MultiModal프로젝트를 진행하면서 동향 발표를 진행하였고
Multimodal model로 VATT를 사용하고자 했는데 왜 사용하는지에 대해 강조하고자 하였다. 거기서 MultiModal representation Learning 에 대해 맡아서 공부했던 부분이다. Deep Multimodal Representation Learning: A Survey - 2019 논문을 참고하였다.

멀티모달 표현 학습의 주요 목표는 모달별 semantic 을 그대로 유지하면서 공통된 semantic 서브(하위)공간의 분포 격차를 줄이는 것

일반적으로 멀티모달 데이터를 기반 기계학습작업에는 3가지 필요한 단계 필요 :
1. 모달별 특징 추출
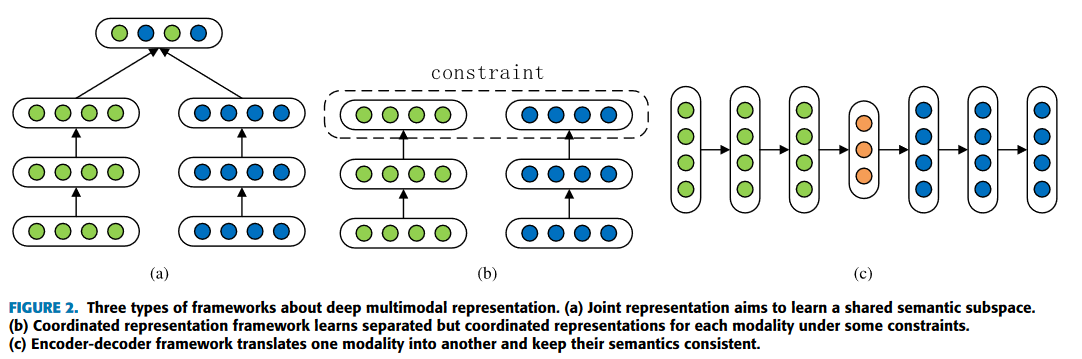
2. 공통 하위 공간에서 멀티모달의 다양한 특징을 통합하는 것을 목표로 하는 멀티모달 표현 학습 : joint representation , coorfinated representation, encoder-decorder
3. 분류 또는 클러스터링과 같은 추론 단계가 포함
Represetation learning? 
Multi-modal Joint representation learning?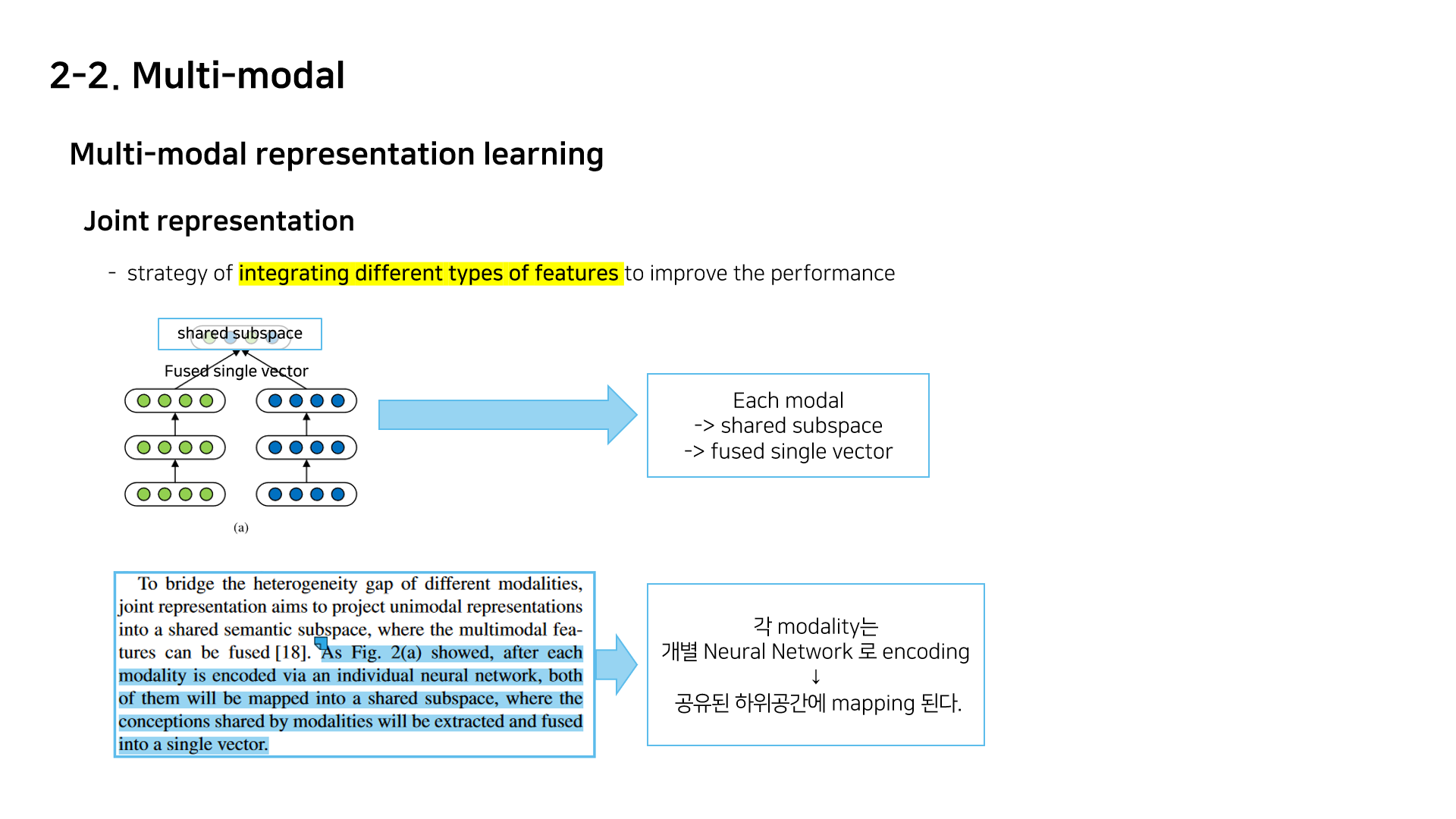


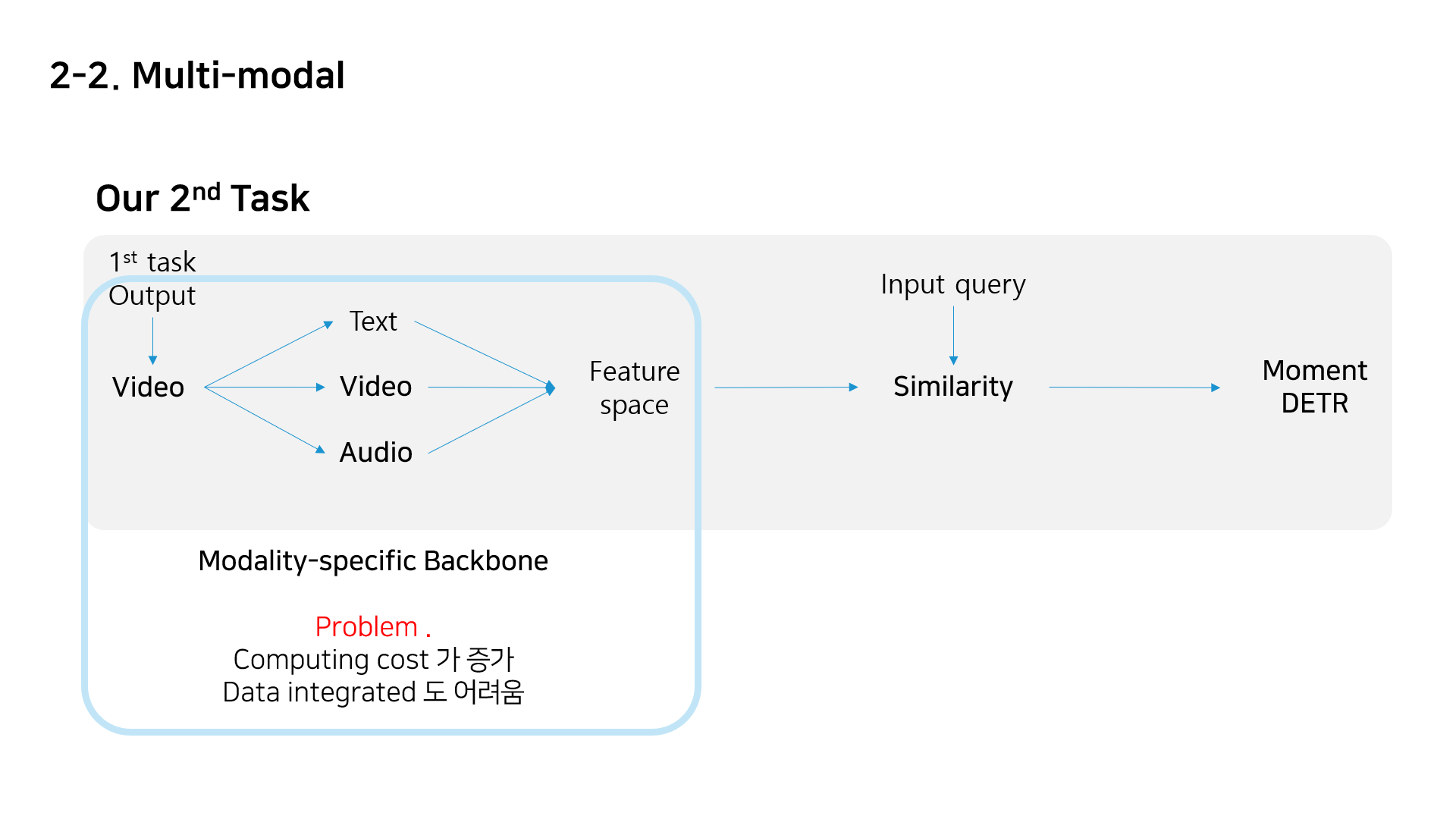
- 위과 같은 Computing cost 증가와 Data integrated 의 어려움을 극복하는 방안으로 VATT를 제시 하였고 이후 논문리뷰를 해볼예저엉어엉ㅇ이다

무니의 성장스토리 😣