본 논문은 2019년에 ACL에서 발표된 논문으로 기존 transformer가 고정된 길이의 sequence를 받아서 생기는 한계점을 잘 보완했다고 생각한다.
1. Introduction
기존 transformer는 RNN의 long-term dependecy를 극복한 모델로 현재 여러 language model에서 활용되고 있다. 그리고 transformer는 input sequence를 고정된 길이로 나눠서 regressive하게 학습되었다. 따라서 고정된 길이를 벗어난, 다른 segment의 sequence들은 dependency를 학습하기 어렵다는 한계점이 발생했다. Segment-token들로는 그저 순서적인 정보밖에 반영하지 못하기 때문에 "context fragmentation" 문제가 발생했다.
이러한 문제점을 보완하기 위해 저자들은 두가지 mechanism을 제시했다.
-
Segment-Level Recurrence with State Reuse
-
Relative Positional Encodings
2. Model
Vanilla Transformer는 corpus 가 input으로 들어왔을 때, 현재 시점의 logit을 계산하여 token을 auto-regressive하게 예측하는 language modeling이다.
2.1 Vanilla Transformer
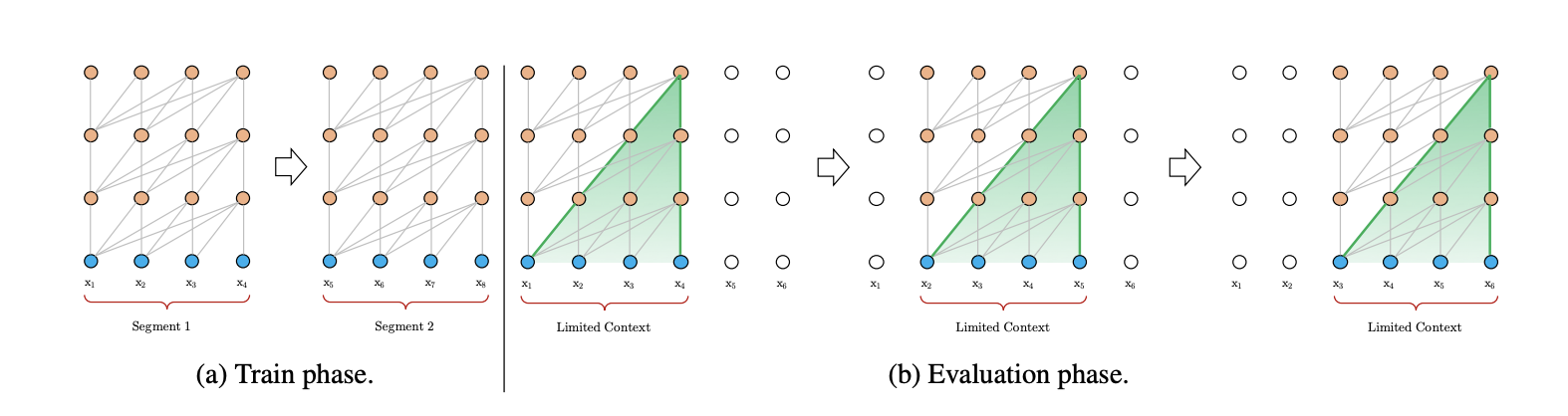
기존 Transformer로 fixed length를 벗어난, 긴 length의 text를 input으로 넣기에는 메모리적으로 한계가 있다. 따라서 왼쪽 train phase처럼 input sequence를 여러 segments로 나눠서 진행되고 evaluation phase에서는 시점 t를 1씩 증가시키면서 진행된다. 그러나 각 segment들이 독립적으로 modeling되기 때문에 서로간의 dependency를 학습하기 어려우며 RNN의 고질적인 문제였던 long-term dependency가 여전히 남아있는 모습이다.
본 논문에서는 다음과 같은 한계점을 극복하기 위해 Transformer-XL을 고안했으며 이를 코드와 함께 확인했다.
3. Transformer-XL
3.1 Dataset

위의 코드는 전체 sequence를 총 20개의 segment로 분할하는 dataset코드이다. 특이점은 get_fixlen_iter함수인데, 이는 start부터 bptt만큼 건너뒤며 iteration을 도는것을 확인할 수 있다. 그리고 iter함수를 통해 segment단위로 model에 input으로 들어가는것을 확인할 수 있다.
3.2 Adaptive Embedding

공식 github에서 adaptive embedding을 거치는데 이는 Adaptive Input Representations for Neural Language Modeling (ICLR 2019)이라는 논문에서 발표된것으로 간단하게 설명하면 빈도수가 높은 단어에 더 많은 capacity를 부여하고 낮은 단어의 capacity를 줄이는 방법으로 overfitting을 완화하는 방법이다.
위에 코드에서 먼저 cutoffs로 vocab을 나눠서 빈도수가 높은 cluster와 낮은 cluster로 나누어준다. 다음 빈도수가 높은 cluster에 대해서는 기존 dimension인 d_emb차원으로 projection하고 빈도수가 낮은 cluster에 대해서는 으로 dimension을 낮춘다음 (scaling) d-dimension으로 다시 projection하여 parameter를 줄이는 방법을 통해 capacity를 줄이는 방법이다. 그리고 output layer에서 class기반 계층 softmax에서 영감을 받은 adaptive softmax를 사용했다.
3.3 Segment-Level Recurrence with State Reuse
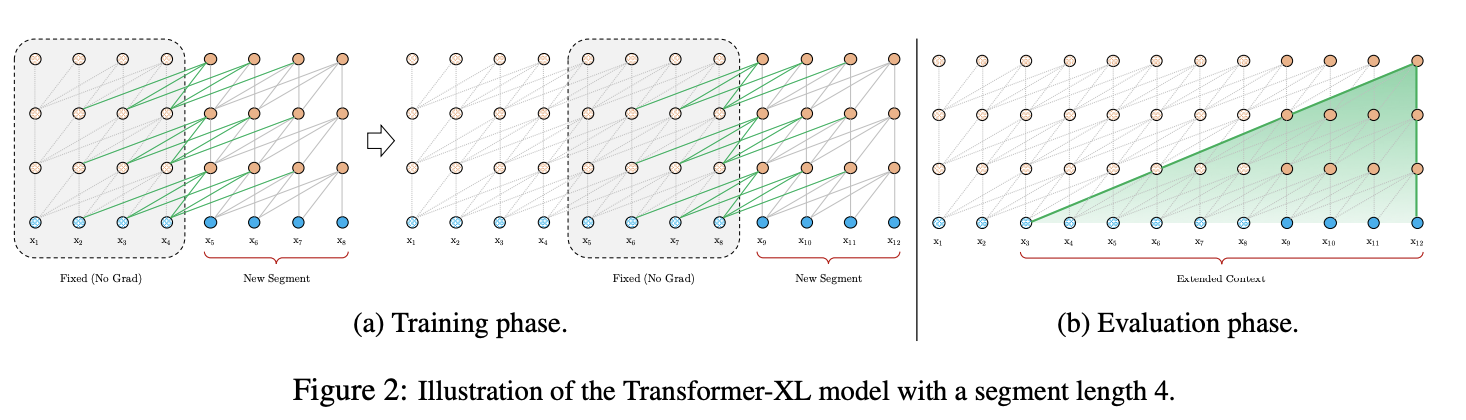
Transformer-XL은 기존 RNN에서 활용되는 방법인, recurrence mechanism을 transformer에 도입하는 것이다. 각 segments에 대해 독립적으로 학습하는것이 아니라 연속적으로 학습하는것으로 이해하면 된다. 즉, 이전 segments의 모든 hidden state를 활용하여 현재 segment에 대한 hidden state를 구하는것이다. 이때 왼쪽 (a)처럼 Fixed와 New Segment를 같이 학습하지만 gradient가 흐르지 않게 학습이 진행된다. 이를 수식으로 나타내면 아래와 같다.
이 수식에 대한 코드이다.

위 함수를 보면 max_len만큼 forwarding이 진행되고 torch.no_grad를 통해 update를 멈추고 memory로 append concat해주는것을 확인할 수 있다.
3.4 Relative Positional Encoding
이전 시점의 segment에 대한 정보를 다음 segment에 대해 전달하면서 context fragmentation을 어느정도 해결할 수 있지만, 생기는 문제점이 다른 segment의 token들이 동일한 positional encoding값을 가지게된다.
위의 수식에서 U가 positional encoding 값일 때, segment와 segment에 동일한 위치정보가 반영된다.
Transformer는 positional encoding을 통해 token들간에 연산이 이루어지는 attention module에서 token들간의 positional information을 줘야한다. 따라서 논문의 저자들은 각 token들의 절대적인 정보를 주지않고 상대적인 정보를 넘겨줘서 이러한 문제점을 해결했다.
먼저 기존 transformer의 i번째 query token과 j번째 key token사이의 attention을 계산하는 식은 아래와 같다.
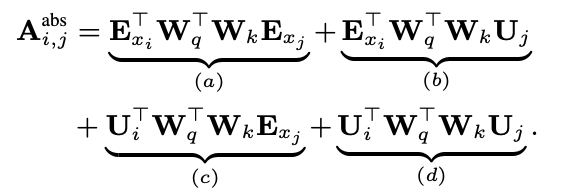
이 식을 보면 attention을 구하는 행렬식은 i,j번째 token의 word embedding과 hidden state가 있는 context-based, 와 순서 정보가 들어가있는 position based, 로 구성되어있다.
이 식에 relative positional encoding을 적용하면 아래와 같이 표현된다.
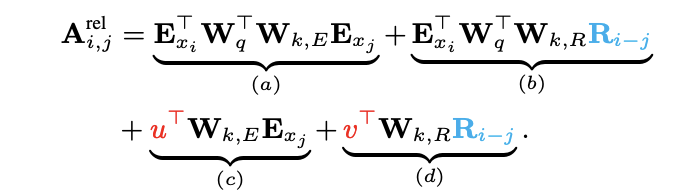
먼저 절대적인 위치를 나타냈던 를 상대적인 위치를 표현하는 로 변경했다. 이를 통해 j번째 key token이 i번째 query token으로부터 상대적인 위치를 반영할 수 있다. 그리고 기존 (c)와 (d)의 를 u와 v로 바꿨는데 이는 query vector는 모든 vector에 대해 동일한 값을 가져야하기 때문이다. 그리고 key에 대한 weight를 와 로 나누어 context based와 position based의 key vector를 만든다.
각 term들이 가지는 의미는 아래와 같다.
- (a) = contentbased addressing
- (b) = contentdependent positional bias
- (c) = governs a global content bias
- (d) = encodes a global positional bias
그리고 이 식을 ((a),(c)), ((b), (d))로 묶어서 최종 attention score를 계산한다.

torch.einsum은 모든 행렬 혹은 tensor 연산을 표기하는 방법이다. 그리고 rel_shift 함수로 행렬의 행과 열의 index를 0으로 padding하면서 상대적인 위치를 바꿔주는 역할을 한다. 이를 ((b), (d))에 적용하는 이유는 라는 위치 기반의 key vector를 통해 연산을 진행하기 때문이라고 생각한다. 즉, layer별로 주어딘 상대적인 위치 vector와 이에 대한 가중치 를 이용하여 상대적인 위치 정보가 포함된 attention score를 구한다.
그리고 이를 masked-softmax, layer normalization, positionwised-feed-forward를 거쳐 최종 output을 구하게된다.
Transformer-XL의 전체 수식을 나타내면 아래와 같다.

최종적인 output의 [1:]을 memory로 저장하여 다음 segment 연산에 사용되게 된다.

4. Experiments
본 논문의 저자들은 다양한 dataset을 통해 성능을 비교했다.
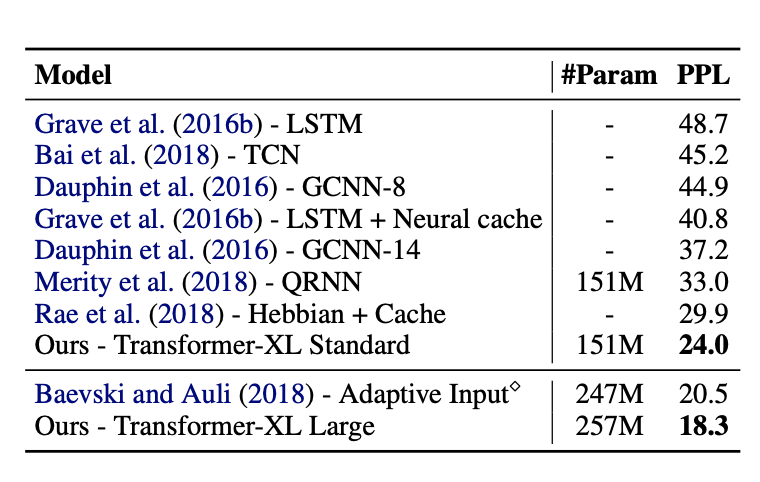
가장 큰 word단위의 benchmark dataset인 WikiText-103에서 SOTA를 달성했다. 이 dataset을 통해 model의 long-term dependency를 test할 수 있었고 ppl을 18.3을 달성했다.
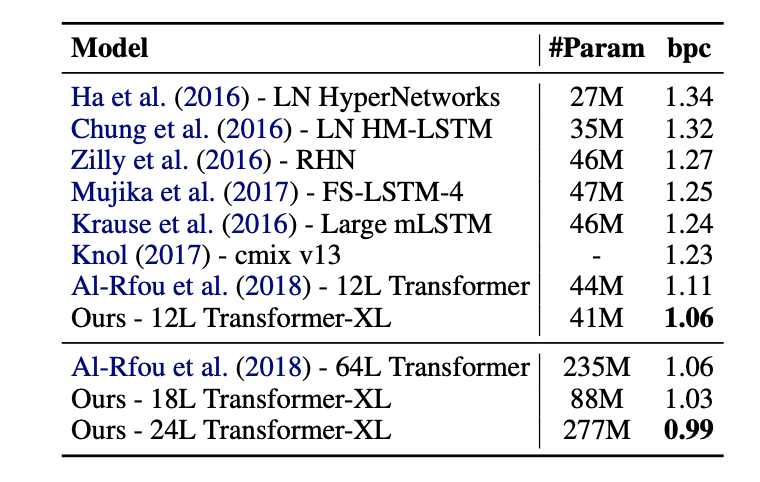
다음으로는 enwik8 benchmark dataset에서 SOTA를 달성한것을 확인할 수 있다.
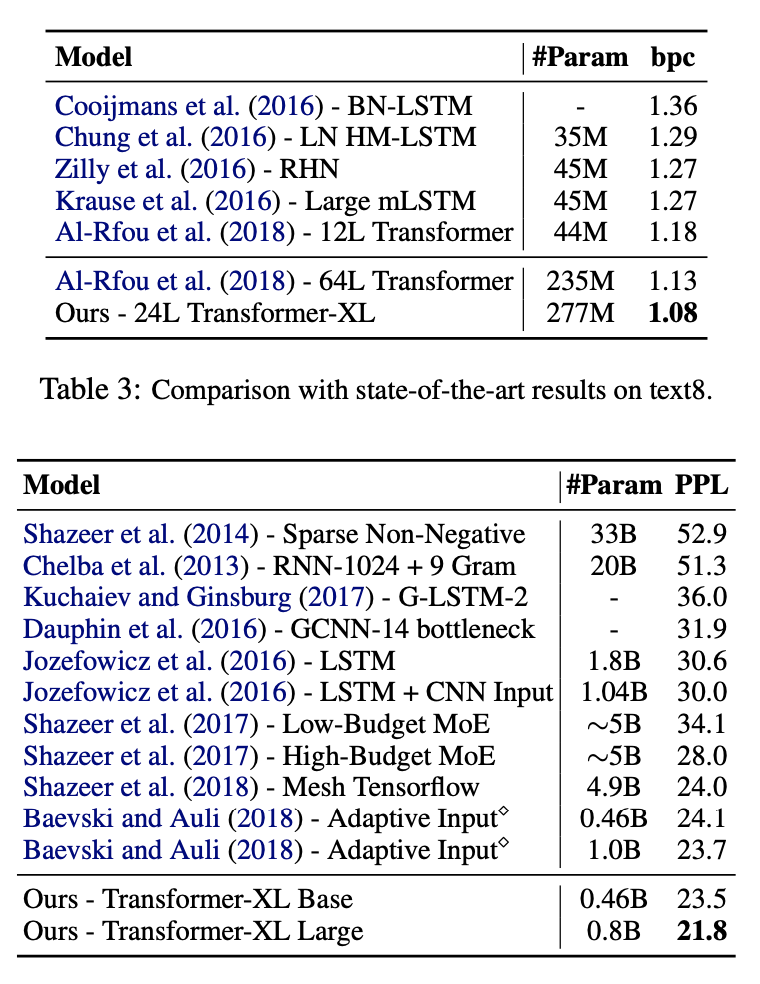
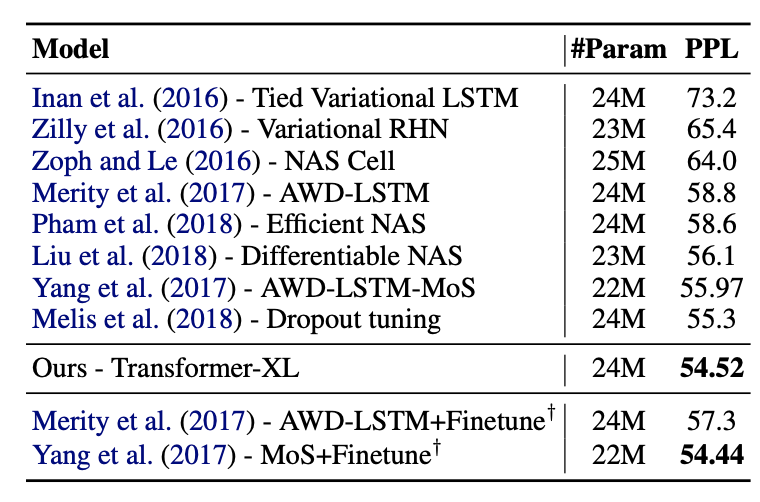
또한 text8, One Billion Word dataset, PennTreebank dataset에서 SOTA를 달성한것을 확인할 수 있고 One Billion Word는 보통 short-term dependency에 대한 테스트를 진행하는것으로 이에 대해서도 좋은 성능을 보여줬다.
4.1 Ablation Studies
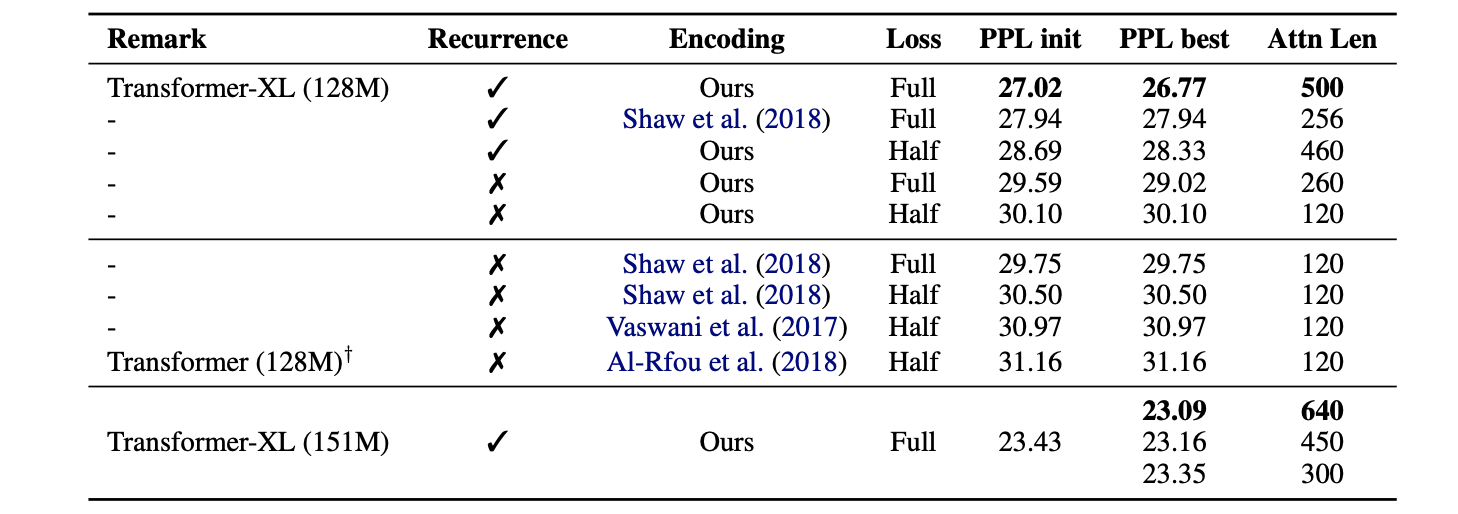
WikiText-103을 dataset을 여러 setting으로 나누어 성능을 비교했다.
먼저 Recurrence가 없는 방식은 기존 sliding window 방식을 이용했고 있는 방식으로는 attention length만큼의 recurrence한 연산을 진행했다. Encoding 또한 relative positional encoding과 기존 positional encoding방법을 나누어 진행했고 loss의 half은 마지막 절반의 위치에 있는 token부터 loss를 계산하는 방식과 full 모든 위치의 token으로 부터 loss를 계산하는 방식으로 나누어 진행했다.
먼저 relative positional encoding 방법이 더 좋은 성능을 보여줬고 recurrence를 사용한 방법과 attention length가 클수록 성능이 좋게 나타났다.
5. Appendix - Efficient Computation of the Attention with Relative Positional Embedding
Query와 key의 token(i,j)에 대해 를 기존의 방식으로 계산하려면 quadratic의 비용을 갖는다. 따라서 본 논문에서는 이러한 연산을 linear하게 효과적으로 계산하는 방법을 소개했다.
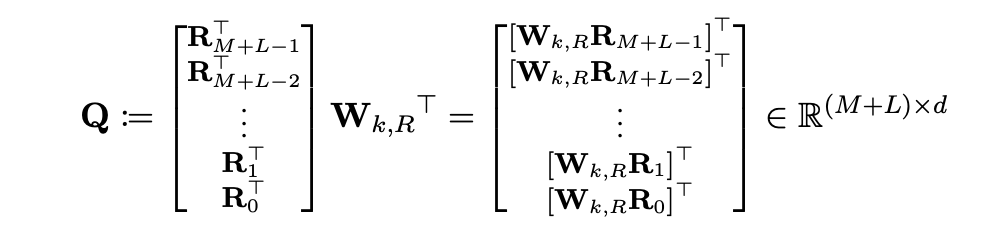
먼저 Q는 역순으로 정의되어 있다.

먼저 B라는 행렬의 첫번째 token은 memory, 즉 이전 segment의 첫 token으로 현재 segmenet의 첫 token과의 relative position vector는 이다. 이 행렬의 행은 query, 열은 key이다. Query는 segment L만큼의 길이를 갖게 되고 key는 M+L만큼의 길이를 갖게된다.
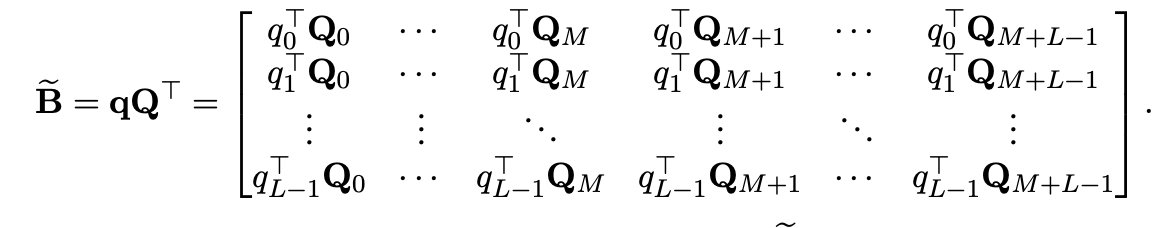
첫번째 Q vector와 query vector를 곱하고 left-shift를 통해 위와같은 행렬을 만들고 (b) term을 계산할 수 있다.
