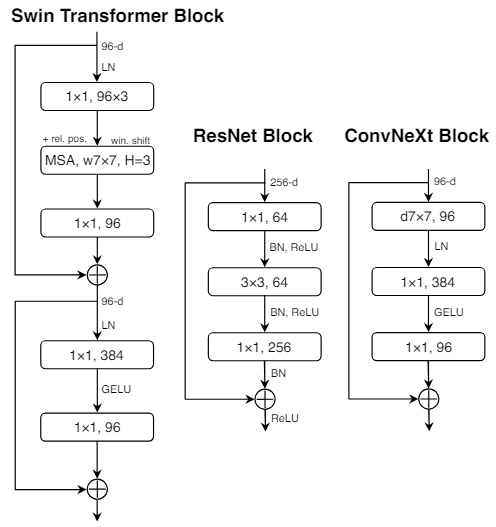
Abstract
ViT 모델이 제시된 이후 빠르게 CNN을 대체해서 transformer가 image classification 분야에서 SOTA 모델이 되었다.
그러나 vanilla ViT 모델은 물체 인식이나 semantic segmentation 등 다른 이미지 분야에는 적용시키기 어려움이 존재했다.
이를 위해 계층적 transformer가 나왔다. (swin transformer 등)
swin transformer는
이미지를 작은 단위에서 attention을 적용시키고 점점 merge해서 큰 단위를 읽어서 attention을 적용시키는 방식이다.
그러나 이런 hybrid 접근법의 효과는 CNN과 같이 inductive bias에서 온 곳이 아니라 transformer의 고유의 장점에서부터 나온 것이다.
결국 inductive bias의 결핍 문제는 해결하지 못하였다. (inductive bias에 대한 설명은 이전 ViT 논문 리뷰 여기에 나와있다.)
이 논문에서는 순수한 ConvNet이 가진 한계점을 다시 테스트하고 ResNet을 점점 vision transformer의 방향으로 근대화를 시키고 성능에 가장 중요한 영향을 미치는 것을 조사하였다.
이렇게 해서 나온 모델이 ConvNext라고 이름을 지었다.
ConvNext 모델은 Convnet의 simple함을 유지하면서 transformer에 비해서 정확도와 scalability에서 더 우수한 성능을 보였다.
1. Introduction
(왜 시작을 하였는지 설명인데 내용이 길다. 아래에 요약있음)
2010년은 주로 CNN이 주도해서 neural network의 부흥기를 이끌었다.
이 기간 동안 이미지 인식 분야는 feature engineering에서 architecture(ConvNet) degisn으로 성공적으로 바뀌었다.
ConvNet은 1980년대에 처음 등장하였지만 2012년에 alexnet에서 처음 등장해서 이미지 학습에 매우 좋은 성능을 보인다는 것을 알게되기 전까지 잠재력을 몰랐었다.
ConvNet의 지배는 우연이 아니었다. ConvNet에서도 사용되는 sliding window기법은 이미지 인식(특히 고해상도 이미지)에 있어서 매우 좋은 성능을 내었다.
ConvNet은 결국 inductive bias 자체가 이미지 처리에 특화되어 있었다.
특히 CNN은 translation equivariance(물체를 옮겨도 동일하게 인식하는 능력)가 매우 중요한데 이는 물체의 인식을 가능하게 해주기 때문이다.
그 동안에 nlp 분야 역시 빠르게 다른 길로 발전하고 있었는데 transformer는 recurrent network가 근본 network가 되게 만들어주었다.
그리고 image 분야와 nlp 분야의 차이가 있음에도 ViT라는 모델이 나옴으로 2020년에 CNN, transformer 2가지의 다른 갈래가 합쳐지게 되었다.
ViT 모델의 장점은 scalability에 있다. 모델과 데이터의 크기가 매우 커짐으로 Transformer는 이미지 분류에서 ResNet을 매우 큰 차이로 이길 수 있었다.
그러나 vision 분야는 이미지 분류만 있지 않다.
vision 분야에는 inductive bias가 매우 중요한 분야가 많고 이는 transformer가 하기 힘든 일이다.
가장 큰 문제는 transformer는 모든 patch를 global하게 처리하기 때문에 계산량이 input size의 제곱으로 늘어난다.
이미지의 해상도가 늘어나면서 이는 문제가 되었다.
Swin transformer등 sliding window를 transformer에 적용해서 CNN처럼 활용하려는 시도는 많이 존재했고 성공적인 성능을 보였지만 결국 이는 CNN의 존재가 필요하다는 것을 보여준다.
이러한 시각에서 transformer는 CNN으로 돌아가려는 것처럼 보인다.
그러나 이러한 시도는 비용이 든다. transformer에 sliding window를 적용하기 위해서는 매우 비싸다. 또는 cyclic shifting등으로 최적화할 수 있지만 구조가 매우 복잡해진다.
CNN은 inductive bias를 매우 직관적으로 만족시키지만 사용되지 않는 이유는 단지 (계층적) transformer보다 scalability가 떨어져서 성능이 안나오기 때문이다.
CNN과 vision transformer는 점점 비슷해지고 있다. 이 논문에서는 ConvNet과 transformer를 비교해서 어떤 구조적 차이가 성능에 영향을 주는지 알아낼 것이다. 또한 ViT 전과 ViT 이후의 세대를 비교하고 순수한 CNN의 한계를 테스트 해볼 것이다.
이를 위해 ResNet을 점점 계층적 transformer에 가깝게 현대화하면서 transformer의 어떤 디자인이 성능에 영향을 주는 것인지 알아낼 것이다.
요약하자면
현재 vision 분야는 (계층적) transformer가 지배를 하고 있는데 사실 transformer는 CNN과 비슷한 구조로 바뀌어가고 있다. 여기에서 왜 transformer가 성능이 잘 나오는지 CNN을 점차 transformer와 비슷한 구조로 바꾸어 가면서 성능에 영향을 미치는 요소를 알아내고 순수한 CNN의 한계를 테스트 해보겠다는 내용이다.
2. Modernizing a ConvNet: a Roadmap
ConvNet의 간단한 구조를 유지하면서 점차 바꾸어 나간다.
우선 ResNet-50 모델에서 시작해서 vision transformer을 학습하는 기술과 비슷하게 학습을 하고 origin ResNet의 결과와 비교하는 것이다.
그리고 디자인의 선택을 진행하는데 종류별로 적자면
1. macro design
2. ResNeXt
3. inverted bottleneck
4. large kernel size
5. various layer-wise micro design
이다.
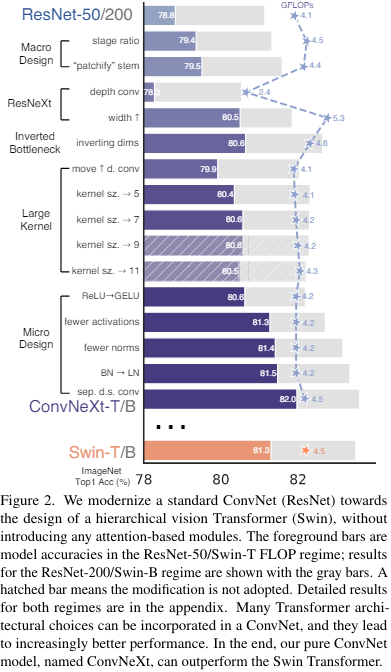 과정과 결과를 그림으로 표현하면 위와 같다.
과정과 결과를 그림으로 표현하면 위와 같다.
파란색은 ResNet50이고 회색은 ResNet200이다.
모든 모델은 ImageNet-1k 데이터로 학습되었다.
2.1 Training Techniques
모델의 구조뿐만 아니라 학습 방법 역시 성능에 영향을 미친다.
Vision transformer는 구조 뿐만 아니라 새로운 학습 방법을 소개도 소개하였다. (AdamW 등등)
그렇기 때문에 처음 해야할 것은 vision transformer의 환경으로 ResNet 모델을 학습해서 baseline을 만드는 것이다.
- epoch 90 -> 300
- AdamW optimizer
- Mixup, Cutmix, RandAugment, Random Erasing 등의 데이터 기술
- Label smoothing, Stochastic depth 등의 regularization 기술
이를 통해 ResNet의 성능을 76.1%에서 78.8%로 올릴 수 있었다.
이후에도 학습되는 모델은 동일한 hyper param으로 진행한다.
2.2 Macro design
우선 Swin Transformer의 macro design부터 적용을 해본다.
Swin Transformer는 CNN이 다른 해상도의 feature map을 각각 stage에 분석하게 해준다.
여기에는 2가지 중요한 디자인 요소가 있다.
1. stage compute ratio
2. stem cell structure
Changing stage compute ratio.
원래 ResNet의 stage별 계산 분포는 경험적으로 이루어졌다.
Resnet의 4번째 stage의 경우 복잡하게 설계가 되었고 object detection등의 downstream task에 맞게 14x14의 feature map에서 구성이 되었다.
반면에 Swin Transformer는 동일안 원리에서 다른 계산 비율을 적용하였는데 1:1:3:1이고 더 큰 모델은 1:1:9:1이다.
이를 따라서 ResNet-50의 block 비율을
(3,4,6,3)에서 (3,3,9,3)으로 변경하였다.
이를 통해 Swin-T와 계산량이 비슷해졌고 모델의 정확도가 78.8%에서 79.4%로 증가하였다.
물론 추후에 이것보다 더 최적의 설계가 존재할 수 있다.
이제부터 이 계산 비율을 모델에 적용시켜서 진행을 한다.
Changing stem to “Patchify”.
Stem cell 디자인은 네트워크의 입력에서 어떻게 이미지를 처리할지 고민한다.
stem cell은 딥러닝에서 network의 input에 downsampling이나 feature 추출에 사용되는 부분이다.
ResNet의 경우 7x7 conv layer과 max pool을 통해 이미지를 4배 다운샘플링 한다.
vision transformer의 경우 kernel size 14, 16의 중첩되지 않는 convolution 과 같이 이미지를 patch화를 하는 방식으로 진행한다.
swin transformer의 경우 multi-stage design이 있기에 4x4의 이미지로 patch화를 한다.
이미지의 중복 성질 때문에 보통 CNN과 vision transformer 공통적으로 stem cell은 이미지를 적절한 크기로 강하게 down sampling을 하는 것으로 시작한다.
각각 방법은 위에 ResNet과 swin transformer에서 적용된 방법과 같다.
여기에서 ResNet의 7x7, maxpooling의 stem cell 부분을 4x4, stride 4의 conv layer로 patch화 같은 방법으로 변경하였다.
정확도는 79.4%에서 79.5%로 0.1% 상승하였다.
이는 ResNet의 stem cell을 ViT 스타일의 단순한 모양으로 바꾸어도 유사한 성능을 낼 수 있음을 뜻한다.
이제부터 이 stem cell을 network에 사용한다.
2.3 ResNeXt-ify
ResNeXt 논문리뷰에 ResNeXt에대한 내용이 있다.
ResNeXt에서 가장 중요한 부분은 group convolution이다.
group convolution이란?
우측 그림과 같이 filter에 각각 group을 할당하고 group에 대항하는 부분만 cnn을 적용하는 것이다.
ResNeXt는 이 group-convolution을 통해 더 나은 정확도를 얻을 수 있었다.
이 원리를 Resnet에 적용을 하려고 한다.
group convolution의 중요한 원리는 더 많은 그룹을 사용해서 width를 확장시키는 것이다.
연산을 그룹별로 쪼개기 때문에 연산이 줄어들게 되고 network의 넓이를 늘릴 수 있다.
여기에서는 group convolution의 특별한 경우인 depthwise convolution을 실행한다.
depthwise convolution은 group==channel이다.
즉이와 같이 channel 각각 별로 1개의 필터가 1개의 channel을 계산한다.
여기에서 중요한 부분은 depthwise convolution은 attention의 weighted sum과 비슷하다. 왜냐하면 각 정보에 가중치를 곱하고 더하기 때문이다. 결국 둘 다 공간차원에서 정보를 섞는다.
depthwisw conv와 1x1 conv는 채널과 공간의 분리를 만드는데 이는 vision transformer의 성질과도 같다.
이 부분이 이해가 가질 않았는데 여러번 읽어보니 이해가 되었다.
bottleneck에서 사용되는 depthwise conv와 1x1 conv의 조합은 채널과 공간 혼합의 분리를 만든다. 즉 depthwise에서는 각각 채널을 분리시키고 공간을 혼합하고 1x1 conv는 각각 채널을 혼합하고 공간의 분리를 진행한다.
이러한 특징은 vision transformer에도 있는데 multi head attention은 각 단어 자체의 정보를 혼합하는게 아니라 중요도를 계산해서 문맥의 내부에서 단어들의 관계의 정보를 고려해서 섞는 것이다.
그리고 linear layer로 단어 자체의 정보를 섞는다.
결국 공간과 차원 차원 각각의 연산을 나눈 것이다.
depthwise를 통해 계산량을 줄이고 이 줄었지만 예상했듯이 정확도가 줄어들게 되었고 이 줄인 계산량을 통해 network의 width를 늘리기 위해 channel을 Swin-T와 동일하게 늘렸다. (64 -> 96)
이를 통해 정확도가 80.5%로 상승하게 되었다.
앞으로 진행되는 network역시 위의 내용이 적용이된 채로 진행이 된다.
2.4 Inverted Bottleneck
transformer에서 적용된 중요한 design 중 하나는 inverted bottleneck이다.
즉 input보다 4배 더큰 inside layer를 가지는 linear layer이다.
transformer에는 실제로
(512, 2048), RELU, (2048, 512)로 진행되는 2개의 linear layer가 존재한다.
이는 input보다 더 큰 차원으로 넓히기 때문에 inverted bottleneck이라고 부른다.
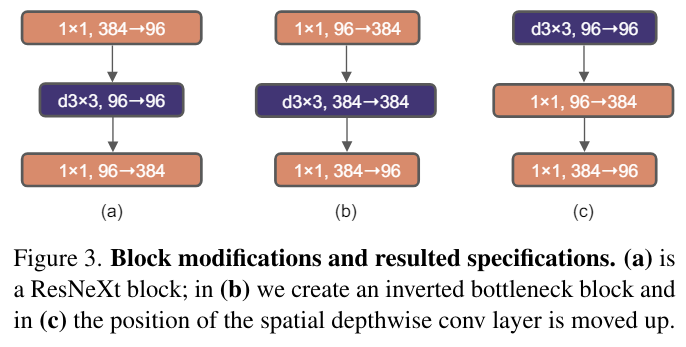 여기 주어진 이미지에서 (a)는 ResNeXt를 적용한 block이고 (b)는 inverted bottleneck으로 내부에서 커지는 느낌으로 진행이 된다.
여기 주어진 이미지에서 (a)는 ResNeXt를 적용한 block이고 (b)는 inverted bottleneck으로 내부에서 커지는 느낌으로 진행이 된다.
inverted bottleneck은 depthwise 연산을 증가시키지만 결국 1x1이 줄어들어서 전체에서 따지면 연산이 줄어든다.
이를 통해 성능이 80.5%에서 80.6%로 조금 증가하였다.
resnet200에서는 81.9%에서 82.6%로 많이 증가하였다.
지금부터는 inverted bottleneck을 적용시킨다.
2.5 Large Kernel Sizes
vision transformer의 가장 큰 특징은 non local self-attention이다.
layer가 global하게 본다는 것이다.
과거에 큰 kernel size(vgg net 등)가 사용되었지만 지금 가장 표준으로 쓰이는 것은 작은 kernel size(3x3)이다. 또한 3x3 conv layer는 현대 gpu에서 효율적으로 작동한다.
swin transformer에서 local window를 self-attention에 적용하는 것을 제시하기는 했지만 window는 최소 7x7으로 resnet의 3x3보다는 훨씬 크다.
다시 예전으로 돌아가 큰 size의 kernel을 쓰는 것을 검토해보자
Moving up depthwise conv layer.
큰 kernel을 사용하기 위해서는 가장 먼저 depthwise conv layer를 첫번째로 올려야 한다.
이는 transformer에서도 분명한 특징인데 Multi head attention이 Multi layer perceptron보다 먼저 나오기 때문이다.
우리가 inverted bottleneck을 채택했기 때문에 이는 매우 자연스럽고 비슷하게 구현이 가능해진다.
복잡하고 비효율적인 attention이나 large kernel은 적은 채널을 사용하고 효율적인 1x1 conv는 많은 채널을 사용한다.
이러한 변경은 계산량을 더욱 줄였지만 성능을 79.9%로 저하시켰다.
Increasing the kernel size.
이렇게 준비를 다 마치고 줄인 연산량을 통해 large kernel size를 적용했다.
여러가지를 테스트 했는데
3, 5, 7, 9, 11까지 테스트 했는데
3x3(79.9%)에서 7x7(80.6%)까지는 성능이 증가하였지만 이후에는 정체되었다.
이는 큰 모델에서도 마찬가지였다.
그렇기 때문에 앞으로 7x7 kernel size를 사용하였다.
2.6 Micro Design
이 부분에서는 activation이나 normalization 등 작은 단위로 변경을 한다.
Replacing ReLU with GELU
NLP와 vision에서 차이점 중 하나는 activation function이다.
ReLU는 간단하고 좋은 성능으로 예전부터 계속 사용되어왔고 초기 transformer의 구조에서도 채택이 되었다.
그러나 Gaussian Error Linear Unit(GELU)가 ReLU의 더 부드러운 종류로 나오게 되면서 BERT, GPT-2, ViT를 포함한 transformer의 구조에 채택이 되기 시작했다.
GELU는 이런 모양이다.
출처
공식은 다음과 같다.첫번째 공식은 원본인데 erf는 error 함수이다.
아래 공식은 위의 공식을 근사화 한 것이다.
ReLU 함수를 GELU로 대체했을 때 정확도는 80.6%로 유지했다.
Fewer activation functions.
또 사소한 차이 중 하나는 transformer는 적은 activation function을 가진다는 것이다.
transformer의 block 1개에는 activation function이 multi layer perceptron의 GELU/ReLU 1개만 존재한다.
그러나 CNN에는 각각 layer마다 activation이 존재하는데 이는 매우 많은 숫자다.
그렇기 때문에
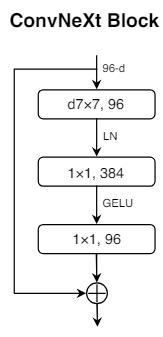 위 그림과 같이 1x1 block 사이에만 activation function을 넣었다.
위 그림과 같이 1x1 block 사이에만 activation function을 넣었다.
이는 transformer의 구조와 동일하다.
이러한 방식은 0.7%의 성능 증가를 가져와 81.3%의 성능을 보이게 만들었다.
이제부터는 각 block마다 single activation을 적용한다.
Fewer normalization layers.
transformer는 또한 적은 normalization layer를 가진다.
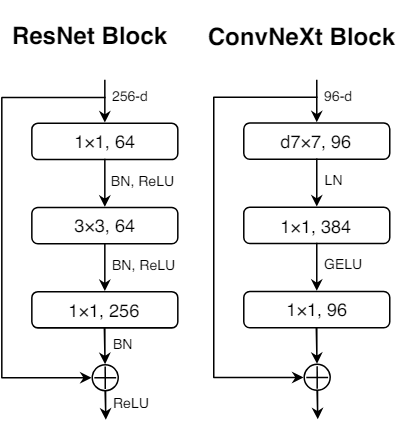 그렇기 떄문에 2개의 BN을 1x1 layer 전의 1개로 대체하였다.
그렇기 떄문에 2개의 BN을 1x1 layer 전의 1개로 대체하였다.
이는 81.4%로 0.1%의 증가를 가져왔으며 Swin-T의 정확도를 넘었다.
또한 block의 시작 부분에 activation을 넣는 것은 성능의 증가를 보여주지 않았다.
Substituting BN with LN.
BN은 ConvNet에서 중요하게 사용되며 convergence를 돕고 overfitting을 억제한다.
그러나 BN은 모델의 성능에 영향을 줄 수 있는 복잡성이 있다.
하지만 대체하기가 쉽지 않아서 vision에서는 계속 사용중이었는데 transformer에서 Layer normalization을 채택해서 더 좋은 성능을 내었다.
LN으로 BN을 직접적으로 바꾸면 ResNet은 최적이 아닌 결과를 낼 것이다.
왜냐하면 이러한 대체는 이미 연구가 되었기 때문이다.
그러나 이전에 우리가 바꾼 기술들을 바탕으로 대체를 해보았을 때에는 모델 학습에 어려움이 없었고 81.5%으로 성능의 향상이 존재했다.
이제부터는 LN을 BN대신 사용한다.
Separate downsampling layers.
ResNet에서는 downsampling이 각 stage에서 시작되는 start block에서 3x3 stride 3 conv로 구현이 되었다.(short cut에서는 1x1 stride 2)
그러나 Swin transformer에서는 각 stage에 downsampling layer가 추가가 되었다.
그렇기 때문에 비슷한 방식을 구현하기 위해 2x2 stride 2 conv layer로 구현을 하였다.
그러나 이 구현은 훈련을 불안정하게 만들었다.
추가적인 실험 후에 공간의 해상도가 바뀌는 곳에 정규화 레이어를 넣으면 학습이 안정화되는 것을 알게 되었다.
이러한 LN의 추가는 Swin-T에서도 적용이 되는 부분이다.
이러한 방식의 추가로 81.3%의 정확도가 82%까지 올릴 수 있었다.
이렇게 최종적으로 나온 모델을 ConvNeXt라고 이름을 지었다.
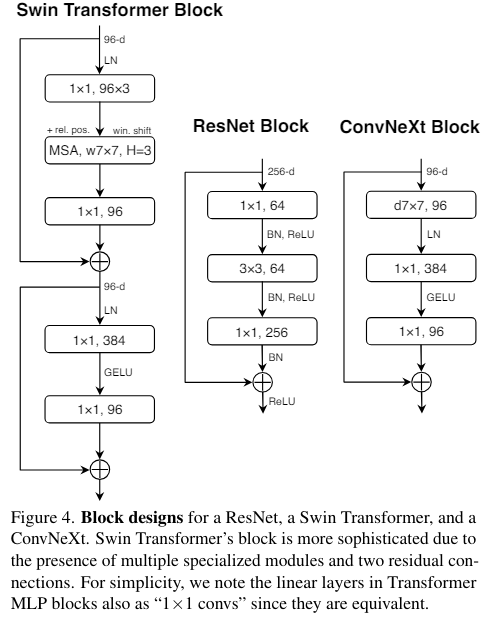 최종 비교 이미지 이다.
최종 비교 이미지 이다.
3. Empirical Evaluations on ImageNet
ConvNeXt를 테스트하기 위해
ConvNeXt-T/S/B/L/XL을 만들었다.
 각각 channel과 Block이 다르다. 이는 scalability를 테스트하기 위함이다.
각각 channel과 Block이 다르다. 이는 scalability를 테스트하기 위함이다.
3.1 Settings
ImageNet-1k는 1k의 class와 1.2M의 training sample이 존재한다.
ImageNet-1k의 validation dataset에서 top-1 정확도를 기준으로 테스트했다.
또한 ImageNet-22K의 21841의 class를 가지고 14M의 이미지를 가지는 데이터로 pretrain을 진행하고 ImageNet-1k로 fine-tune을 진행하고 텧스트를 또 하였다.
- 즉 그냥학습, pretrain 후 학습 2가지 경우 존재.
Training on ImageNet-1K.
pretrain 없이 그냥 학습하는 과정이다.
- ConvNeXt
- 300 epoch
- AdamW
- lr 4e-3
- 20 epoch linear warmup, cosine decaying
- batch 4096
- weight decay 0.05
- data augment -> Mixup, Cutmix, RandAugment, Random Erasing
- regularization -> Stochastic Depth, Label Smoothing
- layer scale initial value 1e-6
- Exponential Moving Average(EMA)
Pre-training on ImageNet-22K.
pretrain에는
- 90 epoch
- warmup 5 epoch
- no EMA
나머지는 fine-tune과 동일
Fine-tuning on ImageNet-1K.
pretrain한 모델로 fine-tune 진행
- 30 epoch
- AdamW
- lr 5e-5
- cosine lr schedule, no warmup
- layerwise learning rate decay
- batch size 512
- weight decay 1e-8
- default resolution , high
3.2 Results
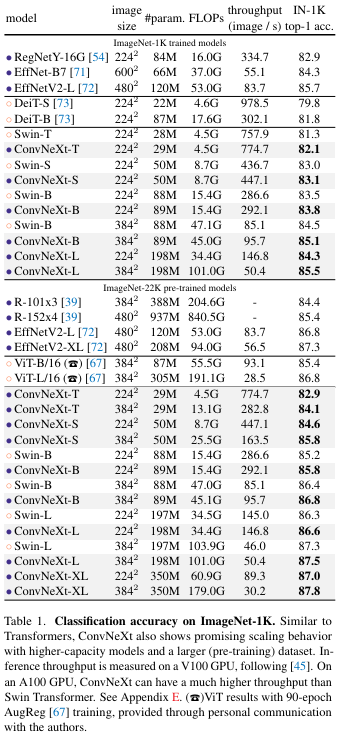
ImageNet-1k에서 매우 좋은성능을 내었다.
구현
class ConvNeXtblock(nn.Module):
def __init__(self, in_channel, out_channel, image_size):
super().__init__()
self.in_channel = in_channel
self.out_channel = out_channel
if in_channel != out_channel:
self.downsample = nn.Conv2d(
in_channel, out_channel, kernel_size=2, stride=2)
self.seq = nn.Sequential(
nn.Conv2d(out_channel, out_channel, kernel_size=7,
padding=3, groups=out_channel),
nn.LayerNorm([out_channel, image_size, image_size]),
nn.Conv2d(out_channel, out_channel*4, kernel_size=1),
nn.GELU(),
nn.Conv2d(out_channel*4, out_channel, kernel_size=1),
)
def forward(self, x):
if self.in_channel != self.out_channel:
x = self.downsample(x)
return self.seq(x) + x
class ConvNeXt(nn.Sequential):
def __init__(self, class_num=10):
super().__init__(
# 원본은 kernel 4 stride 4 지금은 2 2로 변경
nn.Conv2d(3, 96, kernel_size=2, stride=2, padding=0,
bias=False), # 3x32x32 -> 96x16x16
# 블럭 비율 1:1:3:1 -> 2:2:6:2
ConvNeXtblock(96, 96, image_size=16),
ConvNeXtblock(96, 96, image_size=16),
ConvNeXtblock(96, 192, image_size=8), # 96x16x16 -> 192x8x8
ConvNeXtblock(192, 192, image_size=8),
ConvNeXtblock(192, 384, image_size=4), # 192x8x8 -> 384x4x4
ConvNeXtblock(384, 384, image_size=4),
ConvNeXtblock(384, 384, image_size=4),
ConvNeXtblock(384, 384, image_size=4),
ConvNeXtblock(384, 384, image_size=4),
ConvNeXtblock(384, 384, image_size=4),
ConvNeXtblock(384, 768, image_size=2), # 384x4x4 -> 768x2x2
ConvNeXtblock(768, 768, image_size=2),
nn.AvgPool2d(2), # 768x2x2 -> 768x1x1
nn.Flatten(),
nn.Linear(768, class_num),
)
