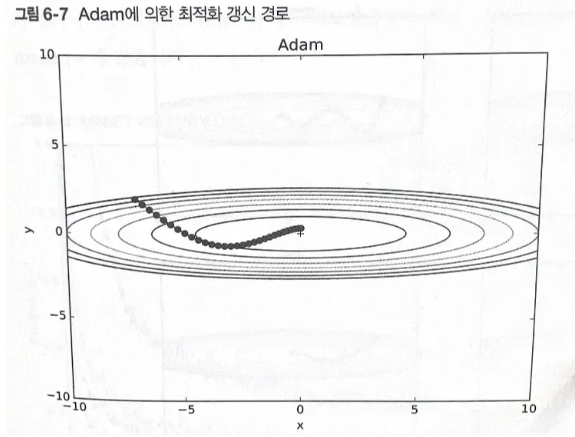
6.1.6 Adam
-
모멘텀과 AdaGrad 기법 융합한 최적화 방식
-
매개변수의 공간을 효율적으로 탐색
-
편향 보정 진행
-
아담 최적화 갱신 경로
- Adam 구현 코드
class Adam:
"""Adam (http://arxiv.org/abs/1412.6980v8)"""
def __init__(self, lr=0.001, beta1=0.9, beta2=0.999):
# 학습률(lr), 1차 모멘텀 계수(beta1), 2차 모멘텀 계수(beta2) 초기화
self.lr = lr
self.beta1 = beta1
self.beta2 = beta2
self.iter = 0 # 업데이트 횟수(에포크 등) 카운트
self.m = None # 1차 모멘텀 변수(평균, 1st moment vector)
self.v = None # 2차 모멘텀 변수(분산, 2nd moment vector)
def update(self, params, grads):
# params: 파라미터(딕셔너리), grads: 파라미터에 대한 그래디언트(동일한 구조의 딕셔너리)
# 첫 업데이트 시 m, v 초기화 (zero tensor와 같은 크기로)
if self.m is None:
self.m, self.v = {}, {}
for key, val in params.items():
self.m[key] = np.zeros_like(val) # key별로 0 배열 할당
self.v[key] = np.zeros_like(val)
self.iter += 1 # 업데이트 횟수 증가
# bias correction을 곱한 현재 스텝별 학습률(lr_t) 계산
# (초기 t에서는 m, v가 0에 가까우므로 보정 필요)
lr_t = self.lr * np.sqrt(1.0 - self.beta2**self.iter) / (1.0 - self.beta1**self.iter)
# 각 파라미터별로 업데이트 진행
for key in params.keys():
# 모멘텀 갱신(이동평균)
#self.m[key] = self.beta1 * self.m[key] + (1 - self.beta1) * grads[key]
#self.v[key] = self.beta2 * self.v[key] + (1 - self.beta2) * (grads[key]**2)
# 위는 일반적인 이동평균 공식,
# 아래는 효율성 위해 바로 배열값 자체 갱신(동치임)
self.m[key] += (1 - self.beta1) * (grads[key] - self.m[key])
self.v[key] += (1 - self.beta2) * (grads[key]**2 - self.v[key])
# 편향 보정된 모멘텀과 분산 사용해서 파라미터 업데이트
params[key] -= lr_t * self.m[key] / (np.sqrt(self.v[key]) + 1e-7)
# 1e-7은 0으로 나누는 것을 방지하는 작은 값(Epsilon)
# 아래는 alternate 방식(주석 처리됨)
#unbias_m += (1 - self.beta1) * (grads[key] - self.m[key])
#unbisa_b += (1 - self.beta2) * (grads[key]*grads[key] - self.v[key])
#params[key] += self.lr * unbias_m / (np.sqrt(unbisa_b) + 1e-7)
# 실제론 위에서 이미 편향 보정된 lr_t를 사용하고 있으므로, 이 부분은 필요 없음
- 경사하강법 기본 원리 다시 상기해봅시다: 파라미터 = 파라미터 - (학습률 × 그래디언트)
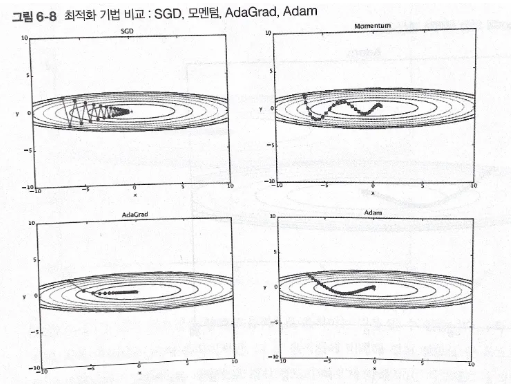
6.1.7 어느 갱신 방법을 이용할 것인가?
-
크게 네 가지 매개변수 갱신 방법 존재.
-
사용 기법에 따라 갱신 경로가 다름.
-
각자의 장단이 있어서 잘 푸는 문제와 서툰 문제가 있음.
-
그 외의 기울기 갱신 방식을 다시 복습해보자.
-
SGD (Stochastic Gradient Descent)
- 기본 개념: 손실 함수의 그래디언트를 전체 데이터가 아닌 무작위로 선택한 한 개 또는 소규모 배치에 대해 계산하여 파라미터를 업데이트하는 방법입니다.
- 장점: 계산량을 줄여 효율적인 학습 가능, 큰 데이터셋에 적합.
- 원리: 파라미터를 손실이 줄어드는 방향으로 조금씩 이동시키는 반복적인 과정.
- 특징: 노이즈가 있는 업데이트로 인해 지역 최솟값에서 벗어날 수 있지만, 진동하거나 수렴 속도가 느릴 수 있음.
-
Momentum (모멘텀)
- 기본 개념: 물리학에서 관성의 개념을 빌려, 이전 업데이트 방향을 일정 부분 유지하며 현재 그래디언트를 반영하여 파라미터를 업데이트하는 방법.
- 장점: 진동을 줄이고 최적점으로 더 빠르게 수렴할 수 있음.
- 원리: 현재 그래디언트뿐 아니라 이전 업데이트(속도)를 일정 비율만큼 더해줌으로써 관성을 부여.
- 특징: 학습 경로가 평탄한 영역에서는 가속을 얻고, 급격히 방향이 바뀌는 지점에서는 업데이트 진동을 감소시킴.
-
AdaGrad (Adaptive Gradient Algorithm)
- 기본 개념: 각 파라미터마다 그동안 누적된 그래디언트 크기에 따라 학습률을 조절하는 적응적 학습률 방법.
- 장점: 희소한 데이터나 드물게 업데이트되는 파라미터에 대해 더 큰 학습률을 부여, 자주 업데이트되는 파라미터는 학습률을 감소시켜 안정화.
- 원리: 각 파라미터에 대해 제곱된 그래디언트의 합을 누적해 학습률을 점점 줄임.
- 특징: 학습 초반에는 빠르게 수렴하지만 시간이 지날수록 학습률이 너무 작아져서 학습이 멈추는 현상이 있을 수 있음.
{kind=link}
6.2.1 초깃값을 0으로 하면?
- 가중치 감소: 가중치 매게변수의 값이 작아지도록 학습하는 방법
- 가중치 감소 정공법: 초깃값도 최대한 작은 값에서 시작하는 것.
- 만약 가중치 초깃값을 0으로 설정하면? 학습이 올바르게 이루어지지 않음.
-
이유: 역전파에서 모든 가중치 값이 똑같이 갱신되기 때문.
“예를 들어 2층 신경망에서 첫 번째와 두 번째 층의 가중치가 0이라고 가정하겠습니다. 그럼 순전파 때는 입력층의 가중치가 0이기 때문에 두 번째 층의 뉴런에 모두 같은 값이 전달됩니다. 두 번째 층의 모든 뉴런에 같은 값이 입력된다는 것은 역전파 때 두 번째 층의 가중치가 모두 똑같이 갱신된다는 말이 됩니다. 그래서 가중치들은 같은 초깃값에서 시작하고 갱신을 거쳐도 여전히 같은 값을 유지하는 것이죠. 이는 가중치를 여러 개 갖는 의미를 사라지게 합니다.”
-
6.2.2 은닉층의 활성화값 분포(기울기 소실) (1)
- 활성화 값 분포를 관찰하면 중요한 정보를 얻을 수 있음
- 코드: 이 분포된 정도를 바꿔가며 활성화값들의 분포가 어떻게 변화하는지 관찰하는 것이 이 실험의 목적.
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.random.randn(1000, 100) # 1000개의 데이터
node_num = 100 # 각 은닉층의 노드(뉴런) 수
hidden_layer_size = 5 # 은닉층이 5개
activations = {} # 이곳에 활성화 결과(활성화값)를 저장
for i in range(hidden_layer_size):
if i != 0:
x = activations[i-1]
w = np.random.randn(node_num, node_num) * 1
a = np.dot(x, w)
z = sigmoid(a)
activations[i] = z- 코드: activations에 저장된 각 층의 활성화값 데이터를 히스토그램으로 그려보기
# 히스토그램 그리기
for i, a in activations.items():
plt.subplot(1, len(activations), i+1)
plt.title(str(i+1) + "-layer")
plt.hist(a.flatten(), 30, range=(0,1))
plt.show()-
활성화 함수별 활성화값 분포
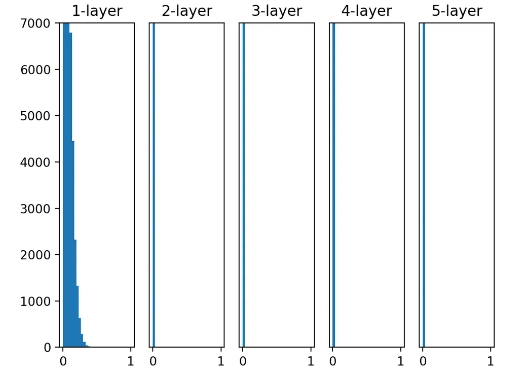
- 지금은 가중치의 표준 편차를 1로 설정한 상황
w = random.randn(node_num, node_num) * 1- 시그모이드의 단점
-
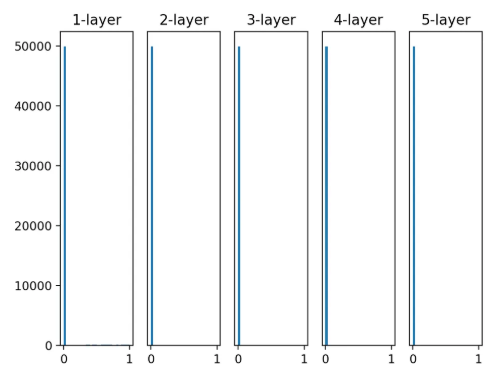
활성화 함수의 일반적인 특성: 활성화값들이 0과 1에 치우쳐 분포되어 있음.
-
시그모이드 함수는 그 출력이 0이나 1에 가까워지면 그 미분은 0에 다가감(함수 그래프를 보면 알 수 있음).
-
데이터가 0과 1에 치우쳐 분포하게 되면 역전파 기울기 값이 점점 작아지다가 사라짐.
-
이것이 기울기 소실. 층이 깊은 경우 더 큰 문제가 될 수 있음.
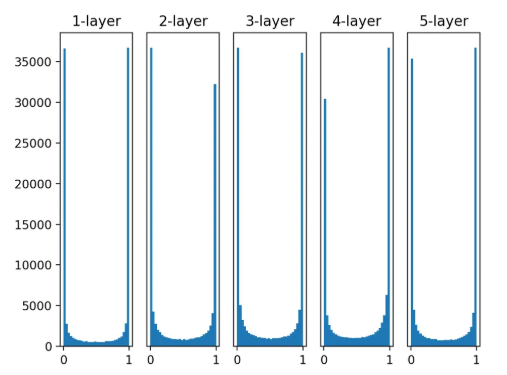
-
- ReLU
- tanh
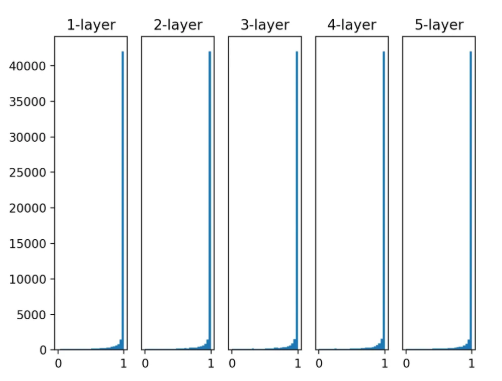
-
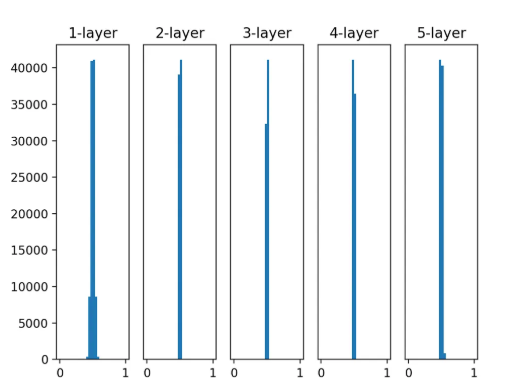
이제 표준편차를 0.01로 한 경우 각 활성화 함수의 정규분포를 보기(표준편차를 줄였기 때문에 가운데로 몰려 있을 수 밖에 없음)
- 시그모이드
-
출력이 0.5에 치우쳐 있음. 이러면 기울기는 살아남지만, 출력층의 다양성이 매우 떨어짐.
-
- ReLU
- tanh
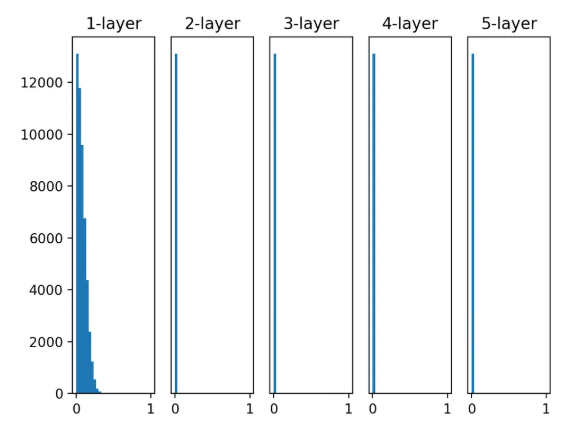
- 시그모이드
-
시그모이드 활성화함수가 특히 기울기 소실 문제를 가장 직관적으로 보여준다.
6.2.2 은닉층의 활성화값 분포(해결책) (2)
-
Xavier 초깃값: 일반적인 딥러닝 프레임워크들이 표준적으로 이용하고 있음.
-
이 논문은 각 층의 활성화값들을 광범위하게 분포시킬 목적으로 가중치의 적절한 분포를 찾고자 함.
-
앞 계층의 노드가 n개라면 표준편차가 인 분포를 사용하면 됨.
-
앞 층의 노드가 많을수록 대상 노드의 초깃값으로 설정하는 가중치가 좁게 퍼짐.
-
그림: Xavier 초깃값(n은 앞 층의 노드 수)
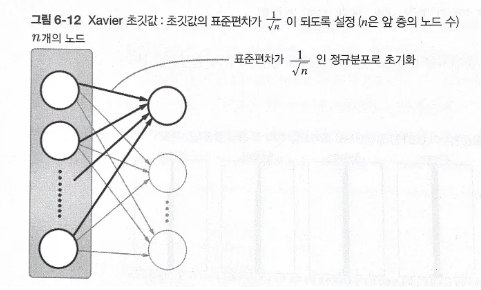
-
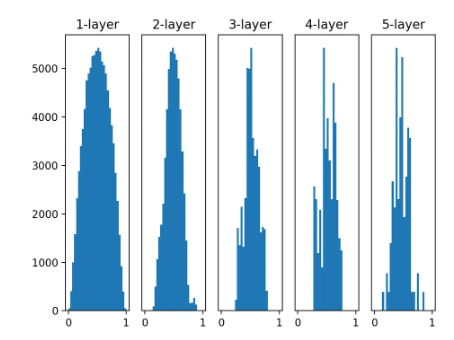
Xavier분포를 활용한 경우의 활성화 분포
-
시그모이드
- 층이 깊어지면서 다소 일그러지지만 분포가 더 다양하고 시그모이드의 기울기도 살릴 수 있음.
- 표준 편차가 1인 경우
- Xavier 분포 + 시그모이드를 사용한 경우
- Xavier + ReLU를 사용한 경우(이 경우는 특별히 보도록 함)
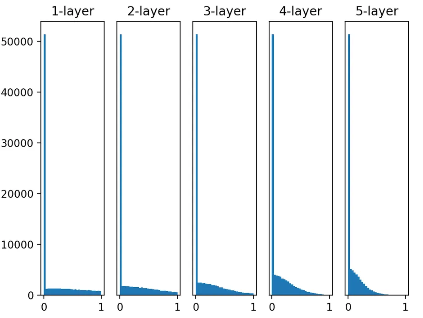
- Xavier + tanh를 사용한 경우
-
-
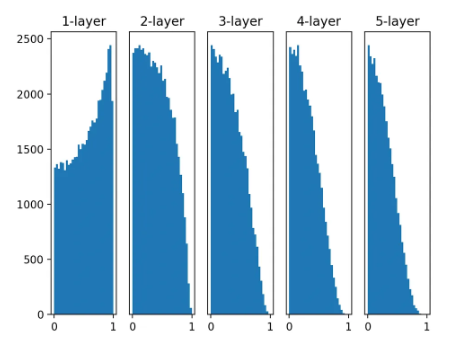
tanh와 시그모이드의 차이: 둘다 모양은 같은데 시그모이드는 (0, 0.5)에서 대칭, tanh는 (0, 0)에서 대칭. tanh로 xavier 분포를 사용한 그래프를 보면 좀 더 매끄러운 분포를 볼 수 있다.
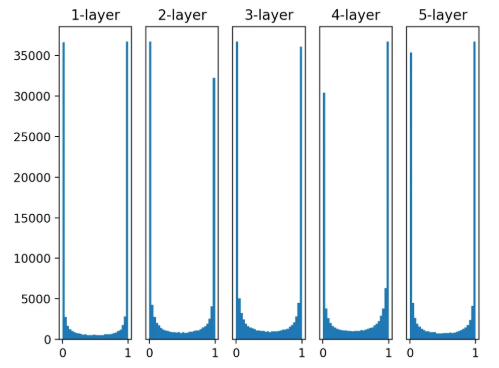
6.2.3 ReLU를 사용할 때의 가중치 초깃값
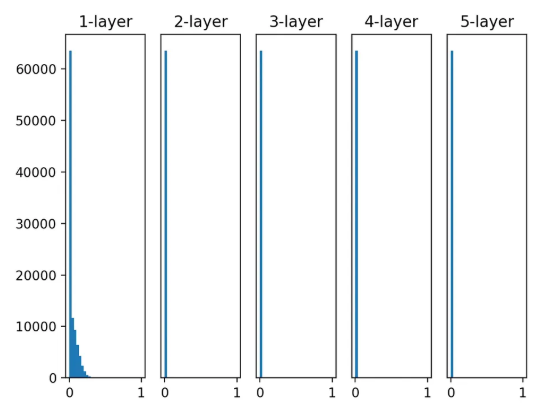
- 앞서 본 ReLU 활성화 + Xavier 분포는 매우 이상했음.
-
ReLU 특성 상 활성화 분포가 0에 치우칠 수밖에 없음.
-
특화된 초깃값을 사용해야 함.
-
He 초깃값: 노드 n에 대해 표준편차가 인 정규분포를 사용함.
-
ReLU는 음의 영역이 0이라서 더 넓게 분포시키기 위해 Xavier 분포에 비해 2배의 계수가 필요하다고 직간접적 해석 가능.
-
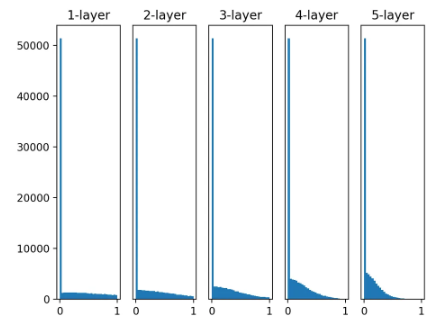
활성화 함수로 ReLU를 사용한 경우의 가중치 초깃값에 따른 활성화값 분포 변화
-
ReLU + 0.01
-
ReLU + Xavier:
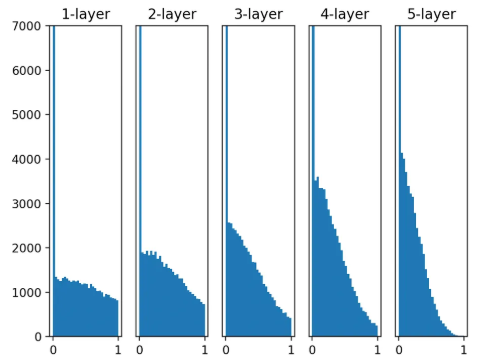
-
ReLU + He
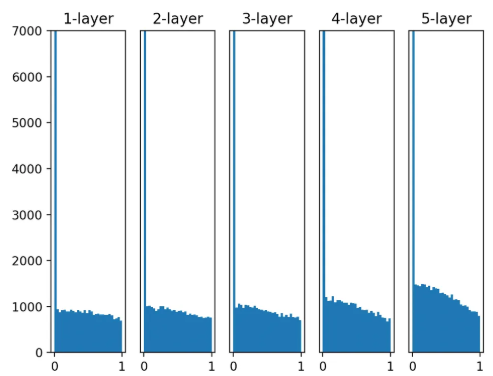
- 확실히 Xavier보다 He 초깃값이 더 강하게 활성화 분포를 흩어주는 모습을 볼 수 있다. 층이 깊어질 수록 그 효과가 확실히 드러난다.
6.2.4 MNIST 데이터셋으로 본 가중치 초깃값 비교
-
실제 데이터로 가중치 초깃값 비교
-
표준편차 0.01, Xavier, He 초깃값 각각의 학습 효과 비교.
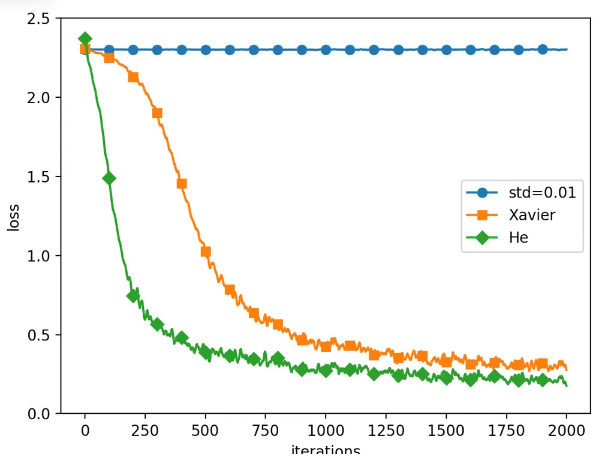
- 핵심은 가중치 초깃값 분포 설정이 정말정말 중요하다는 것. 각 활성화 함수에 따라서 결과가 매우 달라질 수 있음.
- 수어지교 프로젝트에서 작성한 스크립트의 초기화 설정이 궁금해서 찾아본 결과 TensorFlow/Keras 프레임워크의 기본 초기화(default initializer)가 사용됨. 기본 초기화기는 Glorot Uniform 혹은 Xavier라고 함.
- Conv1D 및 Dense 레이어는 기본적으로 Glorot Uniform(또는 Xavier Uniform) 초기화를 사용합니다.
- LSTM 레이어 역시 기본적으로 Glorot Uniform 초기화를 기본으로 하며, 편향(bias)은 0으로 초기화됩니다.
- 또, 활성화 함수는 아래와 같이 사용됐었음
- CNN: relu
- LSTM: tanh(셀 상태용), 게이트용(sigmoid)
- Dense: relu
- 그렇다면, 초깃값 설정을 그리 효과적으로 하지는 못했군. 추후 프로젝트에서는 활성화 함수와 초기화기의 관계를 고려해서 신경망을 설계해야겠다.
트러블슈팅: 부모 디렉토리 임포트 실패
Phase 1
환경: python venv(3.10), macOS, m1, macbook air
로그:
Exception has occurred: ModuleNotFoundError
No module named 'dataset.mnist'
File "/Users/johyeonho/WegraLee-deep-learning-from-scratch/ch06/weight_init_compare.py", line 9, in <module>
from dataset.mnist import load_mnist
ModuleNotFoundError: No module named 'dataset.mnist'최근 변경 사항
sys.path.append(os.pardir) # 부모 디렉터리의 파일을 가져올 수 있도록 설정
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnistPhase 2.
확인
- 파이썬 모듈 시스템을 이해 못해서 그런가? from dataset.mnist가 있을 때, from의 대상으로 모든 path의 경로를 탐색하는가?
from dataset.mnist에서dataset이 가질 수 있는 경로(디렉토리)는sys.path내의 여러 경로를 순서대로 탐색해서 찾습니다.- 첫 번째로
dataset폴더를 찾으면 그 경로를 기준으로 하위mnist.py파일을 찾고 임포트합니다. - 만약 여러 곳에 동일한 이름의 패키지가 있다면
sys.path에 등록된 순서에 따라 처음 발견된 경로가 우선됩니다.
- 그렇다면 부모 디렉토리를 탐색하다가 dataset을 만나야 정상이다. 그게 안 된다는 말은 현재 디렉토리가 잘못 설정돼 있다는 것일 수도 있겠다.
print(os.getcwd())로 현재 디렉토리를 확인해보자.
cwd: /Users/johyeonho/WegraLee-deep-learning-from-scratch
all paths
/Users/johyeonho/WegraLee-deep-learning-from-scratch/ch06
/Library/Frameworks/Python.framework/Versions/3.10/lib/python310.zip
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/lib-dynload
/Users/johyeonho/WegraLee-deep-learning-from-scratch/.venv/lib/python3.10/site-packagesdataset 패키지는 분명 현재 디렉토리 하위에 존재하고 있음. 정작, paths에는 이 경로가 포함돼 있지 않음. 왜 cwd가 ch6이 아닌 상위로 설정된 걸까? 그건 지금 중요한 문제가 아니고, 일단 제대로 /Users/johyeonho/WegraLee-deep-learning-from-scratch이 경로가 sys.path에 포함이 됐음에도 /Users/johyeonho/WegraLee-deep-learning-from-scratch/dataset 패키지를 참조하지 못하고 있음.
시도
- 직감적으로 가상환경 문제일 거 같아서 작업중인 디렉토리에 바로 가상환경 생성 후 그것을 활성화 시킨 상태에서 스크립트를 실행하니까 잘 됨.
결과분석
- 해결하긴 함. 루트 디렉토리 가상환경으로 실행하면 부모의 부모에서 패키지를 찾으려 한 것이 화근인듯.
- 그런데 path에 분명 패키지의 부모를 명시를 해 줬음에도 이런 결과가 난 이유가 뭐지?
- TODO: 파이썬 패키지와 가상환경의 관계 이해하기
6.3.1 배치 정규화
-
배치 정규화의 장점
- 학습을 빨리 진행할 수 있음
- 초깃값에 크게 의존하지 않음(응?)
- 오버피팅을 억제한다.
-
방법: 배치 정규화 계층을 신경망에 삽입
-
말 그대로 미니 배치를 단위로 정규화.
-
구체적으로는, 데이터 분포가 평균이 0, 분산이 1이 되도록 정규화.
-
미니배치라는 m개의 입력 데이터의 집합에 대해 평균 와 분산 을 구하고, 입력 데이터를 평균이 0, 분산이 1이 되도록 정규화
-
이 처리를 활성화 함수의 앞 혹은 뒤에 삽입하여 데이터 분포가 덜 치우치게 함.
-
배치 정규화 계층마다 이 정규화된 데이터에 고유한 확대와 이동 변환을 수행.
-
이 알고리즘이 신경망에서 순전파 때 적용.
-
그림: 배치 정규화를 사용한 신경망의 예
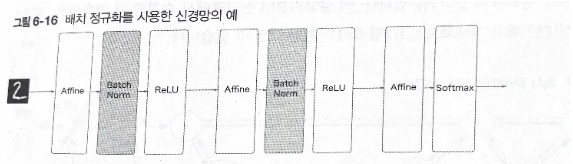
- 배치 정규화 효과
- 그래프 위에 표시된 값은 가중치 초깃값의 표준편차(얘네는 어차피 랜덤이다. 그러니까 랜덤한 요소에서 하나 건들 수 있는 건 표준편차다. 그래서 초깃값을 정의할 때 표준편차가 중요)
- 각 초깃값 표준편차마다 배치 정규화 혹은 일반 방식의 학습 속도가 다른 것을 볼 수 있다.
- 표준편차가 낮아질 수록 일반 정규화는 학습이 안 되는 것도 볼 수 있음. 그런데 표준 편차마다 학습 속도가 좀 다르다.
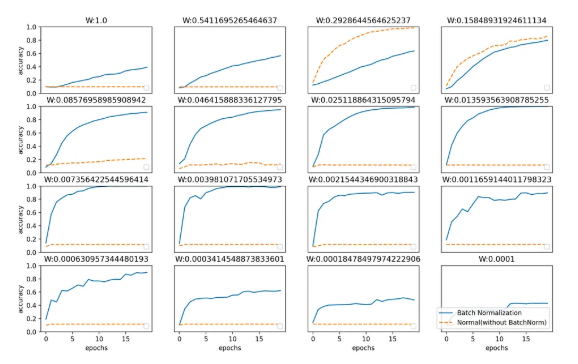
- 배치 정규화가 별도 레이어가 필요했는줄은 몰랐다. 배치간의 분포를 정규화 시키기 위한 방식으로 배치 정규화 레이어가 필요한 것으로 이해하면 되겠다. 기본적으로 affine 계층과 활성화 계층 사이에 있는 것 같다. 출력 레이어에서는 굳이 필요 없겠네.
6.4.1 오버피팅 / 6.4.2 가중치 감소
-
오버 피팅은 주로 다음의 두 경우에 발생
- 매개변수가 많고 표현력이 높은 모델
- 훈련 데이터가 적음
-
오버피팅 억제용: 가중치 감소. 학습 과정에서 큰 가중치에 대해서는 그에 상응하는 큰 패널티를 부과하여 오버피팅을 억제하는 방법. (원래 오버피팅은 가중치 매개변수의 값이 커서 발생하는 경우가 많음)
-
“가중치의 제곱 노름을 손실 함수에 더합니다. 그러면 가중치가 커지는 것을 억제할 수 있죠. 가중치를 W라 하면 L2 노름에 따른 가중치 감소는 이 되고, 이 을 손실 함수에 더합니다. 여기에서 람다는 정규화의 세기를 조절하는 하이퍼파라메터입니다. (아하! L2노름의 학습률과 같은 역할을 하는구나) 또 의 앞쪽 1/2는 의 미분결과인 를 조정하는 역할의 상수입니다.”
-
“가중치 감소는 모든 가중치 각각의 손실 함수에 을 더합니다. 따라서 가중치의 기울기를 구하는 그동안의 오차역전파법에 따른 결과에 정규화 항을 미분한 를 더합니다.”
-
중요! “L2 노름은 각 원소의 제곱들을 더한 것에 해당합니다. 가중치 이 있다면 L2 노름에서는 으로 계산할 수 있습니다. L2 노름 외에 L1 노름과 L inf 노름도 있습니다.” 즉, 애초에 각 원소들의 제곱 합을 루트 씌운 것이 L2 노름임.
-
오버피팅
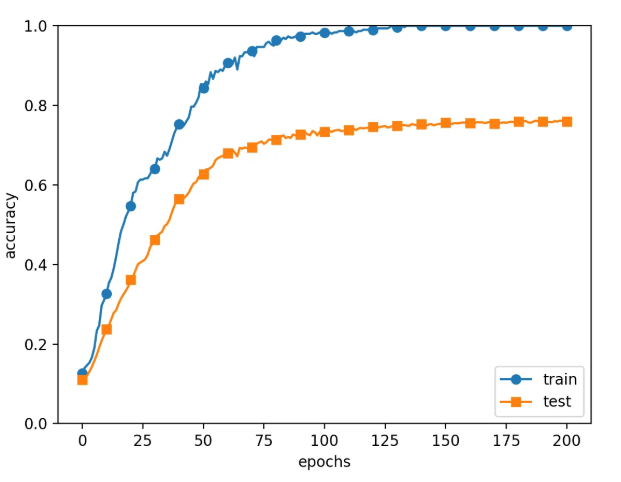
- L2 정규화의 위대한 힘
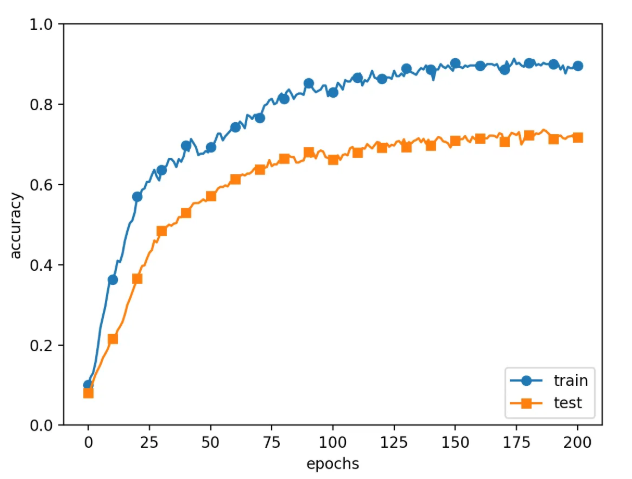
- L2 정규화가 확실히 제일 효과적인 방법인 거 같다.
6.4.3 드롭아웃
-
가중치 감소(L2 정규화)는 간단하게 구현할 수 있고, 어느 정도 지나친 학습을 억제할 수 있음. 하지만 복잡한 네트워크에서 한계.(가중치 감소를 일괄로 적용해서 그런듯)
-
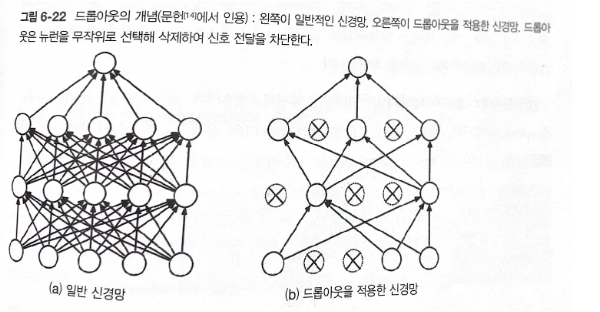
드롭아웃: 임의로 뉴런을 삭제하면서 학습.
-
왜 앙상블과 비슷한가?: 신경망의 맥락에서 이야기하면, 같은 구조의 네트워크 5개 준비하여 따로따로 학습시키고, 시험 때는 그 5개의 출력을 평균 내어 답하는 것임. 드랍아웃이 학습 때 뉴런을 무작위로 삭제하는 행위를 매번 다른 모델을 학습시키는 것으로 해석할 수 있음.
-
그림: 드롭아웃의 개념
class Dropout:
def __init__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1.0 - self.dropout_ratio)
def backward(self, dout):
return dout * self.mask- dropout 사용
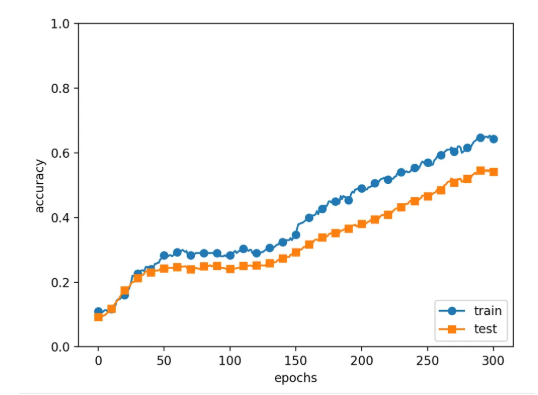
- dropout 미사용
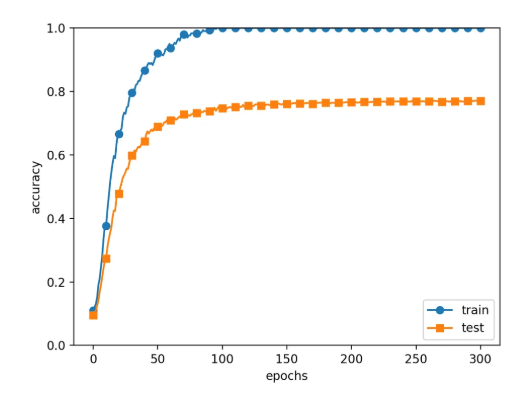
6.5.1 검증 데이터
- 하이퍼파라미터를 다양한 값으로 설정하고 검증할 때, 하이퍼파라미터의 성능을 평가할 때는 시험 데이터를 사용해서는 안 됨.
- 같은 성능 평가에서 하이퍼파라미터가 대상일 때는 시험 데이터를 사용해서는 안 되는 이유? 시험 데이터를 사용하여 하이퍼파라미터를 조정하면 하이퍼파라미터 값이 시험 데이터에 오버피팅되기 때문.
- 그래서 하이퍼파라미터를 조정할 때 하이퍼파라미터 전용 확인 데이터 필요. 이를 검증 데이터라고 함.
- 훈련 데이터: 매개변수 학습
- 검증 데이터: 하이퍼파라미터 성능 평가
- 시험 데이터: 신경망의 범용 성능 평가
6.5.2 하이퍼파라미터 최적화
-
하이퍼파라미터 최적화 핵심은 하이퍼파라미터의 ‘최적 값’이 존재하는 범위를 조금씩 줄여나가는 것.
-
하이퍼파라미터 최적화에서는 그리드 서지 같은 규칙적인 탐색보다는 무작위 샘플링 탐색이 좋은 결과를 낸다고 함
-
하이퍼파라미터는 대략적으로 지정하는 것이 효과적임. 로그 스케일로 지정하기
-
로그 스케일: 그냥 스케일이 큰 단위 개념. 0.001에서 ~ 1000사이로 10의 거듭 제곱으로 범위를 넓게 넓게 지정하는 것.
-
딥러닝 학습에는 오랜 시간이 걸리므로 나쁠 듯한 값은 일찍 포기하는게 좋음.
-
하이퍼파라미터 최적화 스텝
- 하이퍼파라미터 값의 범위를 설정(로그스케일)
- 설정된 범위에서 하이퍼파라미터의 값을 무작위로 추출
- 1단계에서 샘플링한 하이퍼파라미터 값을 사용하여 학습하고, 검증 데이터로 정확도를 평가
- 1단계와 2단계를 특정 횟수 반복하며, 그 정확도의 결과를 보고 하이퍼파라미터의 범위를 좁히기.
-
책에도 나와 있지만 그냥 과학이라기에는 직관이다. 더 세련된 최적화는 베이즈 최적화라는게 있음. (bayesian optimization) 하지만 안 쓰는데는 또 이유가 있긴 하다.(직관으로 해도 얼추 실무가 되니까)
6.5.3 하이퍼파라미터 최적화 구현하기
-
일단 예제의 경우는 학습률과 가중치 감소율 범위를 랜덤으로 잡아서 테스트하는 것.
-
하이퍼파라미터 최적화 구현
# 탐색한 하이퍼파라미터의 범위 지정===============
weight_decay = 10 ** np.random.uniform(-8, -4) # 10의 제곱수로 logarithmic scale로 조절하는 모습을 볼 수 있음
lr = 10 ** np.random.uniform(-6, -2)- 20가지 랜덤 경우의 수를 보여줌.(검증 데이터의 학습 추이를 정확도가 높은 순으로 나열)
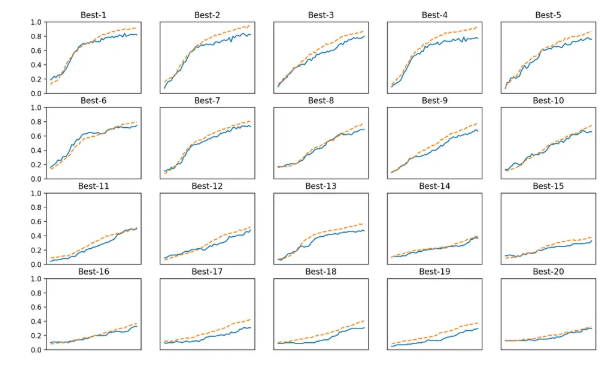
- 위의 실험에 대한 각 하이퍼파라미터 값(learning rate와 weight decay를 보면 됨)
=========== Hyper-Parameter Optimization Result =========== Best-1(val acc:0.82) | lr:0.0095672414080316, weight decay:6.635070742416745e-06 Best-2(val acc:0.82) | lr:0.009477221325778502, weight decay:1.1760685227016651e-07 Best-3(val acc:0.8) | lr:0.006739037463419945, weight decay:1.7010661695265425e-06 Best-4(val acc:0.77) | lr:0.00934915370701577, weight decay:1.7997196297327098e-06 Best-5(val acc:0.76) | lr:0.009868985075769459, weight decay:1.635486821915554e-06 Best-6(val acc:0.75) | lr:0.005475284194275679, weight decay:4.937344966443514e-05 Best-7(val acc:0.73) | lr:0.006905775299401849, weight decay:3.6399087334523756e-05 Best-8(val acc:0.69) | lr:0.00649821775816646, weight decay:5.47158945826805e-07 Best-9(val acc:0.67) | lr:0.005076157371628773, weight decay:1.734058463590518e-05 Best-10(val acc:0.66) | lr:0.004422836414123521, weight decay:7.264194832560532e-08 Best-11(val acc:0.5) | lr:0.0029130171987521453, weight decay:2.475549407588865e-05 Best-12(val acc:0.48) | lr:0.002579622537811143, weight decay:2.9655297816333528e-05 Best-13(val acc:0.47) | lr:0.0032637996247260035, weight decay:2.361395686396247e-08 Best-14(val acc:0.37) | lr:0.0021051083047830257, weight decay:6.928148559885636e-05 Best-15(val acc:0.33) | lr:0.0014275293878210434, weight decay:5.3801532386646794e-05 Best-16(val acc:0.33) | lr:0.002500298574255524, weight decay:6.352249911767835e-05 Best-17(val acc:0.31) | lr:0.003043759722856916, weight decay:4.893367583617906e-07 Best-18(val acc:0.31) | lr:0.0011888516788333278, weight decay:4.345552677170607e-06 Best-19(val acc:0.3) | lr:0.0025389223212827433, weight decay:1.5845294906776385e-06 Best-20(val acc:0.3) | lr:0.0018240949466978775, weight decay:3.5713163246505394e-08
