시스템 콜이란?
시스템 콜은 OS의 API라고 이해하면 됩니다. 사용자가 어떤 서비스에 요청을 날릴 때 API 범위 내에서 서버에 요청을 하듯이, 운영체제에서도 사용자 프로그램이 커널의 모든 기능을 사용할 수 있는게 아니라, 커널이 제공하는 API 범위 내에서 커널에 요청을 보낼 수 있습니다. 만약 사용자 프로그램이 커널의 모든 기능을 사용할 수 있다면 아주 위험하겠지만, 반대로 커널의 어떤 기능도 사용할 수 없다면 할 수 있는게 없겠죠?
간략한 예를 들어 fork에 대해서 생각해봅시다. 서브 프로세스를 생성하기 위해서는 커널에서 아래와 같은 작업을 해줘야 합니다.
- 프로세스 생성
- 파일 디스크립터 테이블 복사
- 페이지 테이블 복사
- 프로세스 ID 할당
- 프로세스 스케줄링 준비
이 작업들을 유저 프로그램이 마음대로 하게 둬서도, 그렇다고 사용 할 수 없게 둬서도 안 되겠죠. 따라서 운영체제는 시스템 콜이라는 API를 사용자 프로그램에 제공하여 핵심 기능을 안전하게 사용할 수 있도록 합니다.
시스템 콜의 작동 원리
시스템 콜을 구현하기 위해서는 systemcall_handler를 이해해야 합니다. 아래 글을 읽어 봅시다.
- 시스템 콜 핸들러는 운영체제의 핵심 인터페이스로, 사용자 프로그램이 커널 기능에 접근하는 유일한 안전한 방법이다.
- 시스템 콜 넘버는 사용자 프로그램이 요청하는 특정 시스템 기능을 식별하는데 사용된다.
- 시스템 콜 인수는 사용자 공간에서 커널 공간으로 전달되는 데이터로, 이 인수들의 유효성 검사가 필수다.
1번은 위에서 살펴봤던 시스템 콜의 기본 개념이고, 2, 3번은 시스템 콜을 사용하기 위해 매개변수를 전달하는 등의 개념으로 이해하면 됩니다. 사용자 프로그램이 커널의 동작을 요청할 때, '무엇'을 요청하는지 system call number가 가리키고, 인자 값은 시스템 콜 인수로 넘어갑니다.
시스템 콜 넘버와 시스템 콜 인수
이 두가지, 즉 시스템 콜 넘버와 인수를 제대로 이해하기 위해서는 시스템 콜 레지스터 설정 프로토콜을 이해해야 합니다. 아래 글을 읽어봅시다.
시스템 콜은 전통적인 레지스터 설정 방법과 달리, %rax 레지스터에 시스템 콜 넘버가 들어가야 하며, 네 번째 인수로 %rcx 대신 %r10을 쓴다.
여기서 말하는 전통적인 레지스터 설정 방법은 뭘까요? 일반적인 함수 호출 상황을 생각해 봅시다. %rax에는 보통 리턴 값이 들어가지만, 시스템 콜에서는 시스템 콜 넘버가 저장됩니다. 또, 인자값이 설정되는 레지스터는 %rdi, %rsi, %rdx, %rcx, %r8, %r9 순서지만(6개보다 만을 경우 런 타임 스택에 복사), 시스템 콜 인자값 전달 시에는 %rcx 대신 r10을 씁니다. 이 레지스터 값들은 유저 프로그램이 생성한 인터럽트 프레임 구조체에 저정됩니다. 시스템 콜 핸들러에서의 인터럽트 프레임 처리를 이해하기 위해서는 아래 글을 이해해야 하죠.
caller's register는 syscall_handler로 전달된 인터럽트 프레임 구조체를 통해 조작할 수 있다.이때 규약을 지켜 인라인 어셈블리어로 값을 잘 설정하면 된다.
이 말을 더 자세히 분해해 봅시다.
대체 이 인터럽트 프레임이 무엇일까요? 이것은 일반적으로 모든 범용 레지스터와 프로그램 카운터, 플래그 레지스터 등의 상태를 포함하는 구조체입니다. 운영체제에서는 시스템 콜이 발생하면 인터럽트 매커니즘을 통해 커널 모드로 전환되며, 이 과정에서 사용자 프로그램의 레지스터 상태가 인터럽트 프레임 구조체에 저장됩니다.
이제 시스템 콜을 실제로 구현해보도록 합시다
시스템 콜 구현하기
1. exit
exit은 프로세스를 exit code와 함께 종료시키는 시스템 콜입니다.
흐름도를 간략히 보도록 하지요.
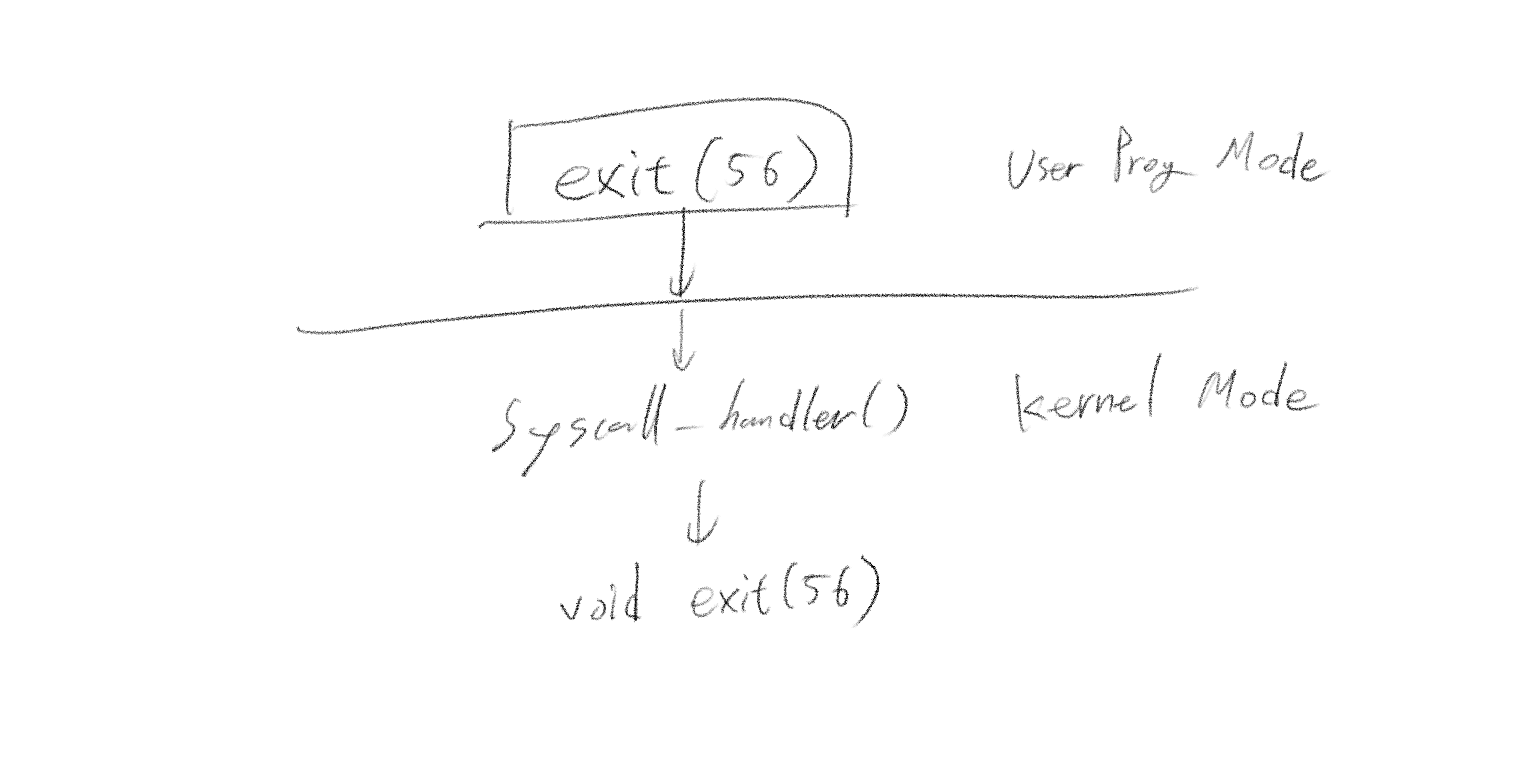
사용자 프로그램이 exit(56)을 호출하면 일어나는 일
만일 어떤 사용자 프로그램이 아래와 같이 exit(56)을 호출했다고 가정해 봅시다.

이때 컴퓨터에서는 어떤 일이 일어날까요? exit(56)을 사용자 프로그램에서 호출하면, 인터럽트 프레임의 %rdi에 56이 저장되고 %rax에는 enum 값인 SYS_EXIT이 저장됩니다. 그 후로는 간단합니다. 인수를 넘겨받은 인터럽트 프레임 구조체 그대로 위 레지스터 값을 복사 후 exit(56)을 실행한다. 그 중간 과정은 분기와 인자값 획득, 전달로 이루어지는데, 시스템 콜 핸들러가 이 작업을 모두 처리해 줍니다.
커널에서 exit 처리를 구현할 때 주의해야 할 점은 종료 코드를 넘겨야 한다는 점입니다. 그냥 인자값을 넘기면 된다고 생각할 수 있지만, 사실 좀 복잡한 동기화 문제가 얽혀 있는데요.
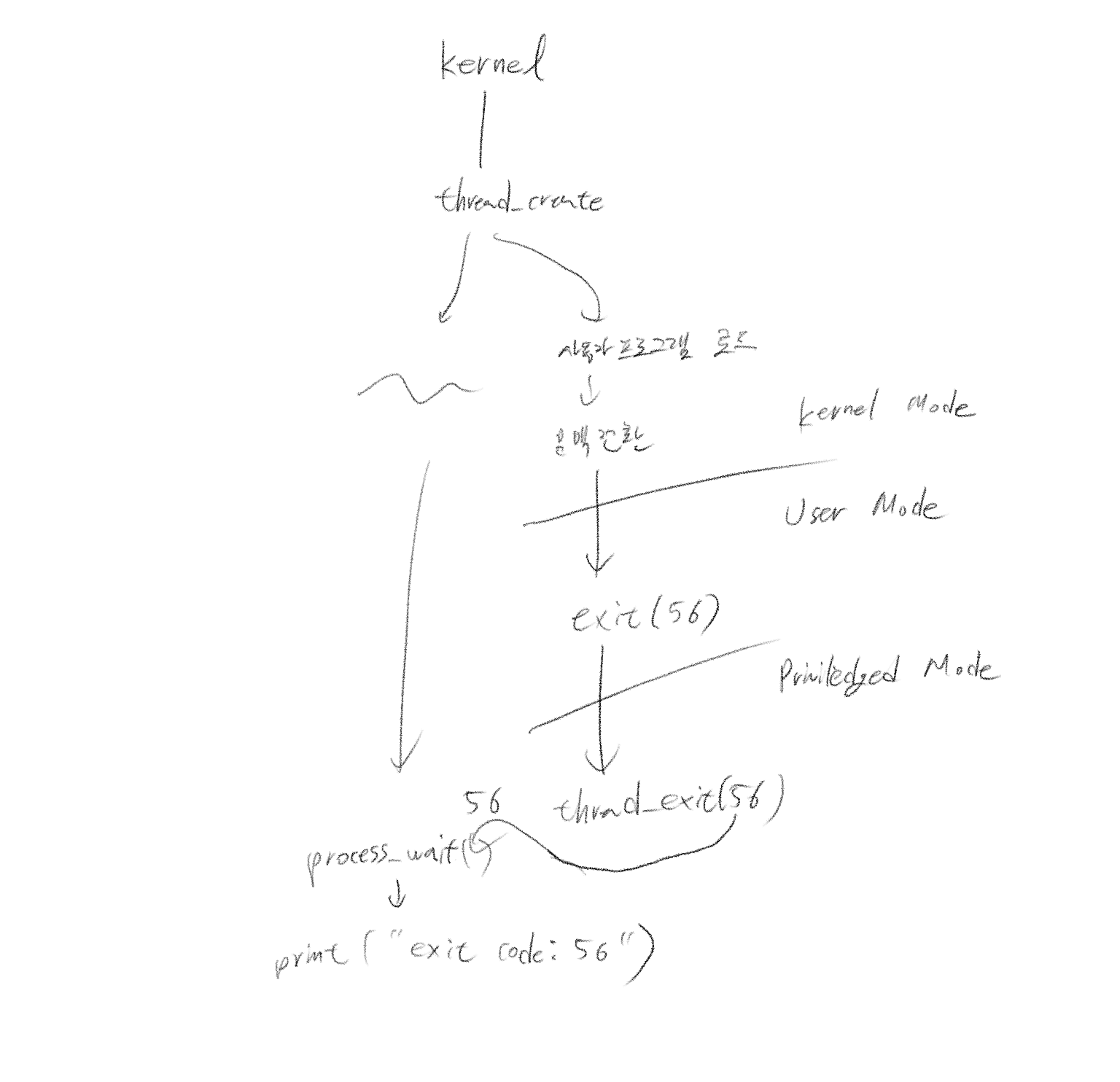
위에서는 kernel의 자식 쓰레드 입장에서만 exit 처리를 그렸는데 사실, 전체 쓰레드의 흐름은 아래와 같이 kernel main, kernel 자식 쓰레드를 모두 고려해야 합니다.
좌측의 흐름이 커널 메인, 우측의 흐름이 유저 프로그램을 실행한 자식 쓰레드입니다. 이때 exit의 인자값 전달 과정은 아래를 따릅니다.
- 유저 프로그램이 종료 인자값을 시스템 콜 핸들러에 전달.
- 시스템 콜 핸들러는 특권 모드(priviledged mode)에서 실행되며 프로세스를 종료하고, 전달 받은 상태 코드를 커널 메인 쓰레드가 접근할 수 있도록 전역 변수에 저장
- 상태 코드가 확실히 저장된 시점에 커널 메인 쓰레드가 이를 획득
위의 흐름에서 두 쓰레드가 다르기 때문에, 인자값을 일반적인 함수 루틴으로 전달받을 수 있는게 아니라, 아래와 같이 자식의 종료가 확실할 때 전역 변수(status_table)에 접근해서 종료 코드를 얻어 와야 합니다.
int process_wait(tid_t child_tid)
{
thread_join(&condition, &lock);
return status_table[child_tid];
}
void thread_join(struct condition *cond, struct lock *lock) {
lock_acquire(lock);
while (child_done == 0)
{
cond_wait(cond, lock);
}
lock_release(lock);
}
/* Exit the process. This function is called by thread_exit (). */
void process_exit(void)
{
struct thread *curr = thread_current();
status_table[thread_current()->tid] = thread_current()->status_code;
lock_acquire(&lock);
child_done = 1;
cond_signal(&condition, &lock);
lock_release(&lock);
process_cleanup();
}이때, 위의 코드처럼 동기화를 구현하지 않는다면 상태 코드가 메인 커널 쓰레드(좌측 루틴)로 제대로 전달될 수 없습니다. 컨디션 변수의 사용에 대해서는 이후 더 자세히 알아보도록 하죠.
2. open
구현 명세에 앞서 두 개의 그림을 보도록 하자.
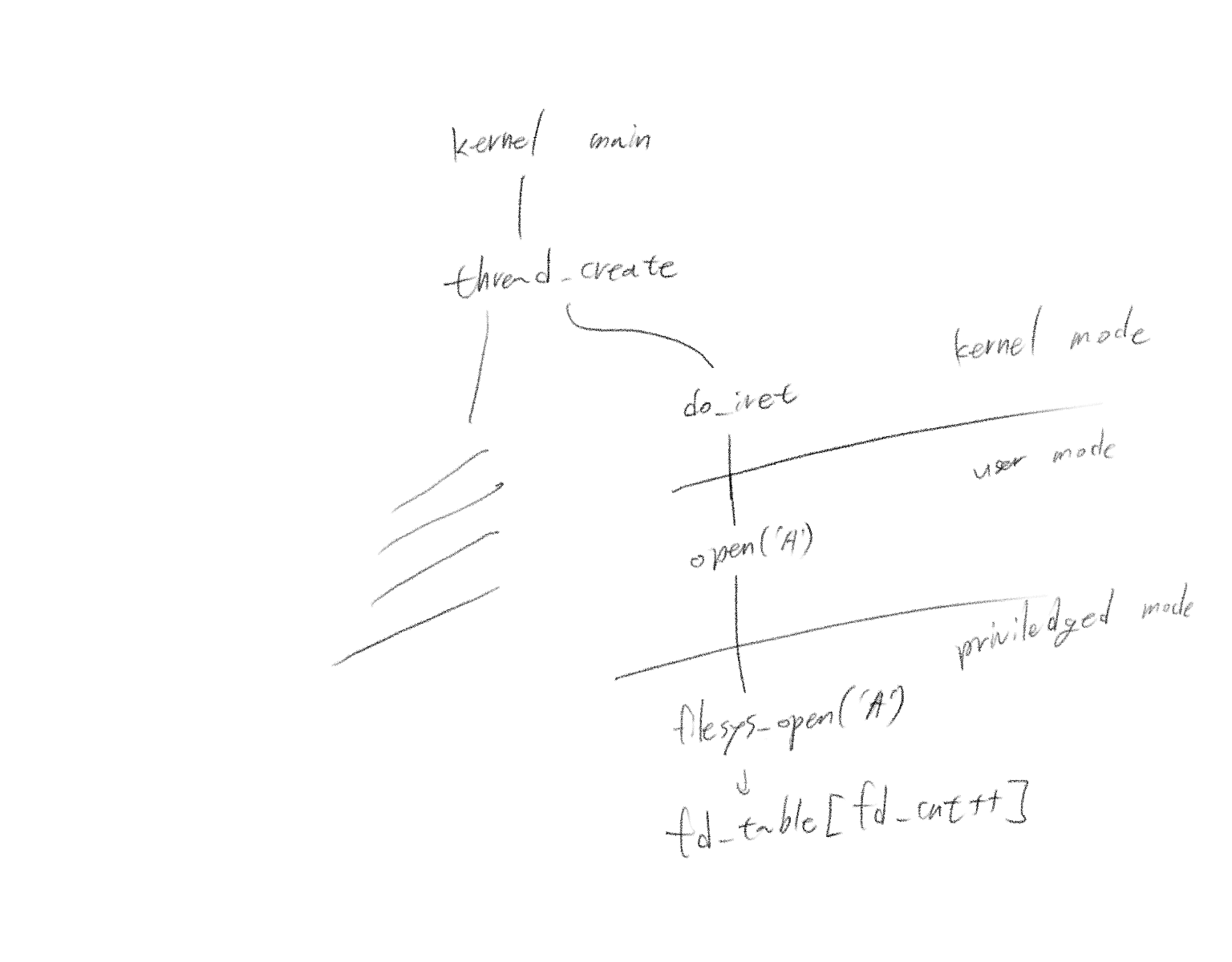
이 그림은 사용자 프로그램이 시스템 콜을 하면 커널에서 filesys_open을 처리하는 모습을 보여준다. 파일 이름인 'A'는 %rdi로 넘겨진다. 그렇다면 filesys_open은 무엇을 할까? 그리고 프로세스에는 어떤 일이 일어날까? 다음을 보자.
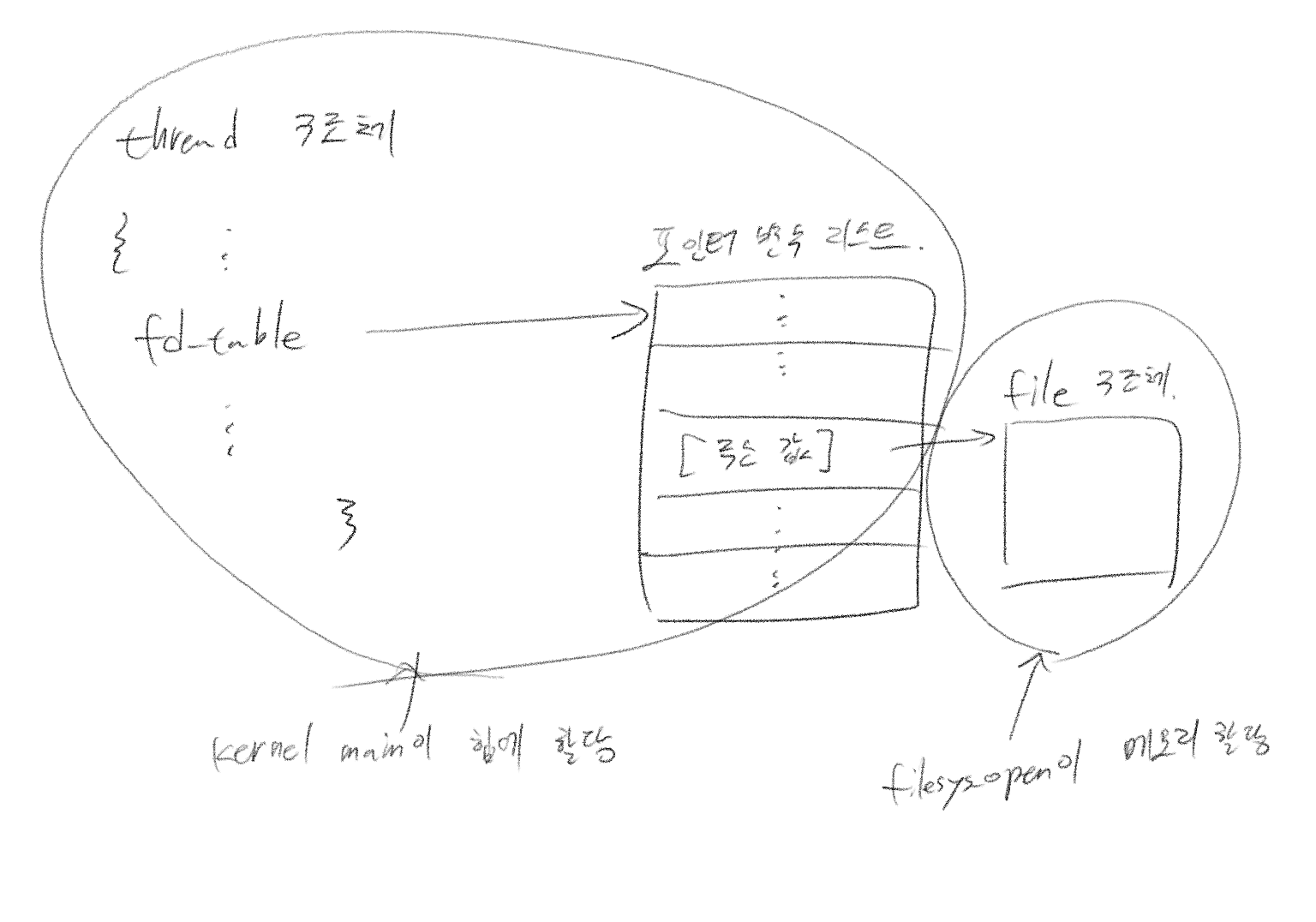
핀토스의 프로세스는 쓰레드 하나로 만들어지기 때문에 fd_table을 쓰레드 구조체에 추가해주는 것이 첫 번째 할 일이다. 여기에는 몇 가지 방법이 있는데 쓰레드 내에 fd_table을 직접 할당하는 것이 있고, 또는 fd_table에 대한 포인터 변수만 구조체에 넣고 실제 테이블을 따로 할당한 후 포인터에 참조시키는 방식이 있다.
첫 번째 방식이 메모리 관리 차원에서 편리하긴 하지만, 쓰레드가 프로세스라는 점을 명심하자. 이 방법에서는 힙의 크기가 커진다. 따라서 가용한 스택 공간도 작아진다. 이런 이유로 나는 두 번째 방식을 선택했다.
파일 디스크립터 테이블은 파일 구조체 주소를 담고 있다. 파일 구조체는 filesys_open이 알아서 할당 및 해제 해주므로 자세히 알 필요는 없다. 우리가 흔히 아는 fd는 그저 이 테이블의 인덱스를 의미한다.
이제 구현을 읽어보도록 하자.
int open(const char *file_name)
{
struct thread *t = thread_current(); // 현재 쓰레드 포인터를 획득
check_user_ptr(file_name); // 포인터 유효성 검사
lock_acquire(&filesys_lock); // 전역 락 획득
struct file *file = filesys_open(file_name); // 파일 오픈 작업 수행
lock_release(&filesys_lock); // 전역 락 해제
if (file == NULL) // 실패 시 -1 리턴.
{
return -1;
}
// File load success.
if (t->next_fd == -1) {
file_close(file);
return -1;
}
int fd = t->next_fd; // fd 값 획득
t->fdt[fd] = file; // 파일 테이블에 할당.
t->next_fd = get_next_fd(t);
return fd;
}핀토스의 어려운 점은 이 모든 선택이 나중에 책임으로 돌아온다는 점이다. 나는 쓰레드에 포인터 변수 하나를 더 정의하는 방식으로 파일 디스크립터 테이블을 구현했고, 결국 이 주소를 따로 역참조 후 해제해야 메모리 누수를 방지할 수 있다. 복제의 경우에도 역참조가 필요하다. 각각의 경우 모두 exit, fork 구현 시 마주하게 될 것이다.
마지막으로, open 구현 시 중요한 예외 처리가 하나 있었다. filesys_open은 파일 열기에 실패할 경우 null을 리턴하므로, open 루틴 내에서 꼭 아래와 같이 null 체크를 해야 한다.
if (file == NULL) // 실패 시 -1 리턴.
{
return -1;
}쓰레드 테스트 이슈
이 당시 베이스 코드의 이슈로 인해 이전 챕터의 쓰레딩 테스트가 실패하고 있었다. 쓰레드 테스트의 경우 유저 프로그램 실행과 달리, 다른 분기로 빠지게 되는데, 어째서인지 나의 코드는 그것이 제대로 되지 않았고, 쓰레드 프로그램도 유저 프로그램 실행 루틴으로 빠졌다. 그로 인해 락 초기화가 되지 않아 process_exit 과정에 page fault가 발생했다. 이해하기 쉽게 두 테스트의 루틴 차이를 나열해보자.
유저 프로그램
- 프로세스 생성 루틴을 타며 synch primitive들이 초기화됨
- 프로세스 종료 루틴에서 동기화 변수 참조 후 정상 종료
쓰레드 테스트 문제 상황
- 쓰레드 테스트 분기에서는 별도의 synch primitive 초기화 루틴이 없음
- 프로세스 종료 루틴에서 동기화 변수 참조 후 page fault
이것이 동료들의 코드에서는 애초의 별도의 분기가 이루어져 문제가 되지 않았는데, 나는 어째서인지 유저 프로그램과 쓰레드 모두 같은 루틴을 따르는 바람에 문제가 됐었다. 덕분에 프로세스 종료 과정을 더 자세히 살펴보는 계기가 되었다.
위와 같이 원인을 파악한 후에는 그냥 아래와 같이 쓰레드 신원을 파악하는 코드를 process_exit에 삽입하여 robust하게 종료 루틴을 분기시켰다.
// load 내부에 아래 부분 추가.
strlcpy(t->name, file_name, strlen(file_name)+1);
// ...
void process_exit(void)
{
struct thread *curr = thread_current();
if ((curr->name != NULL && userprog_names[curr->tid] != NULL) && !strcmp(curr->name, userprog_names[curr->tid]))
{
lock_acquire(&lock);
status_table[thread_current()->tid] = thread_current()->status_code; // set status_table of child thread
child_done = 1;
cond_signal(&condition, &lock);
lock_release(&lock);
printf("%s: exit(%d)\n", userprog_names[curr->tid], status_table[curr->tid]);
}
process_cleanup();
}사사로운 트러블슈팅이었지만, fork와 같은 프로세스 복제 루틴을 구현하기 앞서 프로세스 생명 주기를 자세히 볼 수 있는 경험이었다. 아래는 그 당시 쓰레드 테스트 분기를 파악해보고자 작성한 그림.
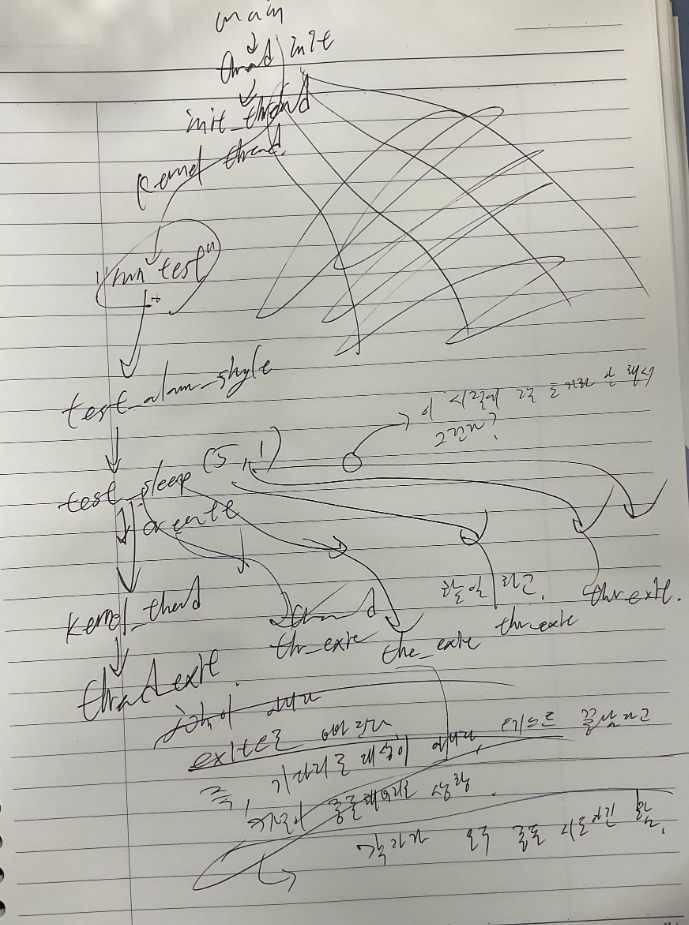
fork
fork 구현에 앞서 동기화 제어에 중요한 리팩터링을 해야 한다. 지금까지는 동기화 변수를 전역으로 사용하고 있었다. 하지만 자식 프로세스의 자원이 회수되지 못하는 상황을 방지하기 위해 부모와 자식은 서로에게 템포를 맞춰야 하며, 이를 위해 전역 변수가 아닌 각 구조체의 지역 변수가 필요하다.
그렇다면 발생하는 의문은 다음과 같다.
부모 자식 간에 공유할 동기화 변수는 둘 중 어디에 선언해야 하는가?
이에 대한 답을 찾기 위해 아래 그림을 살펴보자.
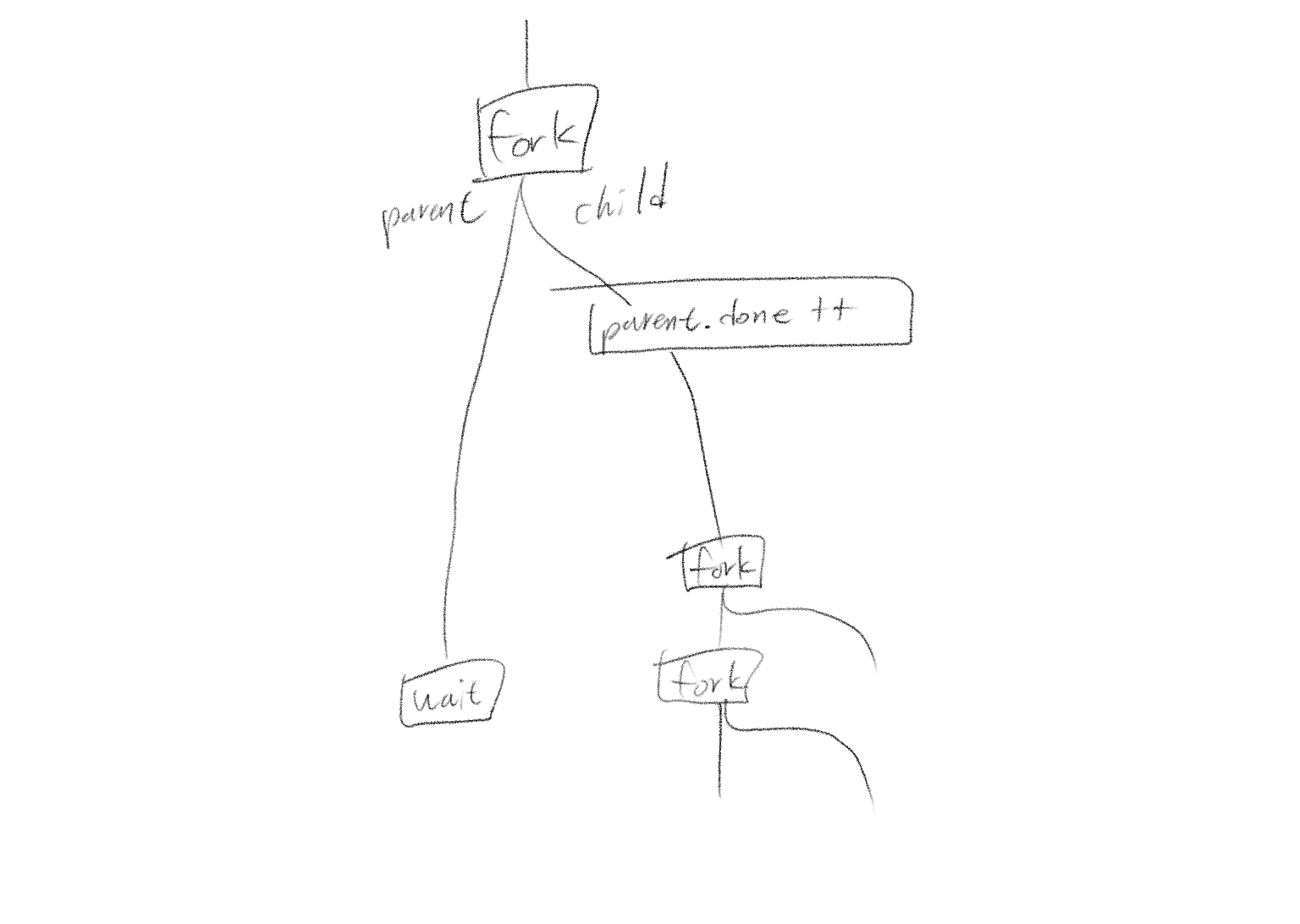
그림에서 parent의 멤버 done을 증가시켜준 이유가 무엇일까? 이를 이해하기 위해서는 미뤄왔던 컨디션 변수를 이해해야 한다.
condition variables
아래는 OSTEP의 예제이다.
int done = 0;
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;
pthread_cond_t c = PTHREAD_COND_INITIALIZER;
void thr_exit()
{
Pthread_mutex_lock(&m);
done = 1;
Pthread_cond_signal(&c);
Pthread_mutex_unlock(&m);
}
void *child(void *arg)
{
printf("child\n");
thr_exit();
return NULL;
}
void thr_join()
{
Pthread_mutex_lock(&m);
while (done == 0)
Pthread_cond_wait(&c, &m);
Pthread_mutex_unlock(&m);
}
int main(int argc, char *argv[])
{
printf("parent: begin\n");
pthread_t p;
Pthread_create(&p, NULL, child, NULL);
thr_join();
printf("parent: end\n");
return 0;
}이 코드에서 원하는 동작은 아래와 같다.
parent: begin
child
parent: end이 동작을 확실히 보장하기 위한 방안으로 예제 코드가 작성됐다고 보면 되는데, 이때 중요하게 볼 세가지가 있다.
- 컨디션 변수의 역할
- done이 있는 이유
- mutex lock이 있는 이유
1번을 이해하기 위해서는 아래 글을 읽어보자.
A condition variable is an explicit queue that threads can put themselves on when some state of execution (i.e., some condition) is not as desired (by waiting on the condition); some other thread, when it changes said state, can then wake one (or more) of those waiting threads and thus allow them to continue (by signaling on the condition).
쉽게 설명하자면 하나의 쓰레드가 다른 쓰레드를 기다리기 위해 sleep 상태에 들고, 다른 쓰레드가 작업을 마치면 signal을 보내서 잠자던 쓰레드를 깨울 수 있도록 하는 것이 조건 변수다. 그렇다면 done은 왜 있는 걸까? 다음 상황을 가정해보자.
- 부모가 wait에 걸리기 전에 자식이 빠르게 작업을 끝내고 시그널을 보낼 수 있음. 자식이 다시 signal을 보내는 루틴이 없으므로 이 경우 부모는 영원히 잠에 들게 됨.
- done은 쓰레드가 알아야 하는 동기화 정보이며, 이를 기준으로 sleeping, waking, locking이 이루어짐
void thread_exit()
{
Pthread_mutex_lock(&m);
Pthread_cond_signal(&c); // <- 1. 자식이 시그널을 보냄
Pthread_mutex_unlock(&m);
}
void thread_join()
{
Pthread_mutex_lock(&m);
Pthread_cond_wait(&c, &m); // <- 2. 부모가 그 후 잠에 듦. 깨워줄 루틴이 없음. 영원히 잠에 듦.
Pthread_mutex_unlock(&m);
}이제 3번, mutex lock이 있는 이유를 보도록 하자.
- 락이 없으면 race 컨디션 발생. 부모 쓰레드가 운 나쁘게 루틴 도중 인터럽트 발생으로 진행이 끊기면 역시 영원히 잠에 들 수 있음.
- mutex lock이 없을 경우 부모가 done을 확인하고 wait에 들어가기 직전에 인터럽트가 발생할 수 있다. 이때 자식이 signal을 보내고, 부모는 signal을 놓침에 따라 영원히 잠에 들게 됨.
- mutex lock이 있으면 부모와 자식이 부모와 자식이 동시에 done을 확인하거나 수정할 수 없다. 따라서 자식이 signal을 먼저 보내도 부모가 나중에 done을 확인해서 이미 자식의 루틴이 끝났는지 확인하고 sleep을 스킵할 수 있다.
void thread_exit()
{
done = 1;
Pthread_cond_signal(&c); // <- 2. 제어를 넘겨 받은 자식이 모든 작업 처리.
}
void thread_join()
{
if (done == 0) // <- 1. 이 줄 수행 후 인터럽트 발생으로 자식으로 제어권 넘어감
Pthread_cond_wait(&c); // <- 3. 다시 제어를 넘겨 받은 부모가 잠에 듦. 영원히.
}이렇듯 컨디션 변수는 강력한 동기화 기능을 제공하지만, 세 가지 변수(done, condition, lock)에 의존한다는 단점이 있다. 다시 fork 문제로 돌아와서, 이 변수들을 어디에 정의해야 좋을지 고민해보자.
방금 전에 보았던 wait 문제를 생각했을 때, 우리의 고민은 아래 문장으로 정리된다.
자식이 여럿일 때 어떻게 부모는 모든 자식이 종료될 때까지 기다릴 수 있을까?
앞서 보았던 OSTEP의 예제 코드는 done을 이진수처럼 쓰기 때문에 부모가 둘 이상의 자식을 고려할 수 없다. 답은 간단하다. done을 유동적으로 정의하는 것이다. 나는 복수의 자식과 동기화를 위해 아래와 같이 done을 변경했다.
- 자식 프로세스 생성 시점에 부모의 expected_done을 1 증가
- 자식 프로세스 종료 시점에 부모의 actual_done을 1 증가
기본적인 부모-자식 프로세스 동기화에 대한 접근은 이와 같았고, 이를 구현하기 위해 쓰레드 구조체에 아래 멤버를 추가했다.
struct thread *parent_process;
struct list *childs;
struct list_elem *child_elem; //
struct condition condition;
struct lock lock;
int expected_done;
int actual_done;이제 이를 사용하여 process_wait을 구현하면 된다.
이까지 fork를 구현하기 위한 동기화 문제를 살펴봤다. 이제 본격적으로 fork 매커니즘을 살펴보도록 하자.
핀토스에서 프로세스의 정체성은 아래 두 가지로 정리할 수 있다.
- 동일한 가상 주소
- 동일한 파일 디스크립터 테이블
1을 구현하기 위해서는 페이지테이블을 복제해야 한다. x86-64 아키텍처에서는 PTE(page table entry)에 가상주소/물리주소 매핑이 저장돼 있으므로 이것을 복제하면 된다. 이를 수행하는 함수가 duplicate_pte이다. 자세한 함수의 구현은 VM 파트에서 다루도록 하자.
2번은 말 그대로 fd_table을 복제하는 것이기 때문에 직관적으로 테이블을 복제하고 filesys_duplicate로 파일 구조체를 복제하면 된다. 이것도 VM구현 시 더 자세히 다루게 될 것이다.
1, 2를 통해 포크를 수행할 때, 또다른 동기화 문제가 다시 등장한다. 이는 아래 조건에서 기인한다.
"Parent process should never return from the fork until it knows whether the child process successfully cloned"
자식은 do_fork 루틴을 통해 포크를 진행하며, 부모는 이 루틴의 성공 여부를 알 때까지 자신의 fork 루틴에서 벗어날 수 없다. 이를 위해 fork_sema를 사용해 아래 순서를 보장한다.
- 부모의 fork 루틴 시작
- 자식의 do_fork 수행 완료
- 부모는 do_fork 성공/실패 여부에 따라 tid/tid_error 리턴
이를 세마포와 함께 그림으로 보면 아래와 같다.
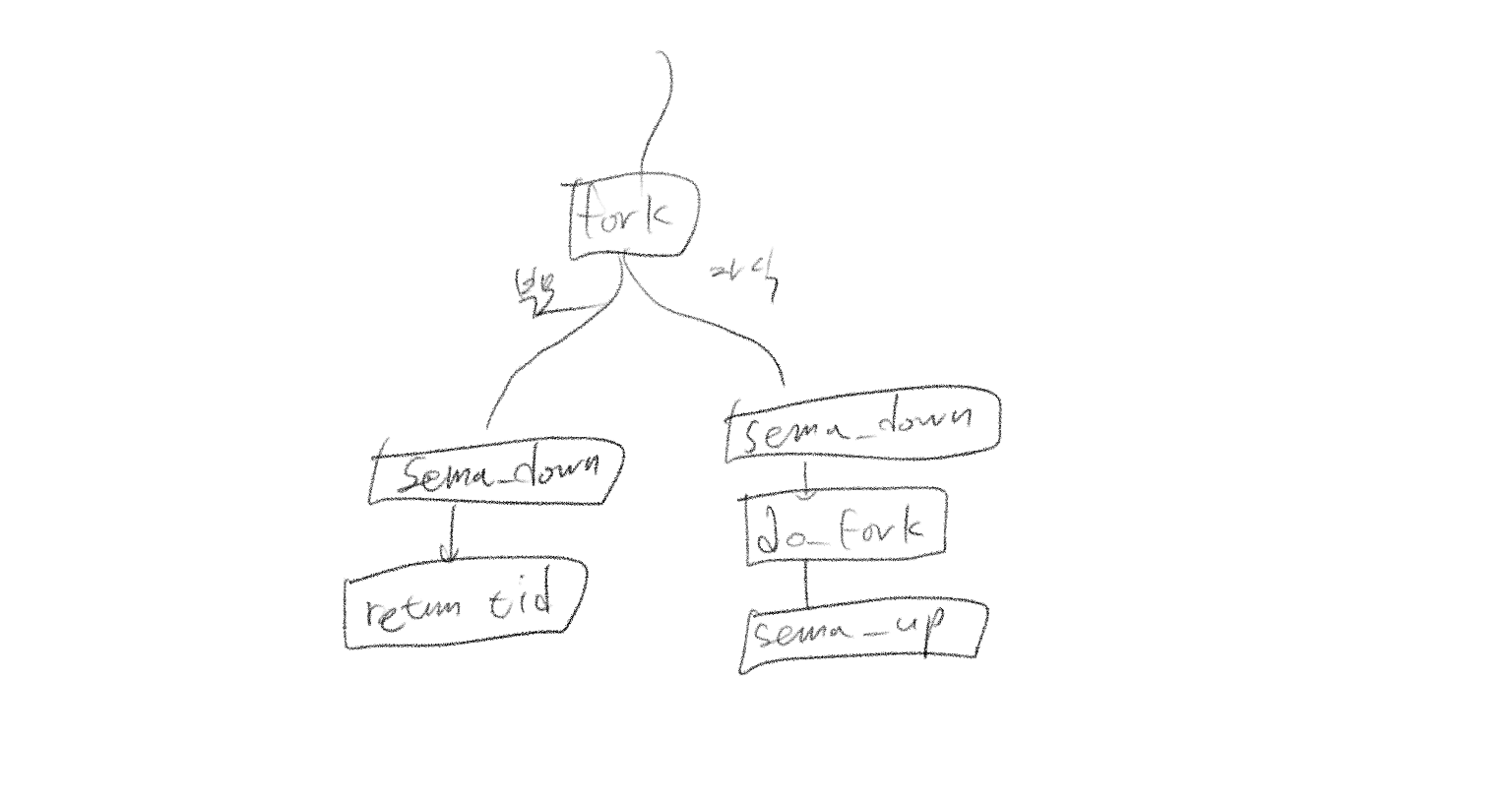
이까지가 기본 명세지만, 사실 테스트 케이스를 트러블슈팅할 때 배울 수 있는 점들이 더 많다.
exec-read 테스트
TODO: 추후 작성 예정
rox-multiple 테스트
TODO: 추후 작성 예정
exec
exec 같은 경우는 각 자료에서 명세가 다 달라서 구현 방향에 혼동이 있었다. 기본적인 exec은 실행 중이던 유저 프로그램을 exec의 대상인 다른 프로그램으로 교체하는 것이다. 하지만 카이스트 슬라이드 명세에는 새로운 프로세스 생성 후 exec을 따로 수행하는 것까지 exec에 포함돼 있다고 명시돼 있었고, 이는 잘못된 지침이었다. 그에 따라 관련한 트러블 슈팅이 있었는데, 자세히 보도록 하자.
int process_exec_pass1(const char *cmd_line)
{
char *fn_copy;
tid_t tid;
fn_copy = palloc_get_page(0);
if (fn_copy == NULL)
return TID_ERROR;
strlcpy(fn_copy, cmd_line, PGSIZE);
tid = thread_create(cmd_line, PRI_DEFAULT, process_exec, fn_copy);
sema_down(&thread_get_child(tid)->exec_sema);
}
int process_exec(void *f_name)
{
char *file_name = f_name;
bool success;
struct thread *curr = thread_current();
struct intr_frame _if;
_if.ds = _if.es = _if.ss = SEL_UDSEG;
_if.cs = SEL_UCSEG;
_if.eflags = FLAG_IF | FLAG_MBS;
process_cleanup();
success = load(file_name, &_if);
palloc_free_page(file_name);
if (!success)
return -1;
sema_up(&thread_current()->exec_sema);
do_iret(&_if);
NOT_REACHED();
}이로 인해 테스트 케이스의 요구사항과 다른 결과가 나왔다. 이해하고 있던 명세 자체가 오류였음을 늦게 깨달을 수록 문제 해결은 길어진다. 위의 코드를 올바른 명세대로 수정 후 테스트케이스는 매우 쉽게 해결됐다.
