CycleGAN 논문을 읽기전 알아야하는 배경지식이 있다.
GAN (Generative Adversarial Network)
먼저 GAN은 generator(생성자)와 discriminator(판별자), 두 가지 network로 구성되어 있다. G는 D를 속일 수 있는 data를 생성하게 되고 D는 data가 진짜인지(실제 input) 가짜인지(G가 생성한 data) 구별하는 역할을 한다. D는 일종의 분류 model이라고 볼 수 있고, G는 다양한 data가 구상하는 분포를 학습하면서 새로운 data를 생성한다.
GAN의 목적함수는 min, max objective function으로 구성되어 있다. 기본적으로 V의 함수는 D가 max 되게 학습되고 그리고 최소한의 값을 갖도록 G를 업데이트되는 방식으로 진행됩니다. 먼저 왼쪽항에서 는 실제 data의 distribution이고 실제 x를 sampling해서 이를 D에 넣고 이에 log를 씌운값이 커지는 방향으로 D를 업데이트 한다. D에서 1이라는 값을 내보낼 수 있도록 진짜 data는 진짜라고 판별할 수 있도록 D를 학습한다. 반면에 가짜 이미지가 들어오는 경우 음수를 취해서 결과적으로 G가 생성한 이미지는 가짜라고 구별하게 D를 학습한다. 다음 G는 이러한 V값을 최소가 되어야하기 때문에 왼쪽항에는 G가 들어있지 않고 오른쪽 항에 G가 생성한 data D가 진짜라고 판별할 수 있도록 학습된다.
결과적으로 G가 생성한 이미지는 실제 data의 distribution과 거의 유사해진다.
cGAN
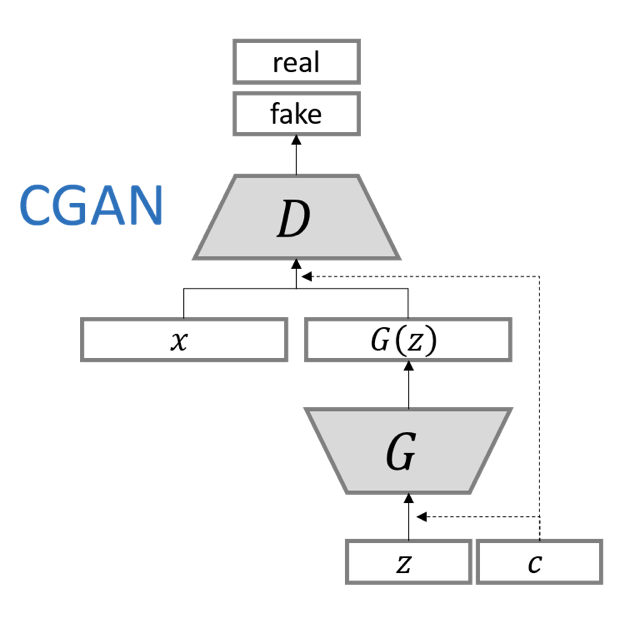
다음은 data의 mode를 제어할 수 있도록 condition 정보를 함께 입력하는 GAN입니다. 기존 GAN은 noise vector를 통하여 ouput을 생성했는데 이는 사람이 통제할 수 없었다. 여기서 noise vector는 latent vector라고도 불리는데, 이는 부분 정보(랜덤값)를 받아 up-sampling하여 data를 생성한다.
G와 D에 추가 정보, condition 가 붙으면 조건부 생성 모델을 만들 수 있다. 를 input값으로 함께 넣어 수행할 수 있는데 input noise z와 y가 합쳐진 형태로 들어가게 된다.
기존 입력을 줄 때, 조건부 y를 함께주는 식으로 정리할 수 있다. 예를 들어, mnist data에서 0부터 9까지 숫자 이미지를 만들 때, 어떤 숫자를 만들어야할지 함께 정보를 주는것이라고 보면 된다.
Pix2Pix
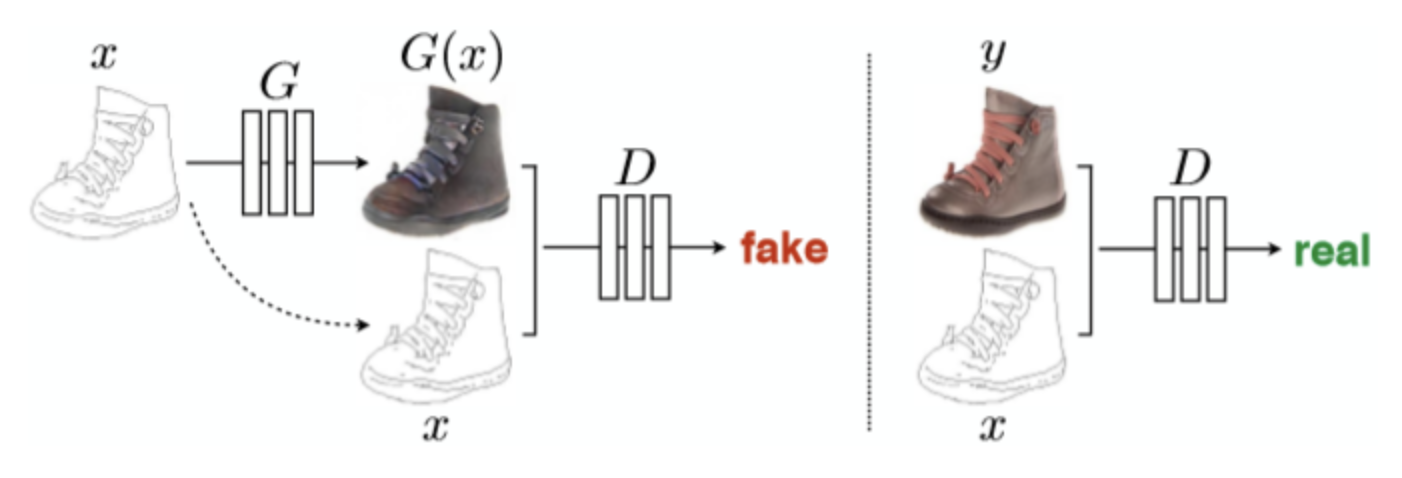
오늘 소개할 논문 cycleGAN은 Pix2Pix를 개선한 model이라고 볼 수 있다. 이는 GAN을 활용한 초창기 image-to-image translation model이다. Pix2Pix는 위의 예시에서 설명한 class를 조건으로 받는것이 아닌 image를 조건으로 받는 일종의 conditional GAN이다.
이전까지 GAN의 noise vector는 randomness를 가지고 있었는데 pix2pix에서는 이에 확률성을 유지하는 방법을 도입했다.(dropout을 통하여)
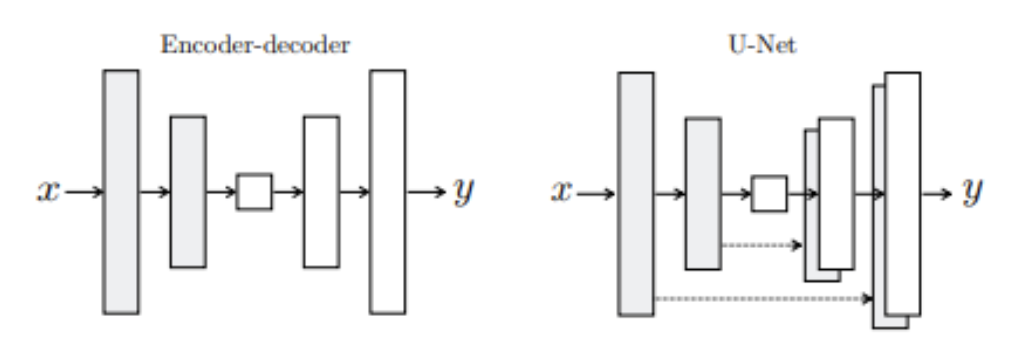
Pix2pix의 generator는 U-net의 구조를 가지고 있으며, encoder-decoder 구조에 skip-connection을 추가한 형태이다. (bottle-neck문제 해결)
Pix2pix의 discriminator의 기본 구조는 Patch-GAN이다. 이미지를 NxN 크기의 patch로 나누고 각 patch에 대하여 참/거짓을 판별한 뒤 분류하는 model이다. 지역적인 특징을 잘반영하는 model이다.
0.Abstract
Image-to-image translation은 보통 input image와 output image의 pair를 align된 training set을 이용하여 학습한다. 그러나 많은 task에서 paired training data는 사용하기 쉽지않다. Cycle-GAN은 이런 pair image를 사용하지 않고 X-domain dataset과 Y-domain dataset만을 이용하여 두 domain간의 image를 변환하는 법을 학습한다. 기존의 GAN은 adversarial loss를 사용하여 generator(X)로부터의 data의 distribution과 Y의 data의 distribution을 discriminator가 구분하지 못하도록 학습한다. 이러한 X를 Y와 mapping하는, 즉 X -> Y를 학습하는 것뿐만 아니라, 역방향 mapping을 함께 진행했다. 그리고 cycle consistency loss를 도입하여 유사해지도록 강제했다. 이로인해 pair data가 없이 여러 translation task가 가능했다.

1. Introduction
본 논문에서는 pair의 data없이 기존 data의 특징을 파악한 후에 data에 어떻게 특징을 적용하여 translation할지 제시했다. 기존 domain들의 data들에는 근본적인 관계가 있다고 가정했다. 과 를 구분할 수 있게 adversially 학습된 model을 통해 실제 이미지 와 구별하기 힘든 genenrator의 sampling된 output , 을 산출하는 을 목표로 학습한다.
그러나 이러한 방식의 translation은 input domain X와 domain y가 의미있는 방식으로 mapping되는 것을 보장하지 않고 종종 collapse되는 현상이 일어난다. 이러한 collapse은 input domain X가 모두 같은 domain Y로 mapping되는 현상이다.
이러한 문제를 해결하기 위해 본 논문에서는 translation이 cycle consistent이 있어야한다고 주장한다. 여기서 cycle consistent는 예를 들어, 영어 corpus를 불어 corpus로 번역할 때, 불어 corpus를 다시 영어로 corpus로 번역할 수 있는 것을 의미한다. 이러한 역방향 mapping을 반영하기 위해 cycle consistency loss와 adversarial loss를 목적함수로 G와 F를 동시에 학습한다.(여기서 F는 되돌리는 함수, 역방향을 의미)
예를 들어, 여름 domain의 input image 를 겨울 domain의 output image 로 translation을 학습하고 다시 역방향으로 를 여름 이미지 가 되도록 학습한다.
2. Related Work
- GAN과 image-to-image translation에 대한 기본적인 설명.
- 기존 방법들처럼 task에 specific하지 않음.
즉 general한 solution.
3. Formulation
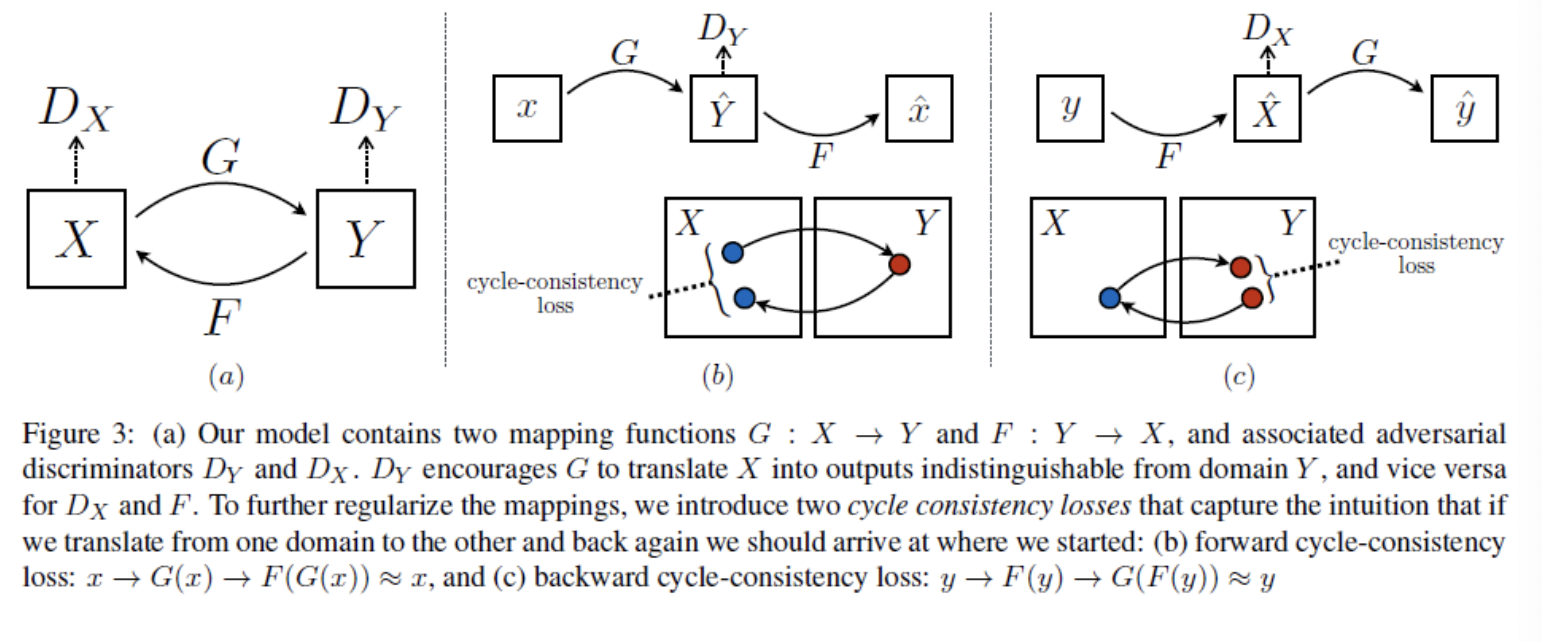
본 논문의 목표는 domain X와 domain Y를 mapping하는 함수를 학습하는 것이다. 그림과 같이 cycleGAN은 두가지의 방법으로 generator를 학습한다.
Generator 로 mapping
Generator 로 mapping
기존 X를 Y로 mapping해주는 generator와 Y를 X로, 역방향으로 mapping하는 함수가 존재.
그리고 domain X에서 domain Y의 data로 생성해주는 generator와 data를 구별해주는 discriminator가 존재한다.
Discriminator : 실제 domain Y의 data y와 가 생성한 을 구분
Discriminator : 실제 domain X의 data x와 가 생성한 을 구분
3.1 Adversarial Loss
먼저 함수 와 에 대해서 다음과 같이 학습을 진행한다.
이는 기존 GAN의 adversarial loss함수와 동일하다. G는 위의 loss함수를 최소화시키고 반대로 D는 위의 함수를 최대화하는 방향으로 학습된다. 이는 에 대해서도 동일하게 적용된다. 로 나타낼 수 있다.
3.2 Cycle Consistency Loss
기존 adversarial 학습은 target domin인 Y와 X를 각각 동일한 분포로 각각 mapping하게 학습한다. 그러나 이럴 경우 앞서 설명한것처럼 mode collapse이 발생할 수 있다. Adversarial loss로는 하나의 개별 input x가 원하는 ouput y에 mapping한다는 보장이 없다. 그렇기 때문에 본 논문의 저자는 cycle consistency loss를 추가하여 이를 보완했다.
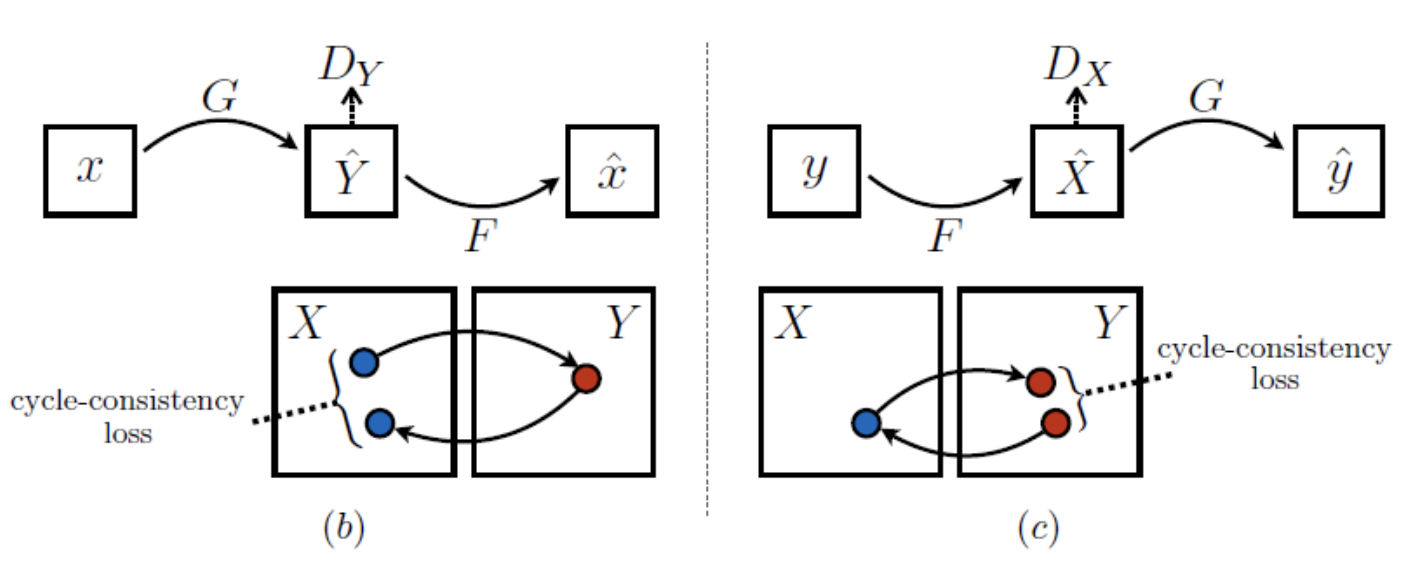
Cycle consistency loss는 각각 생성한 data 를 다시 원본의 data 로 복구할 때, 두개의 거리를 구하는것으로 계산한다. (b)를 보면 인것을 확인할 수 있다. 이것은 정방향으로 진행되는 forward cycle consistency로 확인할 수 있으며, (c)는 backward cycle consistency로 확인할 수 있다.

위 그림을 통해 재건된 image F(G(x))가 input image 와 유사한것을 확인할 수 있다.
3.3 Full Objective
CycleGAN의 최종 목적함수는 다음과 같다.
위의 식을 아래와 같이 4개의 network에 대해서 optimize한다.
CycleGAN은 얼핏보면 autoencoder와 비슷하게 보일 수 있다. 그러나 autoencoder는 translation의 데이터를 다른 domain으로 나타내는 intermediate representation을 통해 스스로 mapping한다.
4. Implementation
CycleGAN의 generator는 아래와 같은 구조를 가지고 있다.
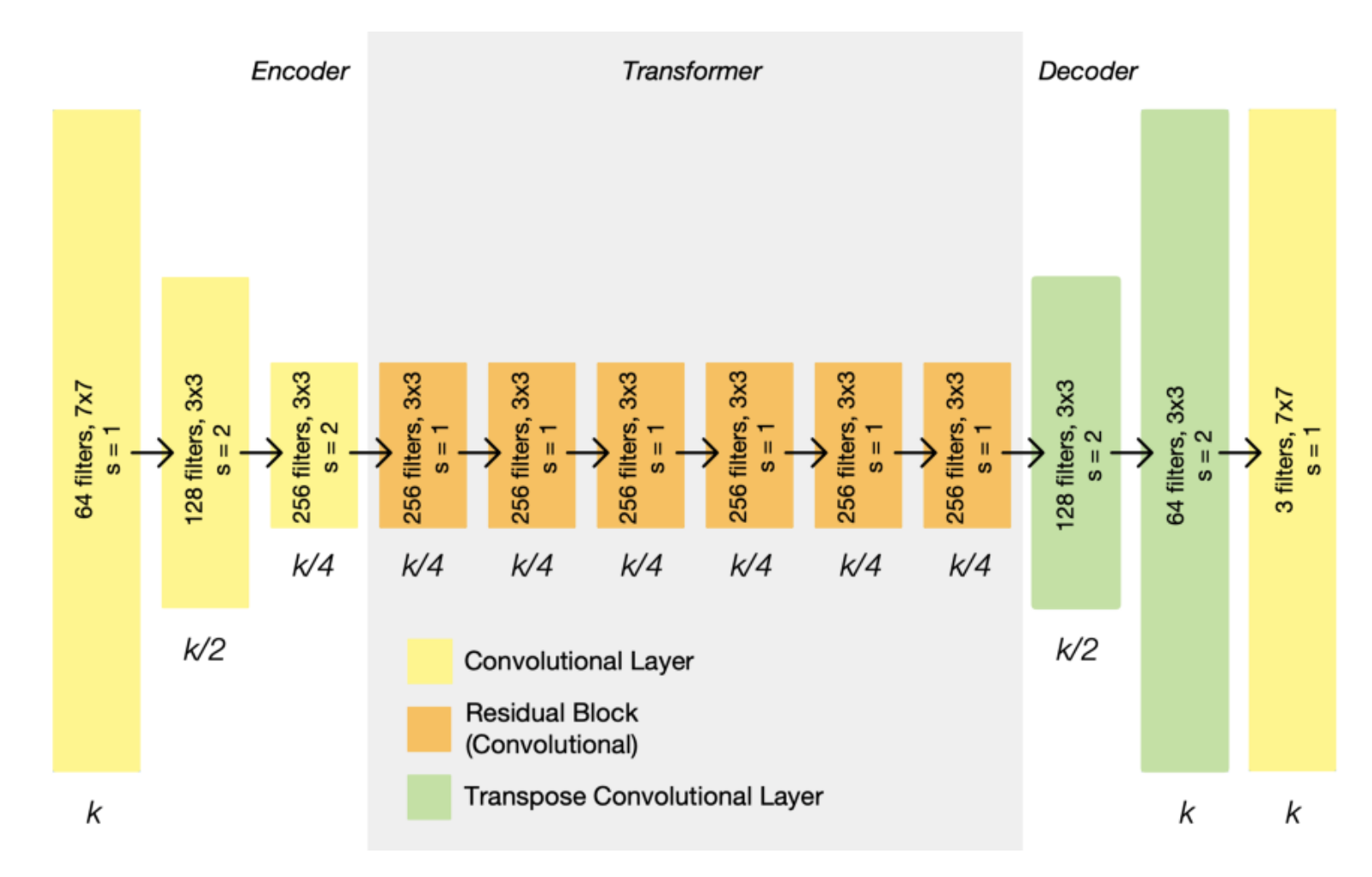
먼저 encoder, transformer, decoder 총 3개의 section이 존재한다. Input image는 channel의 개수는 증가하면서 representation의 size는 줄이면서 encoder로 들어간다. Encoder는 총 3개의 CNN으로 이루어져있다. 그리고 transformer는 6개의 residual block으로 이루어져있다. 그리고 decoder로 들어가면서 다시 확장되고 이는 두개의 transpose CNN으로 이루어져있고 output layer를 통해 산출된다.
그리고 cycleGAN의 discriminator는 다음과 같이 PatchGANs로 구성되어 있다. PatchGANs란 특정 크기의 patch 단위로 가짜와 진짜를 구별하고 그 결과에 평균을 취하는 방식으로 진행된다. PatchGAN을 통해 전체 이미지가 아닌, 작은 patch에 대하여 sliding 방식으로 연산을 수행하기 때문에 parameter의 수가 현저히 적다. 본 논문에서는 70x70 size의 pixel를 사용했다.
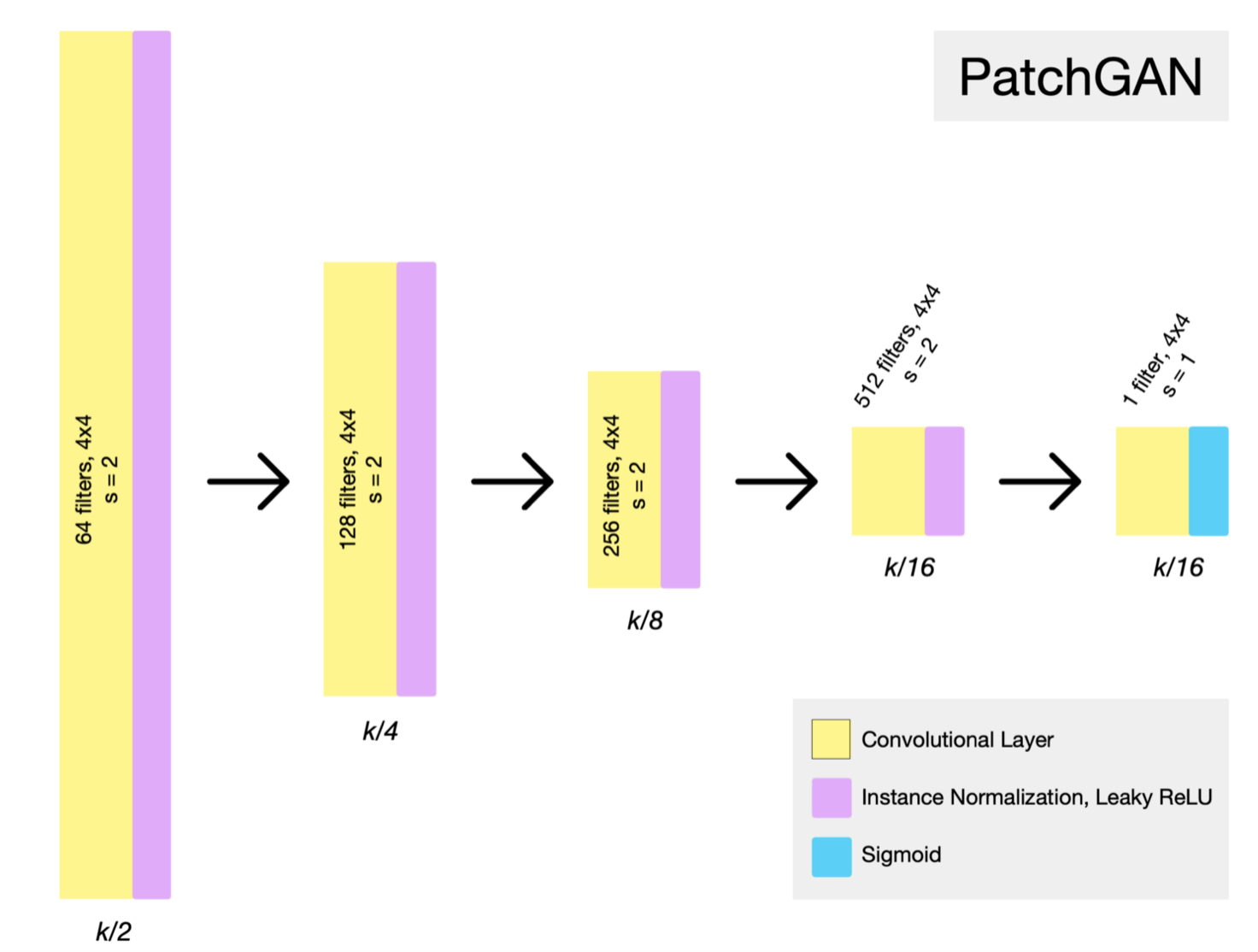
PatchGAN의 특징으로는 기존 GAN은 G가 생성한 데이터(이미지) 전부를 보고 Real/Fake 여부를 판단하기 때문에 discriminator를 속이기 위해 데이터의 특징을 과장하려는 경향을 보인다. 즉, 데이터 퀄리티 여부와는 상관없이 D를 속이려는 방향으로만 학습하게 되고 일종의 blur가 데이터가 끼어 나타나게 된다. PatchGAN은 patch 범위보다 멀리 있는 픽셀은 모두 independent하다고 가정하고 이미지를 하나의 MRF(Markov Random Field)라고 간주한다. 마르코프 연쇄 속성에 의해 근처 주변의 픽셀만을 고려하고 나머지는 고려하지 않게 되는, 지역적으로 학습이 진행된다.
본 논문에서는 학습과정을 안정화시키기 위해 두가지 방법을 적용했다.
-
의 negative log likelihood 함수를 least-squares loss로 대체했다. 이를 통해 안정화가 가능했다고 한다.
-
Reduce model's oscillation : discriminator가 수렴하지않고 진동하는것을 안정화시키기 위해 최신의 generator가 생성한 하나의 이미지를 사용하는것이 아니라 지금까지 이미지를 정부 사용했다. (50개)
5. Result
모델의 성능 평가를 위하여 본 논문에서는 3가지의 지표를 사용했습니다.
- 정성평가
- FCN score
- per-pixel accuracy