Abstract
최근 ML 모델들은 tabular data의 학습에서 데이터의 구조가 고정되어있다고 가정하는 경우가 많다.
서로 다른 column을 가지는 table을 합치기 위해서는 많은 데이터 전처리가 필요하고 보통 대량의 데이터 손실이 발생한다.
(일치하지 않는 column이나 샘플 제거 등)
- 어떻게 모델이 부분적으로 겹치는 column을 가진 table들을 학습하게 만들 수 있을까?
- 어떻게 모델이 시간에 따라 점점 더 많은 column이 추가되는 table을 학습할 수 있을까?
- 어떻게 여러개의 서로 다른 table에서 모델을 pre-train할 수 있을까?
- 어떻게 보지못한 table을 예측하는 모델을 학습할 수 있을가?
이러한 질문에 답을 하기 위해 transfer이 가능한 tabular transformer모델을 제시한다.(TransTab)
TransTab의 목적은 sample(row)을 embedding vector로 변환하고 transformer를 이용해 feature encoding을 하는 것이다.
이를 위한 하나의 방법론은 column에 대한 설명과 table cell을 합치는 것이다.
table cell에 대해서 찾아보니
Name Age City Alice 30 New york Bob 25 Los Angeles Charlie 20 Chicago 이렇게 구성된 table에서 각각의 Name, Alice, 30, New york 등의 값이 1개의 cell이다.
1가지 방법은 Column에 대한 설명과 cell을 합쳐서 학습하는 것이다.
또다른 방법으로는 모델 성능 향상을 위해 supervised learning, self-supervised learning을 하는 것이다.
1. Introduction
최근 tabular data를 ML 모델이 학습하는 방법은 deep network를 만들거나 self-supervised learning을 도입하는 것이다.
이러한 기존 방법론들은 training과 test에서 동일한 구조의 table이 필요하다는 것이다.
그러나 실제로는 column이 부분적으로 겹치는 여러개의 table이 존재하는 것이 가능하다.
여러개의 테이블을 활용하는 과거의 방법은 데이터 cleaning을 통해 겹치지 않는 column을 지우고 mismatched sample을 삭제하는 것이다.
그러나 이 과정에서 많은 데이터가 상실된다.
- 그렇기 때문에 다른 column을 가진 table들을 학습하고 knowledge를 transfer하는 것을 필수이다.
learning across table을 하기 위해서는 table의 최소 단위를 정하는 것이 중요한데 이미지의 픽셀, nlp의 토큰과 같이 tabular에는 각 column의 cell을 독립적인 element로 보는 것이 자연스럽다.
column은 고유한 index에 매핑이 되고 모델은 훈련과 추론에서 cell 값을 사용한다.
-> 이러한 방법은 모든 table에서 동일한 column 구조를 유지해야 한다.
그러나table은 종종 열과 cell이 다른 명명법을 가지는 경우가 생긴다.
이를 해결하기 위해 column과 cell의 contextualize를 제시
예를 들어, 이전 방법들은 gender column 아래의 'man' value를 코드북 {man : 0, woman : 1}을 참조하여 0으로 표현
논문에서 제시하는 모델은 표 입력을 sequence input으로 변환 (gender is man 등)
이렇게 작동하는 모델은 downstream sequence model로 바뀌어질 수 있다.
요약하자면
TransTab는 column과 cell을 sequence로 표현함으로써 다양한 table을 학습할 수 있다.
- 테이블의 column과 cell의 의미를 모두 고려하는 근본적인 featurizing protocol을 제시
- Vertial-Partition Contrastive Learning으로 다양한 table을 pretrain하고 target dataset을 fine-tune할 수 있다.
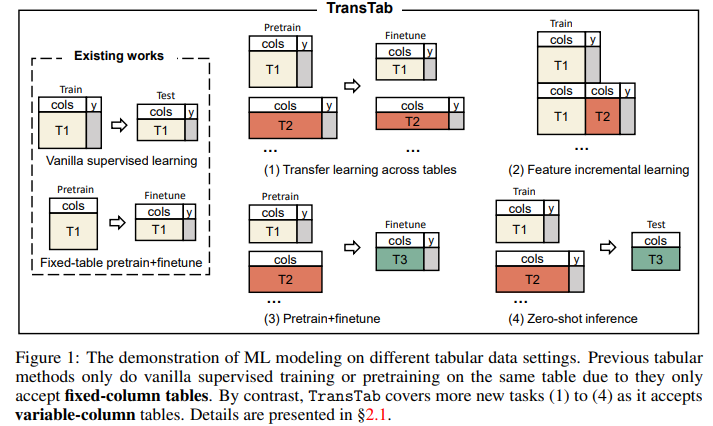 기존 방법은 고정된 column에서 작동을 하지만
기존 방법은 고정된 column에서 작동을 하지만
TransTab는 다양한 table을 학습할 수 있다.
2. Method
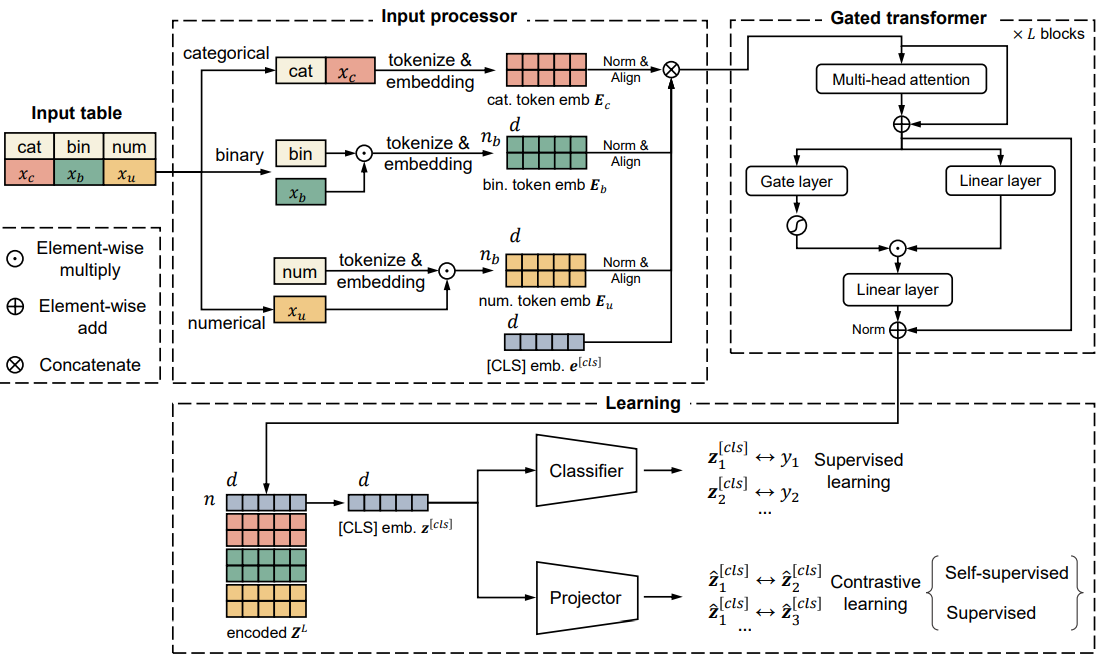
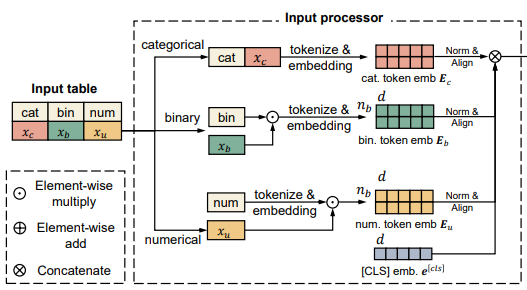
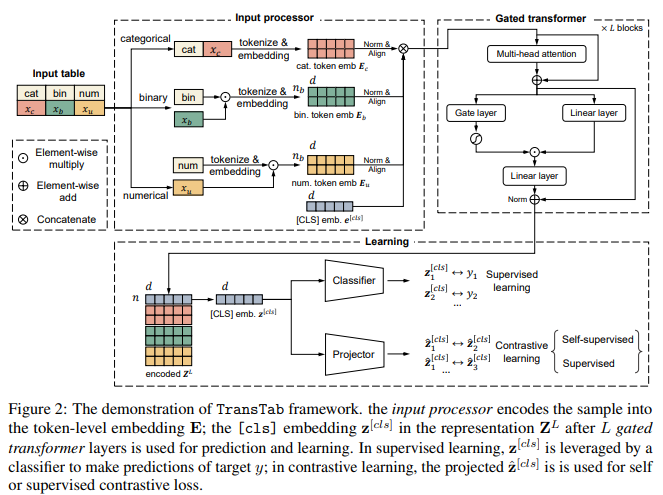 위 사진은 TransTab의 중요한 부분을 포함하고 있다.
위 사진은 TransTab의 중요한 부분을 포함하고 있다.
1. input processor: Input 을 featurize하고 token-level embedding을 진행한다.
2. gated transformer: stacked gated transformer가 token-level embedding을 encode한다.
3. learning: 마지막으로 학습이 진행되는데 classifier가 labeled data로 학습하고 contrastive learning을 위한 projector를 포함한다.
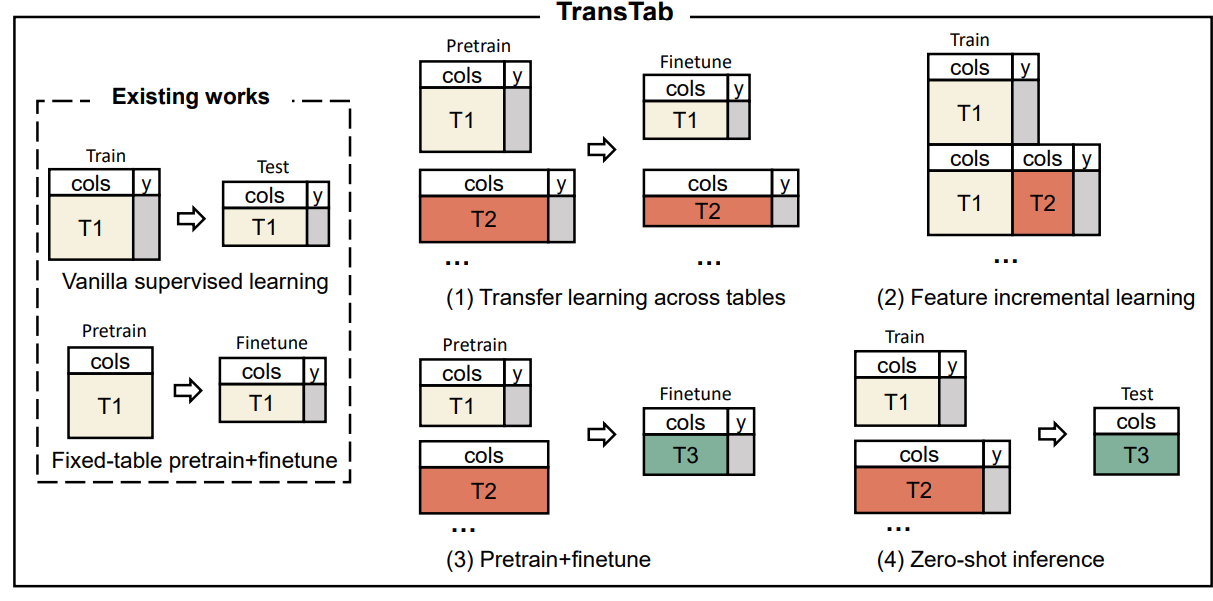
2.1 Application scenarios of TransTab
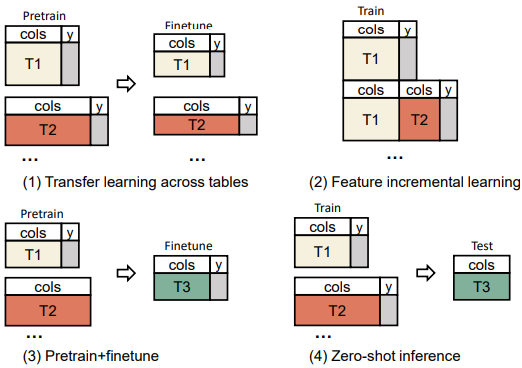 앞서 언급한 4가지 시나리오이다.
앞서 언급한 4가지 시나리오이다.
예시로 임상시험표를 통해 유방암 치료 효능을 예측하는 것이 목표일 때 4가지 방법이 있다.
1. Transfer learning.
여러 다른 암 실험 데이터를 수집해서 다른 환자에게 동일한 약의 효능을 테스트한다.
이때 테이블은 독립적이지만 겹치는 column이 존재한다.
어떻게 학습할 수 있을까?
2. Incremental learning
실험이 진행되면서 column이 추가될 수 있다. 어떻게 이러한 단계들을 통해 모델을 학습할 수 있을까?
3. Pretraining+Finetuning
임상실험 내용 결과(사망 등) label이 항상 이용이 가능한 것은 아니다.
label이 없는 데이터로 pretrain을 진행하고 label이 있는 데이터로 fine-tune을 진행하는건 어떨까?
4. Zero-shot inference
기록을 학습해서 약의 효능을 학습한 모델이 있다.
만약 drug의 table과 하나도 겹치는 부분이 없는 patient table을 사용해서 약의 효능을 얻을 수 있는 환자를 예측할 수 있을까?
앞으로 어떻게 이러한 문제를 해결하는지 다룬다.
2.2 Input processor for columns and cells
input을 바꾸는 과정은 다음과 같다.
1. variable column table들을 받고
2. tabular dataset들의 knowledge를 유지한다. 이는 tabular data를 sequence of semantically encoded token으로 변경하는 것으로 진행한다.
column이 cell의 의미를 결정한다.
smoking history의 cell이 1이라면 흡연을 했었다는 의미이고
weight의 cell이 60이면 60kg이라는 의미이지만 age의 cell이 60이면 60살이라는 의미이다.
이러한 관찰에서 동기를 얻어 tabular modeling에 column의 이름을 포함하는 것을 제시하였다.
결과적으로 TransTab는 tabular data를 3가지 요소들의 집합으로 다룬다.
- text(categorical & textual cell and column names)
- continuous values (numerical cells)
- boolean values(binary cell)
각각의 처리는 다음과 같다.
Categorical/Textual feature.
column name 과 value 를 concat해서 sequence of token으로 만든다.
이 문장을 tokenize하고 token embedding matrix를 통해 feature embedding 으로 바뀌게 된다. 는 embedding dim이고 는 token의 숫자이다.
Binary feature.
value는 으로 표현이 되는데 만약 이라면 bin은 tokenize가 되고 로 encoding이 된다.
만약 0이라면 따로 처리하지 않는데 이는 1이 거의 없고 high-dim 일 때 계산량을 매우 줄인다.
Numerical feature.
numerical feature의 경우 column name과 value를 concat하지 않는다.
왜냐하면 tokenization-embedding의 과정이 숫자를 구별하는데 좋지 않기 때문이다.
대신에 분리해서 을 encode해서 으로 변경을 하고
numerical value를 곱해준다.
으로 만들어준다.
이는 경험적으로 복잡한 numerical embedding보다 우위를 점했다.
마지막으로 각각의 는 layer normalization을 통과하고 동일한 linear layer를 통과해서 같은 선형 공간에 정렬된 후 토큰과 함께 concate를 한다.
결과적으로 cell의 value가 column과 결합해 의미를 가진다.
이러한 기능은 knowledge transfer에 많은 도움을 준다.
예를들어 previously smoked는 smoking history와 동일하다.
이전의 방법은 이러한 관계를 학습하지 못하였다.
그림으로 표현하면 다음과 같다.
2.3 Gated transformers
gated tabular transformer는 NLP의 transformer의 수정버전이다.
multi head attention과 gated feedforward로 구성되는데 multi head는 다음과 같다.
이후 gated feedfoward가 진행이 되는데
이 sigmoid일 때 일 때
으로 진행된다.
그런데 이 논문의 수식과 논문의 그림에서 다른 부분이 존재한다.
하나씩 예를 들자면
- skip connection이 수식에선 없다.
- 특히 2번째 수식의 의 내부에서 부분의 이 위 그림에서는 Linear layer를 통과하지만 수식에서는 바로 들어간다.
위 문제에 대한 답은 공식 github를 보고 알 수 있었는데
skip connection은 우선 위 그림처럼 진행하는 것이 맞고
modeling transtab.py의 418번째 줄을 보면def _ff_block(self, x: Tensor) -> Tensor: g = self.gate_act(self.gate_linear(x)) h = self.linear1(x) h = h * g # add gate h = self.linear2(self.dropout(self.activation(h))) return self.dropout2(h)feed forward는 위 코드와 같이 그림의 내용대로가 맞다.
아마 정확한 수식은 다음과 같을 것이다.
이전 block의 마지막에서 이고
이다.
2.4 4 Self-supervised and supervised pretraining of TransTab
이제 TransTab는 column-value의 쌍을 학습하기 때문에 여러 다른 table들을 학습할 수 있다.
Self-supervised VPCL(Vertical-Partition Contrastive Learning)
기존 SSL(self-supervised learning)은 고정된 column set을 받고 학습하는데 이는 매우 비싸고 overfitting을 야기한다.
대신에 이 방법은 세로의 partition을 사용해서 contrastive learning을 위한 양성, 음성의 sample을 만들고 진행한다.
이는 강력한 representation이 view에 달라지지 않는 특징을 가져야 한다는 가정에서 출발한다.
한번 들어가보자
X가 K개의 partition으로 구성된 로 구성이 되었다고 할 때
이 중에서 인접한 partition은 겹치는 영역이 생길 수 있는데 이는 partition에서의 column의 비율로 정의가 된다.
Self-VPCL은 같은 sample의 partition은 양성으로, 다른 sample의 partition은 음성으로 표현을 하고 대조학습을 진행한다.
loss는 다음과 같이 정의된다.
위 수식은 이전 SAINT 논문리뷰에서도 다룬 적이 있는 InfoNCE loss이다. 간단하게 설명하자면 -log의 내부는 커져야 loss가 줄기에
오른쪽 분자의 와 은 커져야 하기에 같은 sample의 partition representation은 가까워지고
분모의 값은 작아져야 하기 때문에 와은 작아져야해서 유사도가 멀어지게 된다.
여기에서 B는 batch size이고 는 cosine similarity이다.
는 의 projection인 에 적용이 된다.
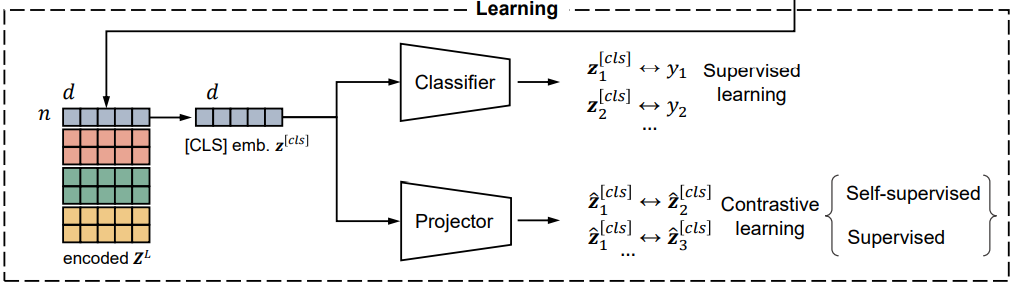 여기 그림을 보면 이해가 쉬울 것이다. 즉 partition들을 가지고 같은 sample이냐 아니냐의 정보를 가지고 학습을 하는 것이다.
여기 그림을 보면 이해가 쉬울 것이다. 즉 partition들을 가지고 같은 sample이냐 아니냐의 정보를 가지고 학습을 하는 것이다.
Supervised VPCL(Vertical-Partition Contrastive Learning)
원래 label이 있는 데이터로 사전학습을 할 때에는 보통 작업별 classification head를 두고 일반적인 supervised loss 즉 cross entropy 등을 사용하고 fine-tune 때는 head를 떼고 학습을 하는게 일반적일 것이다.
그러나 저자는 이러한 방법은 transfer의 기능을 저하한다고 말한다. 왜냐하면 tabular data는 작업에 따라서 dataset의 크기, 클래스 분포, 작업정의가 매우 다르기 때문이다.
처음 제시한 방법과 같이 학습을 하게 된다면 encoder가 불가피하게 주요 작업과 class에 편향된다.
그리고 hyper param도 table마다 달라서 적절하게 설정하기 어렵다.
결국 위에서 제시한 방법과 비슷하게 Supervised VPCL을 제시한다.
위와는 다르게 Label이 주어지기 때문에
같은 class의 Label을 가지면 양성, 여러개의 sample들 사이에서 다른 class의 Label을 가지면 음성이다.
(위에서는 같은 sample만 고려)
수식은 아래와 같다.
위와 비슷한데 sample이 2가지이기에 B가 2개로 늘어났고 1{}와 같이 확인을 하는 부분이 추가되었다.
이 부분이 조금 어려워서 한번 더 정리하겠다.
각각 왼쪽은 data이고 오른쪽 위는 Self-supervised이고 아래는 Supervised이다.
오른쪽 위는 1개의 sample이 기준이며 데이터가 같은 sample의 column과 value이냐 아니냐가 양성, 음성 판단 기준이고
아래 supervised는 여러개의 sample이 기준이며 각 sample이 같은 class이냐 아니냐가 양성, 음성의 판단 기준이다.
3. Experiments
되게 재밌는 실험이 많은데
여기서는 이전에 제시한 5가지의 질문이 가능하다.
 1. TransTab이 vanilla setting에서 얼마나 성능이 나올까?
1. TransTab이 vanilla setting에서 얼마나 성능이 나올까?
2. 위 시나리오 2번 즉 늘어나는 column table에 대해 얼마나 성능이 나올까?
3. 위 시나리오 1번 같은 여러개의 domain data에서 얼마나 좋은 성능이 나올까?
4. 위 시나리오 4번 zero-shot에서 얼마나 성능이 나올까?
5. 위 시나리오 3번 pretrain하고 fine tune시 성능이 얼마나 나올까?
datasets
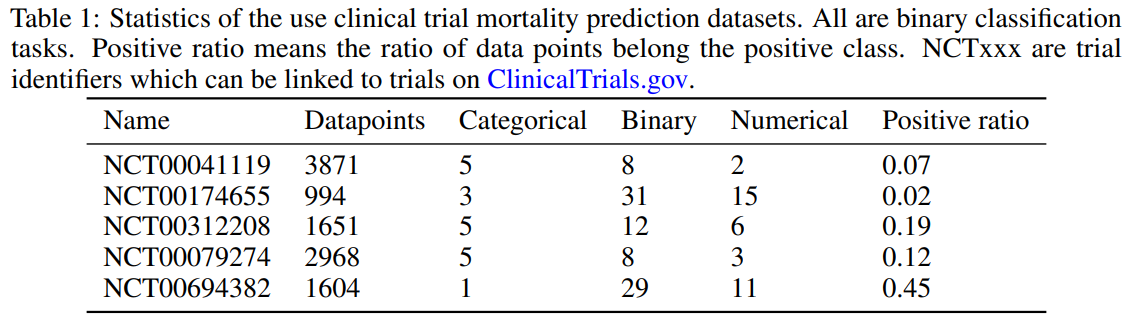 임상실험 사망율 예측 데이터셋이다.
임상실험 사망율 예측 데이터셋이다.
Dataset pre-processing
모든 모델의 경우 간단하게 categorical의 경우 categorical feature의 표현이 필요한 경우면 순서 encoding을 사용하였고 아니면 one-hot encoding을 사용하였다.
numerical의 경우 min-max normalization으로 [0,1] 사이의 값으로 바꾸어주었다.
TransTab의 경우 categorical에서의 의미가 중요하기 때문에 원래 설명으로 매핑한다 예를 들어 gender의 항목에서 class 1을 'female'으로 매핑한다.
3.1 Q1. Supervised learning
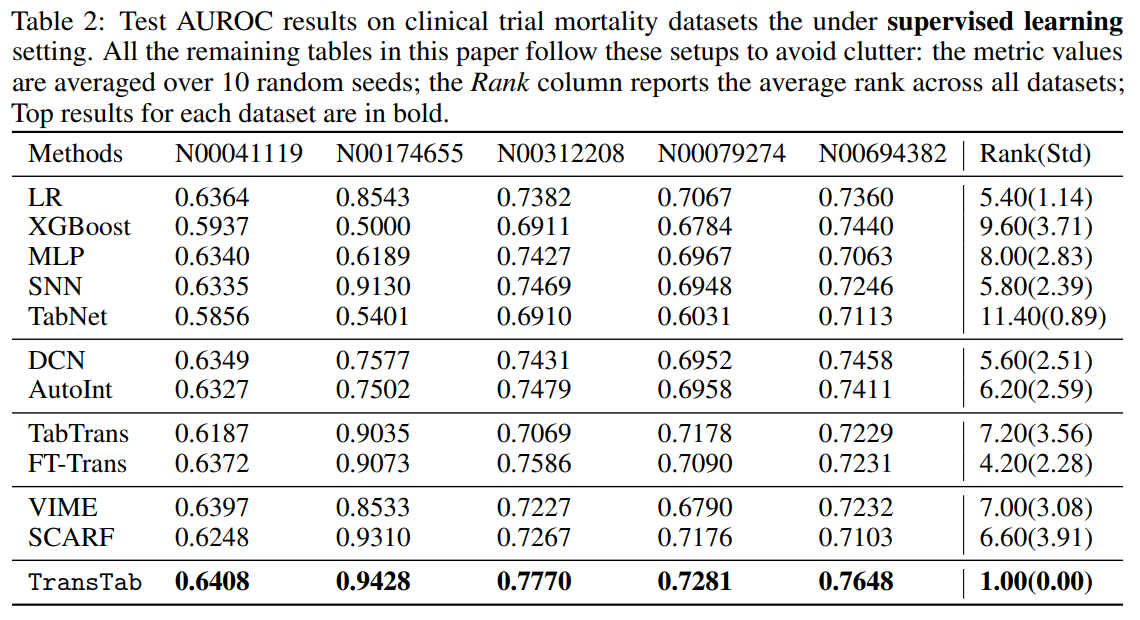 pretrain을 하지 않고도 이미 좋은 성능을 보여줌
pretrain을 하지 않고도 이미 좋은 성능을 보여줌
3.2 Q2. Feature incremental learning
이전 모델의 경우 새로운 feature을 버리거나 이전의 data를 버리고 다시 학습해야 했는데 TransTab의 경우 계속된 학습이 가능하다.
데이터를 3가지 set으로 나누고 위와 같이 2가지 시나리오로 테스트를 하였는데
1. set 1에 제시된 feature만으로 학습
2. set 3의 데이터 만으로 학습
둘 중에 더 좋은 결과를 사용
TransTab는 다 학습한다.
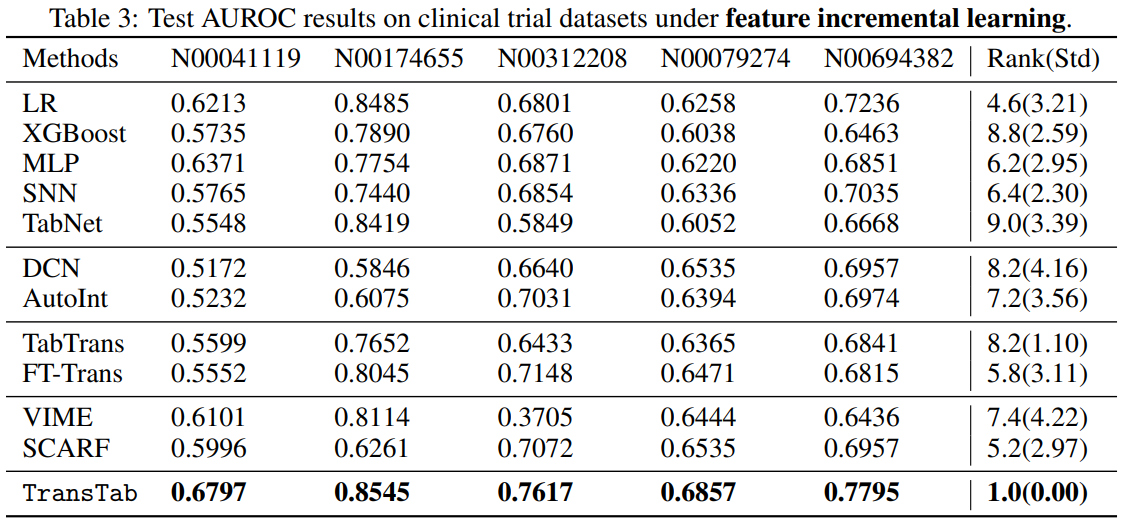 결과는 아무래도 특화가 되어있는 만큼 매우 큰 차이로 이긴다.
결과는 아무래도 특화가 되어있는 만큼 매우 큰 차이로 이긴다.
3.3 Q3. Transfer learning
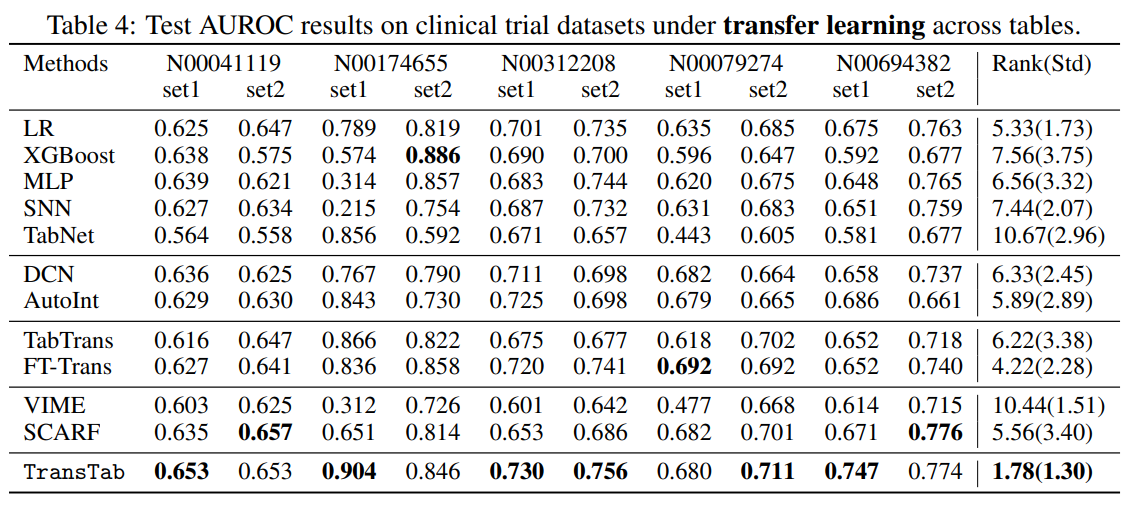 이 부분은 아무래도 다른 모델도 가능한 부분이기 때문에 좋은 성능을 보여주는 모델이 있다. 그렇지만 전반적으로 TransTab이 좋은 성능을 보여준다.
이 부분은 아무래도 다른 모델도 가능한 부분이기 때문에 좋은 성능을 보여주는 모델이 있다. 그렇지만 전반적으로 TransTab이 좋은 성능을 보여준다.
3.4 Q4. Zero-shot learning
전혀 보지 못했던 데이터를 보는건데
1개의 데이터를 각각 다른 column을 가진 set 3개로 나누고
학습은 Set1+Set2, Set3로 나눈다.
- supervised는 set3만 학습
- Zero-shot는 Set1+Set2만 학습
- Transfer는 Set1+set2를 학습하고 Set3로 fine-tune
논문 저자도 깜짝 놀란 부분은
Zero-shot에서 매우 좋은 성능을 보였기 때문이다.
심지어 supervised보다 더 좋은 결과를 보이는 부분도 있었다.
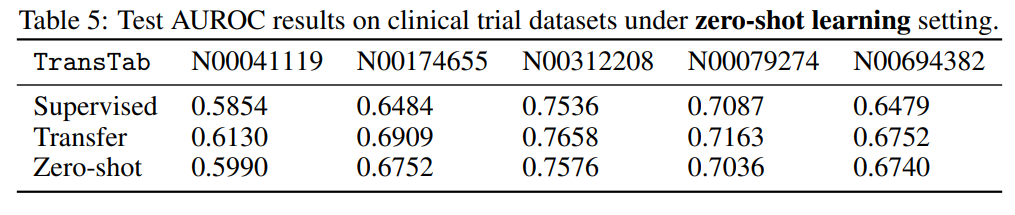
이는 다음을 의미한다.
1. TransTab은 set1+set2에서 학습한 내용을 set3에서 매우 잘 활용할 수 있다.
2. TransTab은 set1+set2의 더 많은 양의 데이터에서 supervised로 set3를 학습하는 것보다 더 이점을 이끌어낼 수 있다.
아무래도 nlp와 접목시켜서 column-value의 문맥을 이해해서 학습하기 때문에 zero-shot도 좋은 성능을 보인다고 추측한다.
3.5 Q5. Supervised and self-supervised pretraining
여기서는 VCPL을 다른 transfer 학습 방법과 비교한다.
2번째 일반적인 tranfer는 위에 설명에서 언급했다시피 Supervised보다 오히려 성능을 떨어지게 만드는 경우가 존재했다.(특정 pretrain task, class에 편향을만든다.)
반면에 Self-VPCL은 일반적으로 성능의 향상을 이끌어냈다.
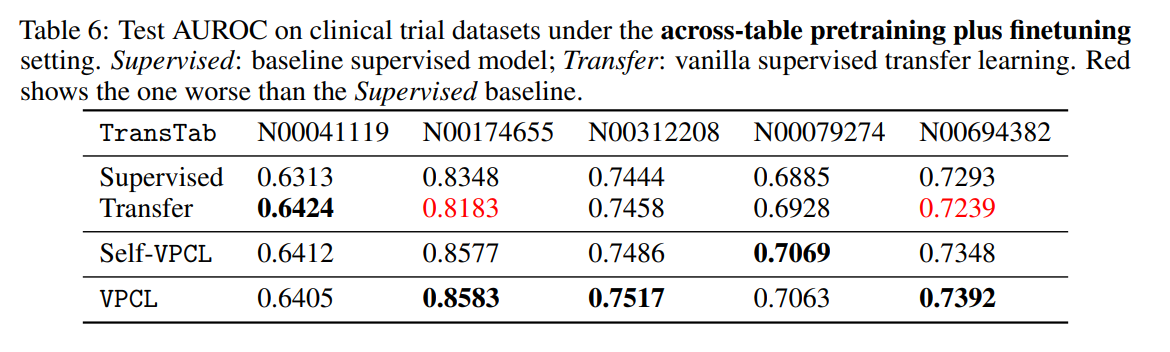
supervised 학습 역시 VPCL로 하는 것이 더 좋다는 결과를 얻을 수 있다.
5. Conclusion
이 논문에서는 TransTab이라는 variable size table을 학습가능한 모델을 제시하였다.
또한 pretrain 방법론을 제시하였으며 좋은 성능을 보여준다는 것을 보였다.
