논문의 흐름을 100% 따라가지 않고 그냥 나름대로 배우고 느낀 내용을 적어보겠다.
요약
기존 diffusion에서 time step을 생성하는 sequence에 대해서도 각각 독립적으로 유지해서 autoregressive하게 생성이 가능하게 학습
Introduction
diffuser에서 보았듯이 diffusion을 통한 action,state의 생성을 통한 policy, planner의 통합이 가능하다.
또한 autoregressive한 데이터의 생성을 통한 planning도 가능하다.
이 논문은 diffusion forcing을 제시하는데 diffusion forcing은 두 가지 경우를 통합한 것이다.
즉, diffusion처럼 생성을 하는 동시에 autoregressive하게 데이터를 생성하는 식으로 진행이 되는 것이다.
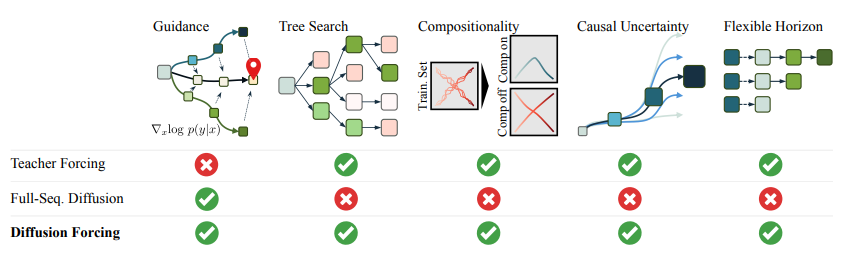 두가지 모두 가능하기에 diffusion forcing은 두 가지 장점을 모두 가진다.
두가지 모두 가능하기에 diffusion forcing은 두 가지 장점을 모두 가진다.
그런데 여기에서 이상한 부분이 있었는데 diffuser도 3번째 compositionality가 가능했는데 이게 안된다고 적혀있었다.
논문의 내용을 읽어보니 diffuser의 내용을 조금 바꿔서 기존의 diffuser은 1step 마다 다시 생성을 하는 것이었는데 여기에서는 전체 sequence를 즉시 생성하는 것으로 생각하는 것 같다.
실제로 Full-Seq Diffusion이라고 적혀있다.
Method
간단하다.
기존의 diffusion은 모든 time step(그림의 row, 각 state이다.)에 noise가 동일한 비율로 들어갔다면(4번째 그림)
diffusion forcing은 각 state의 noise를 독립적으로 보고 학습한다.
(아래 그림 2번째 그림)
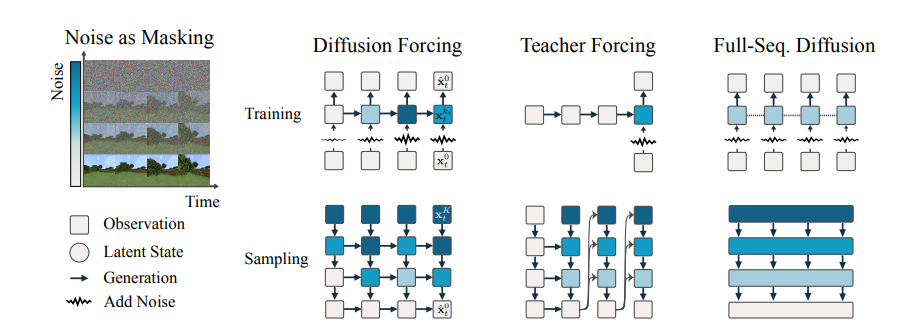
이렇게 각 state의 noise가 독립적이기에 state의 noise의 정도에 상관없이 autoregressive하게 데이터의 생성이 가능하다.
그냥 다음 step의 데이터 noise를 1개 더 붙이면 되기 때문.
학습 코드
학습을 보면 이해가 쉬운데
 각 state에 noise의 level 를 각각 sampling을 진행한다.
각 state에 noise의 level 를 각각 sampling을 진행한다.
이후 이를 복구하는데 여기에서 t는 각 state의 sequence 번호이다.
각각 다른 noise 단계를 가진 state sequence를 복구하는 것이다.
샘플링

샘플링은 사실 하기 나름인데 위 경우에는 기존 Diffusion처럼 진행을 한 경우이다.
이때 는 로 구성된 Noise의 scheduling이다.
이렇게 각각 다른 Noise의 정도를 가진 state들의 sequence를 복구하는 것이다.
m은 row이고 t는 column이라고 생각하면 편하다.
재밌는건 각 state가 독립적인 noise를 가지게 학습을 하였기에 sampling을 다양하게 가능한데

위 그림을 보면서 하나씩 설명하자면
- stable auto-reg는 autoregressive처럼 진행하는데 이전 state에서 가 거의 복구가 다 되었을 때를 기준으로 다음 state를 생성한다.
- diffuse with causal uncertainty는 이전 future state를 noisy하게 유지 하면서 이전의 state를 복구하여서 causal 즉 인과관계를 좀 더 정확하게 유지하면서 미래의 추측이 가능하다.
- Full traj guidance는 재밌는 부분인데
현재의 state 를 guidance하기 위해서 를 여러가지 경우를 sampling하고 이들의 gradient 평균으로 guidance가 가능하다는 것이다.
즉 미래 sample의 여러가지 경우의 수를 고려할 수 있다는 것이다. - 그림에서 오타인지 모르겠는데 corrupted 즉 오염된 분포에서도 noisy한 상황이라고 보고 샘플링이 된다는 것이다.
Experiments
 maze 문제를 보면 비교가 쉬운데
maze 문제를 보면 비교가 쉬운데
diffuser은 전체 sequence를 한번에 생성한다면 diffusion forcing은 순차적으로 생성한다.

결과는 diffusion forcing이 기존의 diffuser를 압도적으로 이긴다.
근데 여기에서 이해가 잘 안가는 부분이 내가 diffuser 논문을 읽었을 때에는
각 step마다 다시 생성해서 action을 진행하는 것으로 알고있는데
diffuser with diffused action을 보면
전체 sequence, action fair를 한번에 생성하고 그대로 진행을 했을 때 인과관계가 제대로 맞지 않는다고 지적한다.
이는 처음부터 끝까지 한번에 생성하고 계속 그 sequence를 따라가는 것으로 생각하고 실험한 것 같다.

추가로 위는 사과 옮기기 문제인데
처음 image에서 특정 부분으로 옮기기 위해서 중간에 다른 통에 두고 옮기는 것인데
이는 memory가 없으면 불가능한 것이다.
그런데 재밌는건 앞에서 따로 언급은 안했지만 diffusion forcing은 rnn을 통해서 과거 sequence의 정보를 latent에 저장하기 때문에 memory를 가질 수 있다.
하지만 memory가 없는 모델은 불가능하다.
