Abstract
예전엔 CNN이 좋은 성능을 보였고 지배적인 모델이었지만 최근 attention 기반의 transformer 모델이 vision 분야에서 특정한 설정에서 지배적인 성능을 보이고 있다.
그러나 ViT는 self-attention의 quadratic computation 때문에 이미지를 나누는 patch embedding이 필요하다.
여기에서 질문이 생긴다
ViT의 좋은 성능은 transformer의 architecture 때문인가? 아니면 patch로 input을 보기 때문인가?
이 논문에서는 후자의 증거를 제시한다.
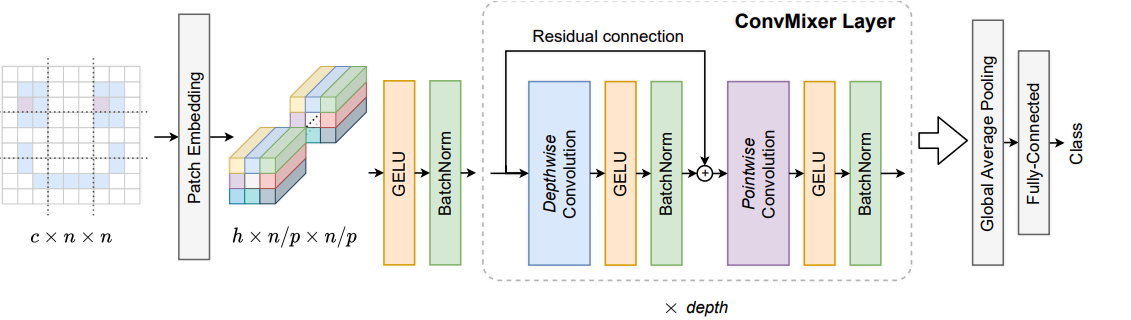
논문에서는 ConvMixer를 제시하는데 ViT와 MLP-Mixer의 기초와 비슷한 구조를 유지한다.
- patch를 input으로 받고
- channel과 spatial mixing의 분리
- network 전체에서 같은 resolution 유지
여기에서 ConvMixer는 convolution만 사용해서 mixing을 진행한다.
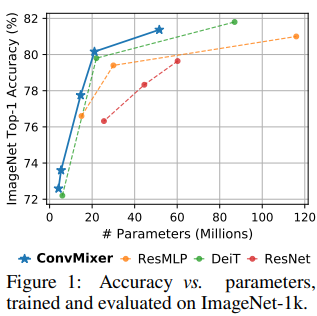 ConvMixer는 이전의 다른 모델보다 같은 계산량에서 더 좋은 성능을 보임
ConvMixer는 이전의 다른 모델보다 같은 계산량에서 더 좋은 성능을 보임
1. Instroduction
처음에 ViT에 대해서 설명을 하고 진행한다.
- transformer 기반 모델은 최근 특정 task에서 지배적인 성능을 보였다. 특히 많은 데이터를 활용하는 부분에서.
- 결국 nlp 분야 뿐만 아니라 이미지도 transformer가 지배하는 것은 시간문제일 것이다.
- 그러나 transformer를 적용하기 위해서는 input의 변화가 필요한데 이는 transformer가 input의 제곱의 계산량을 가지기 때문에 input을 모든 픽셀을 사용하는 것이 아니라 이미지를 patch로 잘라서 진행을 한다.
자세한 ViT에 대한 설명은 다음 ViT 논문 리뷰를 참고하는게 좋다.
여기에서 이 논문은 transformer의 이러한 성능이 input의 patch화 때문인지 아니면 trnasformer 자체의 능력인지 탐구를 한다.
이를 위해 cnn을 기반으로한 ConvMixer를 만들었다. 이는 MLP-Mixer와 유사한 구조 때문에 지은 이름이다.
ConvMixer는 위에어 언급했듯이
- patch를 직접적으로 활용한다.
- 모든 layer에서 해상도, 크기를 일정하게 유지한다.
- downsampling을 하지 않는다.
- channel, spatial wise mixing을 분리하였다.
- 그러나 이러한 모든 과정은 CNN으로 구성되어 있다.
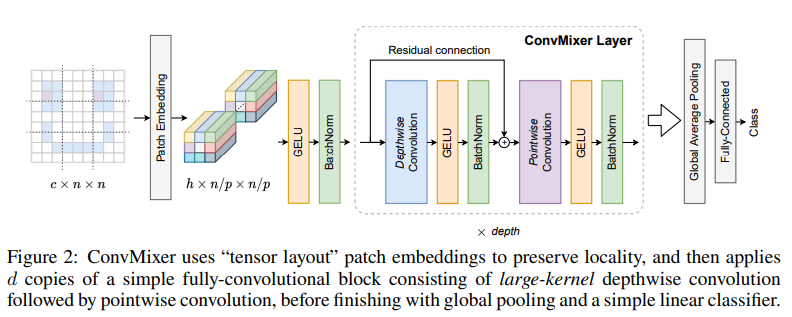 코드 구현은 다음과 같다.
코드 구현은 다음과 같다.

중요한 것은 patch representation 자체가 성능을 증가시키는데 영향을 주었다는 것이다.
2. A Simple Model: ConvMixer
우선 patch embedding을 진행하는데
patch size , embedding dimension 인 patch embedding은 convolution으로 구현이 가능하다.
이 input channel이고 가 output channel, 가 kernel size이면서 동시에 stride 이다.
수식으로 표현하면 patch embedding은 다음과 같다.
 이 부분이다.
이 부분이다.
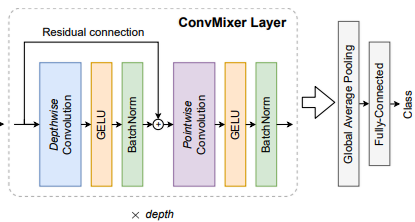
이후 ConvMicer block은 각각 depthwise convolution(grouped conv)과 뒤의 pointwise convolution(1x1 conv)으로 구성이 된다.
이 역시 수식으로 적으면 다음과 같다.
추가로 depthwise에 large kernel size가 좋은 성능을 보여준다고 한다.
이는 ConvNeXt논문에도 나온 내용이다.
또한 중요한 부분이 Pointwise에는 skip connection이 없다.
뒤의 appendix에서는 skip connection을 추가하였을 때 오히려 성능이 떨어졌다고 한다.
이후 global average pooling을 해서 size 로 만들고 MLP를 통과하고 class를 추정한다.
그림으로 표현하면 다음과 같다.
hyper param
조절이 가능한 hyper param이 몇가지 존재하는데
- patch size
- hidden channel dim
- depth
- kernel size
모델의 표기는 ConvMixer - /로 표기한다.
3. Experiment
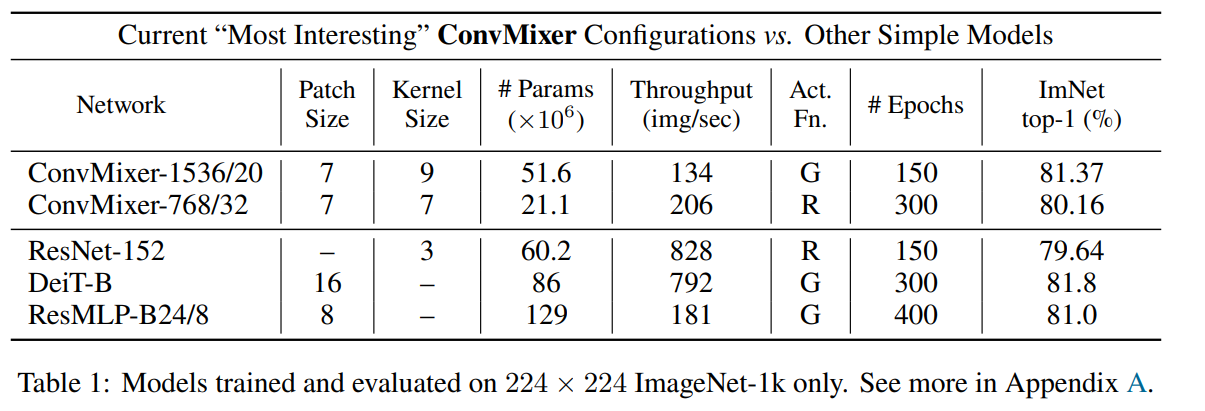 결과는 위와 같고.
결과는 위와 같고.
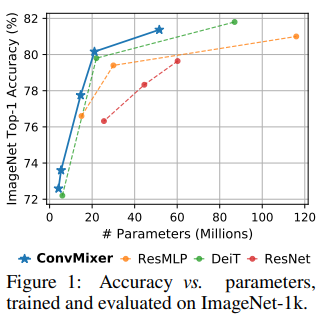 같은 param에서 더 좋은 성능을 보여준다.
같은 param에서 더 좋은 성능을 보여준다.
4. Conclusion
이 논문은 patch embedding과 convolution으로만 구성된 Mixer를 합친 ConvMixer를 제시한다.
ConvMixer 구조는 attention이 없더도 좋은 성능을 보여준다는 것을 보여주고 patch embedding이 성능에 좋은 영향력을 준다는 것도 보여준다.
이 논문은 읽으면서 ConvNeXt와 비슷한 부분이 많았다. (patch embedding, Channel과 Spatial의 분리 등)
그러나
- Mixer의 구조처럼 spatial 계산에서 1x1 conv를 1개만 사용하였다.
- Skip connection은 channel mixing에서만 사용을 하였다.
- patch embedding을 하는 처음 부분을 제외하고는 down sampling을 하지 않아 해상도를 계속 유지하였다.
등의 차이점이 존재했다.
5. 구현
cifar10의 3x32x32를 기준으로 구현하였다.
class ConvMixerLayer(nn.Module):
def __init__(self, kernel_size=3, d_channel=512):
super().__init__()
self.depthwise = nn.Conv2d(d_channel, d_channel, kernel_size=kernel_size, padding=(
kernel_size//2), groups=d_channel)
self.act = nn.GELU()
self.norm1 = nn.BatchNorm2d(d_channel)
self.pointwise = nn.Conv2d(d_channel, d_channel, kernel_size=1)
self.act2 = nn.GELU()
self.norm2 = nn.BatchNorm2d(d_channel)
def forward(self, x):
residual = x
x = self.norm1(self.act(self.depthwise(x)))+residual
# point wise에는 skip connection이 없음
x = self.norm2(self.act2(self.pointwise(x)))
return x
class ConvMixer(nn.Module):
def __init__(self, image_size=32, patch_size=2, channel_size=3, num_layer=8, d_channel=256, class_num=10):
super().__init__()
self.channel_size = channel_size
self.image_size = image_size
self.patch_size = patch_size
self.patch_num = (image_size//patch_size)**2
self.input = nn.Conv2d(channel_size, d_channel,
kernel_size=patch_size, stride=patch_size)
self.act = nn.GELU()
self.bn = nn.BatchNorm2d(d_channel)
self.layer = nn.Sequential(
*[ConvMixerLayer(kernel_size=7, d_channel=d_channel)
for _ in range(num_layer)],
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), # (batch, d_channel, 1, 1) -> (batch, d_channel)
nn.Linear(d_channel, class_num)
)
def forward(self, x):
x = self.bn(self.act(self.input(x)))
# x shape (batch, d_channel, h/p, w/p)
x = self.layer(x)
return x