Abstract
- 이 논문에서는 tabular 데이터의 지도학습, semi-지도학습을 위해 새로운 아키텍쳐인 TabTransformer를 제시한다.
- Tabtransformer는 self-attention based model이고 transformer layer는 높은 정확도를 위해 categorical embedding을 robust contextual embedding으로 변환한다.
- 모델은 기존 모델 대비해서 1%의 성능 향상을 보이고 앙상블 모델과 비슷하다.
- 모델이 학습하는 contextual embedding은 missing, noisy 데이터에 robust하고 높은 해석능력을 보인다.
- semi-supervised setting에서 unsupervised pre-training 과정을 통해 contextual embedding을 학습하는 과정을 개발하였다.
1. Introduction
tabular data는 추천시스템, 온라인 광고 등 다양한 분야에서 가장 많이 사용되는 데이터이다.
현재 tabuler의 SOTA 모델은 앙상블 베이스의 방법을 사용한 gradient boosted decision tree이다.
tree based model은 학습이 쉽고 높은 정확도를 보이고 결과를 이해하기 쉽지만 딥러닝 모델에 비해서 한계가 존재한다.
- 스트리밍 데이터에서 지속적인 학습이 힘들다.
- tabular data의 image/text를 한번에 학습하는 multi modality를 달성하기 비효율적이다.
- 기본 형태의 tree 모델은 SOTA semi-supervised learning에 적합하지 않다. (트리 모델이 믿을 수 있는 확률 추청치를 제공하지 않기 때문에)
- deep learning 모델의 SOTA noisy, missing data feature 처리 방법이 tree에는 적용되지 않는다.
- tree 모델의 robustness는 많이 다루어지지 않았다.
MLP가 경사하강법으로 encoder에서 이미지/텍스트의 end-to-end 학습이 되어서 인기가 많다.
MLP는 카테고리에 learnable embedding을 추가해서 학습을 하지만 모델자체의 얕음과 문맥이 없는 embedding이 있음으로 다음 한계가 존재한다.
- 모델과 학습된 embedding의 의미를 이해할 수 없다.
- NULL과 noise에 약하다
- semi-supervised learning에서 좋은 성능을 내지 못한다.
대부분 MLP는 GBDT 등 tree 기반 모델에 비해서 성능이 나오지 않는다.
이를 극복하기 위한 다양한 방법이 제시되었지만 GBDT와 MLP 둘의 한계점을 극복하지 못하였고 특정 설정, 데이터에 집중되어 있었다.
이 논문에서는 TabTransformer을 제시해서 MLP와 GBDT 사이의 차이를 해결한다.
TabTransformer 설명
TabTrasformer는 각각 카테고리에 따른 contextual embedding을 학습하기 위해 transformer를 활용하였다.
transformer를 tabular 도메인에 활용한 이유는 다음과 같다.
- contextual free emedding을 활용한 모델과 다르게 contexual embedding을 활용한 모델은 다양한 영역에서 더 좋은 성능을 내었다.
- self-attention을 활용한 transformer 기반의 모델은 nlp분야에서 SOTA의 성능을 내고있다.
- transformer에 의해서 학습된 contextaul embedding의 효율성과 의미를 이해는 매우 잘 연구되었다.
transformer를 통해서 학습된 contexual embedding에서 높은 상관관계를 가지는 특성들이 유클리드 거리에서 가까운 임베딩 벡터를 가지는 반면 MLP에서 context free embedding에서는 이러한 경향성이 보이지 않았다.
이러한 contextual embedding은 null, noise에도 잘 작동하였다.
semi-supervised learning
vision, Nlp 분야의 SOTA semi-supervised learning model을 tabular에 확장시키기 어려웠는데 이러한 이유로 언어모델의 pre-training 방법을 통해 unlabeled data를 활용해 TabTansformer에 semi-supervised learning의 방법을 제시하였다.
이 논문에서 제시하는 semi-supervised learning 방법의 가장 큰 장점은 다음과 같다.
- 2개의 독립된 학습 phase
학습이 un-labeled 데이터를 활용한 costly pre-train 과정과 labeled data를 활용하는 lightweight fine-tune 과정으로 나뉜다.
이는 기존의 1개의 phase와 unlabeled, labeled dataset을 가지는 기존의 SOTA semi-supervised learning과는 다르다.
이는 모델을 pre train을 한번만 진행하고 multiple domain에 따라서 여러번 fine-tune을 진행해서 사용할 수 있게 만들어준다.
2. The TabTransformer
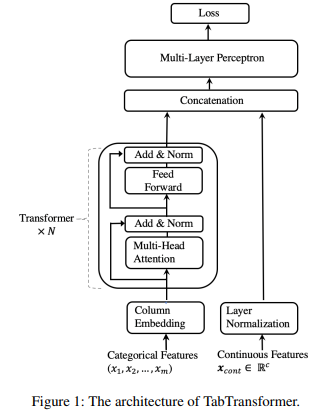
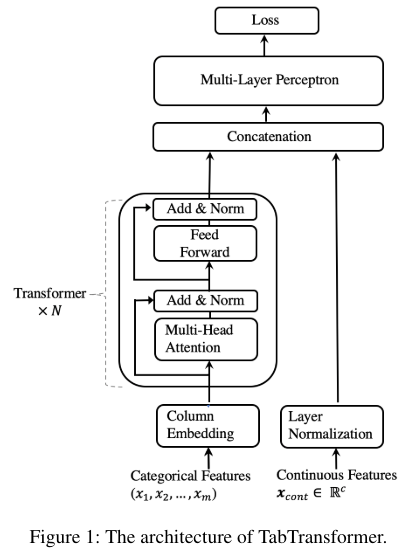 TabTransformer는 N개의 transformer과 MLP로 구성되어있다.
TabTransformer는 N개의 transformer과 MLP로 구성되어있다.
transformer layer의 구조는 그냥 encoder로 보인다.
input을 categorical과 continuous로 나누는데
categorical은 m개의 feature가 있다면 이를 d의 dim으로 parametric embedding을 할당한다.수식으로 다음과 같다.
그리고 으로 모든 categorical feature에 대한 embedding set을 표현한다.
이제 parametric embedding은 transformer를 거치면서 contextual embedding으로 변환이 된다.
transformer layer의 sequence는 로 표현한다.
이렇게 나온 contextual embedding 으로 표현이 되고 각각 차원은 으로 된다.
이러한 contextual embedding을 continuous feature을 합쳐서 concat해서 붙여줘서 의 차원을 구성한다
여기에서 d는 contextual embedding의 차원, m은 categorical feature의 개수, c는 continual feature의 개수이다.
그리고 concat한 내용은 MLP를 통과한다.
mlp는 로 표현한다.
loss는 classification에서는 cross-entropy이고 regression에는 MSE이다.
모든 과정을 수식으로 나타내면 다음과 같다.
transformer
Transformer의 설명은 이전에 작성한 attention is all you need를 참고하면 된다.
Column embedding
번째 categorical feature는 의 embedding lookup table을 가지는데 개의 class를 가지는 i번째 feature는 의 테이블에 missing 값을 포함한 개의 embedding을 가진다.
여기에서
각 encoded value 에 대해서 embedding은
로 구성이 된다. 여기에서 이고 로 구성이 된다.
여기에서 unique identifier로 불리는 은 각각 다른 column의 class와 현재 column의 class를 구별하는 역할을 한다.
는 한 column 내부의 class를 구별하는 embedding 이다.
의 의미는 성별, 직업과 같이 각 categorical feature의 의미가 다를 수 있을 때 이를 구별하기 위해 각 column embedding에서 얼마나 column embedding을 공유할지를 정하는 hyper param이다.
추가로 와$를 연결하는 것이 아닌 더하는 전략도 존재한다.
Pre-training and Embeddings.
위에서 설명한 embedding은 labeled data를 활용한 supervised learning에서 학습이 된다.
그러나 작은 수의 labeled data와 많은 un-labeled data가 있을 때 un-labeded data를 활용해 transformer layer를 학습하는 pre-train을 소개한다.
우선 fine-tune에서는 학습된 transformer layer를 활용해서 MLP layer도 학습이 진행되고
이 수식에 따라서 학습이 진행된다.
pretrain의 방법은 2가지로 나눌 수 있다.
-
Masked language modeling(MLM) : feature 중 k %를 mask 처리하고 missing으로 보는 것. column embedding과 transformer layer는 multi class classifier의 cross entropy loss를 낮추기 위해 masking 된 feature을 예측한다.
처음에 MLM의 구현이 어떻게 구성이 되는지 헷갈렸는데 다음과 같이 되는 것으로 생각된다.
input x의 shape가 (batch, feature)일 때
특정 k%를 masked_indice으로 missing처리를 하고 embedding을 통과시킨다.
그러면 (batch, feature, d_model)의 shape가 되는데
이제 transformer를 우루루 통과를 시키고 마지막에 linear layer를 1개 두어서 (batch, feature, class_num)으로 만들고 masking 된 idx를
다음과 같이 가져오면 된다.mlm_loss = nn.CrossEntropyLoss()( mlm_output[masked_indices], x[masked_indices] )이러면 x는 (mask_num)의 shape가 되고 mlm_ouput은 (masked_num, class_num)이 되어서 multi clas classifier가 된다.
-
replaced token detection(RTD) : RTD는 masking하는 대신에 feature의 원래 값을 다른 랜덤한 값으로 바꾼다. 여기서 loss는 특성이 대체되었는지 아닌지 확인하는 binary classifier이다.
RTD에서 제시된 특정 방법 중 하나는 보조 generator를 사용해서 replace 되어야할 feature의 subset을 sampling을 한다.
그리고 각 categorical feature의 class가 제한되고
각각 column에 binary classifier가 적용이 된다. 왜냐하면 각 column마다 embedding lookup table이 존재하기 때문보조 생성기를 사용하는 이유는
언어 데이터에 수천개의 토큰이 있을 때 무작위로 선택된 토큰이 정규분포를 따른다면 너무 쉽게 감지되기 때문이다.
결국 조금 더 복합한 문제를 풀게하기 위함이다.
실험에 따르면 k는 30%가 적절하다.
3. Experiments
data
평가는 15개의 UCI, AutoML, Kaggle의 binary classification dataset으로 진행을 하였고
supervised, semi-supervised learning 전부 테스트를 하였다.
데이터는 5개의 cross-validation set으로 나누었고
training/validation/test 의 비율은 65%/15%/20%이다.
categorical feature의 개수는 2~136으로 분포가 되어있다.
semi-supervised 에서 처음 p개의 training data는 labeled이고 나머지는 unlabeled이다.
p는 50, 200, 500으로 구성이 된다.
supervised는 당연히 전부 labeled이다.
Setup
embedding 차원: 32
layer 숫자: 6
attention head number: 8
MLP layer size: (은 input의 size)
hyperparameter optimization (HPO): 각 cross-validation split당 20번
evaluation metric: Area under the curve (AUC)
pretraining은 semi-supervised에만 사용
모든 데이터가 labeled일 때 사용했을 때에는 이득이 없음
대부분의 데이터가 unlabeled, 일부가 labeled일 때 이득이 존재
-> labeled 만 가지고 학습하지 못한 데이터 표현을 학습하기 때문
AUC는 ROC curve의 아래 부분이라고 한다.
ROC curve는
x-False Positive Rate(긍정이라고 답했지만 틀린경우->1-특이도),
y-True Positive Rate(긍정이라고 답했고 맞은경우->민감도)
의 그래프이며
이미지 출처
위 그림과 같이 구성이 되며 노란색은 참이라는 결과를 내었을 때 맞은 경우와 틀린 경우가 반반이라는 뜻이고 파란색은 더 맞은 경우이다. 완벽한 경우는 모두 정답인 경우이다.
AUC는 ROC의 아래 넓이이다. 1에 가까울 수록 더 좋은 모델이다.

3.1 The Effectiveness of the Transformer Layers
이 부분에서는 transformer layer를 뺀 것과 넣은 것을 비교
 transformer layer를 넣은 것이 더 성능이 잘 나온다.
transformer layer를 넣은 것이 더 성능이 잘 나온다.
그리고 contextual embedding을 분석하기 위해 transformer의 특정 layer에서 모든 column에 대해서 contextual embedding을 가져오고 이를 t-SNE 방법으로 차원을 낮추면서 visualize해서 유사도 분석을 하였다.
각 그림에서 점은 특정 test data에서 특정 class별로 embedding의 2D 위치를 평균화 해서 나타낸 것이다.
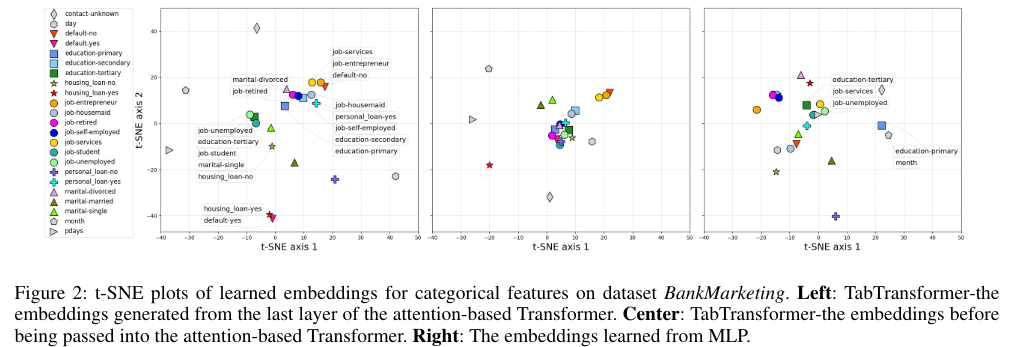 왼쪽 그림은 transformer layer 이전이고 가운데는 transformer layer 전이고 오른쪽인 MLP에서 학습된 embedding이다 즉 context free embedding이다.
왼쪽 그림은 transformer layer 이전이고 가운데는 transformer layer 전이고 오른쪽인 MLP에서 학습된 embedding이다 즉 context free embedding이다.
그림에서 보다시피 의미적으로 유사한 class는 비슷한 위치에 있다.
예를 들어 왼쪽 그림에는 client의 정보를 설명하는 job, martial, education 등은 중심에 있거나 가깝게 있지만 month, day 등의 정보는 멀리 떨어져있다.
또한 밑에는 주택 담보 대출과 default 즉 채무불이행이 가깝게 위치해 있다.
그리고 가운데의 transformer에 들어가기 전의 정보 또한 client based 정보와 아닌 것이 구분이 되어 있다.
그러나 context free embedding인 오른쪽의 그림은 불규칙적으로 위치해 있다.
다른 방법으로 transfomer layer의 효과를 증명하기 위해 각 transformer layer을 통과하는 embedding을 뽑아내서 그 embedding과 continuous variable을 붙이고 linear layer을 학습시켜 보았다.
 결과는 위와 같은데 layer를 통과할 때마다 성능이 좋아진다.
결과는 위와 같은데 layer를 통과할 때마다 성능이 좋아진다.
그림의 검정색은 embedding을 MLP로 학습하였을 때인데 이때에는 매우 안좋은 성능을 내었다.
3.2 The Robustness of TabTransformer
null, noise에도 강건하게 작동하는지 테스트를 진행하였다.
transformer의 강건함을 설명하기 위함이므로 여기에서 missing, noise는 categorical feature에만 적용을 하였다.
Noisy Data.
test 데이터에서 특정 값을 해당 feature에서 무작위로 만든 값으로 대체하는 식으로 오염을 시킨다.
그리고 TabTransformer와 MLP에 각각 통과시키고 결과를 확인한다.
 결과를 보면 noise가 증가할수록 TabTrasformer가 더 좋은 성능을 내었다.
결과를 보면 noise가 증가할수록 TabTrasformer가 더 좋은 성능을 내었다.
특히 노란색 Blastchar에서는 MLP보다 확연하게 더 좋은 성능을 내었다.
결국 TabTransformer가 더 robust하다.
이러한 robustness는 contextual embedding에서 온다고 생각한다.
noise가 있음에도 정상인 feature에서 올바른 정보를 이끌어낼 수 있기 때문이다.
Data with Missing Values.
이번에는 이전에 다른 값으로 바꾸는 것 대신에 missing 값으로 채우고 실험을 하였다.
이때 missing을 넣는 방법은 2가지인데
- column의 모든 class의 embedding의 평균을 사용
- column의 missing class embedding을 사용
학습 데이터셋에는 missing class가 얼마 존재하지 않아서 missing embedding을 제대로 학습할 수가 없어서 (1)번 즉 평균을 사용하여서 실험을 진행하였다.
 이 경우에서도 tabtransformer가 더 좋은 성능을 내었다.
이 경우에서도 tabtransformer가 더 좋은 성능을 내었다.
3.3 Supervised Learning
TabTransformer와 다른 모델들 비교
- logistic regression and GBDT
- MLP, sparse MLP
- TabNet
- VIB
 TabTransformer, MLP, GBDT가 top 3이다.
TabTransformer, MLP, GBDT가 top 3이다.
좋은 성능을 보였다.
3.4 Semi-supervised Learning
소수의 labeled, 다수의 unlabeled 데이터로 학습
이전에 제시한 pretrain -> fine-tune 방법으로 학습한 TabTransformer-RTD/MLM 모델을 다른 semi-supervised learning 모델과 비교
- Entropy Regularization + MLP, TabTransformer
- Psedo Labeling + MLP, TabTransformer
- MLP(DAE): the swap noise Denoising AutoEncoder -> deep learning 모델의 tabular data 비지도 학습을 위해 고안된 방법
여기에서 TabTransformer-RTD/MLM, MLP(DAE)는 우선 pretrain을 진행하고 이후에 fine-tune을 진행한다.
Psedo Labeling, Entropy Regularization은 labeled, unlabeled data를 합쳐서 학습한다.
결과는 다음과 같다.
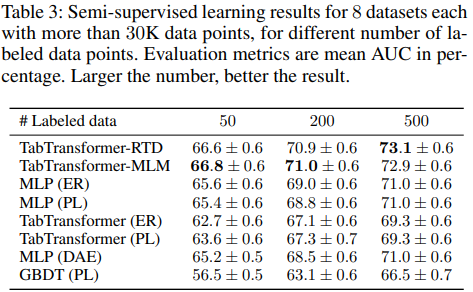 데이터의 숫자가 30K보다 많을 때 즉 unlabled data가 많을 때 모든 모델보다 더 좋은 성능을 보였다.
데이터의 숫자가 30K보다 많을 때 즉 unlabled data가 많을 때 모든 모델보다 더 좋은 성능을 보였다.
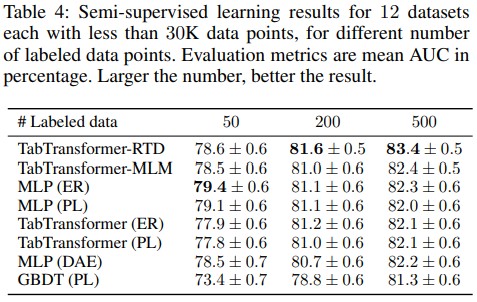 다음은 데이터 숫자가 적을 때 즉 unlabeled data가 적을 때의 성능인데 이전보다는 적은 차이지만 역시 좋은 성능을 보여준다.
다음은 데이터 숫자가 적을 때 즉 unlabeled data가 적을 때의 성능인데 이전보다는 적은 차이지만 역시 좋은 성능을 보여준다.
- 여기에서 보면 unlabled data가 적을 때 RTD가 MLM보다 더 좋은 성능을 보였다. 이는 RTD는 간단한 binary classification이 되지만 MLM은 어려운 multi-classification이 되기 때문이다. 이 내용은 ELECTRA paper에도 있다고 한다.
- Labeled data가 적을 때 MLP(ER), MLP(PL)이 더 좋은 성능을 낸 이유는 논문에서 제시한 pre-train과정에서 unlabeled data를 학습할 때 information embedding을 얻는데 사용하는데 이 과정에서 classifier 자체는 weight 학습이 진행되지 않기 때문이다. 그러나 이는 ER, PL에는 발생하지 않는 문제이다.
이는 이제 앞으로의 fine-tune으로 더 좋은 성능을 얻을 수 있음을 보여준다. 50 labeled data는 이점을 얻기에 너무 적은 데이터였기 때문
4. Conclusion
이 논문에서는 Transformer를 활용한 TabTransformer 구조와
모델에 적용이 가능한 pretrain 방법론을 제시해서 기존의 tree-based ensemble model(GBDT)와 비슷한 성능을 이끌어내었다.
또한 2 phase의 pretrain 방법론을 제시하였고 기존 SOTA semi-supervised learning 방법들과 비슷한 성능을 보였다.
