비선형 자료구조
비선형 자료구조 : 일렬로 나열하지 않고 자료 순서, 관계가 복잡한 구조
그래프
그래프 : 정점 (vertex) 와 간선 (edge)로 이루어진 자료구조
가중치
가중치 : 정점과 간선 사이에 드는 비용
그럼 그래프에 속하는 것 중 하나인 트리에 대해 알아보자.
트리
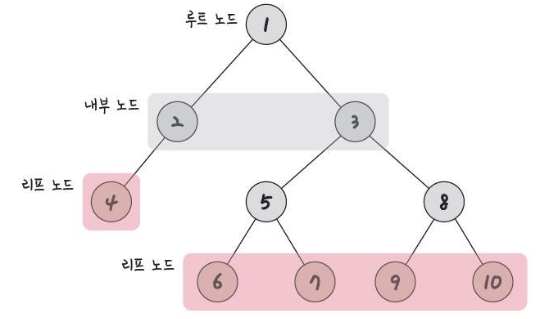
- 루트 노드 : 가장 위에 있는 노드
- 내부 노드 : 루트 노드와 리프 노드를 제외한 노드
- 리프 노드 : 자식 노드가 없는 노드
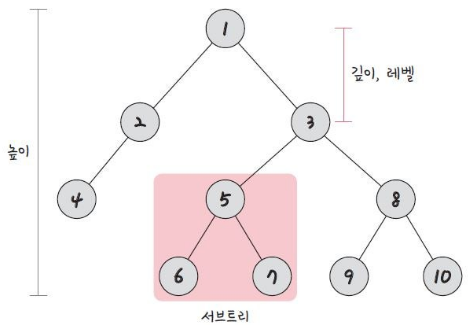
깊이 : 루트 노드 ~ 특정 노드까지 최단 거리로 갔을 때의 거리
- 각 노드마다 트리의 깊이가 다르다.
레벨 : 보통 '깊이'와 같은 의미를 가진다.
- 1번 노드가 0레벨 => 2번, 3번 노드는 1레벨
높이 : 루트 노드 ~ 리프 노드까지의 거리 중 가장 긴 거리
서브트리 : 트리 내의 하위 집합 (부분 집합)
이진 트리
이진 트리 : 자식 노드의 수가 2개 이하인 트리
이진 트리의 종류
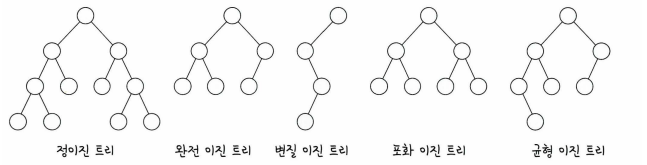
-
정이진 트리 (full binary tree): 자식 노드가 0 또는 2개인 이진 트리를 의미한다.
-
완전 이진 트리 (complete binary tree): 왼쪽에서부터 채워져 있는 이진 트리를 의미한다.
- 마지막 레벨을 제외하고는 모든 레벨이 완전히 채워져 있으며, 마지막 레벨의 경우 왼쪽부터 채워져 있다.
-
변질 이진 트리 (degenerate binary tree): 자식 노드가 하나밖에 없는 이진 트리를 의미한다.
-
포화 이진 트리 (perfect binary tree): 모든 노드가 꽉 차 있는 이진 트리를 의미한다.
-
균형 이진 트리 (balanced binary tree): 왼쪽과 오른쪽 노드의 높이 차이가 1 이하인 이진 트리를 의미한다.
map,set을 구성하는 레드 블랙 트리는 균형 이진 트리 중 하나입니다.
이진 탐색 트리 (BST, Binary Search Tree)
이진 탐색 트리 : 노드의 오른쪽 하위 트리에는 '노드 값보다 큰 값'만 들어 있고, 왼쪽 하위 트리에는 '노드 값보다 작은 값'만 들어 있는 트리
그래서 검색할 때 용이하다
요소에 접근 시 평균적으로는 소요, 최악의 경우에는 소요하며, 삽입 순서에 따라 구조가 선형적일 수 있다.

AVL 트리 (Adelson-Velsky and Landis tree)
AVL 트리 : 선형적인 트리가 되는 최악의 경우를 방지하고, 스스로 균형을 잡는 이진 탐색 트리
두 자식 서브트리의 높이 => 항상 최대 1만큼 차이난다는 특징이 있다.
삽입, 삭제 시마다 균형을 맞추기 위해 트리의 일부를 왼쪽 또는 오른쪽으로 회전시킨다.
- 탐색, 삽입, 삭제 => 소요

레드 블랙 트리
레드 블랙 트리 : 균형 이진 탐색 트리로 탐색, 삽입, 삭제 모두 시간 복잡도가
각 노드에 빨간색 또는 검은색의 색을 저장하는 추가 비트를 저장하고
이는 곧 삽입, 삭제 중 트리가 균형을 유지하는데 사용된다.
힙, 우선순위 큐
힙과 우선순위 큐에 대해서는 정리된 것을 보자.
우선순위 큐에 대해서는 아래로 내려보면 정리를 해뒀다.
맵, 해시 테이블
맵 : 특정 순서에 따라 키에 매핑된 값의 조합 (키-값) 으로 구성된 자료구조
- 레드 블랙 트리 자료구조 기반으로 형성된다.
- 삽입 시 자동으로 정렬된다.
- 해시 테이블 구현 시 사용한다.
unordered_map: 정렬 보장 Xmap: 정렬 보장 O
map<string, int> 형태로 구현하며 아래와 같은 기능들이 있는데
clear(): 맵에 있는 모든 요소 삭제size(): map의 크기 구함erase(): 해당 키와 키에 매핑된 값 삭제
Java에서의 HashMap 메서드도 위 링크에 정리를 해놨다.
해시 테이블 : 무한에 가까운 데이터를 유한한 개수의 해시 값으로 매핑한 테이블
unordered_map으로 구현
삽입, 삭제, 탐색 => 평균적으로 소요
셋 (set)
Set : 특정 순서에 따라 고유한 요소 저장하는 컨테이너
중복되는 요소 없이 unique 값만 저장한다.
