캡스톤에서 준비한 주제를 위해 Vision에서 등장 transformer를 기반으로한 Vision Transformer에 대해 알아봤다.
0. Introduction
현재 NLP에서는 transformer를 기반으로 한 여러 SOTA model이 존재하고 등장하고 있다. 이러한 transformer architecture를 크게 손대지않고 vision task에 적용한 논문이다. 이미 vision 분야에서 attention 기법을 활용한 model이 존재했었고 이를 CNN을 기반으로 한 model과 결합하여 사용했었지만 CNN기반의 model의 성능을 넘지 못했다.
그러나 본 논문 Vision Transformer에서는 CNN 구조에 의존하지 않고 tranformer의 encoder에 image patch sequence를 사용하여 CNN 기반 model의 성능을 넘어섰다.
먼저 Vision Transformer의 장점으로는 먼저 transformer 구조를 그대로 사용하기 때문에 확장성이 좋다. Pose estimation 분야에서도 추가적인 decoder를 붙여 사용할 수 있는것처럼 여러 task에서도 사용이 가능하다. 다음 장점으로는 NLP에서도 증명이 된것처럼, 규모가 큰 data를 활용하는 학습에서 우수한 성능을 보여준다. Dataset이 크다면 그에 맞추어 model의 size를 높이면 되고 성능이 saturate될 가능성이 현저히 적다. 또한 trasfer learning을 진행할 때, 기존 CNN기반의 model보다 더 적은 resource를 활용할 수 있다.
그러나 단점으로는 inductive bias의 부족으로 인하여 많은 data가 요구된다는 단점이 존재한다. 여기서 inductive bias는 model이 처음 보는 input에 대한 output을 예측하기 위해 가정을 하는 것을 의미한다.
기존 CNN에서는 translation equivariance와 locality를 가정한다고 하는데 먼저 translation equivariance는 input의 위치에 따라 output의 위치 또한 변한다는것이다.
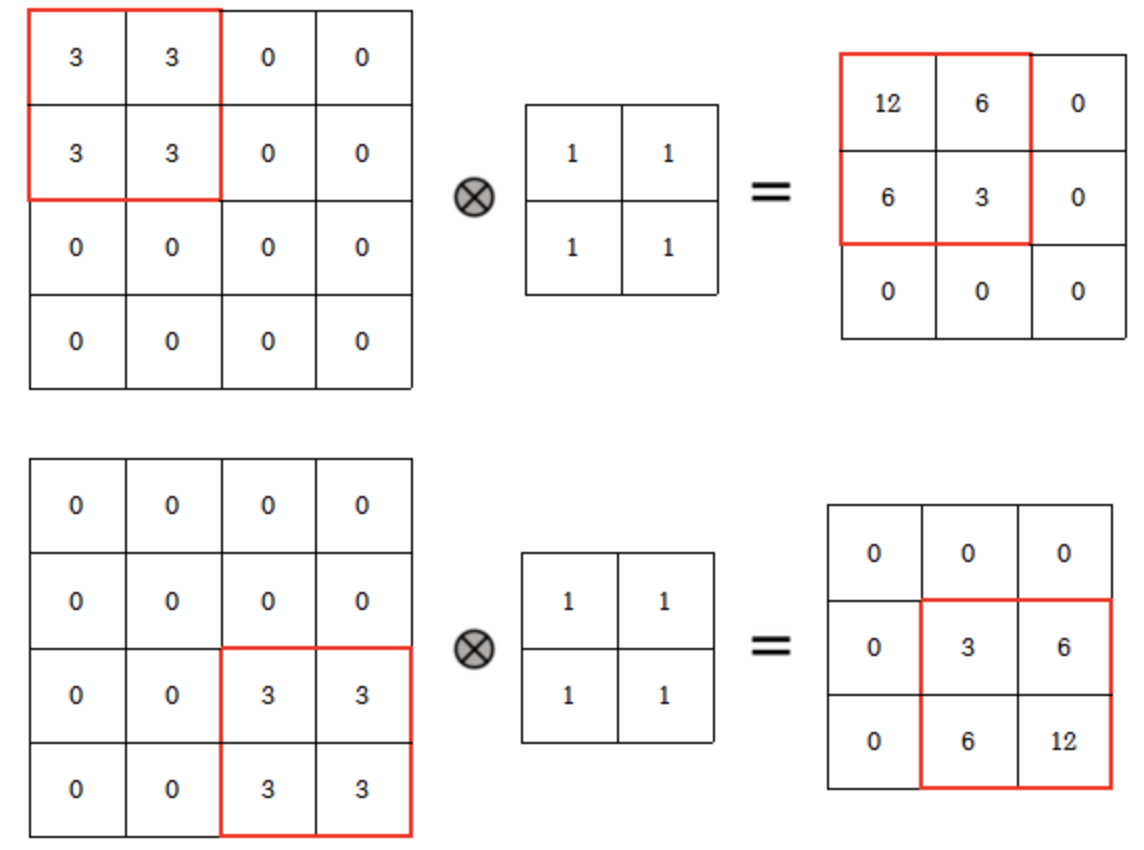
위 그림을 보면 input의 위치에 따라 output의 위치 또한 변한다는것을 가정한다. 또한 CNN에서는 이러한 가정 때문에 MLP보다 좋은 성능을 보여주는데, MLP에서는 이러한 patch의 위치가 조금 달라져도 flatten된 vector 값이 달리지고 이에 따라 FC-layer연산을 진행하면서 weight값도 달라지기 때문이다.
Locality는 convolution 연산을 하면서 input image에서 convolution filter가 data의 일부분만 보고 feature를 추출한다는 것을 가정한다. 위 그럼에서 2x2 local만을 보면서 특징을 추출할 수 있다.
그러나 transformer의 attention mechanism을 사용하는데 이는 local receptive field를 통해 feature를 추출하는것이 아니라 data 전체를 보고 attention할 부분에 적용하는 방법이기 때문에 model이 이러한 pattern을 학습하기 위해서는 CNN보다 더 많은 data가 필요하다. 이러한 점 때문에 충분한 data가 존재하지 않으면 모델의 일반화가 부족하게 된다.
Vision Transformer
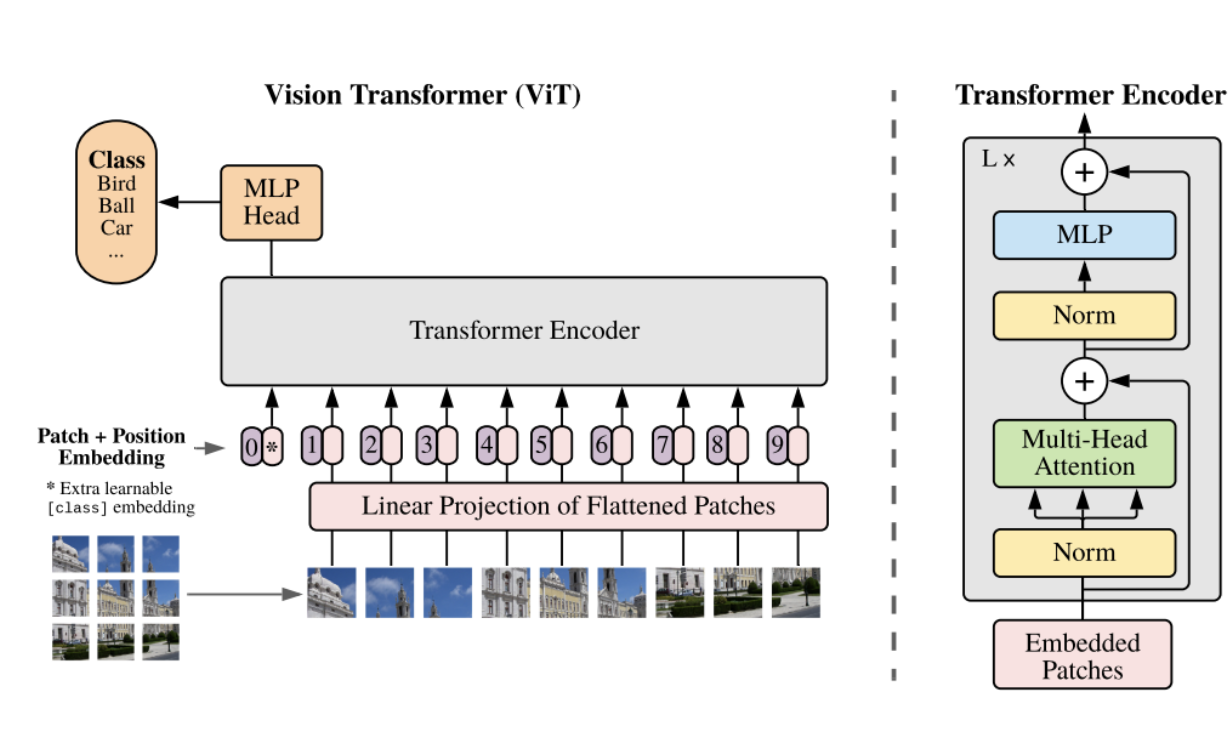
Vision Transformer에서는 transformer에서 encoder만을 사용한다. Transformer는 sequence data를 먼저 embedding하고 positional encoding을 더해줘서 input으로 넣었는데, vision transformer에서도 동일한 방법으로 진행된다.
Transformer와 동일한 구조의 input data를 만들기 위해 image를 patch단위로 쪼개고 왼쪽 상단에서 시작해서 오른쪽 하단까지의 sequence data를 만든다.
Transformer에서 embedding된 data는 vector값을 가지므로 각 patch를 flatten하여 vector로 변환하고 linear 연산을 거쳐 embedding을 시켜준다. 그리고 이 embedding된 vector에 class를 예측할 수 있는 class token을 추가하고 positional embedding을 더해주면 최종 vision transformer의 input값이 된다.
좀더 자세히 들여다보면 각 patch는 (channel, patch_size, patch_size)의 크기를 갖게 된다. Patch를 flatten 하면 N개의 P^2C size의 vector가 나오게된다.
예를 들어, (3x256x256) size의 image가 들어오고 patch_size를 16으로 한다면, 각 패치의 크기는 3x16x16이 되고 patch의 개수는 16x16이 된다. 이러한 patch를 flatten하면 3x16x16 = 768 크기의 vector가 총 16x16개가 된다. (전체 데이터는 (256, 768)의 shape를 가지게됨.)
이렇게 생성된 patch 를 embedding하기 위해 embedding matrix 와 연산을 해준다. 이때 의 matrix size는 의 shape를 갖고 있고 이때 는 embedding dimension을 의미한다.
의 shape 와 의 shape 의 행렬 곱 연산을 통해 의 size를 갖게된다. (Batch size를 추가하면 (B, N, D) shape의 tensor) 그리고 class token을 더해주면 (N+1, D)의 크기가 되고 이때 class token은 학습가능하다. 그리고 같은 shape의 positional encoding을 넣어주면 최종 input값이 된다.
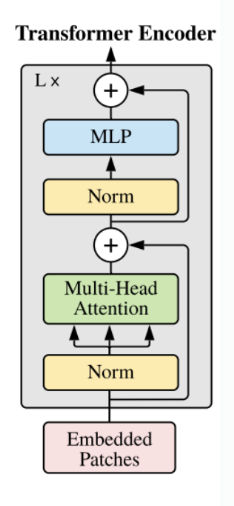
다음 encoder의 구조를 뜯어보면 기존 transformer와 조금 다른것을 확인할 수 있다. 기존에는 multi-head Attention을 진행한 뒤에 Layer normalization을 진행했지만, vision transformer는 바뀌어 있다. Layer normalization은 D차원에 대하여 각 feature를 정규화해주는 것이다.
Multi-head self attention과정에 대해서는 생략하고 각 head의 self attention의 결과를 concat한것이 최종 결과이다.
최종적으로 MLP layer를 거치게되고 이때 GELU activation을 사용한다. L번 반복한 encoder의 마지막 output에서 class 부분만을 MLP에 따로 넣어 classification으로 활용하게 된다.
Experiments
먼저 Vision Transformer의 학습 setting에 대해 알아보면 large dataset에 대해 먼저 사전학습을 시행한뒤 작은 dataset에 대해 fine-tuning을 진행한다. 이때 MLP의 head 수를 class에 맞게 설정한다.
Pre-train에 사용된 data는 ImageNet, ImageNet-21k, JFT를 사용했다. Resize, RandomCrop, RandomHorizontalFlip을 통해 전처리를 진행했고 ImageNet, CIFAR10/100, 9-task VTAB 등 데이터셋에 대해 transfer learning 또한 진행했다.
Pre-train
- Adam optimizer
- Linear learning rate decay
- 0.1 weight decay
- 4,096 batch-size
- Label smoothing
Transfer learning
- SGD momentum
- Cosine learning rate decay
- Grad clipping
- 512 batch-size

먼저 위와 같이 vision transformer의 크기를 3가지로 설정하여 실험을 진행했다.
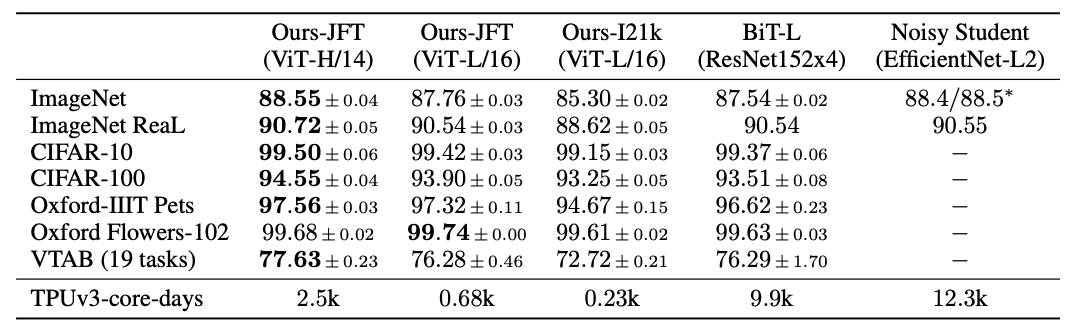
위의 표는 vision transformer가 기존 CNN model보다 좋은 성능을 보여준다는것을 알 수 있다.
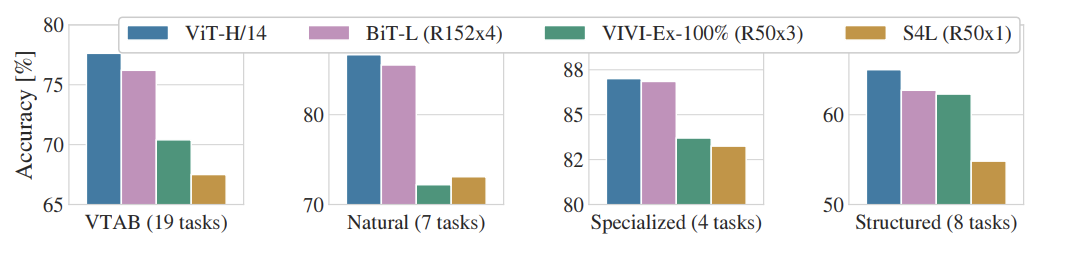
또한 본 논문에서는 data의 특성에 따라 성능이 달라질 수 있는데 이를 위해 data를 묶어서 실험을 진행한 결과이다.
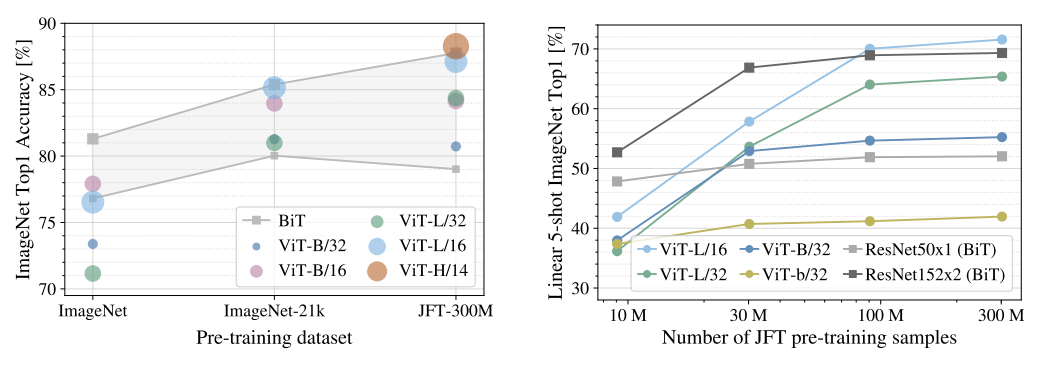
ImageNet과 같이 중간 size의 dataset에서 학습했을 때, 이는 ResNet보다 더 낮은 성능을 보여주고 있는데 이는 CNN보다 inductive biases가 부족한것을 보여주고 있다. 결국 vision transformer는 충분한 dataset이 필요하다고 볼 수 있다.
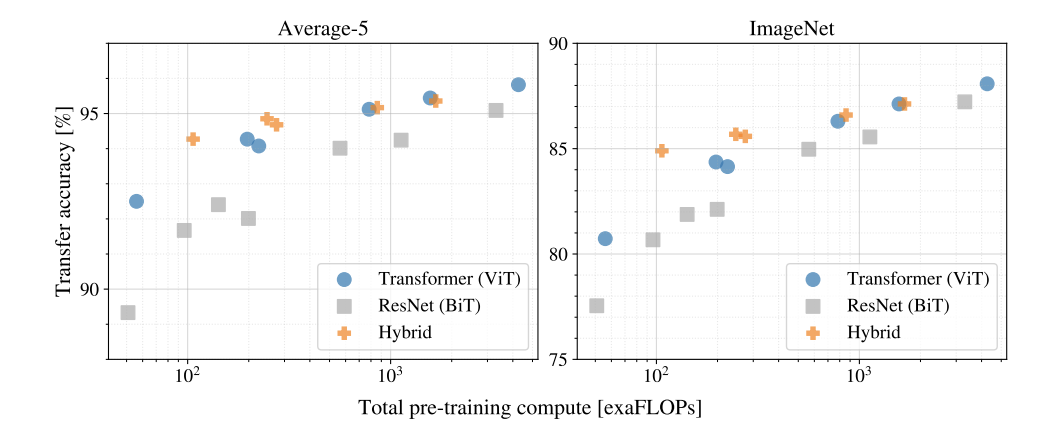
다음으로는 scaling에 대한 실험인데, 위의 그래프를 통해 vision transformer는 ResNet보다 절반정도의 계산량이 필요한것을 알 수 있고 saturate되지 않으며 scaling이 가능하다는것을 알 수 있다.
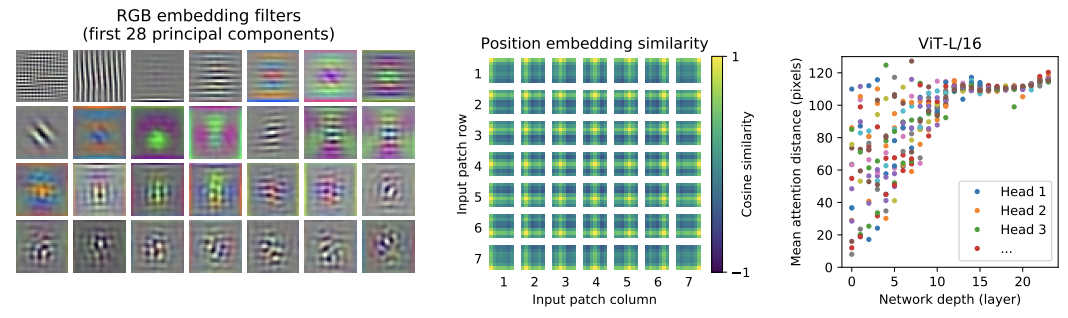
가장 왼쪽의 그림은 encoder에 들어가기전 embedding을 할 때 RGB embedding filter인데, CNN의 low level layer에서와 유사한 형태를 보여주고 있다.
다음 그래프는 Positional Embedding Similarity 그림의 시사점은 Positional Embedding이 데이터의 위치를 잘 위미하도록 학습이 잘 되었다는걸 볼 수 있다. Positional Embedding 에는 각 패치 마다 대응되는 Embedding 벡터가 존재하는데cosine similarity를 구하였을 때 각 row, col에 해당하는 부분의 패치가 similarity가 높은 것을 통해 Position이 의미가 있도록 학습이 잘 되었다는 것을 확인할 수 있다.
오른쪽 그래프에서는 attention 위치의 편차를 보여주고 있다. Low level layer에서는 일부분만 보고 있고 high level layer에서는 전체적으로 보고있는것을 알 수 있다. 거리가 짧을수록 가까운 위치에 attention을 적용하는것이고 거리가 멀수록 먼 위치에 attention을 적용하는것이다.
VITPose
0. Introduction
Human pose estimation은 현재 computer vision에서 근본적인 task로 자리잡아가고 있다. Human의 anatomical keypoints를 localize하는 task로 variations of occlusion, truncation, scales, and human appearances를 다루고 있다. 이러한 것들을 다루기 위해 여러 deep learning을 기반으로한 방법들이 적용되고 있다.
최근, vision transformer는 vision task에서 놀라운 성능을 보여주고 있다. 이에 따라 pose estimation 분야에서도 vision transformer의 구조를 달리하여 적용하고 있고 대부분 backbone을 CNN을 기반으로 하고 있다. 예를 들어, PRTR은 transformer의 encoder와 decoder를 점진적으로 key points를 cascade manner를 통해 정제한다. TokenPose와 TransPose는 오직 encoder만을 사용하여 feature를 extract하고 HRFormer는 transformer를 통해 직접 feature를 extract하고 multi-resolution parallel transformer modules를 통해 high resolution representation을 추출한다. 이러한 방법들은 좋은 성능을 보여줬지만, CNN을 필요로한다는 공통적인 특징을 가지고 있다.
본 논문에서는 오직 transformer만을 이용하여 pose estimation의 task를 수행하는 VITPose를 도입했다. VITPose는 오직 plain한 transformer를 backbone으로 하여 feature extract하고 masked image modeling을 통해 이 backbone을 pre-train했다.(좋은 initialization을 얻기 위해) 다음, light weight decoder를 통해 upsampling과 heatmap의 keypoints를 regressing한다. 이때 decoder는 두개의 deconvolution layers와 하나의 prediction layer로 구성되어 있다. 단순하고 정교하지 않은 model의 구조를 통해서도 SOTA를 달성했다.
또한 VITPose는 namely simplicity, scalability, flexibility,
and transferability하다는 특징을 가지고 있다.
Simplicity
VITPose의 framework는 아주 단순하고 특정한 domain에 대한 지식 없어도 괜찮으며 plain한 encoder로 구성되어 있음. 또한 decoder 역시도 단순한 구조를 가지고 있음.
Scalability
simplicity 덕분에 굉장한 Scalability의 특징을 가지게 됨. Transformer의 layer를 stacking하면서 model의 size를 더 키울 수 있고 feature dimension 또한 쉽게 늘리고 줄일 수 있음. (ViT-B, ViT-L, or ViT-H)
Flexibility
VITPose는 training paradigm에 있어 융통성있는 특징을 보여주고 있음. 특히 input resolution과 feature resolution이 다름에도 model이 잘 적응함. Single pose dataset을 train해도 multiple pose로 decoder를 추가하여 수정해서 사용가능? decoder를 추가하여
Transferability
VITPose는 attention modules frozen를 통해 transfer learning에서도 좋은 성능을 보여줌. Knowledge token을 통한 knowledge distillation에서도 좋은 성능을 보여줌.
3. ViTPose
3.1 The simplicity of ViTPose
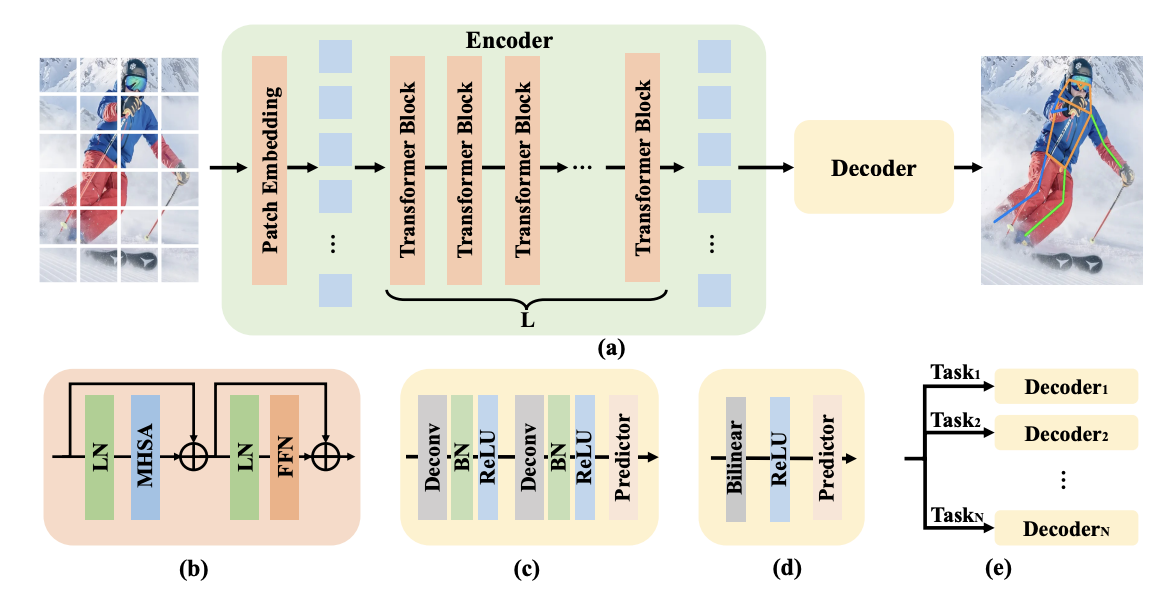
본 논문의 목표는 pose estimation task에서 단순한 구조를 가지고 있지만 성능이 잘나오는, 효율적인 vision transformer를 제시하는데 있다. 그러므로 성능을 올려주지만, 복잡한 구조를 최대한 사용하지 않았다. 끝으로, transformer를 기반으로한 backbone을 지나 heatmap을 예측하는 구조의 decoder, skip connection과 cross-attention을 사용하지 않는 단순한 구조의 decoder를 추가적으로 사용했다. 특히, person instance가 있을 때, patch embedding layer와 channel dimension의 비율로 downsampling된다. Patch로 embedding된 token들을 multi-head attention과 feed-forward network로 구성된 transformer의 module을 지나게 된다. 이를 수식으로 표현하면 다음과 같다.
- i = transformer의 layer index
최종 output은 다음과 같다.
다음은 본 논문에서 두 가지 light weight decoder를 활용했다. 먼저 두개의 deconvolution layer와 batch normalization, ReLU로 구성된 classic decoder를 사용했다.
다음으로는 bilinear와 ReLU, 3x3 convolution layer로 구성된 좀 더 simple한 decoder를 사용했다.
< Bilinear Interpolation이란? >
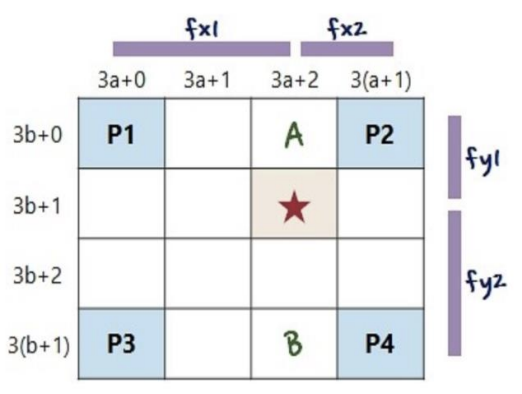
- 기존 행렬에서 3배로 확대할 때 별의 값은?
- P1, P2, P3, P4 원본 값을 그대로 받음
- 4개의 점으로부터의 거리비를 구함
- P1과 P2 각각의 값과 거리비로 A의 값을 구함
-> A = (1/3) P1 + (2/3) P2 - P3과 P4 각각의 값과 거리비로 B의 값을 구함
-> B = (1/3) P3 + (2/3) P4 - A와 B의 Interpolation을 y축으로 적용해서 별의 값을 구함
-> = (1/3) A + (2/3) B
저자들은 ViTPose와 더 simple한 decoder를 활용했을 때, 기존 classic decoder보다 성능이 크게 다르지 않음을 시사했다.
3.2 The scalability of ViTPose
ViTPose는 기존 transformer의 특징과 연결되는, transformer layer의 개수와 feature dimension을 줄이거나 늘리면서 size를 쉽게 조정할 수 있다. 본 논문에서는 기존 vision transformer의 size와 맞게 backbone을 제시했다.

또한 ViT-H와 ViTAE-G에서는 14x14 size의 patch embedding을 진행했는데, 이는 zero padding을 해주어 16x16으로 setting했다.
3.3 The flexibilty of ViTPose
Pre-training data flexibility
- 기존에는 ImageNet을 통해 backbone을 pretrain했음
- 이는 pose estimation과는 거리가 먼 data
- 따라서 masked autoencoder 방법으로 MS COCO data와 AI challenger data를 통해 pretrain진행 (masking 75% patches)
- 기존 ImageNet data와 비교했을 때 작지만 좋은 성능을 보임
Resolution flexibility
- Resolution이 영향을 끼치는지에 대해 실험을 진행
Attention type flexibility
- higher resolution을 사용하거나 full attention하면 memory 많이 소모
- computational cost를 줄이고자 relative position embedding과 window-based attention을 활용
- 기존 window-based기법이 아닌 shift window와 pooling window를 결합하여 사용
Finetuning flexibility
- 기존 NLP domain에서도 증명되었듯이, pre-trained transformer는 부분적으로 parameter를 tuning하여 general하게 사용 가능
- 실험에서 all parameter frozen, MHSA frozen, FFN frozen으로 나누어서 진행
3.4 The tranferability of ViTPose
-
본 논문에서는 Token-based Distillation 방법을 활용
-
Knowledge token T를 teacher model의 patch embedding 이후 visual token과 결합
-
Teacher model을 학습하고 optimal token t*를 구함
-
Optimal token t*를 student model의 visual token과 결합하여 학습을 진행
-
X: input image
-
: ground truth heatmap
-
Student network의 loss는 output distillation loss와 teacher loss의 합
4. Experiments
< Model Setting >
- Top-down setting
- 기존 Vision Transformer와 동일한 size로 설정
- Optimizer : AdamW
- Learning rate : 5e-4
- Batch Size : 512
- Weight Decay : 0.1
- Epochs : 210
- Sweep Layer Wise
- Stochastic Drop Path Ratio
4.1 Decoder Performance of MS COCO Val Set

- ViTPose의 classic decoder와 simple decoder 성능비교 및 다른 backbone 모델과의 성능 비교
- ResNet backbone과 simple decoder를 사용하면 성능 하락
- ViTPose에서는 동일한 성능을 보임
- 따라서 plain vision transformer는 complex한 decoder가 필수적이지 않음
4.2 The Influence of Pre-training Data

- Pre-training dataset의 영향력에 대한 실험
- Dataset을 ImageNet-1k, MS COCO, MS COCO + AI Challenger로 나누어서 실행
- MS COCO + AI Challenger에서는 Person Instance를 Crop하여 Dataset 생성
- MS COCO + AI Challenger는 ImageNet의 절반정도의 양으로 비슷한 성능
- 따라서 ViTPose는 pre-training data와 상관없이 잘 좋은 성능을 보여줌
4.3 The Influence of Input Resolution

- Input resolutions의 영향력에 대한 실험
- 위의 table에 나와있는 input image size로 나누어서 실험 진행
- input resolution이 커질수록 성능이 증가
- Squared input size이라고 성능이 더 좋지는 않음
(COCO Dataset에서 human의 비율이 보통 4:3)
4.4 The Influence of Attention Type
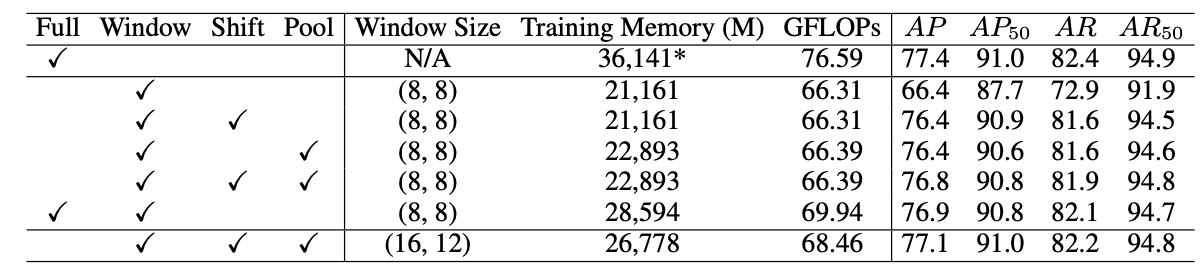
- Attention type의 영향력에 대한 실험
- Full, Window, Shift-window, Pooling-window Attention으로 나누어 진행
- Window의 경우 연산량은 많이 감소, Global Modeling의 부족으로 성능 저하
- Shift-window와 Pooling-window는 Window보다 비슷한 연산량으로 성능 비슷
- Window Size를 16x12로 증가시켰을 때 Full의 성능과 비슷한 성능을 보임
4.5 The Influence of Partially Finetuning

- Fine-tuning을 다르게 했을 때에 대한 실험
- Setting을 fully fine-tuning, MHSA module frozen, FFN frozen으로 나누어 진행
- FFN Module은 more task-specific한 module
- MHSA는 more task-agnostic한 module
4.6 The Influence of Multi-Task Learning
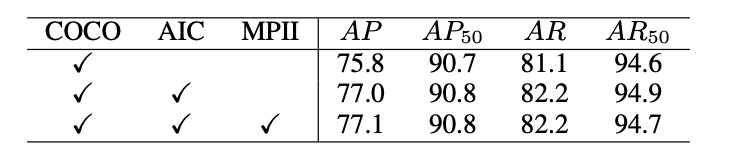
- Multi-Task Learning 성능에 대한 실험
- MS COCO, AI Challenger, MPII, CrowdPose Dataset으로 실험 진행
- ViTPose는 다른 task의 data를 훈련해도 좋은 성능을 보임
4.7 The Analysis of Transferability

- ViTPose의 trasferability에 대한 실험
- Teacher Model : ViTPose-L
- Student model : ViTPose-B
- MS COCO + AI Challenger에서는 Person Instance를 Crop하여 Dataset 생성
- MS COCO + AI Challenger는 ImageNet의 절반정도의 양으로 비슷한 성능
- Token Distillation과 output distillation을 combine 했을 때, 가장 좋은 성능
4.8 Comparison with SOTA Methods
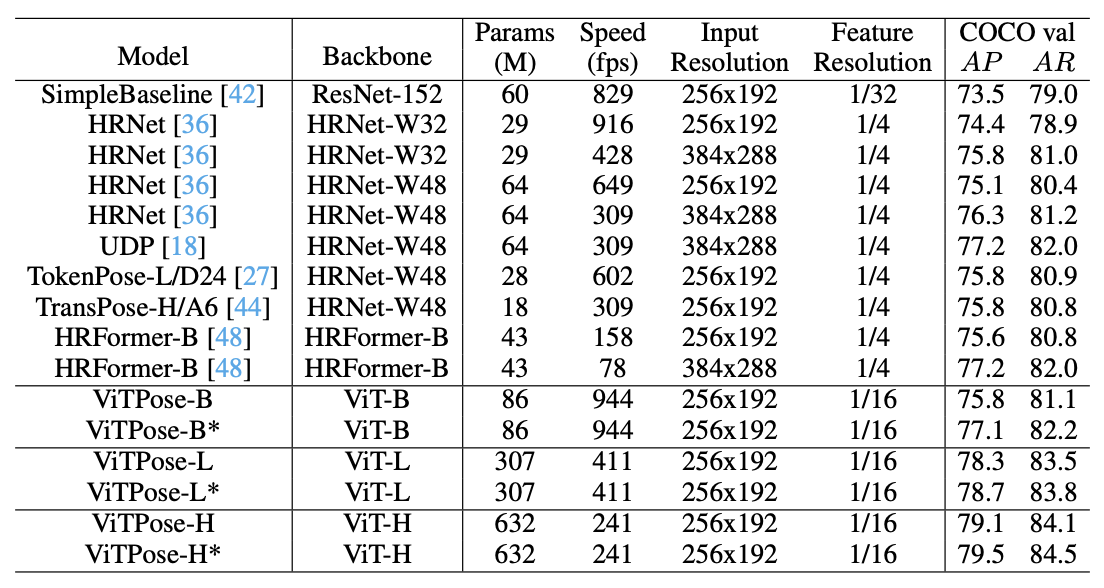
- 이전 SOTA Model과의 성능 비교
- 256 × 192 input resolution with multi-task training
- A100 GPU with batch size of 64
- ViTPose가 크지만 accuracy에 대해 좋은 trade-off를 보여줌
- ViTPose는 큰 backbone에서 더 좋은 성능을 보여줌
- ViTPose-L은 비슷한 inference 속도로 이전 CNN SOTA Model보다 좋은 성능을 보여줌

- ViTAE-G(1B)를 Backbone으로 하여 더 좋은 성능의 model 생성
- 576 x 432의 input resolution
- MS COCO + AI Challenger dataset으로 train
- Detector로 Bigdet을 사용
5. Conclusion
- Potential of ViTPose is not fully explored
추가적인 Mechanism과 FPN Structure와 같은 Complex한 Decoder를 사용하면 성능이 더 증가할 것으로 기대
- 이미 ViTPose의 Simplicity, Scalability, Flexibility, and Transferability을 증명했지만 더 탐구할 것들이 존재
Prompt-based Tuning을 통해 flexibility의 성능을 증명하지 못함
- Applied to Other Pose Estimation Tasks
Animal Pose Estimation, Face Keypoint Detection, etc..
