[논문리뷰] Rich feature hierarchies for accurate object detection and semantic segmentation - 2014
Preview
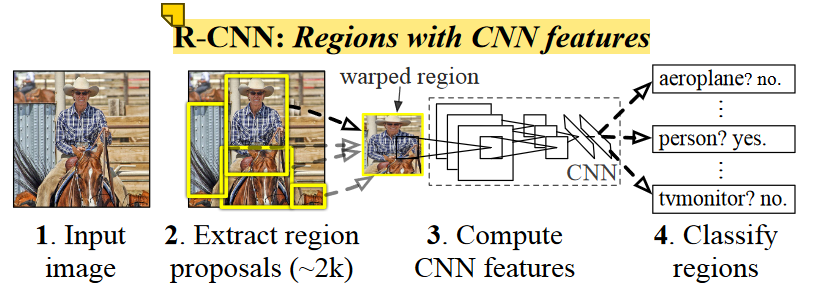
Our system (1) takes an input image, (2) extracts around 2000 bottom-up region proposals, (3) computes features for each proposal using a large convolutional neural network (CNN), and then (4) classifies each region using class-specific linear SVMs.
- Selective Search 를 이용해 2,000개의 Region Proposal 을 생성
- 각 Region Proposal 을 동일한 크기의 이미지로 warping
- warping image를 일일이 CNN 에 넣어서 foward 결과를 계산하여 feature vector 를 뽑아줌
- feature vector 를 독립적으로 훈련된 binary SVM 에 넣어서 class 분류
- Bounding box Regression을 통해 위치를 예측
R-CNN 한계점
-
입력 이미지에 대해 CPU 기반의 selective search -> 시간 소요
-
end-to-end 방식 X = 정확도가 낮아짐
- Architecture 에서 CNN고 SVM+BBox Regression이 분리되어 있음
- 즉 , CNN은 고정되어 feature 만 추출하며 SVM,Regression 결과로 CNN 을 업데이트 할 수 없음
(CNN(feature extract)--- forwarding ---> SVM + Reg )
-
모든 RoI를 2000개를 CNN 연산을 해야해서 연산량이 많아짐
- train / test 과정에서 시간 소요
Bounding box regression
Selective Search 를 이용하면 물체가 존재할 법한 region proposal을 해주는 예측한 위치와 실제 위치를 가져와서 Regression 진행

-> R-CNN 에서 x,y,w,h 4개의 학습 파라미터를 통해 Linear Regression 진행 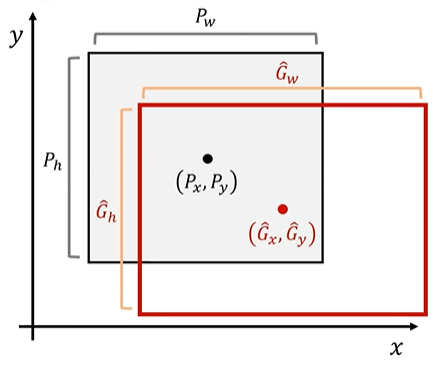 *
*

무니의 성장스토리 😣