Abstract
이 논문은 공간적 맥락을 활용해서 visual respresentation의 supervised training data로 활용하는 방법을 제시한다.
label이 되지 않은 이미지들을 활용해서 각 patch의 pair를 뽑아내고 첫번째 patch에 대한 두번째 patch의 상대적 위치를 맞추는 문제를 convolution으로 학습한다.
이렇게 함으로써 모델은 이미지의 위치를 이해하게 되고 추후 fine-tuning을 하였을 때 이미지를 더욱 잘 이해할 수 있게 된다.
1. Introduction
image 데이터는 매우 많지만 labeling 하는 비용이 비싸기 때문에 다 활용하지 못하고 있다.
그렇기 때문에 unsupervised learning이 필요하지만 아직 이미지 분야에서의 큰 진전은 없다.
text의 경우 대량의 text에서 각 단어의 context를 학습하기 위해 각 단어의 주변 단어를 확인한 후 주어진 단어를 feature vector에 mapping하는 방식으로 학습한다.
이는 unsupervised를 self-supervised 문제로 바꾼 것으로 보인다.
- unsupervised: 단어 사이 유사도 평가 방법(clustering) 구하기
- self-supervised: 주어진 단어(label)와 주변 단어들(input) 사이의 function 구하기
이 논문에서는 이러한 방식과 비슷하게 이미지를 patch화 하고 공간적 맥락을 활용해서 patch의 context를 예측하는 문제로 만든다.
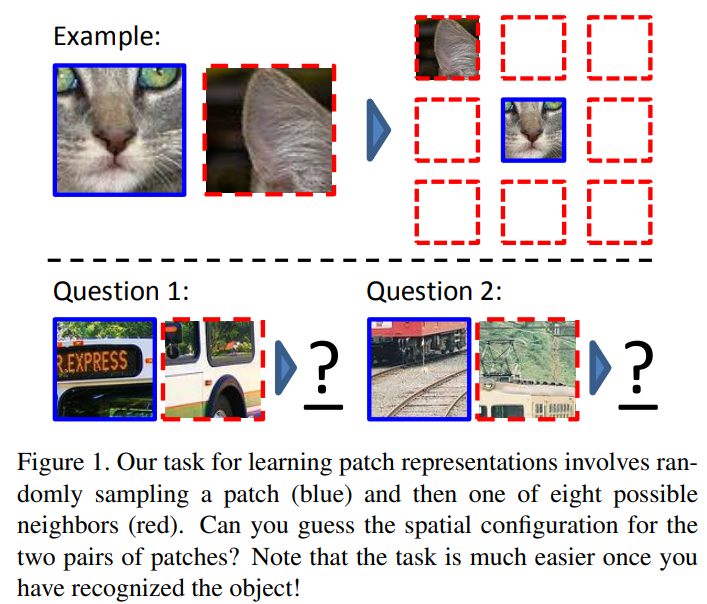
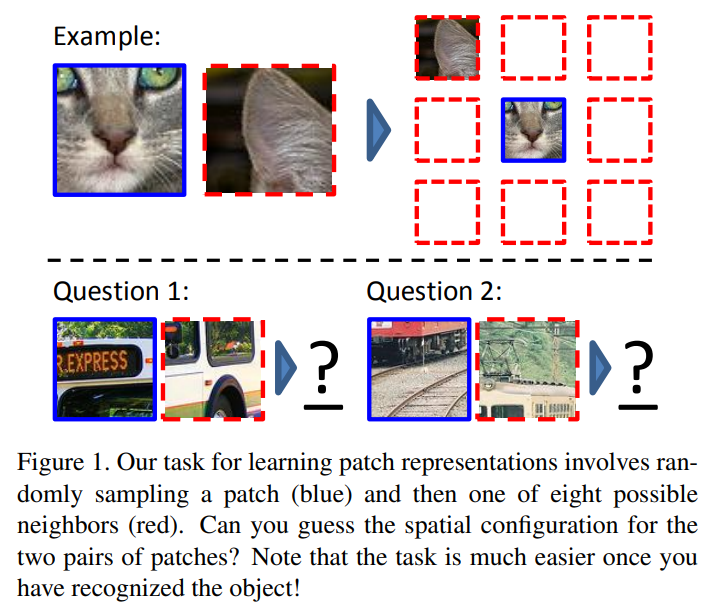 위 그림과 같이 9개의 조각으로 patch화 하고 각 기준 patch에 대해서 input patch의 위치를 예측하는 문제로 만들었다.
위 그림과 같이 9개의 조각으로 patch화 하고 각 기준 patch에 대해서 input patch의 위치를 예측하는 문제로 만들었다.
이 과정에서 object에 대한 이해와 상대적인 공간에 대한 지식이 늘어날 것으로 생각한다.
3. Learning Visual Context Prediction
CNN을 가지고 학습을 진행하였음.
network는 주어진 두 patch에서 상대적인 위치를 예측할 수 있게 구성이 되었으며
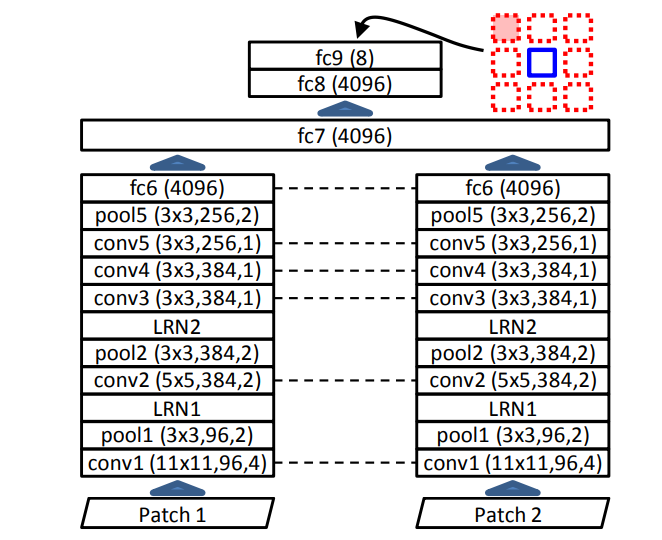 구조는 위와 같다. 여기에서 점선으로 표시된 부분은 같은 wieght를 공유하는 layer이다. pool은 max-pool이고 LRN은 local response normalization layer이다. 모든 conv와 fc는 ReLU를 사용한다.
구조는 위와 같다. 여기에서 점선으로 표시된 부분은 같은 wieght를 공유하는 layer이다. pool은 max-pool이고 LRN은 local response normalization layer이다. 모든 conv와 fc는 ReLU를 사용한다.
fc9이후 softmax로 들어간다.
여기에서 바라는 목표는 network가 각각 patch에 대해서 독립적인 embedding을 학습하는데 보기에 비슷한 patch는 가깝게 학습하고 다른 patch는 멀리 학습하는 것을 바란다.
3.1 Avoiding “trivial” solutions
논문에서는 이미지를 이해하지 않고
경계선의 패턴이나 패치들 사이의 texture의 연속성 등을 가지고 모델이 trivial shortcut을 만드는 것을 막기위해
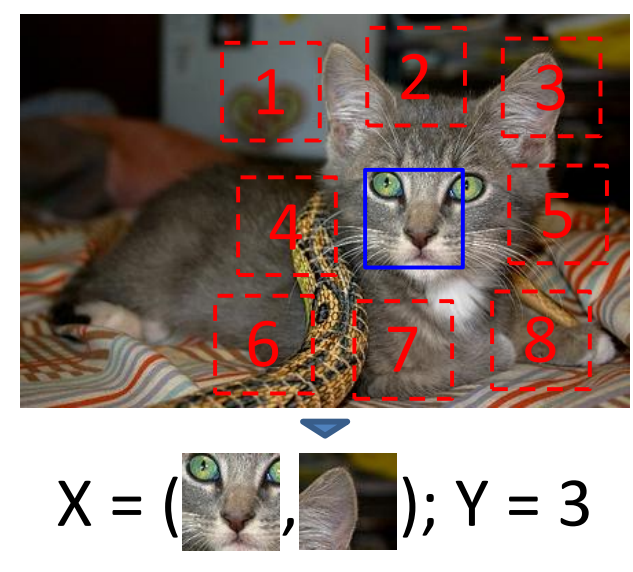 위 이미지와 같이 patch들 사이에 간격을 두고 긴 line이 겹치는 것을 막기위해 최대 7픽셀의 흔들림을 추가하였다.
위 이미지와 같이 patch들 사이에 간격을 두고 긴 line이 겹치는 것을 막기위해 최대 7픽셀의 흔들림을 추가하였다.
그렇지만 이러한 작용도 부족하였다.
심지어 색수차도 문제를 주었기 때문이다.
색수차는 렌즈가 빛의 모든 색을 같은 초점에 맞추지 못할 때 나온다.
위키피디아 예시

색수차를 학습해서 이미지가 아니라 렌즈에서 나오는 패턴을 학습해 이미지에서의 위치를 학습할 수 있다.
이러한 방식이 green, magenta(red+blue)색의 조합으로 판단하는 과정으로 이루어졌기 때문에 green, magenta를 gray로 projection 한다.
projection은 2가지 방법으로 이루어지는데
- a=[-1,2,-1]은 green-magenta color의 axis이다.
는 색을 green-magenta axis로 projection 되는 vector을 빼는 역할이다. 즉 red, magenta를 없애는 역할. - 아니면 단순하게 3개의 색 채널에서 2개를 빼준다.
이 방법이 효과가 있는지 확인하기위해 이미지 patch의 원본 위치를 regression하는 모델을 학습하엿는데 왼쪽이 input이고 2번째는 자른 patch들 3번째는 기존의 regression model 결과이다. 의외로 상당히 좋은 결과를 낸다. color projection 이후에는 오른쪽과 같이 성능을 떨어트리는데 성공하였다.

실제 학습 과정에서는 다음과 같은 순서로 이루어진다.
각 이미지에서 patch를 뽑아내고 주변에 최대 8개의 pairing patch를 뽑는데 유격을 최대 48pixel 둔다. 이후 jittering을 -7~+7을 주어 흔들어서 patch 설정 완료
이제 patch 전처리를 하는데
1. mean subtraction
2. projection or dropping color
3. downsampling 하고 다시 돌리는 방법으로 robust를 증가
그런데 실제로 학습을 진행하는 과정에서 fc6, 7의 모든 activation 값이 0으로 가게되어 학습이 악화되는 경우가 존재함.
이는 학습이 안장점에 갇히게 되었다는 것을 의미하고 이를 해결하기 위해 batch normalization을 없이 사용하여서 activation을 다양하게 만들어서 해결함.
4. Experiment
이후 학습된 모델을 pre-train으로 활용하거나 그대로 visual mining 즉 unlabeled image의 object를 분류하는 문제에 사용하였다.
4.1 Nearest Neighbors
이전에 제시한 내용으로 embedding 값이 비슷한 그림은 비슷하게 표현이 되고 다른 그림은 다르게 표현이 될 것 이라고 예상하였고
Nearest Neighbor와 같은 방법으로 활용
사용할 때에는 fc6의 값을 활용(fc7부터는 다 삭제, 그리고 2개의 stack 중 1개만 사용)
비교를 위해 ImageNet으로 학습된 alexnet의 fc7 layer 값으로 활용
 위 그림이 Nearest Neighbor로 나온 결과.
위 그림이 Nearest Neighbor로 나온 결과.
가장 위는 논문의 모델이 잘한 것이고 중간은 AlexNet이 잘한 부분.
마지막은 3가지 다 잘한 부분이다.
4.3 Object detection
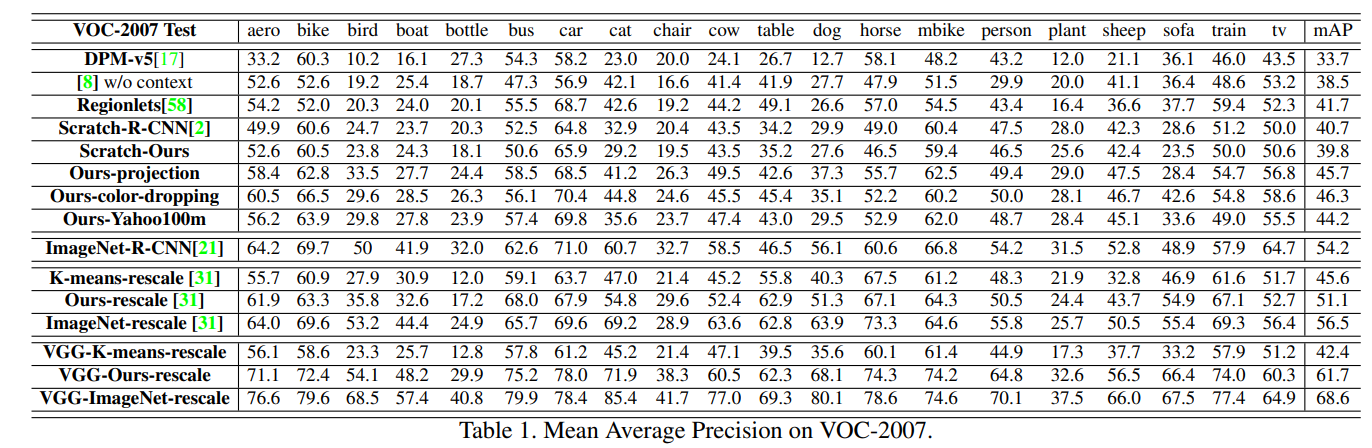
pretrain을 진행하고 학습을 한것이 좋은 성능을 보였다.
Scratch-R-CNN을 Scratch-Ours로 바꾸었을 때는 성능이 조금 떨어졌지만
pretrain을 한 이후 5~6%의 성능향상을 보임
