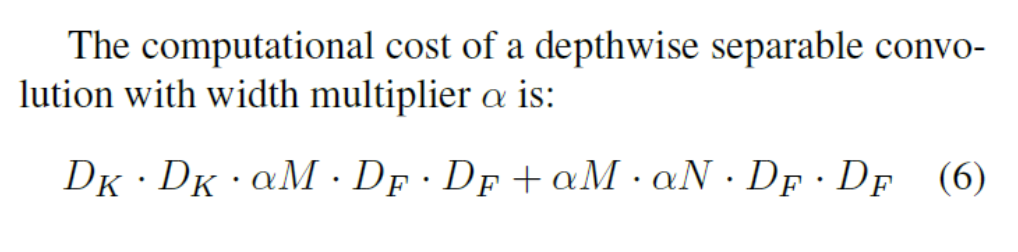
: kernel size(filter size)
: input channel
: input
: output channel(filter 개수)
위의 식은 Depthwise separable convolution 연산을 나타낸 식이다. 첫 번째 항은 depthwise convolution의 연산식이고 두 번째 항은 pointwise convolution의 연산식이다. 상수 는 input channel과 output channel에 곱해지면서 일종에 scaling을 해주는 역할을 한다.
기존 연산량과 만큼 차이가 난다.
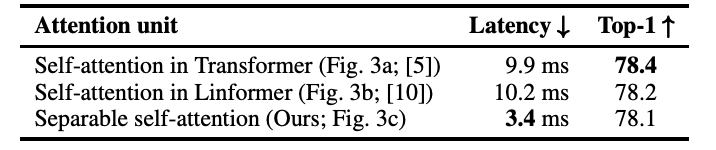
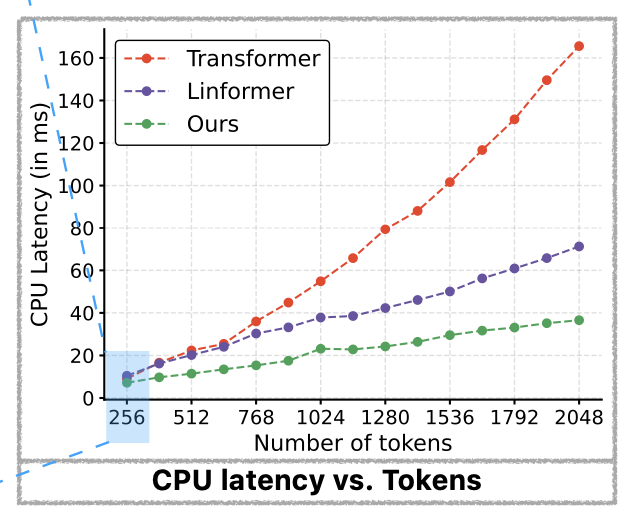
기존 존재하는 Transformer의 다른 attention 기법과의 latency와 성능을 비교하면 아래 표와 같다. 아래 표의 latency는 edge device인 iphone12로 계산되었다.