0. Abstract
본 논문에서는 SimCSE를 통하여 sentence embedding의 SOTA를 달성했다고 한다. 먼저 논문에서 input sentence를 취해 dropout을 noise로 사용하여 contrastive objective를 통해 스스로를 예측하는 unsupervised-approach를 설명한다. 이러한 방법은 기존 supervised-learning과 비슷한 성능을 보여준다. 논문에서는 dropout을 통해 data augmentation을 최소한으로 진행하고 제거했을 때 representation이 붕괴되는것을 확인할 수 있다. 다음, 논문에서는 supervised approach를 제안했는데, NLI dataset에서 entailment가 positive로 contradiction이 negative로 주석이 달린 pair를 사용해서 contrastive learning framework로 통합하는 방법을 제안했다. 논문에서는 SimCSE를 사용해서 STS task를 평가하였고 BERT-base를 사용했을 때 unsupervised-model은 76.3% 달성했고 supervised-model은 81.6%을 달성했다. 또한 논문에서는 contrastive learning objective을 통해 pre-trained embedding의 anisotropic space를 균일하게 정규화하고 supervised signal을 사용하면 positive pair를 더 align한다고 말했다.
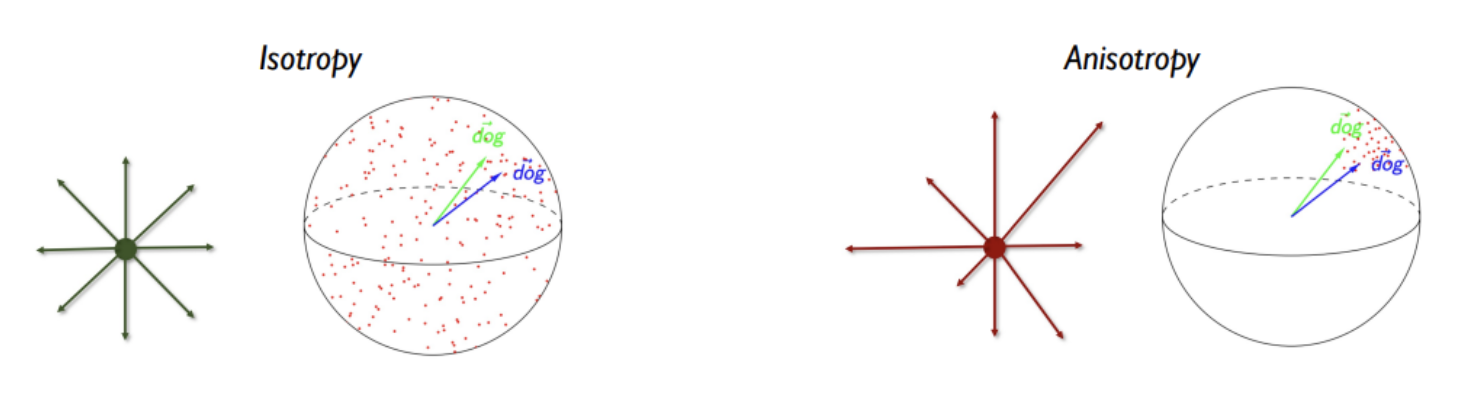
Embedding의 anisotropic space란 vector가 space에서 일정한 방향으로만 뻗어 있어 단어의 의미와 유사도와 관계없이 가깝게 분포하게 되는것을 의미한다. (물론 항상 나쁜것만은 아니다.)
1.Introduction
NLP분야에서는 좀 더 범용적인 sentence embedding을 학습하는것이 연구되어 왔다. Constrative objective가 BERT 혹은 RoBERTa와 같은 pre-trained model에 사용했을 때 매우 효과적이고 SOTA를 달성했다. SimCSE를 통해 label의 유무와 상관없이 sentence embedding을 만들 수 있다.
Unsupervised SimCSE는 dropout을 noise로 사용하여 sentence를 예측하는 방식이다. Pre-trained encoder에 같은 문장을 두번 통과시키고 : 두 문장의 standard dropout 두번 적용하여 두개의 다른 embedding을 positive pairs로 얻을 수 있다. 간단한 방법으로 보일 수 있지만, 이러한 방법은 next sentence predict의 objective와 단어를 삭제하거나 대체하는 discrete data augmentation의 성능을 뛰어넘었고, 이전 supervised method와 일치한다. 그리고 실험을 통하여 dropout은 최소한의 data augmentation의 역할을 수행할 수 있고 이것을 삭제했을 시 representation이 붕괴되는것을 알 수 있었다.
우리의 supervised SimCSE는 NLI dataset을 통해 sentence embedding을 학습하고 contrastive learning에서 주석이 달린 sentence pair를 통합했다. Entailment, neutral, contradiction 3가지의 분류 task를 수행하는것이 아닌 entailment pair를 positive한 data로 사용될 수 있다는 점이 이전 연구와는 다르다. 또한 논문에서는 contradiction의 pair를 아주 강한 부정으로 더 좋은 효과를 가졌다고 한다. 다른 labeled sentence-pair dataset과 비교했을 때, NLI dataset이 sentence-embedding을 학습하는데 더 효과적이라고 한다.
논문에서는 Wang and Isola의 tool을 사용했고, 이는 embedding의 질을 측정하기 위해 전체 representation의 space의 uniformity와 의미적으로 연관된 positive-pairs의 alignment를 가져왔다. 또한 경험적인 측면에서, unsupervised-learning의 SimCSE가 sentence embedding의 uniformity를 향상시키면서 dropout의 noise를 통해 aligment가 점점 사라지는것을 막아서 representation의 더 좋은 표현력을 가지는것을 확인했다. 결과적으로 NLI dataset을 학습하면서 positive pairs 사이의 alignment를 향상시킬 수 있고, 더 좋은 sentence embedding을 만들 수 있는것을 알 수 있다. 또한 pre-trained word embedding이 representation의 space에서 anisotropy 상태로 존재하는 vector들을 좀 더 istropy(representation space에서 유사한 단어는 가깝게, 서로 뜻이 많이 다른 word는 멀게)하게 하고, contrastive learning objective을 통해 sentence embedding의 고유 값 분포도를 flatten하게 만들었다.
- 고유 값의 분포를 flatten하게 만들었다는 것은 결국 방향이 일정한 vector의 분포도가 flatten하지 않고 울퉁불퉁하면 결국 uniformity하지 않고 이리저리 방향이 튀는것으로 이해했고 이 분포도를 flatten하게하여 uniformity를 형성했다,라고 이해했다.
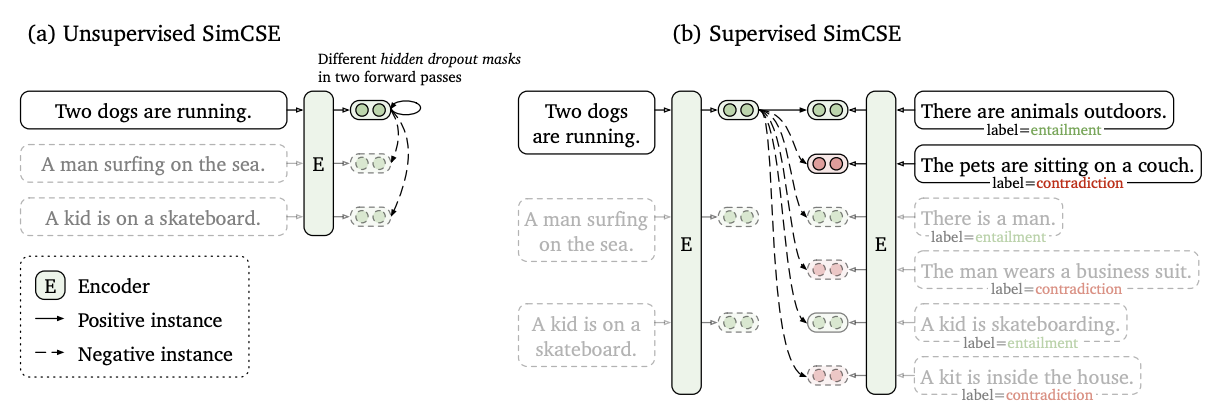
먼저 contrastive learning의 가장 중요한 point는 positive pair의 sentence를 찾는것이다. SimCSE는 unsupervised learning과 supervised로 나눠질 수 있다.
Unsupervised Learning
먼저 unsupervised learning에서는 동일한 문장을 positive pair로 활용한다. 동일한 sentence를 encoder의 input으로 넣어주고 output은 hidden representatoin이 된다. 동일한 문장을 두번 넣어주지만 dropout을 다르게 적용하여 똑같은 output이 생성되지 않고 data augmentation의 효과도 볼 수 있다. 같은 두개의 문장의 다른 hidden representation 두개가 하나의 positive pair를 이룬다.
Supervised Learning
다음 supervised learning에서는 unsupervised learning과 달리 다른 문장의 pair를 positive pair로 활용한다. 이를 위해서 NLI dataset을 활용했는데, entailment라는 annotation label을 positive pair로 contradiction이라는 annotation label을 hard negative pair로 활용했다. 매칭되는 문장들이 entailment인지 contradiction인지를 통해 positive, neagtive pair를 이룬다.
2. Background : Contrastive Learning
Contrastive learning은 sentence embedding에서 같은 의미의 문장은 가깝게, 다른 의미의 문장은 최대한 멀게 효과적으로 representation을 학습하는 것을 objective로 한다. 이라는 pair가 존재한다고 하자, 이때 와 는 의미가 관련된 data이다. Objective function은 다음과 같다.
먼저 분자는 해당 sentence pair가 얼마나 유사한지 계산하기 위해 similarity function을 활용하고 있다. 분모는 나머지 sentence의 similarity를 계산하고 있다. 본 논문에서는 분자의 positive pair의 similarity를 계산하고 분모에서는 negative pair의 similarity를 계산하여 similarity를 학습하는 loss를 구성했다고 한다.
(여기서 similarity function은 cosine 유사도를 의미.)
본 논문에서 BERT와 RoBERTa와 같은 pre-trained language model을 통해 input sentence을 encoding하고 contrastive learning objective을 통해 parameter를 fine-tuning한다.
2.1 Positive instance.
Constrastive learning의 하나의 결정적인 문제는 어떻게 pair를 구성하느냐 이다. Vision 분야에서는, 와 을 cropping, flipping, distortion and rotation 중 2개를 가하는것이다. NLP 분야에서는 단어를 삭제하거나, 재정렬하거나 대체하는 방식을 사용했다. 그러나 NLP에서 data augmentation은 언어가 이산적인 고유의 특성을 갖고있어 쉽지않다.
2.2 Alignment and uniformity
Wang and Isola에서 contrastive learning과 관련한 2가지 핵심 key properties를 구별했고 - alignment and uniformity- representation의 질을 평가하는 방법으로 제안했다. Positive pairs의 representations의 분포를 고려하면, alignment는 두개의 문장 사이의 embedding 거리(기댓값)를 계산할 수 있다.
그리고 uniformity는 embedding이 얼마나 일정하게 분포하고 있는지를 의미한다.
는 data의 분포도를 의미한다. 이러한 두개의 metrics는 contrastive learning과 잘 align되어있다. Positive instance끼리는 가깝게 위치해야하고 random instances의 embeddings는 hypersphere에 골고루 흩어져있어야 하는데 이를 istropy하다고 한다. Embedding space가 hypersphere에서 고르게 분포해야 단어의 의미가 보다 더 명확하게 구분될 수 있다.
3. Unsupervised SimCSE
SimCSE의 unsupervised learning은 정말 간단하다 : 먼저 sentence의 집합인 에서 positive pair인 를 이용한다. 똑같문장을 각각 독립적인 sampling된 dropout mask를 적용하여 positive pair를 얻는다. Transformer의 training에서 fc-layer에 dropout mask가 존재하고 attention probabilities에도 존재한다. 그리고 encoder의 output인 hidden vector 로 정의한다(z는 dropout을 위한 random mask). Encoder에 똑같은 문장을 두번 넣고 각각 다른 dropout 비율을 적용하여 두개의 embedding을 얻는다. SimCSE의 training objective는 다음과 같다.
N개의 문장의 mini-batch에 대한 loss이다. 는 transformer에 존재하는 standard dropout mask이고 추가적인 dropout은 추가하지 않았다.
3.1 Dropout noise as data augmentation
논문에서는 이러한 dropout noise를 일종의 data augmentation이라고 간주했다 : positive pair는 똑같은 문장이고, 그들의 embedding은 dropout mask를 통해 달라진다. 본 논문에서는 STS-B의 실험과 비교를 진행했다.
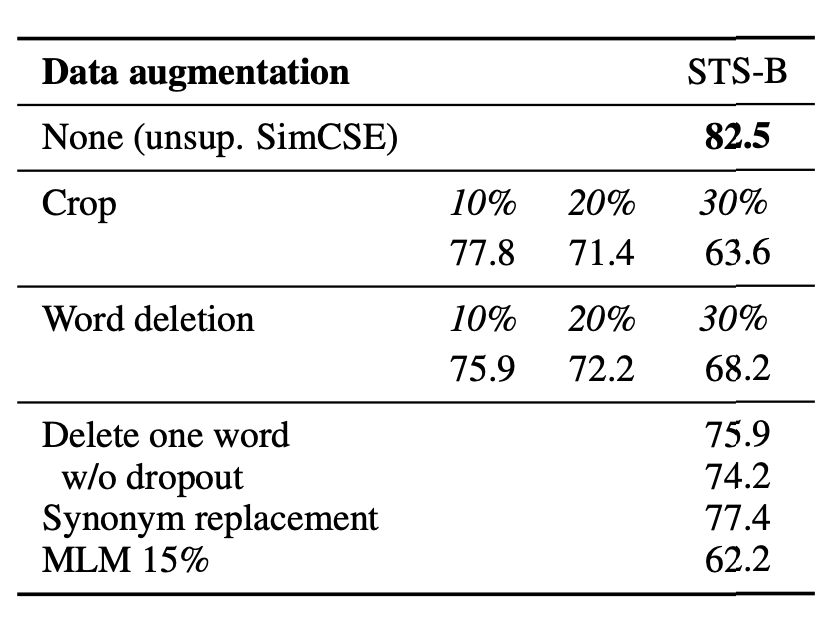
위의 table은 기본적인 data augmentation (crop, word deletion, replacement)의 성능을 비교하는 표이다. 이러한 기법들은 으로 표현할 수 있고 는 에 대하여 random discrete operator이다.
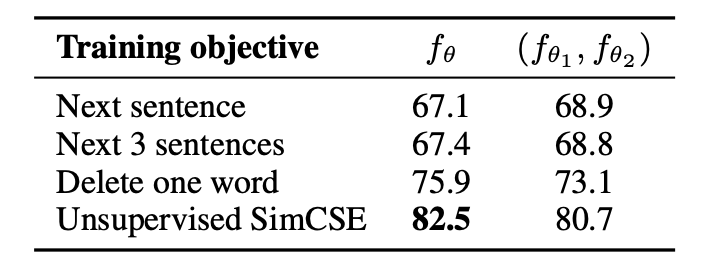
또한, 논문에서는 self-prediction objective인 NSP를 통해 성능을 비교했고 1개의 encoder를 사용하는것이 상당한 차이를 내는것을 확인할 수 있었다.
3.2 Why does it work?
SimCSE의 unsupervised learning에서 dropout의 비율을 비교해봤다. Transformer 모델의 default값인 p = 0.1일 때 성능이 제일 좋은것을 확인했다.
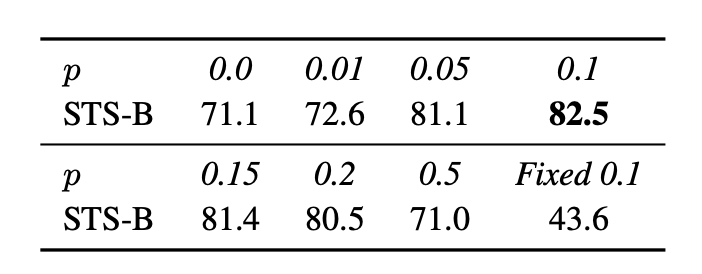
저자들은 흥미로운 점 2가지를 발견했는데, pair 문장에 dropout을 적용하지 않았을 때와 p = 0.1을 똑같이 적용했을 때, 두 가지 상황에서 성능이 극단적으로 저하되는것을 발견할 수 있었다. Pair의 sentence embedding은 둘다 정확하게 같았다.
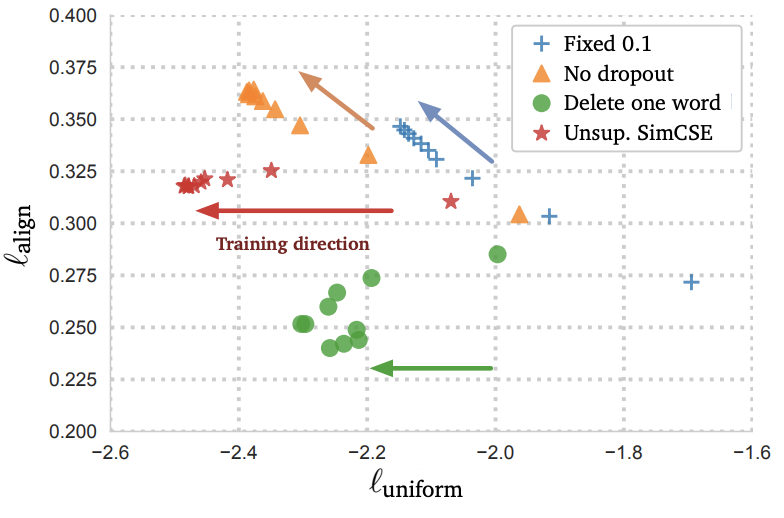
위의 그래프를 통해 모든 기법에서의 embedding uniformity가 좋은것을 확인할 수 있다. Unsupervised learning을 제외한 다른 기법의 alignment는 흔들린것을 확인할 수 있다.
4. Supervised SimCSE
논문에서 dropout noise를 추가하는것이 positive pair의 alignment를 좋게 유지할 수 있다고 증명했다. 이전 논문에서는 NLI dataset에서 두 문장의 관계를 예측하면서 sentence embedding을 얻는것이 효과적임을 확인했다.
4.1 Choices of labeled data
먼저 저자들은 dataset이 positive pair를 구성하는데 적합한지 알아봤다. NLI dataset을 포함한 여러 dataset을 통해 성능을 확인했다.
먼저 positive pair를 구축하는것에 있어서 dataset이 적합한지 알아봤다. 총 4개의 dataset을 이용하여 실험을 진행했다.
- Quora question pairs (QQP)
- Flick30K
- paraNMT
- NLI datasets(SNLI, MNLI)
이러한 dataset을 이용하여 contrastive learning을 진행했다.
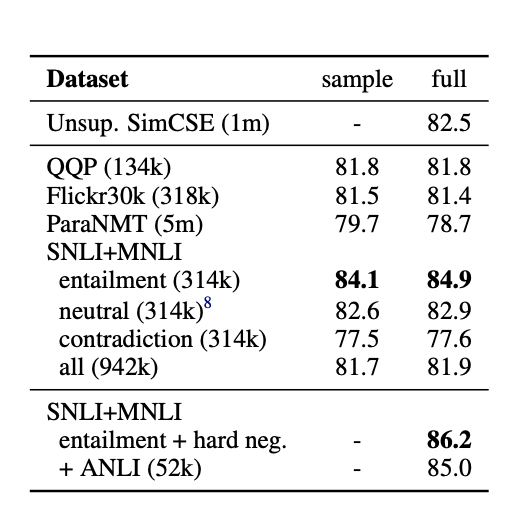
각각 모두 같은 양의 training pair를 이용해 실험을 진행했고 NLI dataset의 점수가 제일 좋았다. Crowd-sourced로 된 data로 구성되어 있고 pair 문장이 적은 차이의 문법구조를 가지고 있기 때문이다.
4.1 Contradiction as hard negatives
그리고 논문에서는 contradiction pair를 hard negatives로 사용하면서 성능을 높였다. NLI dataset의 annotator는 entailment와 neutral은 true로 contradiction은 false로 설정한다. 따라서 를 로 확장하고 는 neutral, 는 entailment, 는 contradiction으로 설정했다. Supervised training objective는 다음과 같다.
Table 4에서도 볼 수 있듯이, hard negative를 추가하는것이 더 나은 성능을 보여준다(84.9 -> 86.2) 그리고 이거이 최종 supervised learning이다. 또한 저자들은 ANLI dataset을 추가하면서 혹은 unsupervised SimCSE방법을 결합했지만 성능 향상은 일어나지 않았다. 또한 encoder를 두개 사용한것도 성능 향상이 없었다.
5. Connection to Anistropy
최근에, 학습된 representation embedding이 표현력도 심하게 부족하고 vector space에서 좁은 콘 모양으로, anisotropy 현상이 일어나는것을 깨달았다. Gao et al.(2019)은 input과 output의 embedding이 동일하면 anistropic한 embedding이 도출된다고 증명했고 또한 contextual representation에서도 나타났다. Wang et al(2020).은 language model에서 word embedding matrix의 특이값이 급격하게 decay되는것을 확인할 수 있다 : 몇개의 특이값 빼고는 전부 0이다.
이러한 문제를 완화시키는 방법은 후처리이다. 후처리로는 주성분을 제거하거나 istropic 분포로 embedding을 mapping 시키는 방법이 있다. 다른 일반적인 해결책은 훈련하는 동안, regularization을 거는 방법이 있다. 본 논문에서는 이론적으로, 실험적으로 contrastive objective가 anistropy 문제를 해결할 수 있다고 한다.
이러한 anistropy 문제는 본질적으로 uniformity와 연결되어 있고, 두가지 모두 embedding은 space에 고르게 분포되어야 한다는것을 강조하고 있다. 직관적으로 negative instance를 서로 멀게하면서 contrastive learning은 uniformity를 해결할 수 있다는것을 알 수 있다. 그리고 논문에서는 word-embedding을 분석할 때 자주 사용하는 방법으로 singular spectrum의 관점을 가진다. Contrastive objective는 sentence embedding을 펼 수 있고 representation을 더 넓게 펼칠 수 있다.
Wang and Isola(2020).에 따르면 contrastive objective의 asymptotics는 negative의 instance가 무한에 수렴함에 따라, 밑에 식으로 표현할 수 있다. (f(x)는 normalized)
먼저 첫번째 항은 positive instance들의 embedding distance를 가깝게하고 두번째 항은 negative instance가 멀리 떨어지게한다. 가 유한한 sample , 에 대하여 uniform히면 Jensen's inequality를 이끌어낼 수 있다.
여기서 Jensen's inequality란 기대값의 볼록 함수와 볼록 함수의 기댓값 사이의 성립하는 부등식이다. 만약 함수 가 열린구간의 이차함수일 때, 기댓값 와 가 존재한다면, 다음의 식이 성립한다.
W가 의 sentence embedding matrix라면 W의 i번째 row는 이다. 두번째 항을 최적화 하기 위해서는 의 모든 element의 합의 상한을 최소화할 수 있다.
를 정규화하기 때문에 에 있는 모든 주 대각원소가 모두 1이고 고유값들의 합인 tr는 상수이다. 의 모든 원소가 양수이면, 의 합은 가장 큰 고유값의 상한선이다. 두번째 항을 최소화 할때, 의 가장 큰 고유값을 작게하고 embedding space의 singular spectrum을 내재적으로 flatten한다. 이렇기 때문에 representation degeneration problem을 완화라고 sentence embedding의 uniformity를 향상시킨다.
Contrastive learning은 첫번째 항으로 positive pair를 align 또한 최적화할 수 있다.
6. Experiment
6.1 Evaluation Setup
7가지의 STS(semantic textual similarity)에 대하여 실험을 진행했을 때, unsupervised learning으로 진행하고 STS dataset은 사용하지 않았다. Supervised learning SimCSE에서 마저도 우리는 이전 연구와 같이 labeled datasets을 사용했다. 논문에서는 또한 7개의 transfer learning을 평가했다. Sentence embedding의 주 목표는 의미적으로 유사한 문장을 clustering하는것으로 STS의 결과를 취했다.
Semantic textual similarity task
논문에서는 7가지의 STS task를 평가했다. 이전 연구와 비교했을 때, 우리는 타당하지 않은 비교 패턴을 인식했다. 먼저 추가적인 regressor를 사용하는지 마는지, spearman vs 피어슨 상관계수, 결과를 어떻게 합치는지.
이전 논문의 연구뿐만 아니라 다른 setting의 결과를 평가했다. 우리는 미래의 연구에서 setting을 통일화 하는것을 요구했다.
Training details
우리는 BERT와 RoBERTa의 pre-trained checkpoint를 사용했고 CLS token을 sentence embedding으로 사용했다. Wikipedia애서 랜덤으로 선택한 문장에 대해 unsupervised SimCSE를 학습했고 MNLI와 SNLI dataset에 대해서 supervised SimCSE를 학습했다.
6.2 Main Results
우리는 STS task를 수행하는 sentence embedding의 SOTA와 SimCSE의 unsupervised와 supervised learning을 비교했다. Unsupervised learning의 baseline은 GloVe, BERT, RoBERTa의 embedding average와 post-processing method로는 BERT-flow와 whitening을 포함했다. 또한 contrastive objective을 사용한 다른 연구와도 비교를 했다.
- IS-BERT : global과 local features의 agreement를 최대화
- DeCLUTR : 동일한 문서에서의 positive pair에서 다른 span을 선택
- CT : 두개의 encoder에서 같은 sentence embedding을 align
Supervised의 baseline은 InferSent, Universal Sentence Encoder, SBERT, SRoBERTa를 사용했다.
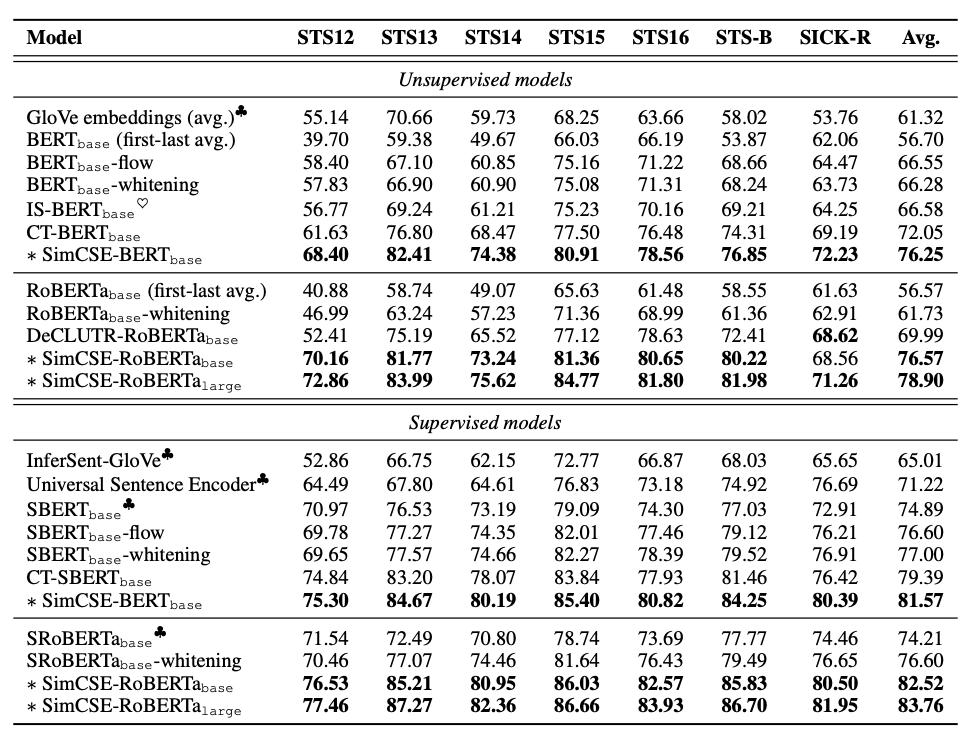
위의 table은 7가지 STS task의 결과로 SimCSE는 NLT supervision가 있던 없던 모든 dataset에 대해서 이전 SOTA model을 능가했다. 특히, unsupervised Sim-CSE-BERTbase에서 이전 가장 좋았던 성능인 72.05%에서 76.25%까지 올렸다. NLI dataset을 사용하면 SimCSE-BERTbase의 성능은 81.57%까지 올렸다. RoBERTa를 사용했을 때, 성능은 더 많이 올랐다. Appendix E에서는 SimCSE가 transfer task performance에서도 동일하거나 더 좋은 결과를 보여줬고 auxiliary MLM objective는 성능을 더 끌어올렸다.
6.3 Ablation Studies
본 논문에서는 다른 pooling 방법과 hard negative의 영향에 대해서도 조사했다. 이 section에서의 결과는 모두 STS-B development set을 기반으로 했다.
Pooling Methods
Pre-traind model의 평균 embedding은 (특히 첫번째 혹은 두번째 layer에서) CLS token보다 성능이 더 좋았다.
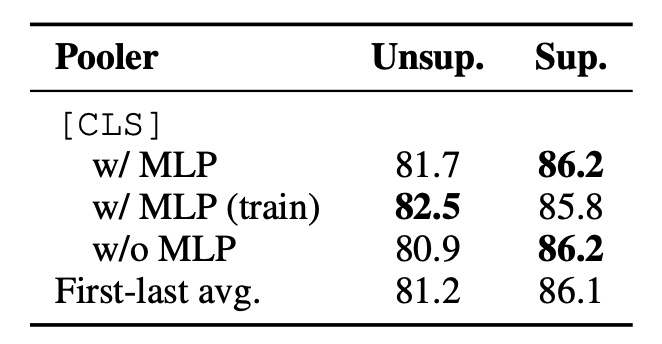
CLS token에 대하여 기존 BERT에서 MLP layer를 추가했고 다양한 setting을 통해 결과를 비교했다.
- MLP Layer
- no MLP layer
- train MLP layer / test no MLP layer
결과적으로 unsupervised에서는 3번째가 성능이 제일 좋았고 supervised에서는 다양한 pooling 방법들이 맞지 않았다.
Hard negatives
직관적으로 다른 batch의 negative로 부터 hard negative를 미분하는것은 굉장히 좋은 방법이다. 그러므로 training objective까지 연장해서 사용했다.
는 i=j일 때 1이다. 논문에서는 SimCSE를 다른 값의 로 훈련했고 STS-B의 dev set을 통해 평가했다. 또한 논문에서는 neutral을 hard negative로 간주했다. 일 때, 성능이 제일 좋았다.
7. Analysis
이 section에서는 추가적인 실험을 진행.
7.1 Uniformity and alignment
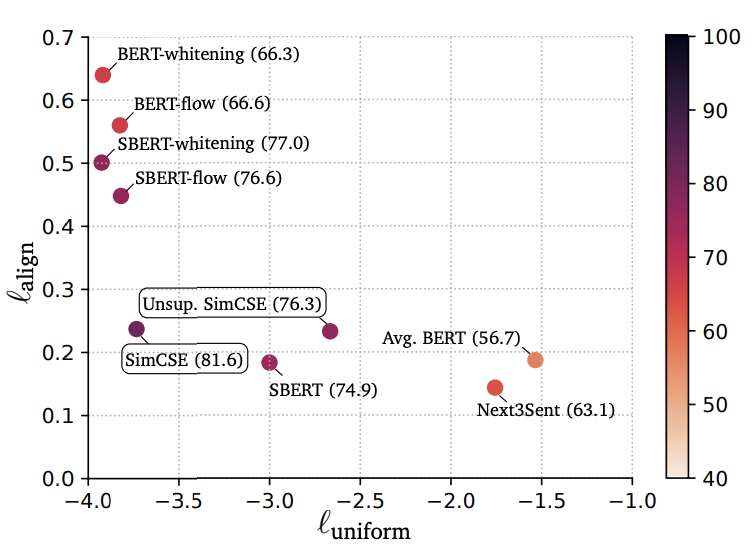
위의 표에서는 다양한 sentence embedding의 align과 uniform이 나타나있다.
1. Pre-trained model은 좋은 성능의 alignment를 보여주지만 uniformity는 좋지 못하다. 이 경우, sentence embedding이 매우 anisotropic하다고 볼 수 있다.
2. BERT-flow와 BERT-whitening과 같은 post-processing 방법은 좋은 uniformity를 갖지만 alignment는 좋지 못하다.
3. Unsupervised SimCSE는 uniformity를 효과적으로 향상시키고 alignment는 좋게 유지한다.
4. Supervised data를 SimCSE와 통합하면서 alignment를 수정했다.
7.2 Qualitive comparison
논문에서는 작은 scale의 실험을 진행했다. SBERT-base와 SimCSE-BERT-base를 사용했고 150k의 자막을 코사인 유사도를 구했다. SimCSE가 더 좋은 퀄리티를 보여줬다.

