가상 메모리 개요
가상 메모리가 뭔가요?
가상 메모리는 물리 메모리(DRAM)의 추상화입니다. 실제 물리 메모리의 제한을 넘어, 모든 프로그램이 자신만의 넓은 주소 공간을 독립적으로 가진 것처럼 보이게 해주는 추상적인 개념이죠. 이제 가상 메모리를 구체적으로 뜯어봅시다.
프레임, 페이지, 페이지 테이블
우선 페이지와 프레임에 대해서는 아래처럼 간단히 생각할 수 있습니다.
프레임 = 물리 메모리의 연속적인 영역
페이지 = 가상 메모리의 연속적인 영역
이때, 페이지 테이블은 각 페이지를 프레임에 매핑하는 역할을 합니다. MMU(Memory Management Unit)는 페이지 테이블을 참조하여 CPU가 생성한 가상 주소를 실제 물리 메모리의 주소로 변환하고, 이 과정에서 페이지 테이블은 가상 페이지 번호를 물리 프레임 번호로 매핑하는 핵심 역할을 수행합니다.
Supplemental Page Table vs Page Table
SPT(Supplemental Page Table) 역시 가상 메모리에서 중요한 역할을 차지하고 있는데요, 이것과 페이지 테이블의 차이가 뭘까요?
SPT는 각 페이지에 대한 추가적인 정보와 함께 페이지 테이블을 공급합니다. 이 추가적인 정보가 무엇일까요?
하드웨어 페이지 테이블은 주소 변환에 필요한 기본적인 정보만을 저장하므로, 운영체제가 고급 메모리 관리 기능을 구현하기 위해서는 추가적인 메타데이터가 필요합니다. 이때 SPT는 각 페이지가 어디서 로드되어야 하는지(실행 파일, 스왑 공간, 익명 페이지 등)에 대한 정보를 저장하며, 페이지 폴트 발생 시 적절한 처리 방법을 결정할 수 있게 합니다.
결국 가장 중요한 부분은 '페이지 폴트 처리' 부분인데요, 페이지 테이블은 DRAM의 공간에 존재하며 가상 메모리 매핑을 수행한다고 했죠? 그런데 가상 메모리와 물리 메모리 매핑이 존재하지 않을 수도 있습니다. (가상 메모리가 물리 메모리와 비교할 수 없이 크기 때문이죠.) 이때 매핑이 실패하는 상황을 페이지 폴트라고 합니다.
페이지 폴트가 발생하면, 페이지 테이블을 SPT의 도움을 받아 갱신하게 됩니다. 업데이트가 제대로 이루어지면 MMU는 다시 물리 메모리 주소를 CPU에 리턴할 수 있게 되고, 프로세스들은 이 모든 일들을 몰라도 실제 DRAM보다 넓디 넓은 가상 메모리 공간을 자유롭게 사용할 수 있죠.
따라서 아래와 같이 정의할 수 있습니다.
SPT의 가장 중요한 사용자는 페이지 폴트 핸들러이다.
페이지 폴트 핸들러
페이지 폴트 핸들러는 말 그대로 페이지 폴트를 처리해주는 모듈입니다. 아래와 같은 동작을 수행하죠.
- SPT에서 폴트 발생한 페이지 찾기
- 페이지를 지정할 프레임을 가져오기
- 데이터를 프레임으로 가져오기.
- 폴트 발생한 가상 주소의 페이지 테이블 엔트리가 물리 페이지를 가리키도록 하기.
이제, 개념은 이까지 보고 자세한 구현으로 넘어가도록 합시다.
난해하게 정리된 구현 기록을 출판할 때 도움이 되는 정리 방식
문제 -> 설계 구상 -> (시도한 접근법)-> (시행착오) -> 결과물
구현
supplemental_page_table
문제
위에서 살펴 보았던 spt를 직접 구현해야 합니다.
설계 구상
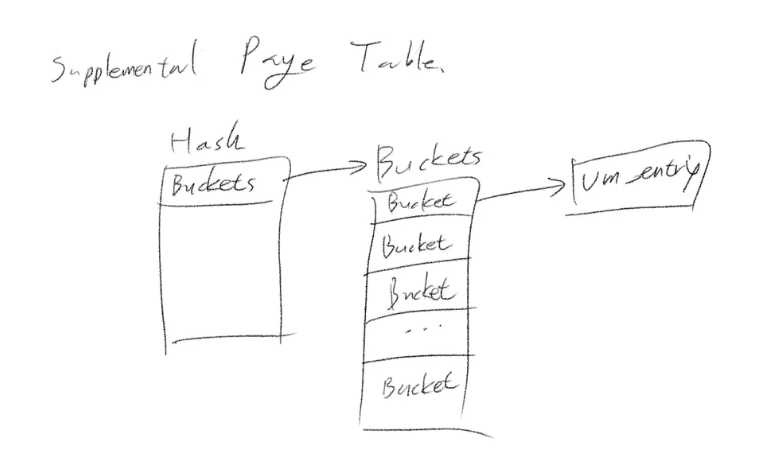
초기 구상은 이렇게 해쉬 테이블을 SPT의 멤버로 만들어 놓고, 해쉬 테이블의 버킷에 vm_entry(매핑 정보가 저장됨)를 저장하는 것이었습니다.
결과물
구상한 그대로 hash_table을 구현했습니다.
struct supplemental_page_table {
struct hash hash
}이렇게 간단하게 구현하고 빠르게 다음으로 넘어가도록 하죠.
supplemental_page_init()
문제
이 함수는 위에서 만들었던 SPT를 초기화하는 역할을 수행합니다. 저는 hash 구조체를 정의해 놓았기 때문에 그에 걸맞는 초기화가 필요합니다
결과물
void supplemental_page_table_init (struct supplemental_page_table *spt UNUSED) {
hash_init(&spt->hash, page_hash, page_less, NULL);
}hash_init 함수의 구체적인 명세는 주제를 벗어나므로 다루지 않겠습니다.
spt_find_page()
문제
이 함수는 가상 주소 'va'에 대응하는 구조체 'page'를 주어진 spt에서 찾습니다. 실패하면 NULL을 리턴하죠.
설계 구상
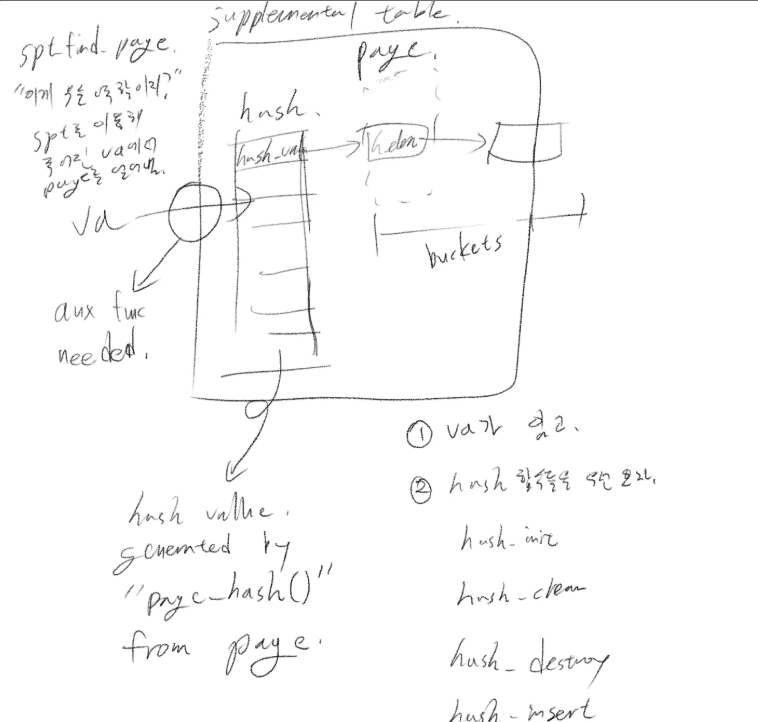
설계 당시에 그렸던 그림입니다. 기본적으로 페이지 구조체의 h_elem을 해쉬 값으로 사용하여 해쉬 검색하면 됩니다.
결과물
struct page *
spt_find_page (struct supplemental_page_table *spt, void *va) {
struct page *page = NULL;
struct page p;
struct hash_elem *e;
e = hash_find(&spt->hash, &p.h_elem);
if (e != NULL)
{
page = hash_entry(e, struct page, h_elem);
}
return page;
}spt_insert_page()
문제
이 함수는 page 구조체를 주어진 spt에 삽입하는 루틴입니다. 이미 동일한 va의 페이지가 존재하면 삽입이 안 되도록 검증 절차도 있어야 합니다. (이 검증은 hash_insert가 주어진 hash elem과 hash table에 대해 수행하고 실패한 경우 알아서 NULL을 리턴합니다.)
설계 구상
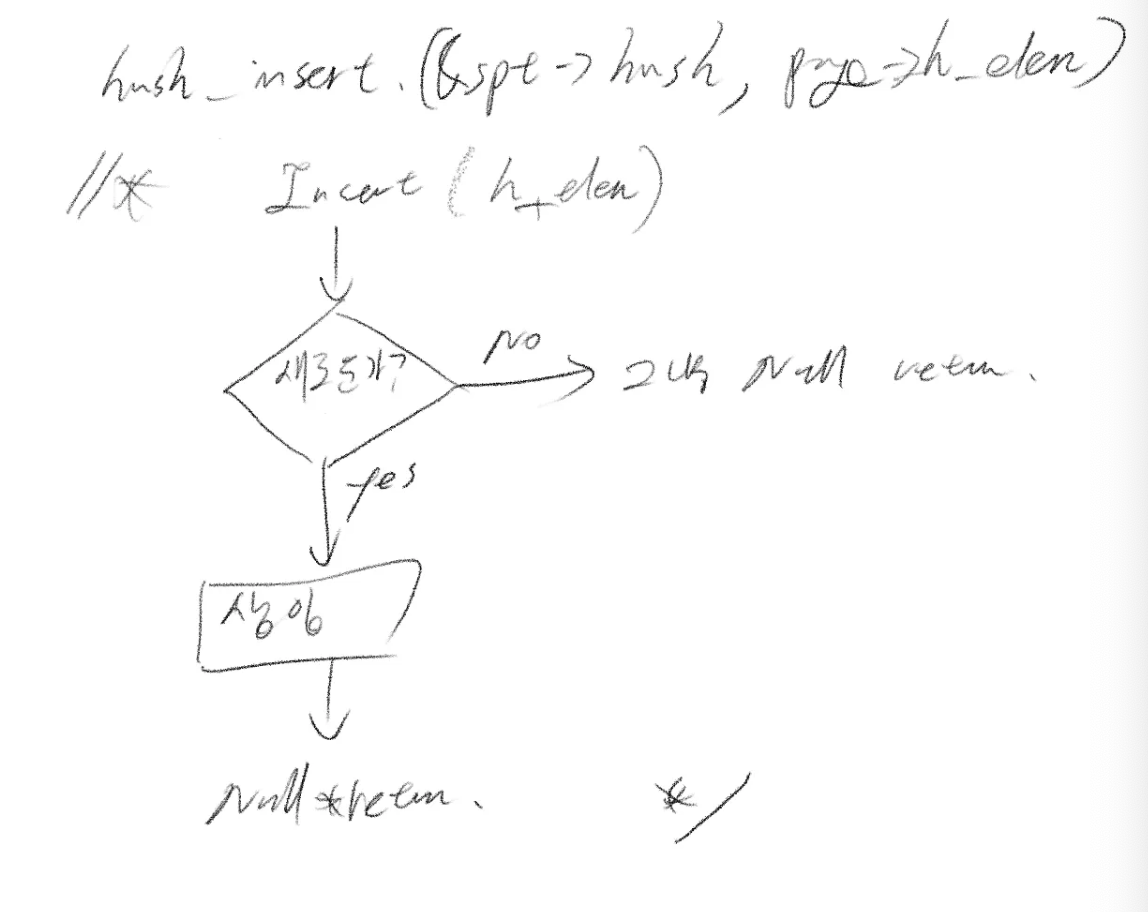
spt_insert_page의 진행 과정을 표현한 다이어그램입니다.
결과물
bool
spt_insert_page (struct supplemental_page_table *spt,
struct page *page) {
int succ = false;
if (hash_insert(&spt->hash, &page->h_elem) == NULL)
{
succ = true;
}
return succ;
}vm_get_frame()
문제
이 함수는 palloc_get_page를 수행해서 유저 풀에서 새로운 물리 프레임을 가져옵니다. 말 그대로 여분의 frame을 DRAM에서 가져오는 함수죠. 그런데 만약 DRAM에 남는 공간이 없으면 어떻게 될까요? 핀토스의 DRAM은 20MB로 설정해놓기 때문에 충분히 그럴 수 있고, 상용 컴퓨터들도 DRAM이 상대적으로 작은건 마찬가지니까 충분히 고려할 상황이죠. 그럴 때 여분의 frame을 만들기 위해 데이터를 디스크로 swap out시키는 기술이 필요합니다. 지금은 일단 이 상황을 고려 않고 구현하도록 하죠.
설계 구상
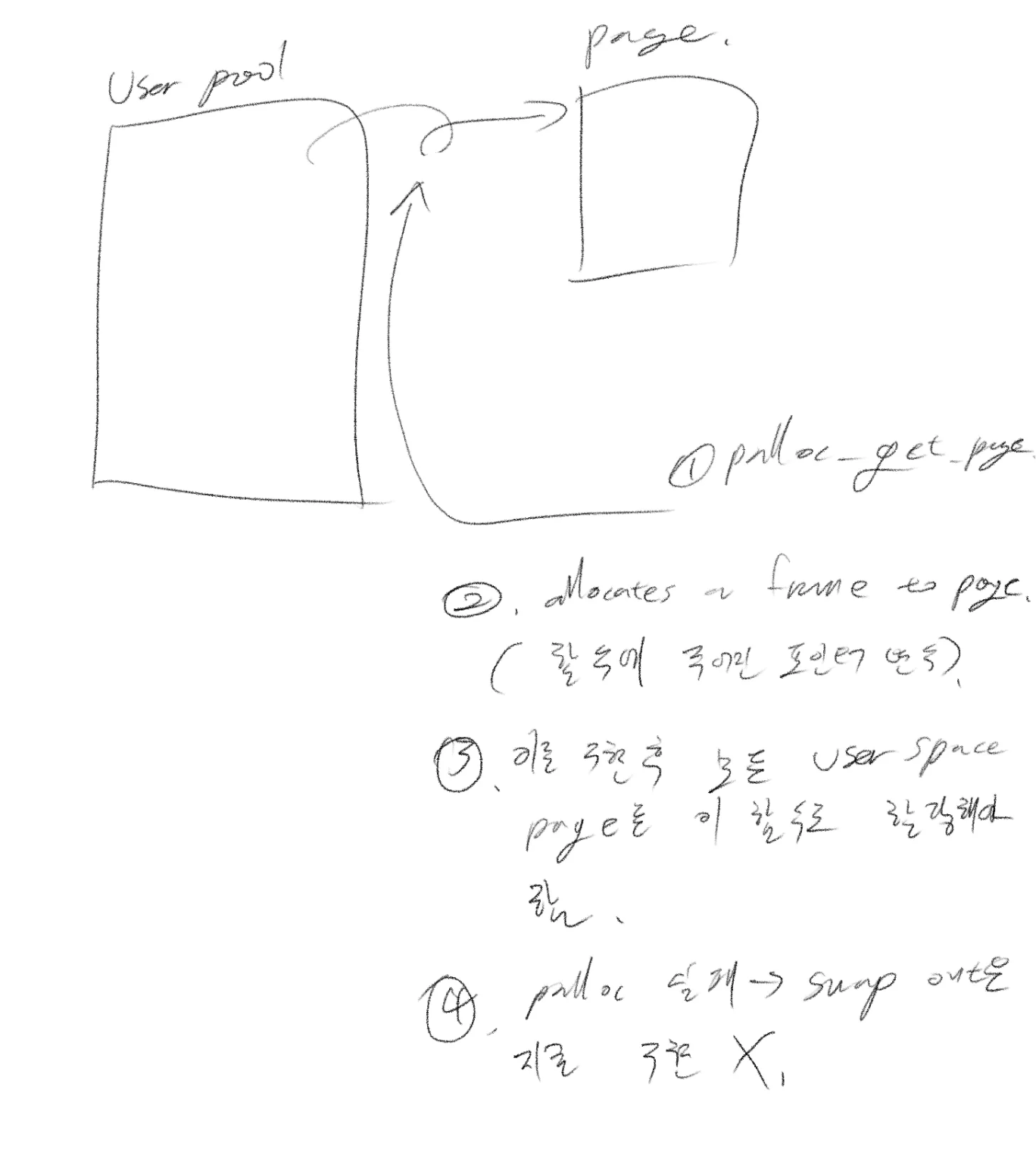
이 함수의 작동 순서는 위 그림과 같습니다. 좌측에 표현된 User Pool은 DRAM과 1대 1로 대응 된 커널 메모리 영역 중에 존재합니다.(이 부분은 이해하기 어렵지만 매우 중요합니다.)
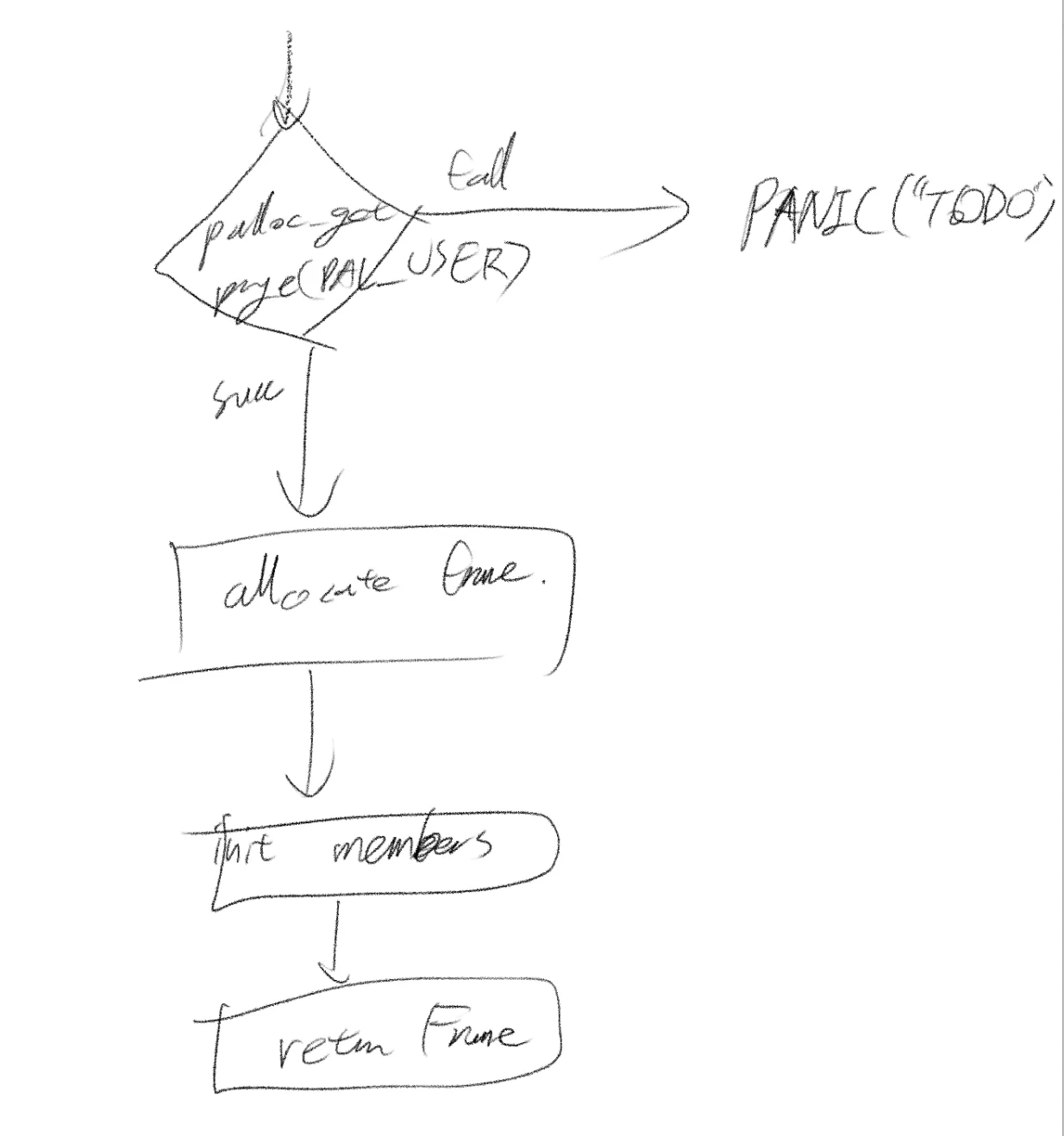
간략히 그려본 다이어그램은 위와 같습니다. palloc_get_page()를 통해 유저 풀에서 프레임 획득을 시도하는데, 실패할 경우 커널 패닉을 일으키도록 일단은 임시 조치를 해야 합니다.
시행착오
static struct frame *
vm_get_frame (void) {
struct frame *frame = NULL;
void *page = palloc_get_page(PAL_USER);
if(page != NULL)
{
frame->page = (struct page *) page; // page에 page 주소가 담겨 있고, 이 주소를 frame->page 포인터 변수에 그대로 복사.
frame->kva = page;
}
else
{
PANIC("TODO");
}
ASSERT (frame != NULL);
ASSERT (frame->page == NULL);
return frame;
}구현 당시 frame 구조체에 대한 오해가 있어서 시행착오가 있었는데요, 최종 코드와 다른 점들을 간략히 정리해 봅시다.
| 시행착오 | 최종 코드 | |
|---|---|---|
| palloc_get_page 리턴값 저장 위치 | (보이드 포인터) page | (보이드 포인터) kva |
| frame->page에 지정되는 값 | (page 구조체 포인터) 위의 page 포인터 값 | NULL |
| frame->kva에 지정되는 값 | (보이드 포인터) page | kva |
두 코드 구현의 결정적인 차이를 일으킨 오해는 아래와 같습니다.
vm_get_frame 함수 내의 frame 포인터 변수는 실제 프레임이다.
이는 사실이 아닙니다. frame 구조체는 프레임의 메타 데이터를 저장할 뿐입니다(이는 page 구조체 역시 마찬가지입니다). 따라서 단순히 DRAM에서 프레임을 할당받은 지금, 어떤 가상 페이지에 매칭도 되지 않았는데 frame->page에 어떤 값을 할당하는 것은 어불성설이죠. 대신 실제로 가상 메모리의 페이지에 할당이 되는 시점에 frame->page도 업데이트해야 할 것입니다.
그렇다면 이 메타 데이터를 '올바르게 설정'하기 위해서 포인터 변수에 불과한 frame에게 실제 공간을 할당해줘야 합니다. 이 때문에 아래 코드가 추가 됐습니다.
frame = malloc(sizeof(struct frame));
그리고 이 메타 데이터에 적절한 값을 업데이트 해야겠죠? 이때, 원래 page였던 보이드 포인터 변수의 이름을 kva로 바꾼 이유를 짚어 보겠습니다.
page로 이름 지었던 이유: palloc_get_page가 리턴하는 것이 실제 페이지의 주소라고 생각했기 때문
이 역시 사실이 아닙니다. palloc_get_page는 이름과 달리(어째서!) 가상 페이지가 아닌 물리 프레임을 할당합니다. (이 사실은 위에서도 살펴 봤었죠) 핀토스에서는 여기서 의미하는 페이지의 주소를 일반적인 가상 주소와 구별하기 위해 kva(kernel virtual address)라는 개념을 사용합니다. 그래서 깔끔하게 정리하면 아래와 같은 결론이 나오죠.
kva = 물리주소
palloc_get_page = 물리 주소인 kva를 리턴
그래서 frame 메타 데이터 구조체에는 kva라는 멤버가 있는 것입니다. 프레임이 실제로 어떤 물리 주소에 존재하는지 저장하기 위해서죠. 이런 개념을 이해하고 봐야 아래 코드가 충분히 합리적입니다.
frame->kva = kva;
frame->page = NULL;결과물
static struct frame *
vm_get_frame (void) {
struct frame *frame = NULL;
void *kva = palloc_get_page(PAL_USER); // DRAM에서 획득한 프레임의 실제 주소
if(kva != NULL)
{
frame = malloc(sizeof(struct frame)); // 실제 frame이 아니고 frame의 메타 데이터입니다.
if (frame != NULL)
{
frame->kva = kva; // 메타 데이터에 물리 주소를 할당
frame->page = NULL; // 지금은 할당된 페이지에 채워넣을 프레임 데이터가 정해지지 않았음을 의미합니다.
}
else
{
palloc_free_page(kva);
PANIC("TODO");
}
}
else
{
PANIC("TODO");
}
ASSERT (frame != NULL);
ASSERT (frame->page == NULL);
return frame;
}vm_do_claim_page()
문제
이 함수는 인수로 넘겨진 page 포인터 변수에 대해 프레임을 매칭(이를 claim이라고 표현합니다)시켜주는 함수입니다. 이때, 여기서 다루는 page 역시 실제 가상 메모리상의 페이지가 아닌 페이지 메타 데이터임을 명심해야 합니다.
설계 구상
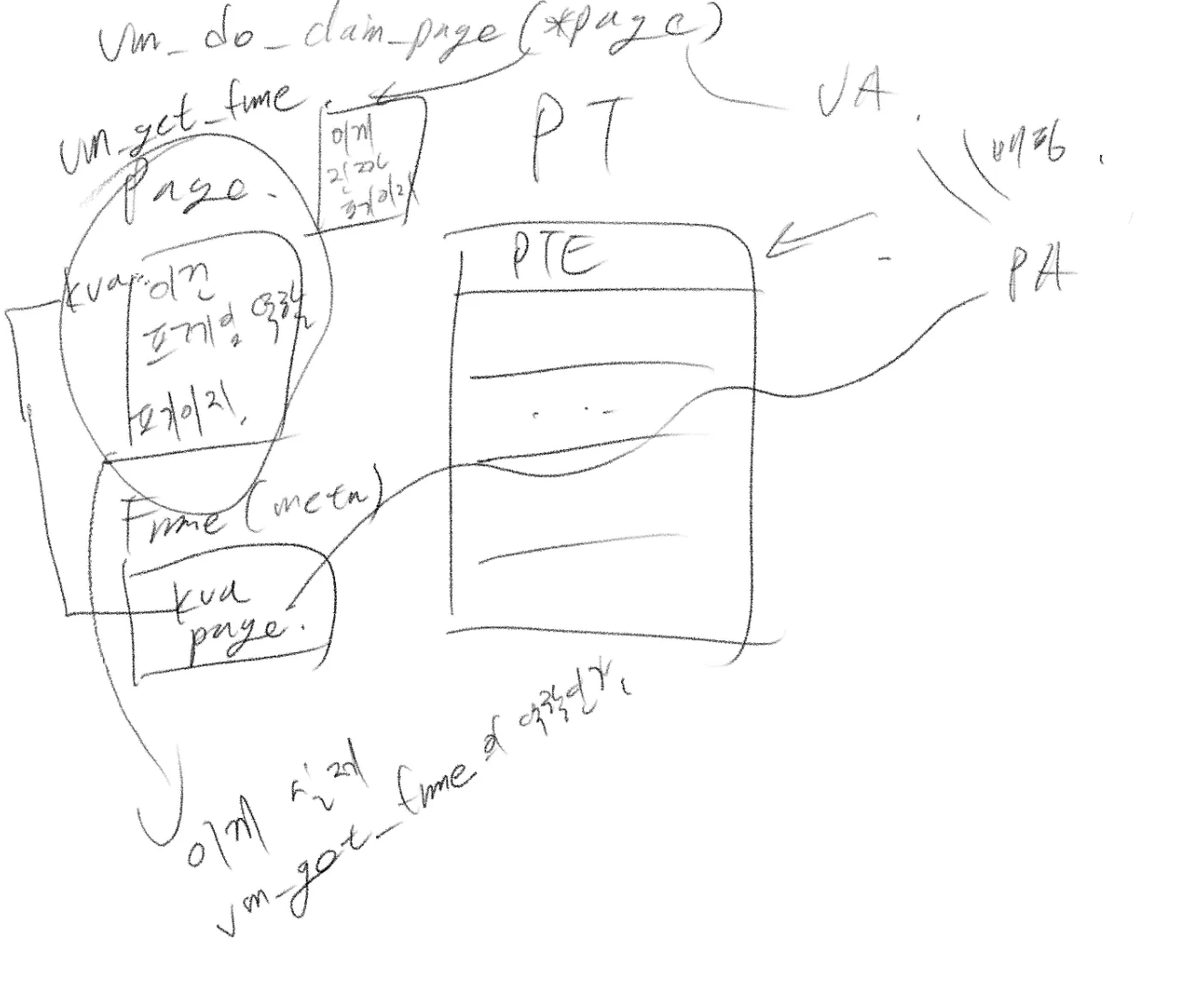
결과물
Set links 부분은 메타 데이터 개념을 제대로 이해했다면 어렵지 않게 넘어갈 수 있을 겁니다.
static bool
vm_do_claim_page (struct page *page) {
struct frame *frame = vm_get_frame ();
/* Set links */
frame->page = page;
page->frame = frame;
pml4_set_page(thread_current()->pml4, page, frame->kva, true);
return swap_in (page, frame->kva);
}vm_claim_page()
문제
위에서 구현한 vm_do_claim_page()가 page를 인수로 받는 것과 달리, 가상주소 va를 인수로 받아서 이를 page 메타 데이터에 설정하고 다시 vm_do_claim_page를 호출합니다.
이때, page를 새로 만들 필요는 없고 spt에서 va가 할당된 페이지 구조체를 찾아서 vm_do_claim_page로 넘겨주면 됩니다.
시행착오
이때, 페이지 구조체가 메타 데이터라는 사실을 이해하지 못하고 역시나 이상한 구현을 했었습니다. palloc_get_page 결과를 page에 할당하는 대신, spt_find_page(spt, va)의 결과로 리턴된 페이지 포인터 변수를 할당해주고 이를 vm_do_claim_page로 넘겨주면 됩니다.
bool
vm_claim_page (void *va) {
struct page *page = NULL;
page = (struct page *) palloc_get_page(PAL_USER);
if (page == NULL)
{
return false;
}
return vm_do_claim_page (page);
}결과물
bool
vm_claim_page (void *va) {
struct page *page = NULL;
page = spt_find_page(&thread_current()->spt, va);
if (page == NULL)
{
return false;
}
return vm_do_claim_page (page);
}페이지 알아보기
Uninitialized Page, Anonymous Page, File backed Page가 다 뭐죠?
가상 메모리를 구현하기 위해서는 위의 세 가지 종류의 페이지가 구현돼야 합니다.
uninit page는 초기화되지 않은 페이지입니다.
anonymous page와 file backed page는 서로 상보적인 개념으로 보면 됩니다. 프로세스의 가상 메모리 공간을 봅시다.
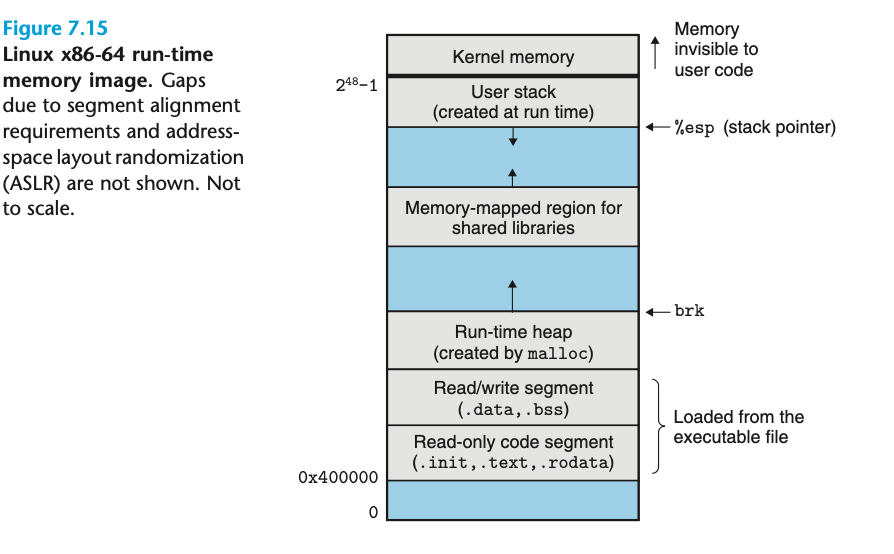
프로세스의 가상 메모리 공간을 보면, .data, .bss처럼 프로그램의 코드가 로드되는 영역이 있고, 함수 루틴에 따라 가변적으로 크기가 변하는 스택 영역이 있습니다. 이때 스택처럼 데이터의 출처 역할을 하는 파일이 필요 없는 경우 anonymous page, 필요한 경우 file backed page를 사용해야 합니다.
굳이 용도에 따라 페이지 구조체를 구분하는 이유는 뭔가요?
이런 구현으로 가장 이득을 볼 수 있는 부분은 lazy load 구현이 가능하다는 점입니다. lazy load기능이 있다면 필요한 데이터를 즉시 DRAM에 올리는 대신, 각 페이지별로 필요한 데이터를 어디서 얼마나 긁어올지 정보를 저장하기만 합니다. 그리고 페이지 폴트 발생 시 상대적으로 느린 디스크 IO 작업을 수행하며 데이터를 로드하죠. 만약 lazy load가 되지 않았다면 응용 프로그램을 수행한 즉시 램에 모든 프로그램의 데이터를 올려야 했을 겁니다.
페이지 구조체
페이지 구조체는 아래와 같이 구현돼 있습니다.
struct page {
const struct page_operations *operations;
void *va; /* Address in terms of user space */
struct frame *frame; /* Back reference for frame */
union {
struct uninit_page uninit;
struct anon_page anon;
struct file_page file;
};
};주목할 점은 union 구조체가 사용됐다는 점인데요, 그 안의 멤버들은 각각 uninitialized page, anoymous page, file ,backed page를 의미합니다. page 구조체는 이 union의 멤버 중 하나로 정의되고, 그에 따라 page_operations 함수 포인터가 결정됩니다. swap in/out, destroying을 수행하는 page operation이 페이지 종류에 따라 구체적인 동작이 다르기 때문에 이렇게 (객체 지향적으로) 구현된 것이죠. struct page가 부모 클래스, 나머지가 자식 클래스라고 생각하면 되겠습니다.
페이지 초기화와 관련한 의문점들
vm_anon_initializer와 vm_file_initializer의 역할은 무엇인가요?
위에서 살펴본 것처럼, page 구조체는 anon_page, file_page 처럼 구별되는 union 멤버를 가지고 있으며, uninit 페이지는 둘 중 하나로 형변환 될 수가 있습니다. 그때 각 union으로 초기화가 되는데, 이 union들은 서로 다른 페이지 구조체를 가지고 있죠. 이 페이지 구조체의 차이 때문에 서로 다른 initializer 함수를 사용해야 합니다.
위의 두 함수. vm_anon_initializer와 vm_file_initializer는 언제 호출되나요?
이 부분이 어려운데요, 기본적으로 페이지 폴트는 페이지의 종류를 고려하지 않고 발생합니다. 페이지 폴트 핸들러에게 페이지의 타입은 추상화가 됐다고 생각할 수 있겠죠. 이 추상화 덕분에 페이지 폴트 핸들러는 무조건 uninit_initializer를 호출합니다. 이때 uninit_initialize가 페이지의 타입에 따라 vm_anon_initializer 혹은 vm_file_initializer를 호출합니다.
lazy load는 어떻게 구현되나요?
이제 lazy load의 구현 방식에 대해 짚어봐야 합니다. 가상 메모리가 구현된 시점에는 페이지를 할당할 때 vm_page_alloc_with_initializer를 사용하여 새로운 페이지를 할당하는데요, 이때 ‘initializer’는 위에서 본 vm_anon_initializer / vm_file_initializer가 아니라 다른 종류의 초기화 함수를 가리킵니다. 그것이 lazy_load_segment같이 레이지 로딩을 수행해주는 루틴인데요, 이 함수의 주소를 함수의 인자값으로 쓸 구조체와 함께 페이지 할당 함수의 인자값으로 넘겨주어 필요할 때 언제든지 레이지 로딩 루틴을 수행할 수 있도록 합니다.
lazy_load_segment 같이 vm_page_alloc_with_initializer에 주어지는 함수와 위의 두 initializer의 차이는 무엇인가요?
그렇다면 이제 위 질문에 쉽게 대답할 수 있겠죠. 각 페이지 타입을 위한 초기화 함수와, 레이지 로딩과 같은 ‘특수한 목적’의 초기화를 위한 초기화 함수는 서로 다릅니다. 핀토스 구현 중에는 이름이 비슷해서 헷갈릴 수 있으니 주의가 필요합니다.
그렇다면 vm_page_alloc_with_initializer 함수의 초기화 함수 인수로 vm_anon_initializer를 준다면?
코드로 표현하면 아래와 같겠죠.
vm_page_alloc_with_initializer(Type=VM_ANON, init=vm_anon_initializer)
이건 완전 의미 없는 행동입니다. 함수 루틴 내에서 type을 보고 어떤 ‘페이지’ 초기화 함수를 써야 하는지는 다 알 수 있으니까요. 이때 init 자리에 들어가야 하는 함수는 lazy_load_segment처럼 특수한 목적의 함수들입니다.
vm_page_alloc_with_initializer는 주어진 타입을 보고 적절한 페이지 초기화 함수를 지정해서 uninit_new 함수에 넘겨줍니다. uninit_new 함수는 넘겨받은 페이지 초기화 함수를 페이지 구조체의 page_initializer 멤버로 포인터 복사하죠.
그렇다면 이 page_initializer는 언제 호출되는가요?
uninit_initializer가 호출합니다. 그리고 이 함수는 최초 페이지 폴트 발생 시 호출되어 uninit -> page_initializer를 호출, 이 루틴 내에서 프레임을 초기화할 때 ‘특수 목적의 초기화 함수’(lazy_load_segment 등)이 호출됩니다. 이런 특수 목적의 초기화 함수를 vm_initializer라고 하는데, 보시다시피 page initializer와 헷갈릴만하죠. 매우 주의가 필요합니다. (사실 왜 이렇게 이름을 비슷하게 해 놨는지 이해가 안 갑니다.)
lazy_load_segment 같은 특수 목적 초기화 함수는 처음에만 호출되면 끝인가요?
맞습니다. 그 이유가 뭘까요? 바로 스와핑 시스템 덕분입니다. DRAM이 가득 차서 새로 프레임을 할당하기 위해 스왑 아웃을 수행할 때 DRAM의 프레임은 이미 데이터가 다 로드된 상태(lazy load가 끝난 상태)이고, 이를 디스크로 그대로 내렸다가 페이지 폴트 발생 시 다시 SPT를 참조하여 DRAM으로 프레임을 복구하기 때문에 특수 목적 초기화 함수도 ‘여러 번’ 호출할 필요는 없습니다.
vm_alloc_page_with_initializer의 type 인수로 VM_UNINIT을 지정하면 어떻게 되나요?
그러면 안 됩니다. vm_alloc_pagae_with_initializer를 쓰는 목적은 본질적으로 가장 기초적인 형태의 프레임과 페이지 매핑을 uninit page라는 일관된 API로 수행한 후 운영체제 레벨의 특정한 목적에 따라 anon page 혹은 file page로 쓰기 위함입니다. 따라서 uninit page 그 자체는 쓸모가 없고, 이것을 결국 무슨 목적으로 할당하는지 vm_alloc_page_with_initializer에 명시해줘야 하는데 VM_UNINIT을 주는 것은 마치 어린이의 장래 희망을 ‘어린이’로 주는 것과 같죠. 무조건 VM_ANON 혹은 VM_FILE로 타입을 지정해야 합니다.
총 정리
지금까지 페이지의 초기화 과정을 살펴봤습니다. 저는 가상 메모리를 구현하면서 이 초기화 과정을 크게 지정과 실행 두 부분으로 나누어 볼 수 있다고 생각했습니다. 아래처럼요.
- 지정: vm_alloc_page_with_initializer에서 수행
- 페이지의 타입을 지정: anon_page인지 file_page인지.
- 지정된 타입으로 page initializer 지정
- 만약 주어졌다면 vm_initializer(특수 목적 초기화 함수) 지정
- 수행: 첫 페이지 폴트 발생 시
- uninit_initialize가 수행되며 아래 루틴들을 수행
- VM_TYPE에 따라 넘겨받은 page initializer를 수행, page operations(swap in/out, destroy) 지정
- vm_initializer가 존재한다면 수행
Growing Stack 구현하기
문제
프로세스의 스택에 대해 생각해 봅시다. 모든 프로세스는 스택을 가지고 있죠. 함수가 호출 될 때마다 call stack이 성장합니다. 그렇다면 여기서 한 가지 질문을 던질 수 있죠. 콜 스택은 어디까지 성장할 수 있을까요?
콜 스택도 결국 페이지로 구성돼 있습니다. 만약 페이지가 하나밖에 할당되지 않았고, 또 추가적인 페이지 할당을 구현하지 않았다면 콜 스택은 페이지 하나 크기인 4KB에 한정되겠죠. 제법 작은 숫자입니다. 함수가 복잡하고, 호출이 많아지고, 인자값이 많아지면 4096 바이트는 금방 소진되겠죠.
따라서 스택의 성장을 구현해야 합니다. 스택에 현재 페이지 사이즈를 넘어선다면 새로운 페이지를 할당해줘서요.
그렇다면 언제 어떻게 할당해주면 될까요? 우선 ‘언제’의 문제는 다른 페이지 할당과 같습니다. 페이지 폴트가 발생하면 할당하면 됩니다. 그렇다면 ‘어떻게’의 문제도 간단하죠. anon page 타입으로 uninit 페이지를 하나 할당해서 spt에 저장하도록 핸들러 루틴을 처리하면 됩니다. 그런데 여기서 중요한 점이 하나 있습니다.
페이지 폴트 핸들러가 어떻게 이것이 ‘스택 할당’에 필요한 페지 폴트 처리인지 판단할 수 있을까요? 페이지 폴트는 하드웨어적으로 발생하죠. 따라서 PTE에 적절한 가상 주소 값 매핑이 없다면 기계적으로 발생할 뿐입니다. 힌트는 여기에 있죠. 페이지 폴트가 발생한 가상 주소 위치가 스택 포인터(%rsp)의 근처라면 스택 성장으로 판단하면 됩니다. 이때 중요한 점은, x86-64 아키텍처는 rsp를 조작할 때 항상 rsp 위치의 8바이트 아래를 먼저 참조해서 페이지 폴트가 발생하는지 검증한다는 사실입니다. 따라서 커널은 이를 이용해 페이지 폴트 발생 지점이 rsp의 8바이트 아래일 경우 스택 성장으로 처리할 수 있습니다.
설계 구상
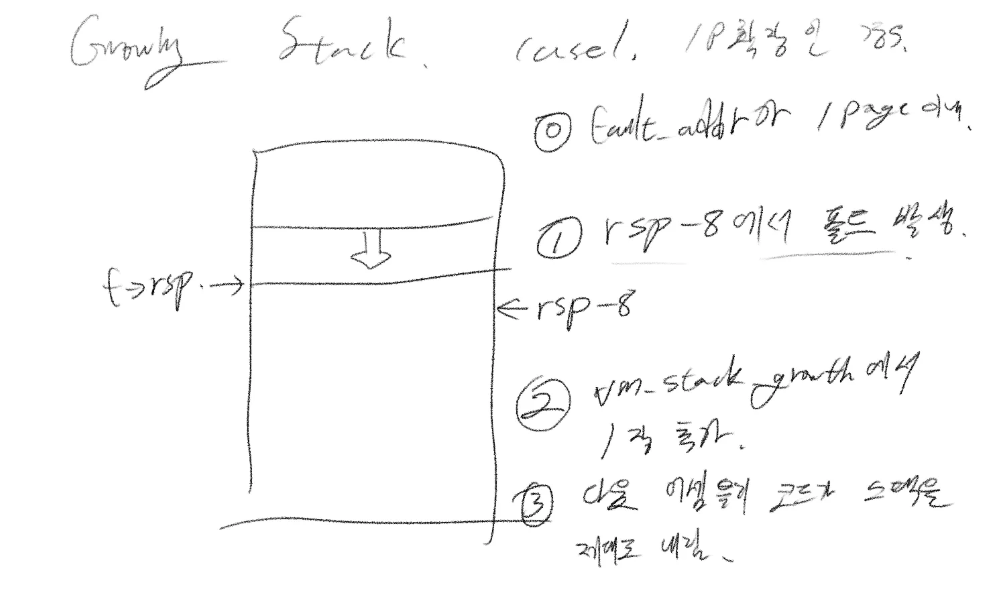
초기 구상은 위와 같았습니다. 이때 제가 파악했던 스택 성장의 매커니즘은 다음과 같죠.
- rsp의 8바이트 아래서 폴트 발생.
- 폴트 핸들러가 vm_stack_growth를 호출해서 페이지 1장 추가.
- 스택 포인터가 제대로 갱신, 성장 처리 완료
따라서 스택 성장을 판단할 때 다음 로직을 사용헀었습니다.
addr == rsp - 8
하지만 이 경우 문제가 있습니다.
시행착오
위의 초기 설계 구상에서는 스택이 무조건 한 페이지 이내로 성장한다는 전제가 깔려 있습니다. 하지만, 스택 포인터는 2장 이상의 페이지 영역을 한번에 가로질러 확장될 수도 있습니다. 그렇게 될 경우 위의 로직으로는 다음과 같은 흐름으로 이어집니다.
- rsp - 8에서 폴트 발생
- 페이지를 한 장만 할당하고 폴트 처리를 끝냄
- rsp는 두 장 이상의 페이지 영역만큼 주소가 내려간 상태이고, 운영체제는 스택 포인터와 스택 베이스 사이의 모든 페이지가 할당됐을 거라 기대
- 하지만 한 장만 할당됐기 때문에 다음 페이지를 참조 시 또다시 페이지 폴트 발생
- 이때 폴트 주소는 스택 포인터의 검증 절차와 무관하게, 그냥 rsp 위에서 발생.
- 페이지 폴트 처리 못하고 exit(-1)로 프로세스 비정상 종료
따라서 정상적인 스택 성장을 구현하기 위해서는 addr == rsp - 8로는 부족하고, 스택 베이스(USER_STACK)와 스택 포인터(rsp) 사이에 있는지 검사해야 합니다.

2페이지 이상 사이즈로 스택 성장한 경우 위와 같은 매커니즘으로 별도의 분기를 생각해줘야 했던 겁니다.
따라서 아래와 같은 로직으로 정상적인 구현이 가능했죠.
if (addr >= rsp - 8 && addr < USER_STACK && addr >= STACK_MAX)
STACK_MAX는 스택의 최대 크기를 설정한 매직 넘버입니다. 크게 중요하지 않습니다.
결과물
bool vm_try_handle_fault(struct intr_frame *f, void *addr,
bool user, bool write, bool not_present)
{
struct supplemental_page_table *spt = &thread_current()->spt;
if (not_present)
{
struct page *page;
void *rsp = user ? f->rsp : thread_current()->rsp;
if (addr >= rsp - 8 && addr < USER_STACK && addr >= STACK_MAX)
{
vm_stack_growth(pg_round_down(addr));
return true;
}
else
{
page = spt_find_page(spt, addr);
if(page == NULL)
{
return false;
}
return vm_do_claim_page(page);
}
}
else
{
return false;
}
}
위에서 호출되는 vm_stack_growth 함수도 같이 보겠습니다.
static void
vm_stack_growth(void *addr)
{
bool result = vm_alloc_page_with_initializer(VM_ANON | VM_MARKER_STACK, addr, true, NULL, NULL);
vm_claim_page(addr);
}역시나 익명 페이지로 uninit page를 할당하는 모습을 볼 수 있군요! 저는 VM_MARKER_STACK을 마킹해놓고 로직에 적극적으로 사용하지 못했는데, 위에서 고안했던 스택 성장 판단 로직에 이를 활용하면 더 철저한 검증이 가능할 거 같습니다.
mmap 구현
file-backed page가 뭔가요?
file-backed page는 memory mapped page라고도 하며, 따로 참조하는 값이 없는 anonymous page와 달리 파일의 데이터를 복사하는 페이지입니다. 중요한 점은 이렇게 매핑 된 file-backed page에서 변화가 생긴 상태에서 swap out이 발생하거나 매핑 해제될 경우 그 변화가 그대로 파일에도 반영된다는 사실입니다.
그 외에도 구현 상에 가졌던 의문 사항을 아래와 같이 정리했습니다.
파일의 사이즈가 PGSIZE(4KB) 이상인 경우 연속된 file page 간의 리스트를 관리해야 하나요?
네.
연속된 페이지가 하나의 파일로 매핑됐고, munmap할 때 주어진 addr이 이 연속 페이지의 중간 페이지를 가리킨다면 이 페이지만 해제하나요? 또, addr이 연속 페이지의 첫 페이지를 가리킨다면 페이지 전체를 해제하나요?
이 부분은 다행히도, munmap의 인자값으로 주어지는 페이지가 항상 매핑된 페이지의 첫 번째 요소라는 제약 조건이 있습니다. 항상 전체 페이지를 해제하도록 해야 하고요. addr도 파일 페이지의 첫 시작 주소로 주어져야 하고, 이를 쓰레드가 검증할 수 있도록 매핑 된 페이지의 리스트를 관리해야 합니다.
문제
mmap/munmap 구현을 통한 file page 기능을 구현하기 위해 아래와 같은 함수들을 구현해야 합니다.
- mmap: 열고 있는 파일을 주어진 주소에 특정 사이즈만큼 매핑.
- munmap: 주어진 주소부터 시작하는 매핑된 페이지들을 매핑 해제.
- vm_file_init: 부팅 중 한 번 호출되는 시스템 초기화 함수.
- file_backed_initializer: file backed page의 초기화 함수
- file_backed_destroy: 제거 함수.
설계 구상 및 시행착오
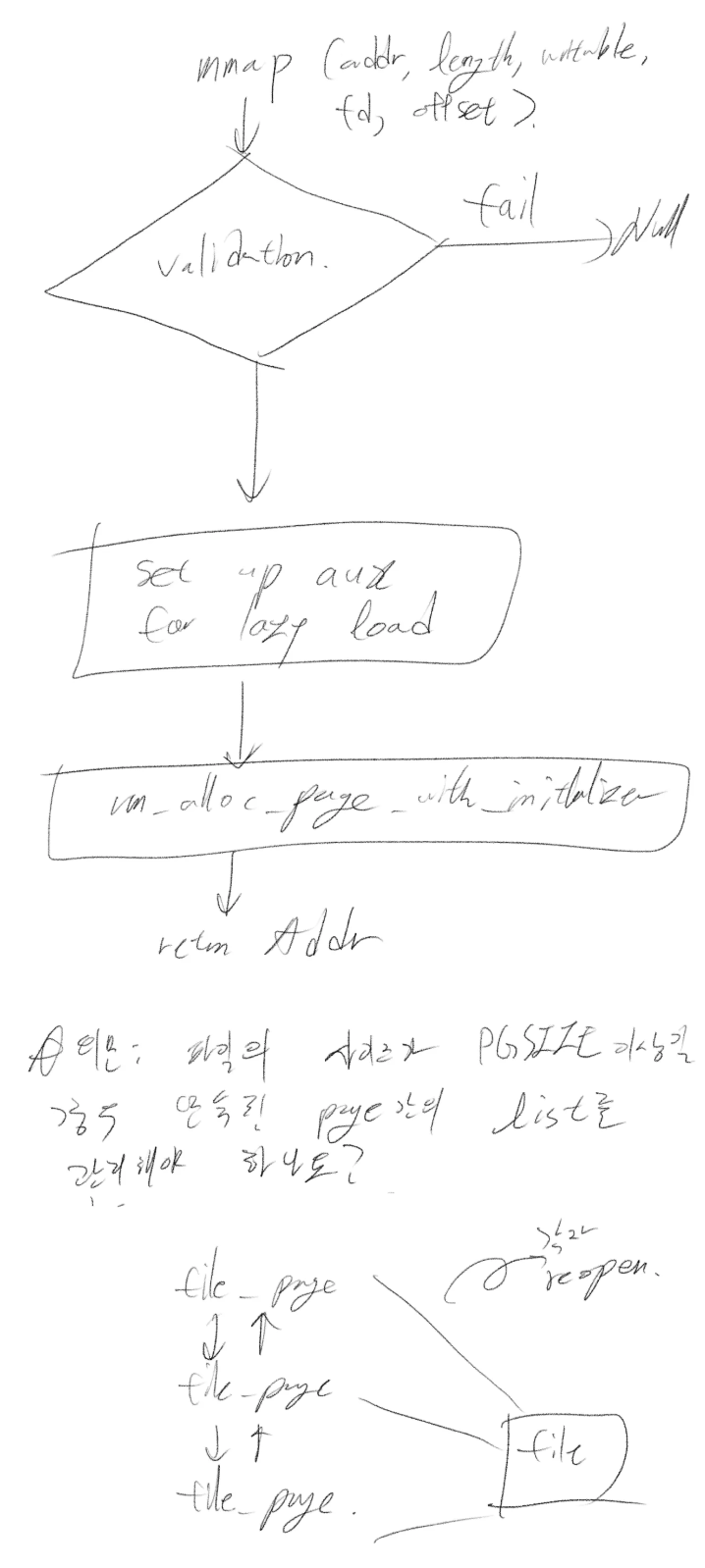
가장 먼저 그렸던 그림입니다. 인자 값으로 주어진 것들을 검증하고, 파일 데이터를 레이지 로딩하기 위한 인자값을 설정한 후 vm_alloc_page_with_initializer에 레이지 로딩 함수 포인터와 함께 넘겨준다는 흐름을 파악하기 위해 그렸습니다. 여기서 나온 레이지 로딩 함수는 anonymous page의 그것과는 따로 구현해야 합니다.
그렇다면 이제 궁금한 점은 주어진 파일을 페이지에 실제로 '어떻게' 복사해야 하느냐 인데요, 그 점은 아래 그림을 통해 구체화했습니다.
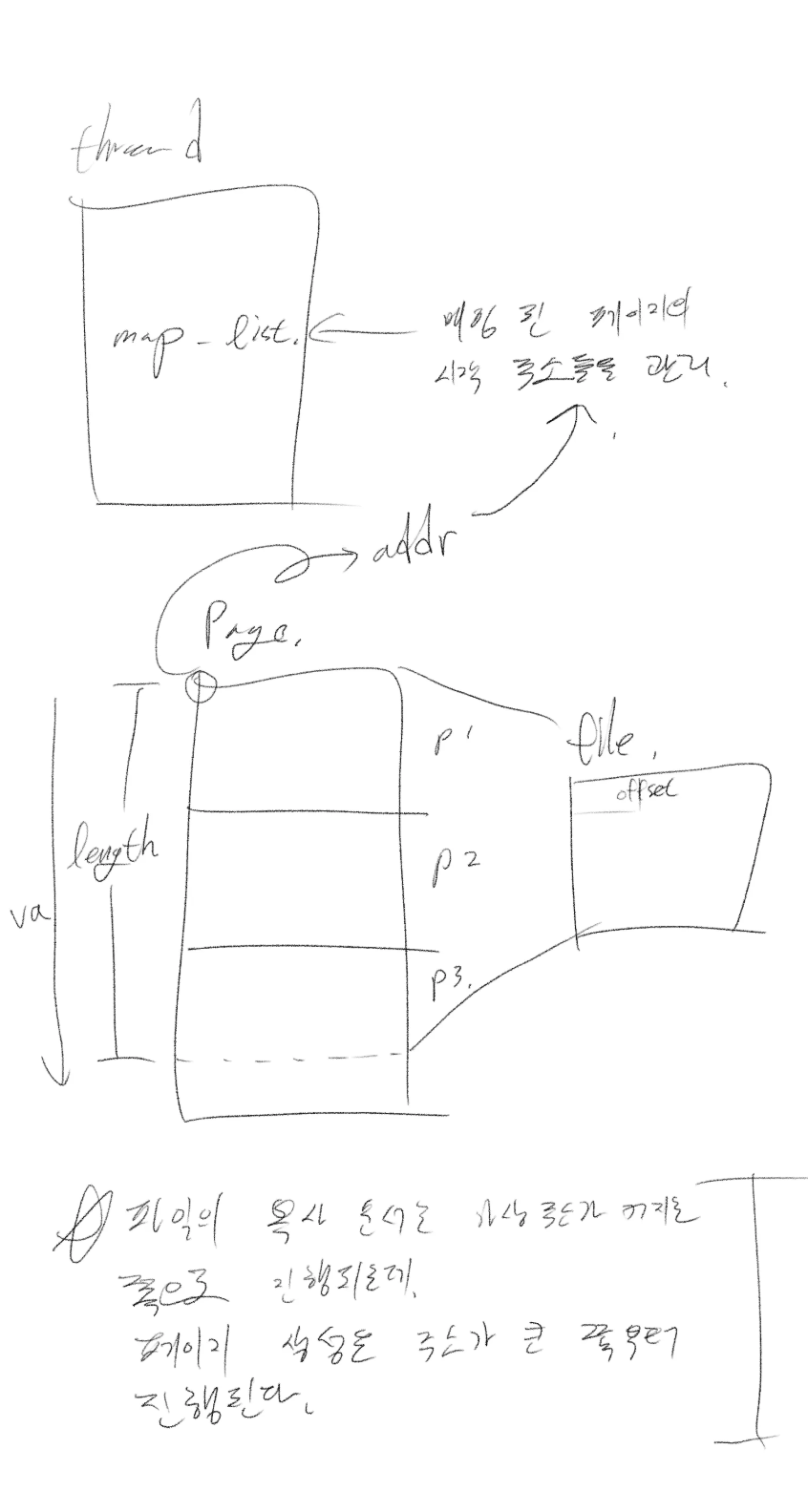
이때, 데이터 복사 순서와 달리 페이지 생성은 주소가 작아지는 방향으로 진행된다는 점이 가장 헷갈리는 포인트였습니다. 실시간으로 페이지를 할당하면서 매핑을 한다면, 결국 아래 그림처럼 가장 낮은 주소의 페이지에는 파일의 마지막 일부가 복사될텐데, 그게 운영체제 입장에서는 되게 난해한 매핑일테니까 말이죠.
(그림에서 p3 > p2 > p1 순으로 주소 값이 크고, p3 -> p2 -> p1 순으로 페이지가 할당됩니다.)
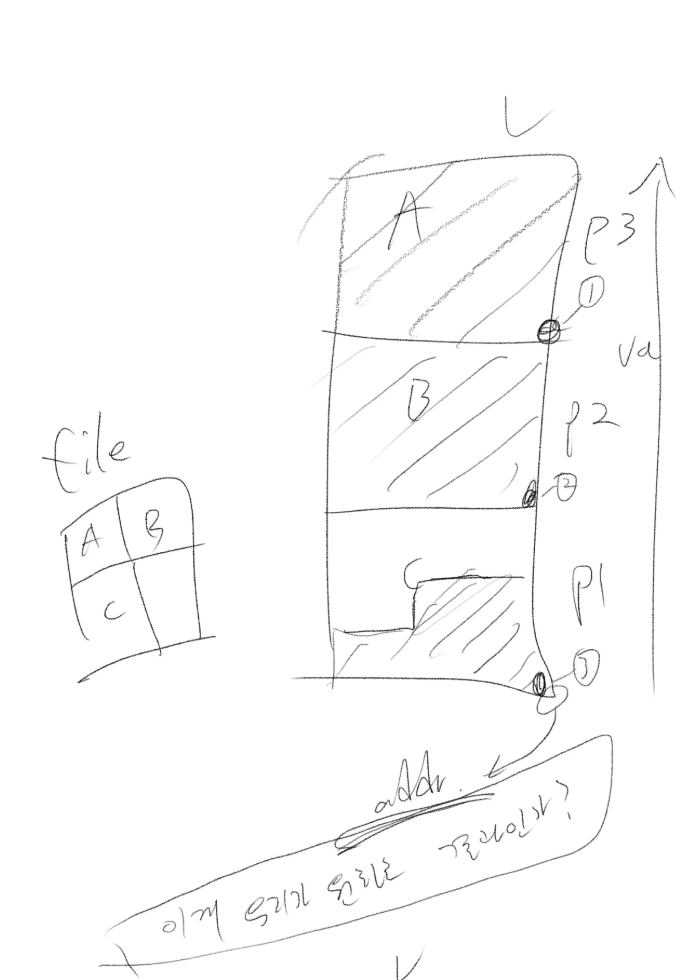
하지만 바로바로 페이지를 할당한다는 생각을 접으면, 이렇게 직관적인 매핑을 구현할 수 있습니다. 그리고 이것이 가능한 이유는, 레이지 로딩 덕분이죠.
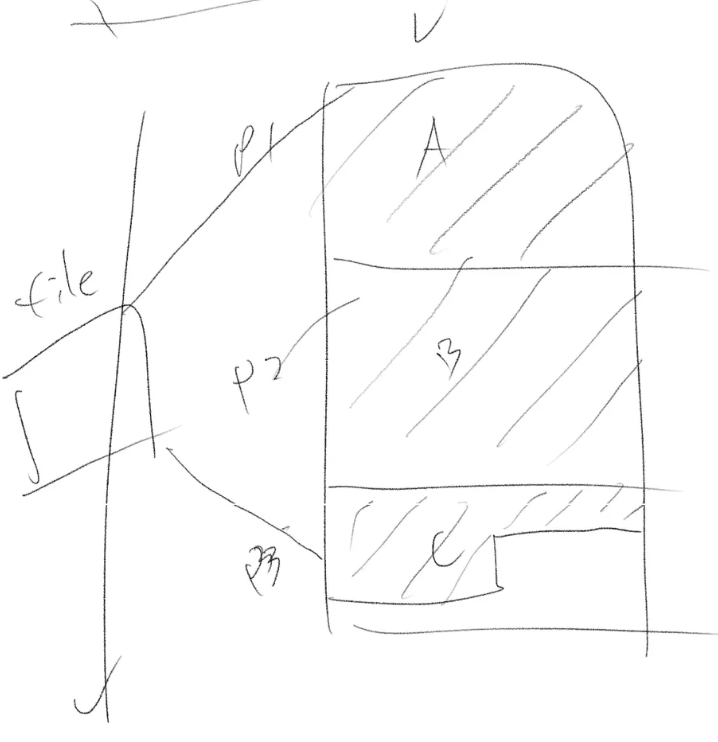
그러니까 아래 사실을 활용하는 것이 아주 중요합니다.
file backed page의 데이터 실제 복사는 lazy load 호출 시점이다!
결과물
로직이 복잡했기 때문에 손코딩을 하고 이리저리 검증을 하며 구현을 했습니다.

작성된 코드는 아래와 같습니다. 코드의 많은 부분이 lazy load 수행을 위한 적절한 인자값 전달에 할애된 모습을 볼 수 있습니다.
void *
do_mmap(void *addr, size_t length, int writable, struct file *file, off_t offset)
{
struct file *re_file = file_reopen(file);
size_t filesize = file_length(file);
size_t file_read_bytes = filesize < length ? filesize : length;
size_t file_zero_bytes = PGSIZE - (file_read_bytes % PGSIZE);
void *original_addr = addr;
for (off_t current_off = offset; file_read_bytes > 0; )
{
size_t page_read_bytes = file_read_bytes > PGSIZE ? PGSIZE : file_read_bytes;
size_t page_zero_bytes = PGSIZE - page_read_bytes;
struct lazy_aux_file_backed *aux = malloc(sizeof(struct lazy_aux_file_backed));
aux->file = re_file;
aux->length = page_read_bytes;
aux->offset = current_off;
if (!vm_alloc_page_with_initializer(VM_FILE, addr, writable, lazy_load_file_backed, aux))
{
return NULL;
}
current_off += page_read_bytes;
addr += PGSIZE;
file_read_bytes -= page_read_bytes;
file_zero_bytes -= page_zero_bytes;
}
return original_addr;
}트러블슈팅: mmap 구현 오류
이제 mmap을 구현 하면서 트러블슈팅을 했던 부분들을 살펴보려 합니다. 아래 코드에서 어떤 부분이 잘못일까요?
틀린 코드
void *mmap (void *addr, size_t length, int writable, int fd, off_t offset)
{
struct thread *curr = thread_current();
if (addr == NULL || length == 0 || fd == 0 || fd == 1 || (uint64_t) addr % 4096 != 0 || spt_find_page(&curr->spt, addr)) {
return NULL;
}
struct file *file = open(curr->fd_table[fd])
sema_down(&filesys_lock);
void *upage = do_mmap(addr, length, writable, file, offset);
sema_up(&filesys_lock);
return upage;
}틀린 이유
오류를 일으킨 부분은 struct file *file = open(curr->fd_table[fd])입니다. mmap을 수행하는 시점에 fd를 넘겨주는데, 이 말인 즉슨 이미 fdt에 파일이 열린 상태로 할당돼 있고, mmap 루틴에서는 그냥 fdt에서 파일 구조체를 가져와서 do_mmap의 인자값으로 file 메타 데이터를 넘겨주면 된다는 말이죠. 굳이 여기서 open을 수행할 필요도 없거니와, open(curr->fd_table[fd])는 결과적으로 open( FILE_STRUCT)를 수행하기 때문에 open에 파일 이름이 아닌 잘못된 인자값을 넘겨주어 오류를 일으키게 됩니다.
정답 코드
아래와 같이 fd를 활용해 파일 구조체를 적절히 획득할 수 있는 코드로 변경하면 됩니다.
void *mmap (void *addr, size_t length, int writable, int fd, off_t offset)
{
struct thread *curr = thread_current();
if (addr == NULL || length == 0 || fd == 0 || fd == 1 || (uint64_t) addr % 4096 != 0 || spt_find_page(&curr->spt, addr)) {
return NULL;
}
struct file *file = process_get_file_by_fd(fd);
sema_down(&filesys_lock);
void *upage = do_mmap(addr, length, writable, file, offset);
sema_up(&filesys_lock);
return upage;
}트러블슈팅: spt copy 함수
이 함수는 페이지에 대한 멘탈 모델을 제대로 잡고 있지 않으면 제대로 구현할 수 없습니다. 아래의 틀린 코드를 보시면, 전반적으로 문제가 많음을 볼 수 있습니다.
틀린 코드
bool supplemental_page_table_copy(struct supplemental_page_table *dst,
struct supplemental_page_table *src)
{
struct hash_iterator i;
hash_first(&i, &src->hash);
while (hash_next(&i))
{
struct page *src_page = hash_entry(hash_cur(&i), struct page, hash_elem);
enum vm_type type = page_get_type(src_page);
void *upage = src_page->va;
// 1. 새로운 페이지를 dst SPT에 할당
if (!vm_alloc_page_with_initializer(type, upage, src_page->writable,
src_page->uninit.init, src_page->uninit.aux))
{
return false;
}
// 2. 새로 할당된 페이지를 찾고 claim
struct page *dst_page = spt_find_page(dst, upage);
if (!vm_claim_page(upage))
{
return false;
}
// 3. 부모의 프레임이 존재하면, 자식의 프레임으로 데이터 복사
if (src_page->frame != NULL)
{
memcpy(dst_page->frame->kva, src_page->frame->kva, PGSIZE);
}
}
return true;
}틀린 이유
전반적으로 문제가 많은 코드라서 굳이 어디를 틀렸다고 짚기가 어렵습니다. 하지만 한 가지로 좁혀서 설명한다면 이렇게 말하겠습니다.
페이지의 타입은 미래의 가능성까지 고려해야 한다.
무슨 말이냐면, 만약 SPT에서 복사를 하려는 페이지가 VM_FILE / VM_ANON이라면 이 둘은 그냥 단순히 데이터만 복사해서 새로 할당한 프레임에 저장하면 될 겁니다. 하지만 만약 VM_UNINIT이라면 어떻게 해야 할까요? uninit page들은 미래에 VM_FILE이나 VM_ANON 둘 중 하나로 초기화가 다시 될 것이고, 그에 따라 필요한 초기화 루틴, 그 루틴의 인수 값이 모두 다릅니다. 따라서 이 모든 경우를 고려한 분기가 필요합니다.
틀린 코드와 정답 코드의 핵심적인 차이는 이 부분이었습니다.
정답 코드
bool supplemental_page_table_copy(struct supplemental_page_table *dst,
struct supplemental_page_table *src)
{
struct hash_iterator i;
hash_first(&i, &src->hash);
while (hash_next(&i))
{
struct page *src_page = hash_entry(hash_cur(&i), struct page, hash_elem);
enum vm_type type = page_get_type(src_page);
if (type == VM_UNINIT)
{
struct uninit_page uninit_page = src_page->uninit;
enum vm_type future_type = uninit_page.type;
if (future_type == VM_ANON)
{
struct lazy_aux *new_aux = malloc(sizeof(struct lazy_aux));
*new_aux = *(struct lazy_aux *)uninit_page.aux;
if (!vm_alloc_page_with_initializer(
future_type,
src_page->va,
src_page->writable,
uninit_page.init,
new_aux))
{
return false;
}
struct page *dst_page = spt_find_page(&thread_current()->spt, src_page->va);
if (!vm_claim_page(dst_page))
{
return false;
}
}
else if (future_type == VM_FILE)
{
struct lazy_aux_file_backed *new_aux = malloc(sizeof(struct lazy_aux_file_backed));
struct lazy_aux_file_backed *prev_aux = (struct lazy_aux_file_backed *)uninit_page.aux;
*new_aux = *prev_aux;
lock_acquire(&filesys_lock);
new_aux->file = file_reopen(prev_aux->file);
lock_release(&filesys_lock);
ASSERT(new_aux->file != NULL);
if (!vm_alloc_page_with_initializer(
future_type,
src_page->va,
src_page->writable,
uninit_page.init,
new_aux))
{
return false;
}
struct page *dst_page = spt_find_page(&thread_current()->spt, src_page->va);
if (!vm_claim_page(dst_page))
{
return false;
}
}
}
else
{
vm_alloc_page(type, src_page->va, src_page->writable);
struct page *dst_page = spt_find_page(&thread_current()->spt, src_page->va);
if (!vm_claim_page(dst_page->va))
{
return false;
}
else if (src_page->frame != NULL && src_page->frame->kva != NULL)
{
memcpy(dst_page->frame->kva, src_page->frame->kva, PGSIZE);
}
}
}
return true;
}트러블슈팅: spt copy 함수 2
이미 supplemental_page_table_copy의 옳은 예시를 보았습니다. 하지만 틀린그림 찾기를 한 번 해보도록 하죠. 아래 코드에는 미묘한 조건 하나가 빠져 있습니다.
틀린 코드
bool supplemental_page_table_copy(struct supplemental_page_table *dst,
struct supplemental_page_table *src)
{
struct hash_iterator i;
hash_first(&i, &src->hash);
while (hash_next(&i))
{
struct page *src_page = hash_entry(hash_cur(&i), struct page, hash_elem);
enum vm_type type = page_get_type(src_page);
if (type == VM_UNINIT)
{
struct uninit_page uninit_page = src_page->uninit;
enum vm_type future_type = uninit_page.type;
if (future_type == VM_ANON)
{
struct lazy_aux *new_aux = malloc(sizeof(struct lazy_aux));
*new_aux = *(struct lazy_aux *)uninit_page.aux;
if (!vm_alloc_page_with_initializer(
future_type,
src_page->va,
src_page->writable,
uninit_page.init,
new_aux))
{
return false;
}
struct page *dst_page = spt_find_page(&thread_current()->spt, src_page->va);
if (!vm_claim_page(dst_page))
{
return false;
}
}
else if (future_type == VM_FILE)
{
struct lazy_aux_file_backed *new_aux = malloc(sizeof(struct lazy_aux_file_backed));
struct lazy_aux_file_backed *prev_aux = (struct lazy_aux_file_backed *)uninit_page.aux;
*new_aux = *prev_aux;
lock_acquire(&filesys_lock);
new_aux->file = file_reopen(prev_aux->file);
lock_release(&filesys_lock);
ASSERT(new_aux->file != NULL);
if (!vm_alloc_page_with_initializer(
future_type,
src_page->va,
src_page->writable,
uninit_page.init,
new_aux))
{
return false;
}
struct page *dst_page = spt_find_page(&thread_current()->spt, src_page->va);
if (!vm_claim_page(dst_page))
{
return false;
}
}
}
else
{
vm_alloc_page(type, src_page->va, src_page->writable);
struct page *dst_page = spt_find_page(&thread_current()->spt, src_page->va);
if (!vm_claim_page(dst_page->va))
{
return false;
}
else if (src_page->frame->kva != NULL)
{
memcpy(dst_page->frame->kva, src_page->frame->kva, PGSIZE);
}
}
}
return true;
}틀린 이유
정답을 공개하도록 하죠.
else if (src_page->frame->kva != NULL) // X
else if (src_page->frame != NULL && src_page->frame->kva != NULL) // O복사하려는 페이지의 프레임 주소가 NULL인지 검사하기 전에 frame 메타 데이터가 존재하는지 검사하는 로직이 꼭 있어야 합니다. 왜 이 로직이 필요할까요? 이 분기가 존재하는 영역은 아래와 같습니다.
else // src_page의 타입이 VM_ANON / VM_FILE인 분기.
{
vm_alloc_page(type, src_page->va, src_page->writable);
struct page *dst_page = spt_find_page(&thread_current()->spt, src_page->va);
if (!vm_claim_page(dst_page->va))
{
return false;
}
else if (src_page->frame->kva != NULL)
{
memcpy(dst_page->frame->kva, src_page->frame->kva, PGSIZE);
}
}
}
return true;이 분기를 탔다면, 페이지의 타입은 uninit이 아니라 이미 초기화가 끝난 페이지들이죠. 페이지를 복제하기 위해 페이지를 할당하고, 프레임을 할당하고, 최종적으로 소스 프레임에서 새로 복제한 프레임에 데이터를 복제합니다(memcpy). 이때, 근원 페이지의 프레임이 애초에 없을 수도 있는데 이에 대한 예외 처리가 안 돼 있으면 처리할 수 없는 페이지 폴트가 발생하게 되는 거죠. (지금 다시 보니 프레임 유효성 검사를 더 일찍 하는게 나았을 거라는 생각이 들긴 합니다. 하지만 이렇게 포인터를 중복 참조할 경우 이전 요소가 유효한지 검사하는 코드 습관이 아주 중요함을 알 수 있었습니다.)
정답 코드
정답 코드는 이미 보았으니 생략하겠습니다.
스와핑
메모리 스와핑이 뭔가요?
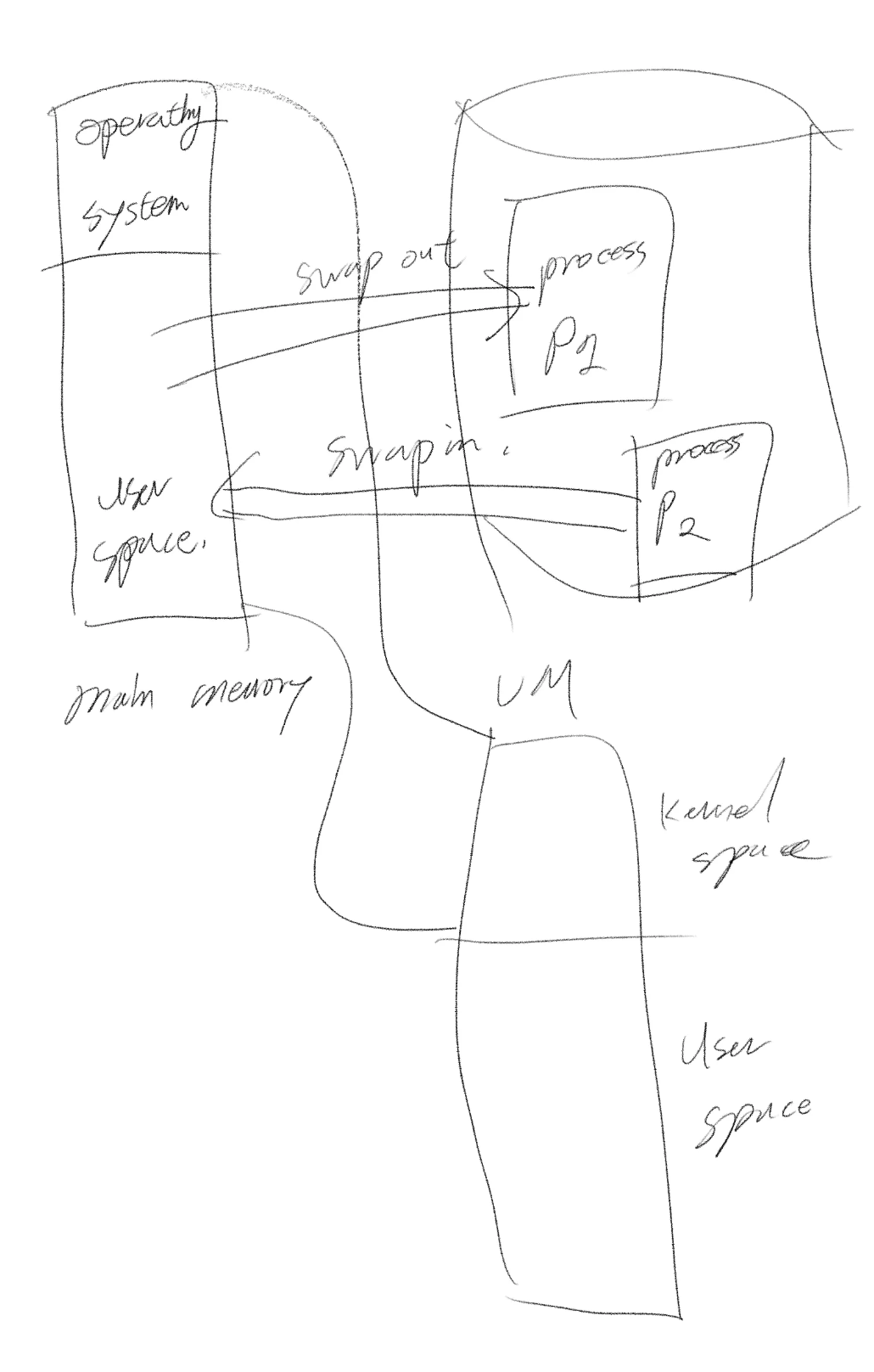
메모리 스와핑은 물리 메모리 사용성을 최대화하기 위한 메모리 재획득 기술입니다. 스와핑이 없는 경우를 상상해보죠. 이때 메인 메모리의 프레임들이 모두 할당됐다면, 시스템은 유저 프로그램으로부터 더 많은 메모리 할당 요청이 와도 처리해 줄 수가 없습니다. 해결책은 스왑 아웃입니다. 사용중이지 않은 메모리 프레임들을 디스크로 내보내는 기술이죠. 이를 통해 메모리 자원을 해제하고, 다른 어플리케이션이 사용할 수 있게 만듭니다.
스와핑의 메커니즘
스와핑은 운영체제가 수행합니다. 시스템이 메모리가 없는 상태에 메모리 할당 요청을 받게 스왑 디스크로 내보낼 페이지를 선택합니다. 그리고 그 페이지의 프레임을 디스크로 카피합니다.
만약 프로세스가 스왑 아웃 돼버린 페이지로 접근하려 하면, 운영체제는 정확한 내용을 메모리로 다시 가져옴으로써 페이지를 복구합니다. 내보내기로 선택된 페이지는 anon page일 수도 있고, file page일 수도 있습니다.
여기서 중요한 분기를 인식해야 합니다. anon page는 file page와 달리 따로 '뒷받침' 되는 저장소가 없습니다. anon page의 스와핑을 지원하기 위해서 따로 스왑 디스크를 마련해야 합니다. 반면, file page의 경우는 훨씬 쉽습니다. 파일 시스템을 활용하여 파일에 프레임 데이터를 반영시키기만 하면 스왑 아웃을 수행할 수 있습니다.
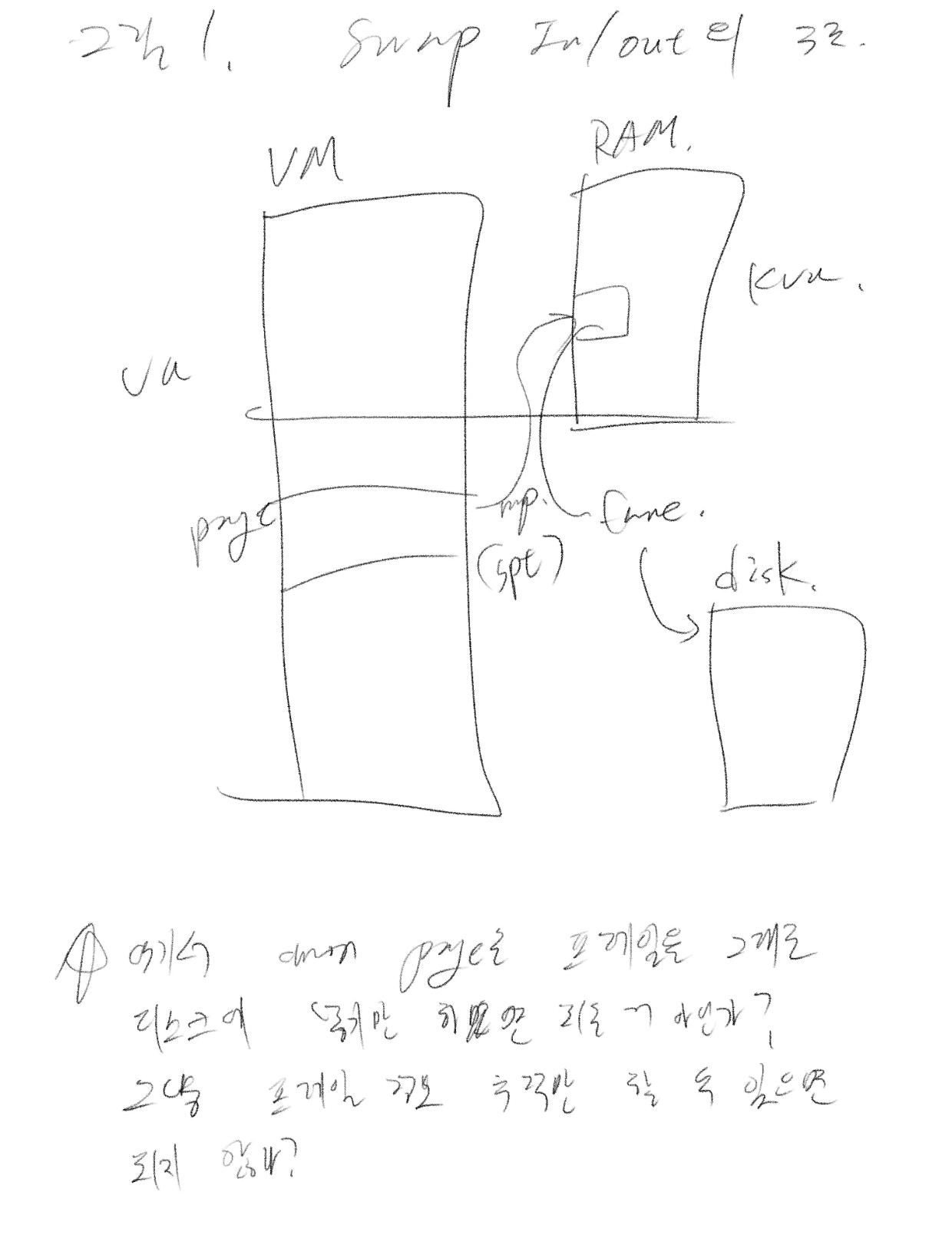
구현을 위한 자료구조
스와핑을 구현하기 위해서 필요한 자료구조들이 있습니다. 먼저 스왑 슬롯이 있습니다.
스왑 슬롯은 스왑 아웃 된 프레임을 저장하기 위한 공간입니다. 디스크에 있는 스왑 파티션의 페이지 크기의 각 영역이죠. 하드웨어 제약 상으로는 프레임 단위보다 자유롭게 슬롯의 위치를 가리킬 수 있지만, 정렬하는 것이 나쁠게 없기 때문에 페이지 단위로 정렬하도록 합니다.
다음으로는 프레임 테이블이 있습니다. 프레임 테이블의 본질적인 목적은 프레임을 스왑시킬 때 선택하기 위한 큐입니다. 이 테이블에 적용된 정책에 따라 스왑 아웃이 수행될 수 있겠죠. 저는 FIFO를 적용하여 간단히 구현했습니다.
마지막으로 스왑 테이블이 있습니다. 스왑 슬롯의 사용을 추적하는 용도이며, 비트 마스킹으로 구현할 수 있습니다.
설계 구상
이제 기본적인 스와핑의 구조를 봅시다.
결과물
멘탈 모델만 제대로 잡혀 있다면 아래와 같이 간단하게 작동하는 코드를 구현할 수 있습니다.
file page의 스와핑
/* Swap in the page by read contents from the file. */
static bool
file_backed_swap_in(struct page *page, void *kva)
{
struct file_page *file_page = &page->file;
lock_acquire(&filesys_lock);
file_read_at(file_page->file, page->va, file_page->size, file_page->file_ofs);
lock_release(&filesys_lock);
return true;
}
/* Swap out the page by writeback contents to the file. */
static bool
file_backed_swap_out(struct page *page)
{
struct file_page *file_page = &page->file;
writeback(page);
pml4_clear_page(thread_current()->pml4, page->va); // 물리 매핑을 해제
return true;
}
anon page의 스와핑은 아래와 같이 구현할 수 있습니다. 이때, kva의 역할은 무엇일까요? 정답은 ‘이미 결정된 메모리 주소’입니다. anon_swap_in은 직접적인 데이터 복사를 수행하는 루틴이므로 필요한 메모리 주소에 disk_read를 수행합니다. kva는 spt의 가상주소:물리주소 매핑을 통해 얻을 수 있겠죠?
static bool
anon_swap_in(struct page *page, void *kva)
{
struct anon_page *anon_page = &page->anon;
if (anon_page->swap_index == -1)
{
return false;
}
uint64_t swap_index = anon_page->swap_index;
for (int i = 0; i < SECTORS_PER_PAGE; i++)
{
disk_read(swap_disk, swap_index * SECTORS_PER_PAGE + i, kva + i * DISK_SECTOR_SIZE);
}
bitmap_set(swap_table, swap_index, false);
anon_page->swap_index = -1;
return true;
}
static bool
anon_swap_out(struct page *page)
{
struct anon_page *anon_page = &page->anon;
size_t page_num = bitmap_scan(swap_table, 0, 1, false);
if (page_num == BITMAP_ERROR)
{
return false;
}
for (int i = 0; i < SECTORS_PER_PAGE; i++)
{
disk_write(swap_disk, page_num * SECTORS_PER_PAGE + i, page->frame->kva + i * DISK_SECTOR_SIZE);
}
bitmap_set(swap_table, page_num, true);
anon_page->swap_index = page_num;
pml4_clear_page(thread_current()->pml4, page->va);
page->frame = NULL;
return true;
}트러블슈팅: anon swap in 구현
틀린 코드
static bool
anon_swap_in(struct page *page, void *kva)
{
struct anon_page *anon_page = &page->anon;
if (anon_page->swap_index == -1)
{
return false;
}
uint64_t swap_index = anon_page->swap_index;
for (int i = 0; i < SECTORS_PER_PAGE; i++)
{
disk_read(swap_disk, swap_index * SECTORS_PER_PAGE + i, kva + i * DISK_SECTOR_SIZE);
}
bitmap_set(swap_table, swap_index, false);
pml4_set_page(thread_current()->pml4, page->va, kva, page->writable);
anon_page->swap_index = -1;
return true;
}틀린 이유
이 코드에는 앞서 살펴봤든 코드와 다른 점이 한 줄 추가됐습니다. swap in을 수행하고 나서, 아래 코드를 통해 페이지 테이블 엔트리를 설정하는데요, 페이지 테이블 정보가 갱신됐기 때문에 여기서 pml4를 업데이트 해줘야 한다고 생각했었습니다.
pml4_set_page(thread_current()->pml4, page->va, kva, page->writable);
하지만 이 코드는 중복입니다. 함수의 추상화 레벨을 생각했을 때, anon_swap_in은 철저히 anon page의 프레임 복사만 수행하게 하는게 적절하고, 페이지 테이블 엔트리 업데이트는 anon page, file page를 가리지 않고 vm_do_claim_page()에서 수행해주는 것이 적절합니다.
정답 코드
정답 코드는 이미 보았으므로 생략하겠습니다.
