Activation Function
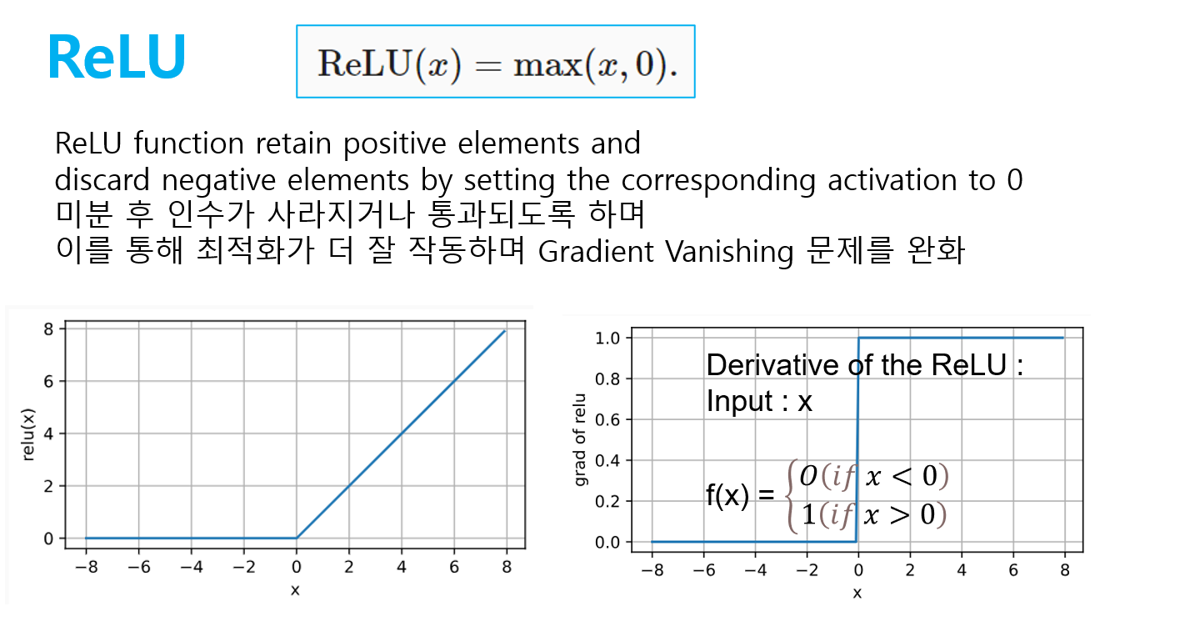
[1] ReLU
- non-saturating , nonlinearity
- Gradient Vanishing 해결
- 연산량이 적음
- dying ReLU problem : weight 가 특정 뉴런이 activate되지 않도록 바뀌면, 해당 뉴런을 지나는 gradient도 0이 된다. -> 이를 막기 위해서 learning rate 가 크지 않게 조절하며 대안으로 leaky relu 을 대안으로 사용가능하다.
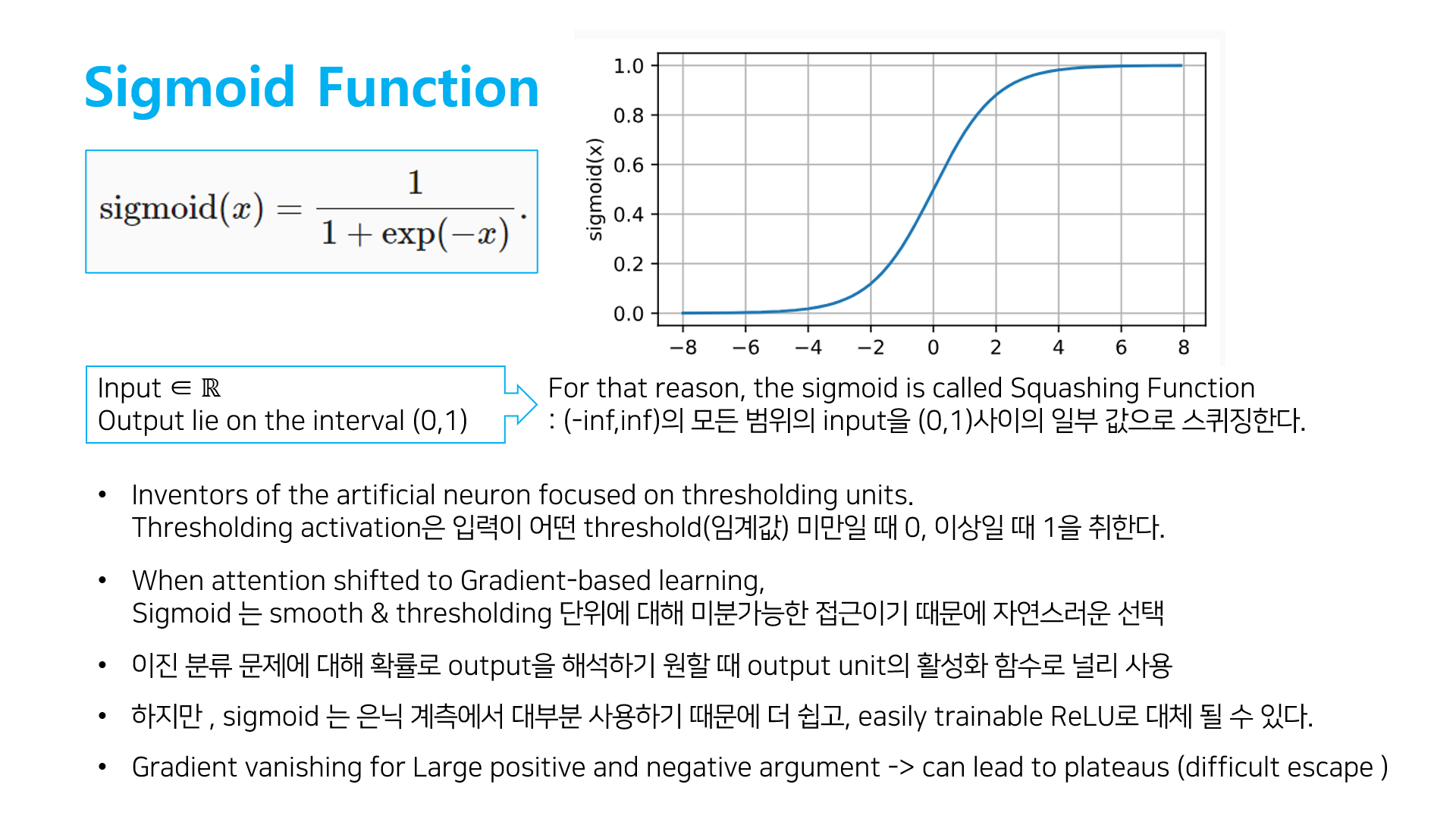
[2] Sigmoid function
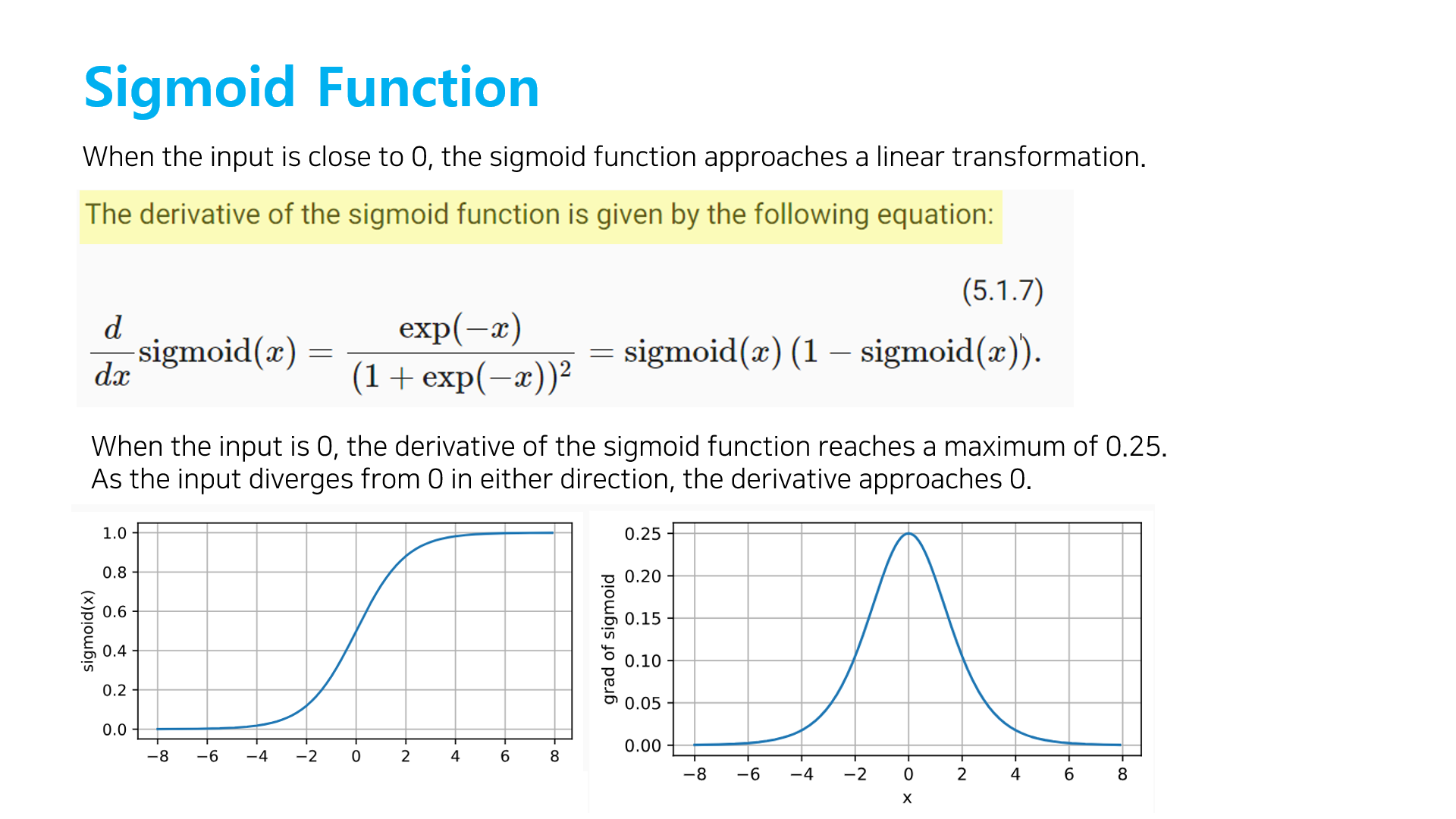
- saturing
- Gradient vanishing
: sigmoid는 미분값이 0에 매우 가까워 지는 특성으로 backpropagation에서 Gradient descent의 경우 chain rule을 이용하는데, 0에 매우 작은 값을 게속 곱한다면 0으로 수렴하게 된다. -> 학습의 결과가 back propagation 과정에 전달되지 못하고 weight값이 조정되지 않는다. - 중심값이 0이 아니기 떄문에 모수를 추정하기 어렵다.
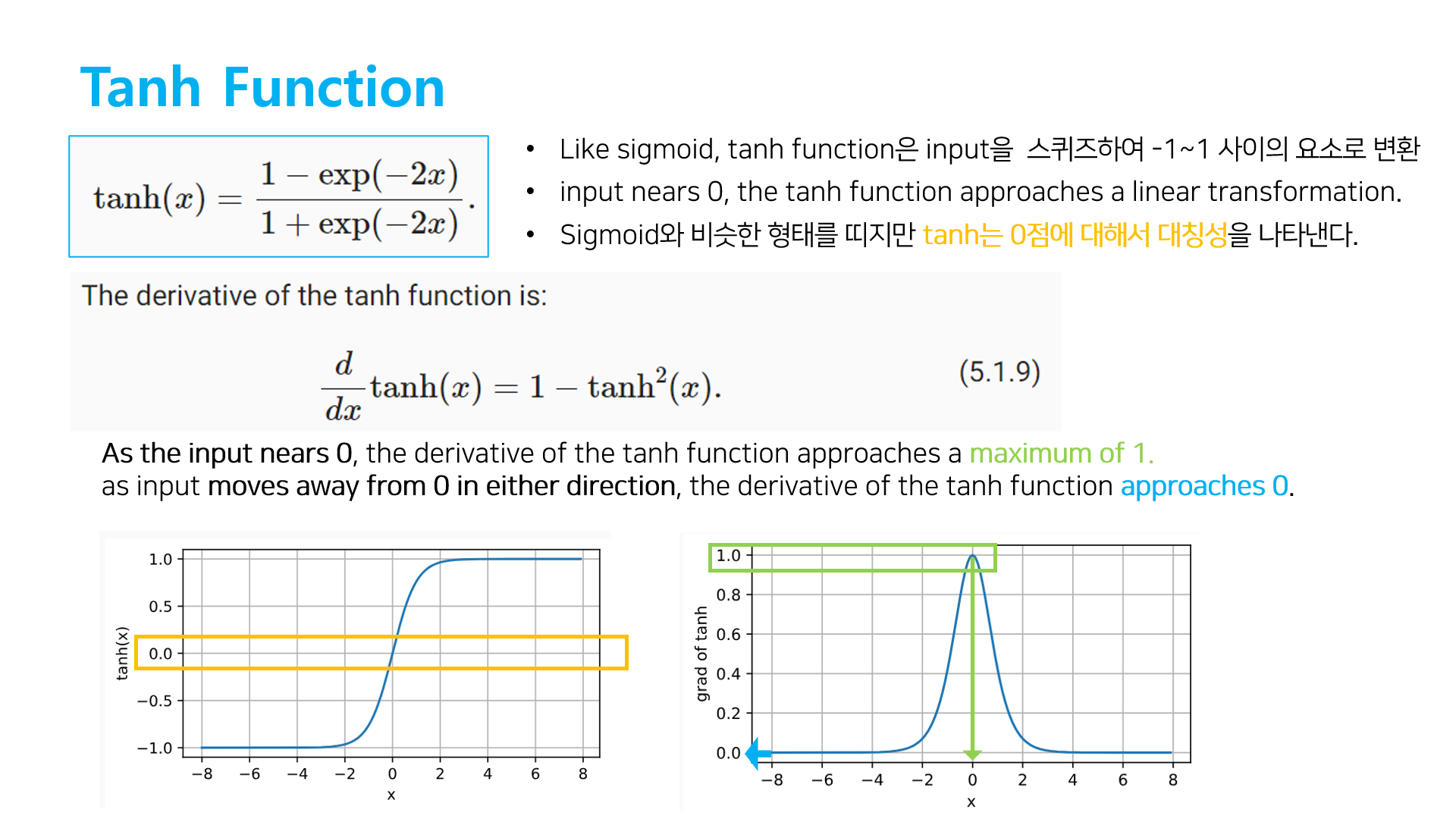
[3] Tanh function
- saturing
- Gradient vanishing
- 중심값이 0이여서 sigmoid보다 optimization 이 빠르다.

무니의 성장스토리 😣