[논문리뷰] ImageNet Classification with Deep Convolutional Neural Networks - 2012 AlexNet
PREVIEW
1) CNN의 성능을 증명한 네트워크
2) ReLU를 사용해서 Gradient Vanishing 문제 해결
3) Regularization : Dropout(어떤 레이어에서 일정 퍼센트만큼 0으로 만들어줌) + data aug
4) Local Response Normalization
1.Abstract
120만개의 high-resolution image를 1000개의 class 로 분류하기 위해 고안된 모델로 기존 sota 보다 top1, top5 에서 37.5%, 17.0% 의 에러율을 기록
- consist of : 60만개의 parameter , 65만개의 neuron 으로 구성된 신경망
- five convolutional layers (maxpooling-layer 포함)
- three FC layer with 1000-way soft max
학습을 빠르게 하기 위해서 [1]non-saturating neurons 사용 [2]GPU으로 효율적인 연산 overfitting 을 줄이기 위해서 정규화 기법인 [3]'dropout'을 사용함
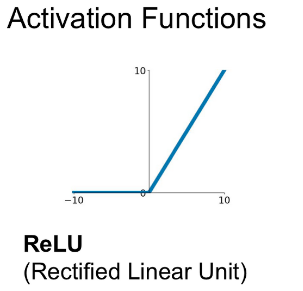
[1] non-saturating(기울기가 0에 수렴하지 않는) neuron 'Relu'
saturing은 특정 구간에 도달하면 수렴하는 함수를 의미한다.
반대로 non-saturating은 발산하는 함수를 의미한다.
1. Gradient vanishing 문제 해결
2. Gradient 가 간단해서 학습을 더 빠르게 할 수 있음
하지만 dying Relu 있을 수도 있음

[3]Dropout?
-네트워크의 일부를 작동하지 않도록 하는 규제 알고리즘 > 모델의 복잡도를 줄여 일반화 성능을 올리며 연산 감소의 이점도 가진다
뉴런의 작동 여부는 random 으로 정해지기 때문에 다양한 학습을 해야 효과를 볼 수 있다
2. Introduction
성과 :
- ILSVRC-2010 및 ILSVRC-2012 대회에 사용된 ImageNet의 하위 집합에서 현재까지 가장 큰 컨볼루션 신경망 중 하나를 훈련했으며 이러한 데이터 세트에서 보고된 것 중 단연 최고의 결과를 달성
- 매우 최적화된 GPU 구현을 작성
- 성능을 향상시키고 훈련 시간을 단축
- 과적합을 방지하기 위한 몇 가지 효과적인 기술을 사용했으며
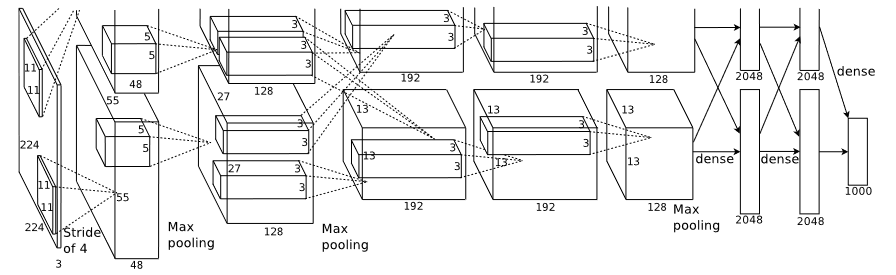
최종 네트워크에는 5개의 convolution , 3개의 Fully- connected layer 포함
3. Dataset
ImageNet은 가변 해상도 이미지로 구성 이미지를 256 × 256의 고정 해상도로 down sampling (직사각형 이미지가 주어지면 먼저 이미지의 길이가 256이 되도록 이미지의 크기를 조정한 다음 결과 이미지에서 중앙 256×256 패치를 잘라냄) 각 픽셀에서 훈련 세트에 대한 평균 활동을 뺀 것을 제외하고는 다른 방법으로 이미지를 사전 처리하지 않고 픽셀의 centered raw RGB 값에 대해 네트워크를 훈련
4. Architecture
학습된 8개의 layers (five convolutional / three fully-connected)
*novel or unusual feature of AlexNet
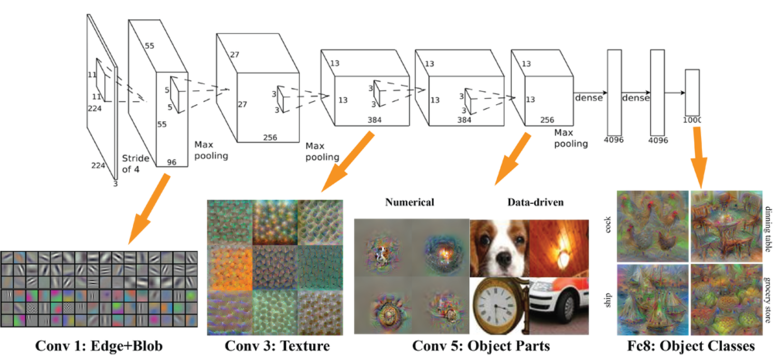
각각의 층들은 하나의 이미지에 대해 독립적으로 특징을 추출하여(Feature Extraction) 가중치를 조정함으로써 필터를 학습
[1] ReLU Nonlinearity
non-saturating nonlinearity f (x) = max(0, x) 방법이 saturating nonlinearity(tanh) 방법보다 빠르다.
DCNN에서 ReLU는 동등한 갯수의 tanh보다 몇배는 빠른 훈련이 가능하다.
figure1.4개의 CNN계층을 가진 신경망에서 ReLU(실선)를 이용한 경우가 tanh(점선) 을 이용하였을 때 보다 매우 빠르게 25%의 에러율에 도달하였다.
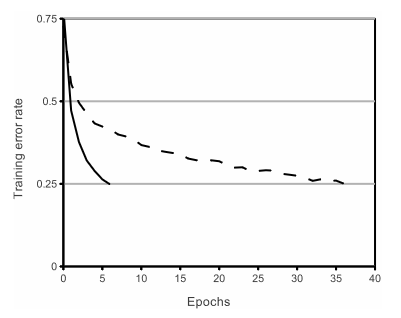
ReLU를 사용할 경우 Epoch이 얼마 돌지 않고 Training Error rate 가 0.25로 떨어지는 것을 알 수 있으며 이는 CIFAR-10 데이터 셋을 통해 증명이 되었다.
이를 통해 non-saturating funtion 을 사용한다면 기존의 saturating 방식보다 더 큰 데이터 셋에도 적용하여 빠르게 학습 할 수 있다.
전통적인 CNN 에서 쓰인 방법을 처음부터 바꾸려고 했던것은 아니다.
예를 들어 jarrete er al.에서 f(x) = |tanh(x)|는 local average pooling으로 대조 정규화된 Caltech-101(data set)에 특히 잘 작동한다.
하지만, ReLU를 사용할 때 데이터 셋에 대한 주요 관심사는 가속화된 훈련속도가 아닌 과적합을 방지하는 측면이다.
빠른 학습은 '대규모 데이터 셋에서 훈련된 대규모 모델'성능에 큰 영향을 미친다.
각 network 에 대한 learning rate 는 가능한 빠르게 학습하기 위해서 독립적으로 선택된다.아무런 정규화 기법도 포함하지 않았다.
여기서 입증된 효과는 네트워크 아키텍쳐에 따라 다르지만 non-saturating neuron 인 ReLU 를 사용하는 것이 saturating neuron보다 지속적으로 몇 배 더 빨리 학습한다.
[2] Training on Mulitiple GPUs.
여러개의 GPU 병렬처리로 학습속도 획기적으로 감소시킴
[3] Local Response Normalization (VGG 에서 성능이 없다고 증명)
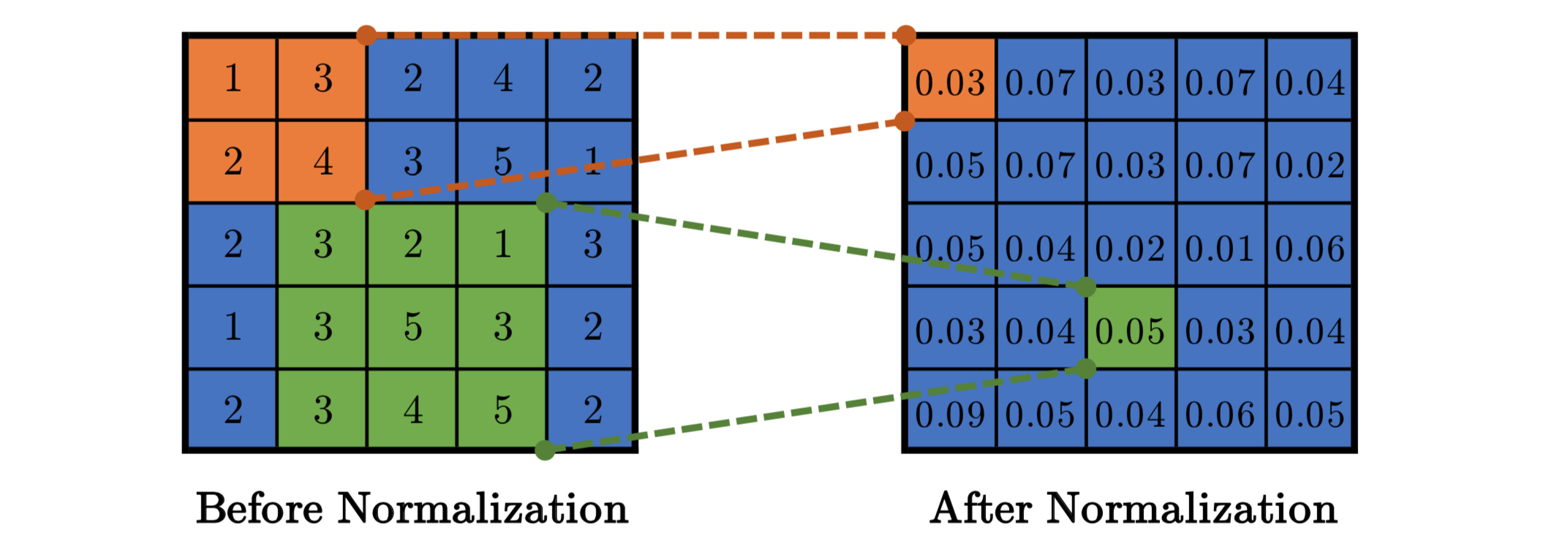
ReLU는 saturate를 방지를 위한 input 을 정규화할 필요가 없는 특성을 가진다.
그러나 , local normalization schema 는 regularization 에 도움이 된다는 것을 발견하였다.
(ReLU 와 같이 지나치게 큰 값이 통과되는 문제의 부작용을 줄이기 위해 사용된 기법)
일반화 성능을 높이기 위한 목적으로 sigmoid 나 tanh 활성화 함수는 입력 데이터의 속성에 따라 편차가 심하면 saturating 되는 현상이 심해서 기울기 소실을 유발할 수 있는 데 ReLU는 non-saturating 함수이기 땜누에 입력 데이터의 정규확 필요없지만
ReLU는 양수값을 받으면 그 값을 그대로 뉴런에 전달하기 때문에 너무 큰 값이 전달되어 주변의 낮은 값이 뉴런에 전달되는 것을 막을 수 있다.
b = regularized output for kernel i at position x, y
a : source output of kernel i applied at position x,y
n : size of the normalization neightborhood (adiacent)
N : total number of kernels
k, n, α, β :hyper parameter
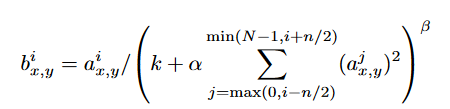{kind=link}
kernel map 의 순서는 임의적이며 훈련 시작전 결정하며 이런 종류의 response Normalization 은 lateral inhibition(측면억제)의 form 을 가진다 .
서로 다른 커널을 사용하여 계산된 뉴런 출력 사이에서 큰 활동에 대한 경쟁을 만든다.
해당 모델에서는 k = 2, n = 5, α = 10-4 및 β = 0.75를 사용했으며 특정 계층에 ReLU를 적용한 후 LRN을 적용했다.
Jarrett et al.의 local contrast Normalization 체계와 약간 유사하지만 mean activity를 빼지 않기 때문에 "brightness normalization"라고 하는 것이 더 정확하다.
respose normalization 은 top-1 ,top-5 에서 1.4% , 1.2% 의 error rate를 감소 시켰으며 CIFAR-10 에서 이 체계의 효과를 검증하였다.
4-layer CNN 은 정규화 없이 13% test error rate 를 달성하였고 정규화로 11% 달성하였다.
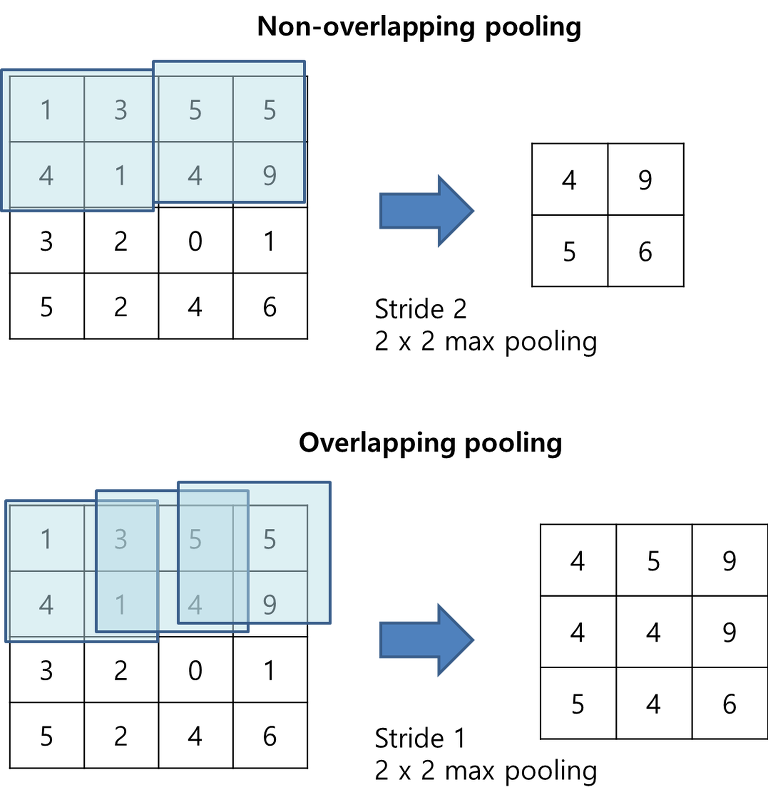
[4] Overlapping Pooling
CNN에서의 Pooling layer 들은 같은 kernel map 에서의 인접된 뉴런들의 결과를 압축하여 출력를 내보낸다. 전통적으로 인접한 뉴런들은 중복되지 않게 pooling을 통과시킨다.
즉, pooling layer 는 s 픽셀단위로 이루어진 pooling units의 그리드로 구성되며 각각은 pooling unit 위치의 중심에서 zxz 크기의 인접 뉴런들을 요약한다.
if s = z -> traditional local pooling (do not overlapping)
if s < z -> overlapping pooling (throughout our network with s=2, z=3)
overlapping pooling 방식은 비중복 방식(s=2,z=2)에 비해top-1, top-5 를 각각 0.4 ,0.3 감소시켰다.
일반적으로 training 과정에서 중복 풀링이 있는 모델은 overfitting 감소시킨다는 것을 관찰할 수 있다.
[5] Overall Architecture
8 layers with weights
- 5-convolution & 3-Fully connected
- last output of FC layer : 1000-way softmax -> 1000 클래스 레이블에 대한 분포를 생성하기 위해서
- 다항 로지스틱 회귀의 목표를 최대화 == 예측 분포 하에서 올바른 레이블의 로그 확률의 training case 의 평균의 최대화
