쓰레드
쓰레드를 한 마디로 정의하면, 코어의 추상화다. 핀토스 깃북에는 다음과 같이 서술돼 있다.
Each threads act like a mini-program running inside Pintos, with the function passed to thread_create() acting like main().
짧은 문장이지만 재미있는 함의가 있다. thread_create의 인자값으로 함수 포인터가 넘겨지는데, 이것을 쓰레드는 항상 main처럼 실행 주기에서 중심적으로 실행한다. 이런 점에서 thread는 하나의 프로세스와 다를 바가 없다.
동기화
핀토스를 어렵게 만들었던 주범이다. 깃북에도 적혀 있었지만, 동기화는 인터럽트를 끄면 문제가 안 된다. 인터럽트로 인해 실행 쓰레드가 코어 점유를 잃게 되고, 그에 따라 (공유 자원에 대한 대처가 돼 있지 않다면) 동기화 문제가 터지기 때문이다. 물론 이렇게 하면 작업 속도가 매우 느려진다.
동기화를 구현하기 위해서는 아래의 중요한 synchronization primitives를 사용해야 한다.
- semaphores: 세마포 변수와 sema_down, sema_up 함수를 사용하여 임계 영역에 대한 접근을 제어
- locks: 역시 임계 영역에 대한 접근을 제어하지만, 세마포와 다른 점은 '소유자'가 있다는 점. 이는 우선순위 문제에서 중요하게 작용한다.
- monitors: 락과 크게 다른 점은 없지만, 두 쓰레드의 경쟁 상태를 철저히 감시할 수 있음. 이를 위해서 정해진 규약이 있는데, 다른 글에서 자세히 다뤄보도록 하겠음.
부연 설명하자면, 핀토스의 첫번째 챕터 이름이 thread이고 중요하게 등장하는 개념이 쓰레드와 동기화이긴 하나, 여기서 구현하고 생략할 수 있는 개념이 아니라 시스템 프로그래밍의 재료와 같은 녀석들이라고 보면 된다.
Alarm Clock
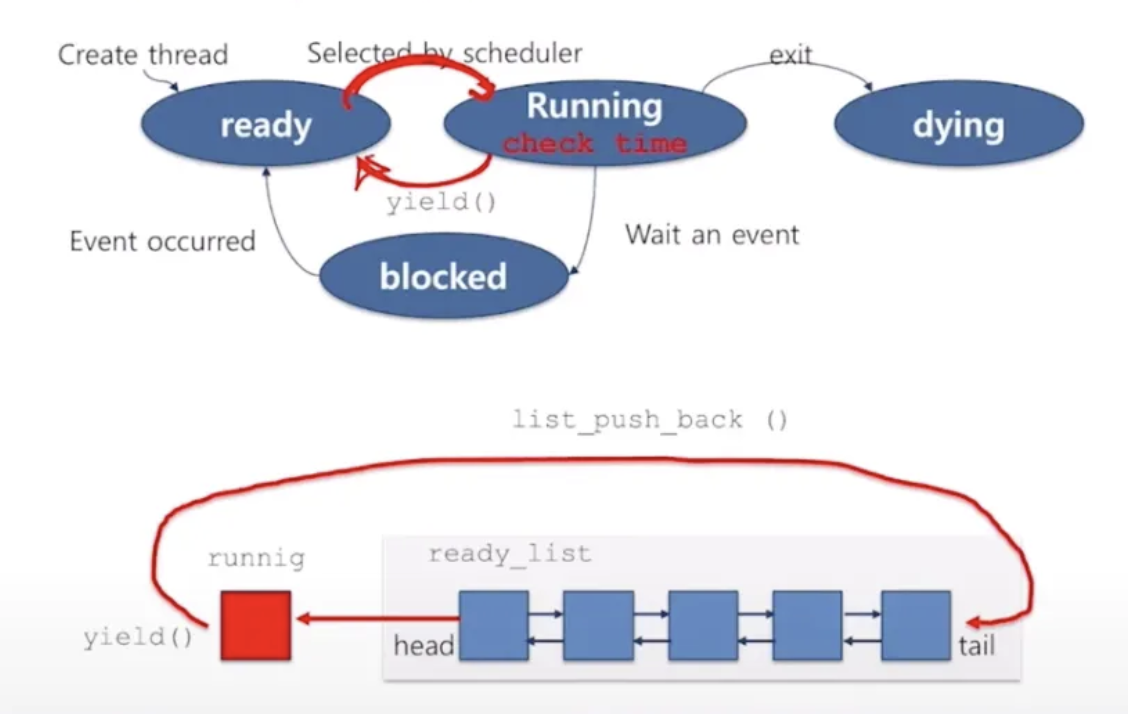
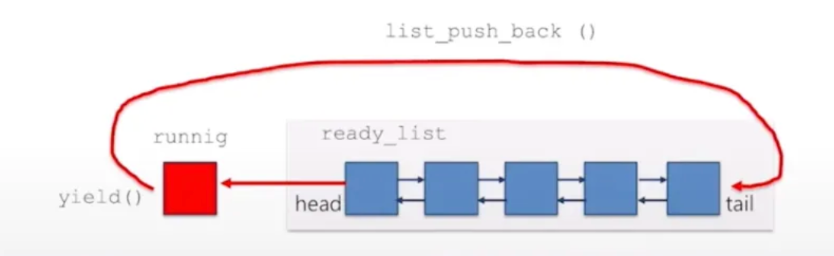
핀토스의 첫 번째 관문은 알람 클락에서 busy waiting을 제거하는 것이다. 우선 아래 그림을 보자. 주목할 점은, sleep list가 없다는 점이다. ready list에 있는 쓰레드들은 차례가 되면 "무조건" running thread가 되고, 이때 시간을 체크한 다음(아래 그림에서 check time으로 표시된 부분) 대기해야 한다면 yield 함수를 통해 다시 ready list로 빠지게 된다. 이때, running thread가 된 후 check time이 이루어지고 yield 수행이 완료되기까지 '애초에 실행될 필요가 없었던 쓰레드'가 코어를 점유하게 되므로 비효율적이다.
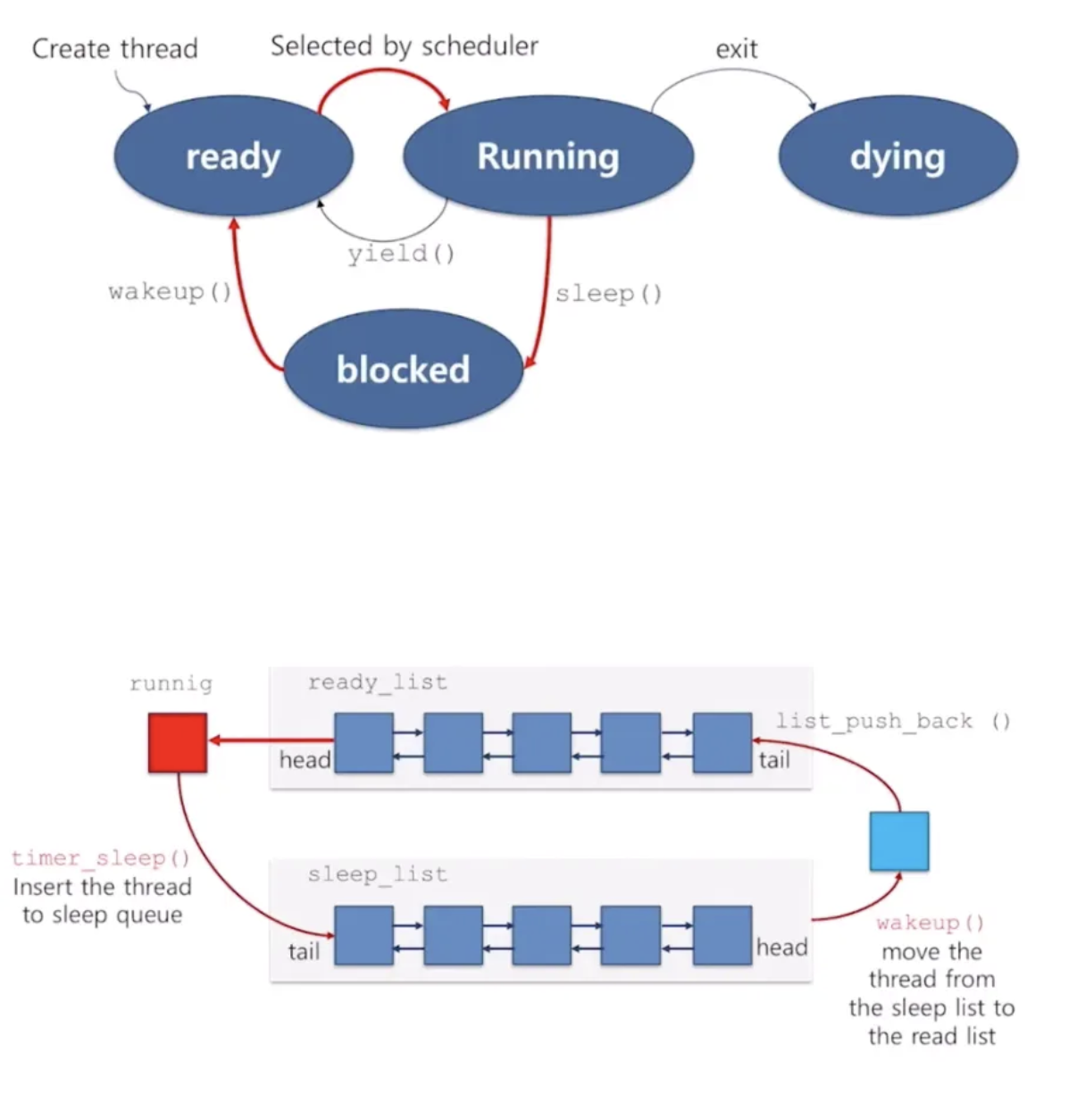
따라서 이를 개선하기 위해 아래와 같이 blocked 상태와 sleep list를 구현한다. sleep list에 blocked 쓰레드를 모두 대기시키고, 인터럽트를 줄 쓰레드만 interrupt handler가 검사하게 만들어 필요 없는 CPU 점유를 막는다.
/* Timer interrupt handler. */
static void
timer_interrupt (struct intr_frame *args) {
ticks++;
thread_tick ();
if (global_tick >= timer_ticks())
{
wakeup();
}
}timer_interrupt 함수를 다음과 같이 구현하면 된다. 간단하지만 아주 중요한 부분이었다.
트러블슈팅: timer_interrupt 함수
timer_ticks에 종속적이라는 사실을 모르고 global_tick의 자리에 현재 쓰레드의 tick을 생각 없이 집어 넣었다가 에러를 일으킨 기억이 있다. 아래는 문제가 됐던 코드.
if (ct->local_tick <= timer_ticks()) 우선순위 스케줄링
우선순위 스케줄링을 이해하기 위해서는 쓰레드에 우선순위가 있다는 사실을 알아야 한다. 이 우선순위에 따라 CPU 점유 순서가 달라지게 하려면 생각보다 많은 점들을 고려해야 한다. 특히 동기화 문제가 겹쳐서 우선순위가 꼬이는 경우가 있는데, 이것을 priority inversion이라고 한다.
우선순위 자체를 도입하기 위해서는 여러 부분을 구현해야 했었는데, 내가 구현 중에 문제를 겪었던 부분 한가지만 간략히 짚고 넘어가고자 한다.
트러블슈팅: ready list priority 문제
PintOS 쓰레드 관리에서 우선순위 구현 후 ready list에서 우선순위가 꼬이는 문제가 있었다. 레디 리스트의 머리를 검사했을 때 우선순위가 0으로 가장 낮은 쓰레드가 나오는 문제가 있었다.
원래는 thread_create에서 아래와 같이 do_schedule을 호출하여 조건부로 쓰레드의 상태를 ready로 바꾸었었다. 우선순위가 ready list안에서 조절되도록 한 것이다. 이것이 정확히 어떤 순간에 경쟁상태를 유발한 것인지는 모르겠으나, 쓰레드의 상태를 직접 조절하는 것의 위험성을 알 수 있었다.
tid_t thread_create(const char *name, int priority,
thread_func *function, void *aux)
{
...;
do_schedule(THREAD_READY);
...;
return tid;
}do_schedule 대신 좀 더 high level의 함수인 thread_yield를 사용하여 우선순위에 따른 선점이 알아서 일어나도록 수정했고, 이 문제를 해결할 수 있었다.
tid_t thread_create(const char *name, int priority,
thread_func *function, void *aux)
{
...
if (t->priority > curr->priority) thread_yield(); // <- 수정
return tid;
}Priority Inversion
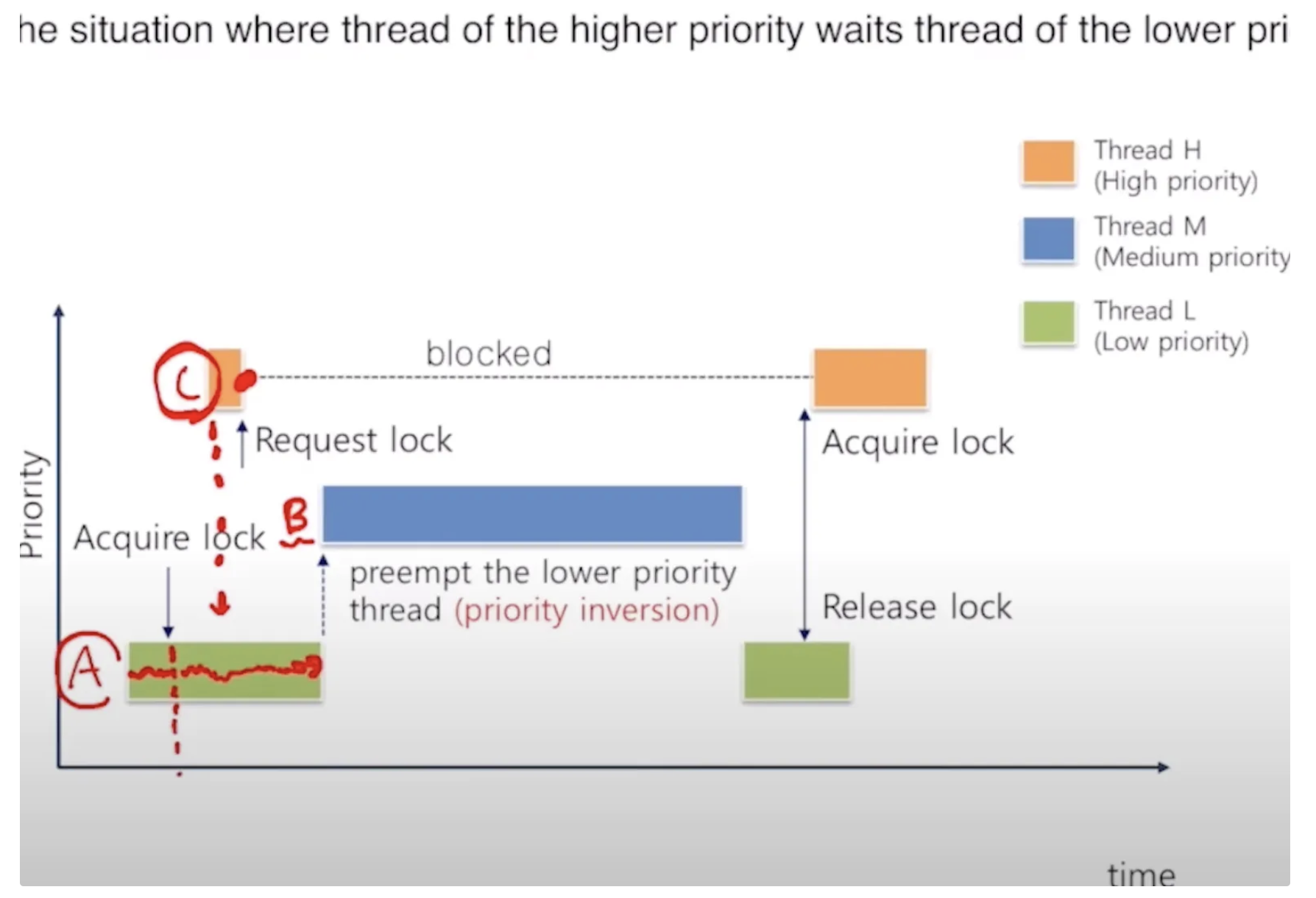
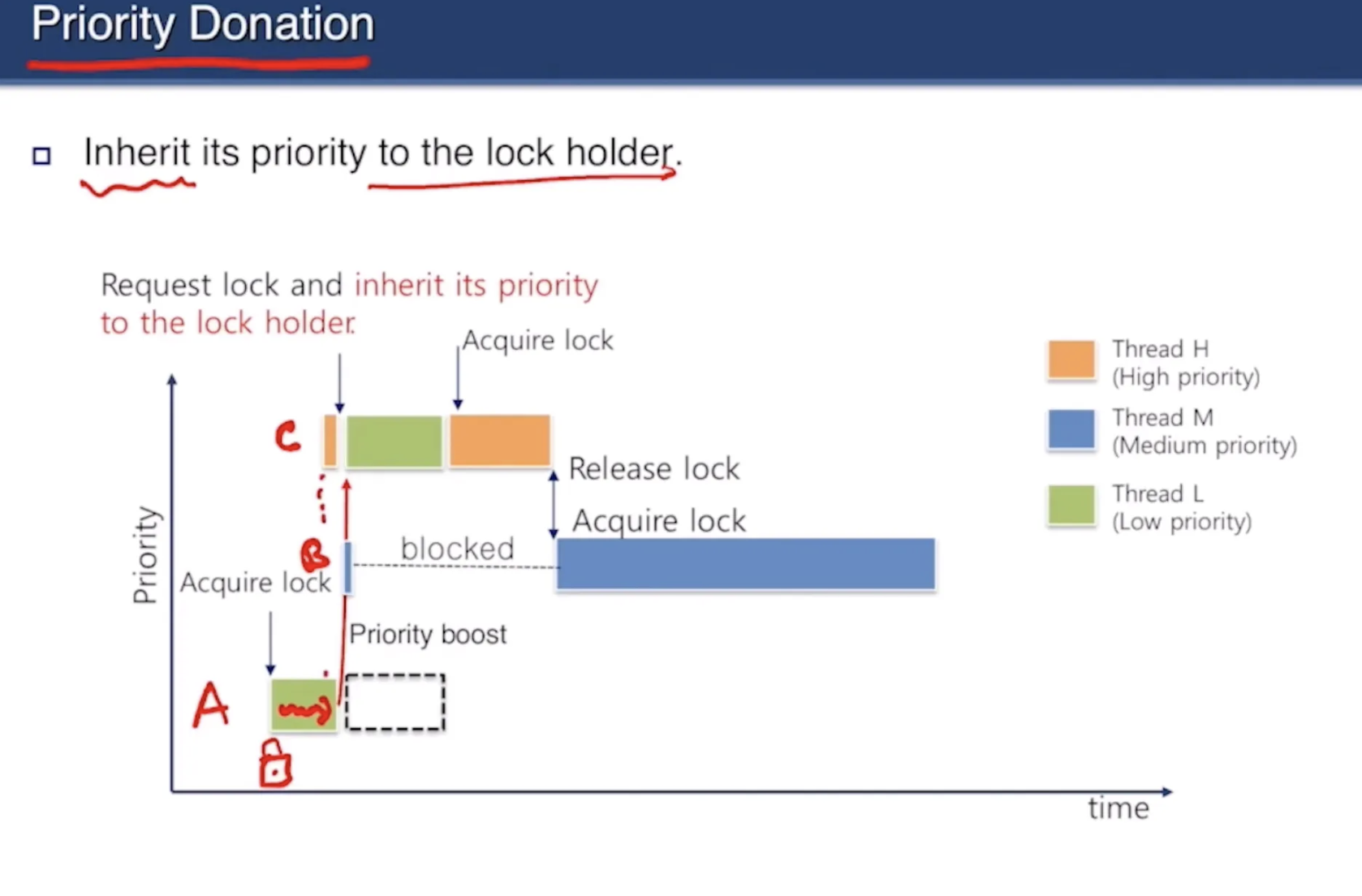
아래는 우선순위 역전 문제를 잘 보여주는 그림이다. 이 경우는 우선순위가 낮은 쓰레드 A가 어떤 락을 획득하고 CPU를 점유한다. 그 후 우선순위가 가장 높은 C가 그 락에 대한 요청을 하고 다시 block 되는데, 이 상황에 A보다는 높고 C보다는 낮은 쓰레드 B가 CPU를 preemption하게 되면 C는 락 홀더인 A가 block 됨에 따라 덩달아 B의 작업을 대기해야 하는 상황이 발생한다.
Priority Donation
이를 해결하기 위해서는 priority donation을 구현해야 한다. 이 역시 개념은 단순하다. 락 소유자인 A에게 C의 우선순위를 기부하여 B의 preemption 시도를 막을 수 있게 하는 것이다.
하지만 생각보다 고려해야 할 것이 많은데, 아래 두 가지가 대표적인 문제다.
-
nested donation: 쓰레드와 락이 겹쳐 있는 경우.
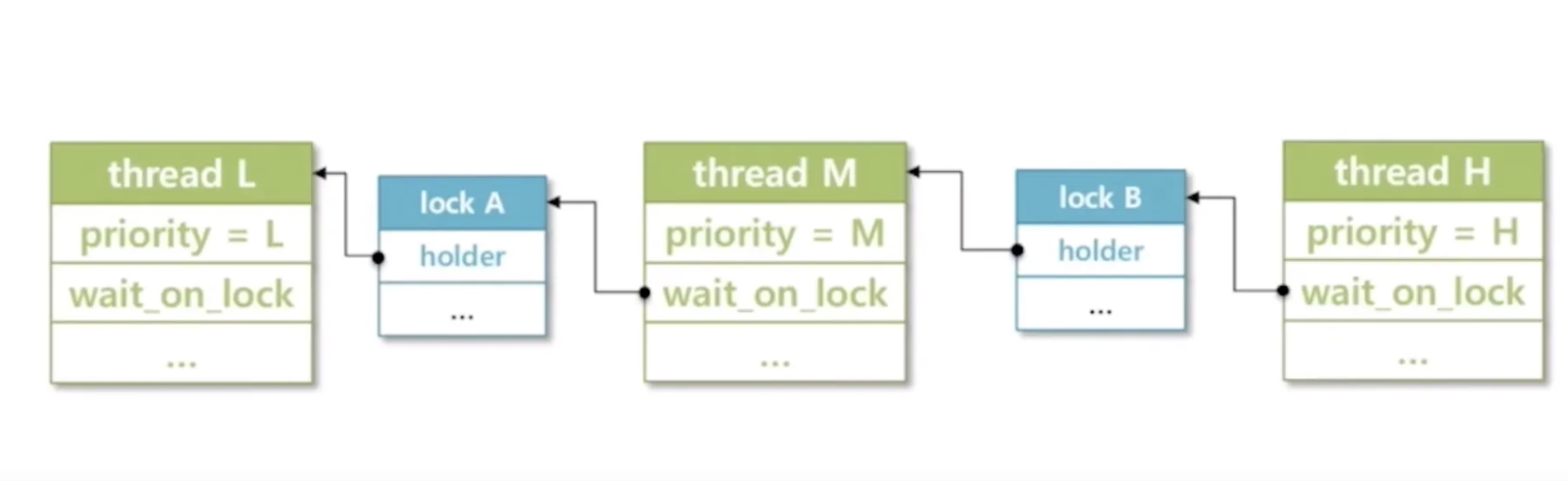
(이때 thread L은 H의 우선순위를 상속받을 수 있어야 한다.) -
multiple donation: 하나의 쓰레드가 락 여럿을 소유하고 있는 경우, 락 점유 쓰레드는 복수의 락으로부터 우선순위를 상속받아야 한다.
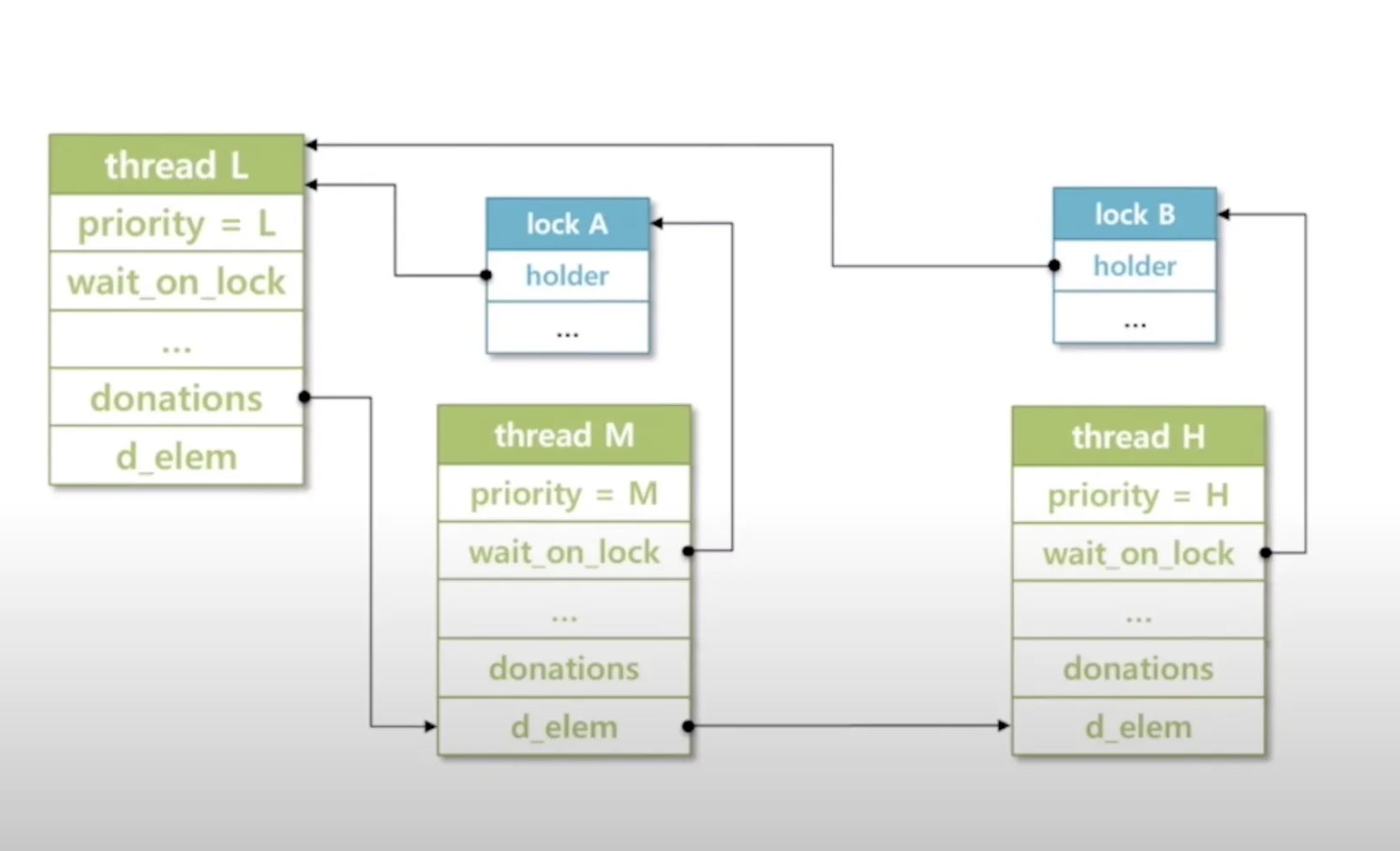
Code: Nested donation 구현
void lock_acquire(struct lock *lock)
{
ASSERT(lock != NULL);
ASSERT(!intr_context());
ASSERT(!lock_held_by_current_thread(lock));
if (lock->holder != NULL)
{
enum intr_level old_level = intr_disable();
list_push_back(&lock->holder->donations, &thread_current()->d_elem);
lock->holder->priority = get_max_priority(&lock->holder->donations, lock->holder->origin_priority);
intr_set_level(old_level);
}
thread_current()->wait_on_lock = lock;
sema_down(&lock->semaphore);
// 내가 락을 획득한 상황. donations 리스트를 관리해야 하는 입장.
lock->holder = thread_current();
thread_current()->wait_on_lock = NULL;
}
// refresh donated priority of a thread including it's predecessor and successor
void refresh_donation(struct thread *thread)
{
for ( ; thread && thread->wait_on_lock ; thread = thread->wait_on_lock->holder)
{
thread->priority = get_max_priority(&thread->donations, thread->origin_priority);
}
}
Code: multiple donation 구현
void lock_release(struct lock *lock)
{
ASSERT(lock != NULL);
ASSERT(lock_held_by_current_thread(lock));
// 여기 개선
lock->holder->priority = get_max_priority(&lock->holder->donations, lock->holder->origin_priority);
if (!list_empty(&thread_current()->donations))
{
struct thread *next_holder = list_pop_front(&thread_current()->donations);
next_holder->donations = lock->holder->donations;
}
lock->holder = NULL;
sema_up(&lock->semaphore);
}
int get_max_priority(struct list *l, int origin_priority)
{
int max_priority = origin_priority;
struct list_elem *e;
for ( e = list_begin(l); e != list_end(l); e = list_next(e))
{
struct thread *curr = list_entry(e, struct thread, elem);
if (max_priority < curr->priority) {
max_priority = curr->priority;
}
}
return max_priority;
}
