논문링크
지난번에 이어서 이번에도 세미나를 준비하며 notion에 작성한 다음 옮겼기에 글자가 이상할 수 있다.
요약
D3PM의 absorb Noise를 활용한 Text 생성에서 assumption을 추가해서 Rao-Blackwellized를 활용한 objective를 만들었다.
추가로 continuous time diffusion, DiT 등 다양한 기술을 추가하였고
기존 diffusion 기반 text 생성 모델을 outperform하는 성능을 얻었음
1 Introduction
diffusion model은 autoregressive와 다르게 한번에 생성하기 때문에 long-term planning, controllable generation, sampling speed에서 뛰어나다.
하지만 discrete diffusion은 AR에 비해서 성능이 떨어진다.
이 논문은 Masked Diffusion Language Model(MDLM)을 제시함. 이전의 D3PM의 text generation을 개선한 것으로 생각하면 된다.
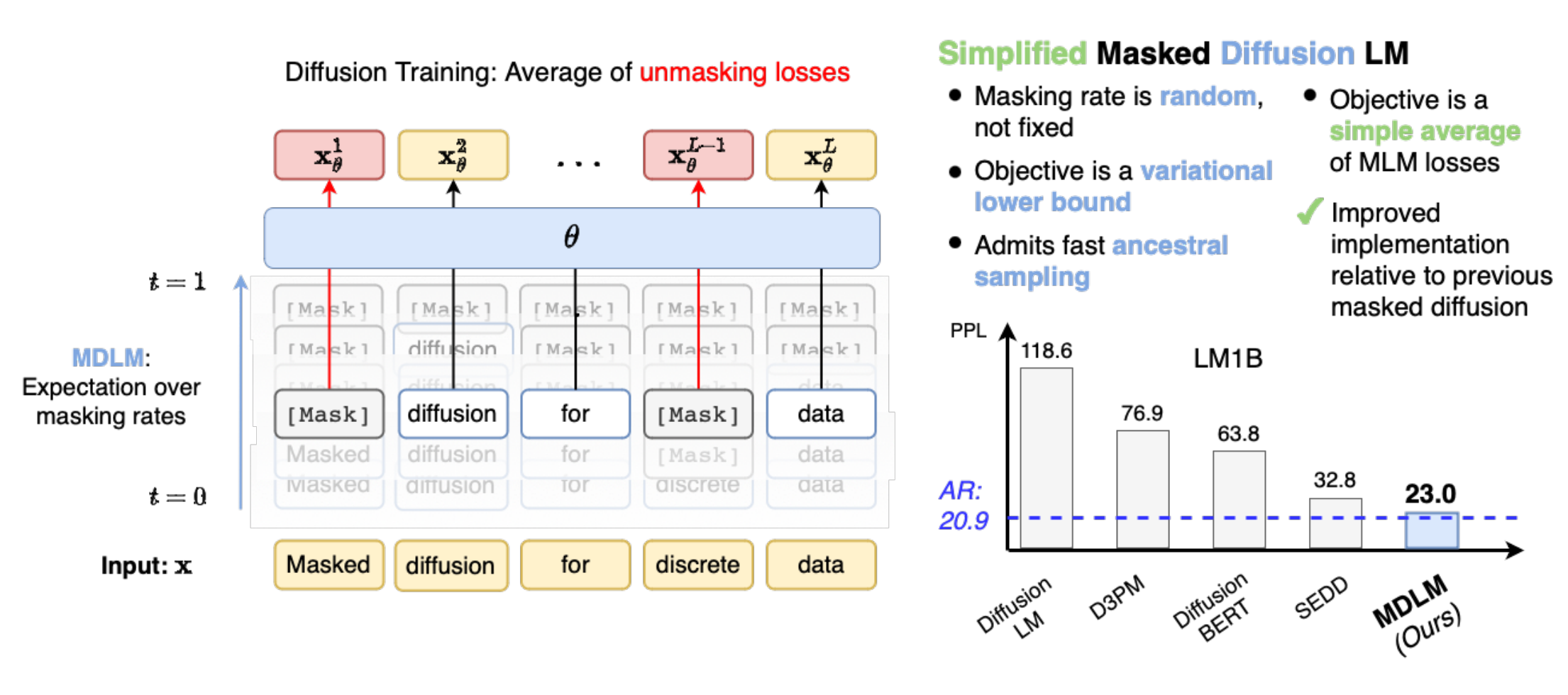
위처럼 구성
reverse diffusion process를 Rao-Blackwellized continuous-time variational lower bound로 더욱 tight하게 만들었다.
Background
diffusion에 대한 내용이다.
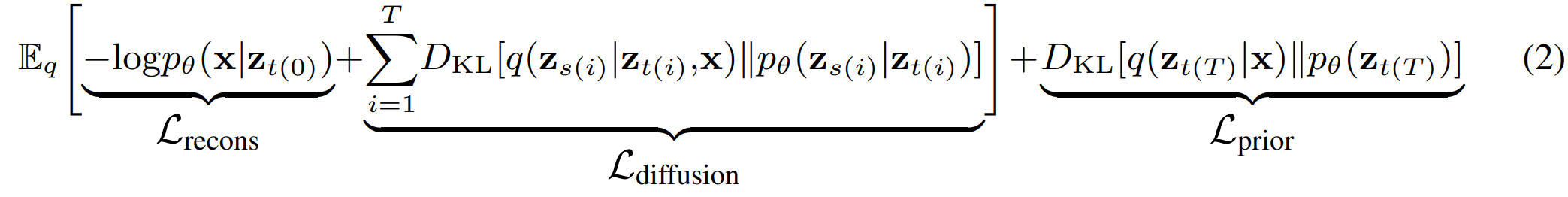
위 내용은 Negative ELBO(NELBO)이다.
아래 내용은 Discrete Diffusion에 대한 내용인데
q(zt∣x)=Cat(zt;Qˉtx)=Cat(zt;QtQt−1...Q1x)로 이전에 D3PM의 Qˉt=Q1Q2...Qt와는 반대 방향으로 표기가 되어있다…
3 Simple Masked Diffusion Models
이전 D3PM에서 absorbing state가 뛰어난 성능을 보였는데 이를 Rao-Blackwellized objective로 수정해서 더 좋게 바꿨다고 하는데 앞에 대한 이해가 필요하기에 한번 천천히 보자.
- Notation: π(prior vector, uniform, absorb 등…)
3.1 Interpolating Discrete Diffusion
이 논문에서는 continuous time에 대해서도 다뤄야 하기 때문에 특이하게 Q를 설정한다
여기에서 다 설정하고 가겠다.
s<t에서
Qt∣s=αt∣sI+(1−αt∣s1π⊤)이라고 하면
q(zt∣zs)=Cat(zt;Qt∣s⊤zs)=Cat(zt;[αt∣sI+(1−αt∣s)1π⊤]⊤zs)=Cat(zt;αt∣szs+(1−αt∣s)π1⊤zs)=Cat(zt;αt∣szs+(1−αt∣s)π).
이다. 중간에 1⊤zs=1이다.
여기에서 논문에 처음 zt=Qtzt−1이라고 해놓고 왜 Q⊤을 넣는지는 모르겠다 오타인가?
뒤에서는 Q⊤을 기준으로 계속 진행된다.
q(zs∣zt,x)= Cat(zs; zt⊤Qt⊤x(Qt∣szt)⊙(Qs⊤x))인데 이것은 D3PM 논문에 유도과정이 나와있었다.
유도
이 논문은 D3PM이랑 표기가 달라서 다시 유도해보자면
q(zs∣zt,x)=q(zt∣x)q(zt∣zs,x)q(zs∣x)=q(zt∣x)q(zt∣zs)q(zs∣x)=zt⊤Qt⊤xQt∣szt⊙Qs⊤x이다.
이를 처음 식으로 풀어서 적으면
q(zs∣zt,x)=Cat(zs;zt⊤[αtI+(1−αt)1π⊤]⊤x[αt∣sI+(1−αt∣s)1π⊤]zt⊙[αsI+(1−αs)1π⊤]⊤x)=Cat(zs;zt⊤[αtx+(1−αt)π1⊤x][αt∣szt+(1−αt∣s)1π⊤zt]⊙[αsx+(1−αs)π])=Cat(zs;αtzt⊤x+(1−αt)zt⊤π[αt∣szt+(1−αt∣s)1π⊤zt]⊙[αsx+(1−αs)π]).
이다.
pθ(zs∣zt)=q(zs∣zt,x=xθ(zt,t))=Cat(zs;zt⊤Qt⊤xθ(zt,t)(Qt∣szt)⊙(Qs⊤xθ(zt,t))).
이다. 간단하게 위 식에서 xθ(zt,t)로 x를 모델링 한 것이다.
3.2 Masked Diffusion
Absorb Noise에 따라서 masking된 diffusion에 대한 설명
3.2.1 Forward Masking Process
absorb stete등의 masked diffusion에서 π=m이다.
여기에서 reverse를 진행할 때 다음과 같은 분포를 따르게 되는데
q(zs∣zt,x)= { Cat(zs;zt) Cat(zs;1−αt(1−αs)m+(αs−αt)x)if zt=m,if zt=m.
의미는 zt가 maked token이 아니면 그냥 그대로 진행하고 만약 masked token이면 1−αt1−αs의 확률로 masking되고 1−αtαs−αt의 확률로 원본을 복구한다.
왜 그렇냐면
q(zs∣zt,x)=Cat(zs;αtzt⊤x+(1−αt)zt⊤π[αt∣szt+(1−αt∣s)1π⊤zt]⊙[αsx+(1−αs)π]).에서
-
case 1) zt=x인 경우 위식에 대입하면
x⊤m=0이기 때문에
Cat(zs;αtx⊤x+(1−αt)x⊤m[αt∣sx+(1−αt∣s)1m⊤x]⊙[αsx+(1−αs)m])=Cat(zs;αt[αt∣sx]⊙[αsx+(1−αs)m])=Cat(zs;αtαtx)=Cat(zs;x)가 된다.
-
case2) zt=m인 경우
q(zs∣zt=m,x)=Cat(1−αt(αt∣sm+(1−αt∣s)1)⊙(αsx+(1−αs)m))=Cat(1−αtαt∣s(1−αs)m+(1−αt∣s)(1−αs)m+(αs−αt)x)=Cat(zs;1−αT(1−αs)m+(αs−αt)x)
를 만족하고
여기에서
q(zs=x∣zt=m,x)=1−αtαs−αt
q(zs=m∣zt=m,x)=1−αt1−αs를 보인다.
3.2.2 Reverse Unmasking Process
생성은 Noise로부터 복구하는 것인데 pθ(zs∣zt)로 q(zs∣zt,x)를 근사해서 진행하게 되는데 q(zs∣zt,x)가 x에 condition이 되어있는데 우리가 x를 잘 모르니까 xθ(zt,t)를 근사해서 network를 만들었고 이를 이용해서 posterior를 추정하는 것이다.
여기에서 만약 time에 대한 dependency t를 제외하면 inference speed를 2배 더 빠르게 할 수 있다는 이야기
3.2.3 SUBS Parameterization
위에서 말한 것처럼 x를 추정해서 parameterization 진행하면
pθ(zs∣zt)=q(zs∣zt,x=xθ(zt,t))= { Cat(zs;zt), Cat(zs;1−αt(1−αs)m+(αs−αt)xθ(zt,t)),zt=m,zt=m.
위와 같이 나오게 되는데
여기에서 중요한 2가지 추정을 추가할 수 있다.
간단하다
- Zero Masking Probabilities: ⟨x,m⟩=0이다. 그렇기에 ⟨xθ(zt,t),m⟩=0이라고 넣어주는 것.
- Carry-Over Unmasking: 이미 한번 unmaked된 것은 carry over 즉 계속 가져간다. network의 output을 바꾸지 않고 가져간다.
3.3 Rao-Blackwellized Likelihood Bounds
위 2가지 가설을 바탕으로 모델을 더 분산을 줄이면서 학습을 할 수있는데 이는 Rao-Balckwellized와 비슷하다.
- Rao-Balckwellized란? 나도 대략적으로 읽고 넘어갔는데 어떤 확률 θ에 대한 추정량 S(X)가 있을 때 충분통계량 T(X)가 주어지면 E[S(X)∣T(X)]=E[S(X)]이고 Var[S(X)∣T(X)]<Var[S(X)]이다.
간단하게 위의 경우 Zero Masking Probability, Carry-over unmasking 등의 조건을 더 붙임으로 써
모델이 m=0을 학습해야 하는 부담을 덜어주고 더 정확한 값의 표현이 가능해진 것
결국 KL divergence를
Ldiffusion=∑i=1TEq[ DKL(q(zs(i)∣zt(i),x)∥pθ(zs(i))) ]=∑i=1TEq[ 1−αt(i)αt(i)−αs(i) log⟨xθ(zt(i)),x⟩ ]
이렇게 표현이 가능하고 더욱 안정적인 결과를 얻을 수 있었다고 한다.
유도 과정은 논문 appendix B.1.3에 있다.
3.4 Continuous-Time Likelihood Bounds
앞에서 D3PM의 경우 우리는 time이 discrete하다고 가정하고 진행을 하였는데
T→∞인 경우 ELBO를 더욱 tight하게 구성할 수 있다.
간단하게 위 수식에서 유도하자면
limT→∞∑i=1TEq[1−αt(i)αt(i)−αs(i)log⟨xθ(zt(i)),x⟩]=Eq[limT→∞∑i=1T1−αt(i)αt(i)−αs(i)log⟨xθ(zt(i)),x⟩]=Eq[limT→∞∑i=1T1−αt(i)αt(i)−αs(i)log⟨xθ(zt(i)),x⟩T1∗T]=Eq∫t=0t=11−αtαt′log⟨xθ(zt,t),x⟩dt
인데 limT→∞T(αt(i)−αs(i))=αt′인 이유는 Δt=T1라고 할때 αs(t)=αt(t−Δt)로 표현이 가능하다.
그리고 limT→∞Δt=0이니까 limΔt→0Δtαt(t)−αt(t−Δt)=αt′(t)를 만족한다.
이렇게 continuous로 유도가 되면 Noise Schedule에 Invariance하다는데 이 부분은 잘 와닿지 않고 중요한 부분은 아니니 제외하겠다.
3.5 Masked Diffusion Language Models
결국 위와 같이 구해서 이전 sequence 전부를 받고 1글자씩 독립적으로 예측이 되는 모델이 있을 때
NELBO는 다음과 같이 유도가 된다.
LNELBO∞= Eq∫t=0t=1 1−αtαt′ ∑ℓ log⟨xθℓ(zt1:L,t),xℓ⟩dt
재밌는건 이렇게 구성된 objective가 MLM loss와 똑같은 모양이다.
정확히는 weighted average of MLM loss
3.5.1 Training Considerations for Masked Diffusion
학습을 위해서 추가한 내용에 대해서 설명을 하는데
tokenizer가 상당한 영향을 주었다는데 vocabulary의 size가 작으면 단어를 더 잘게 나눠서 표현을 해야하기 때문에 sequence가 길어지고 long term dependency 문제가 발생한다.
model은 D3PM은 T5을 사용하였는데 발전된 DiT를 넣었고
sample도 랜덤이 아니라 low-discrepancy sampler를 사용하였다고 한다.
4 Inference and Sampling in Masked Diffusion Language Models
4.1 Efficient Ancestral Sampling
전체가 masked token에서 시작해서 점점 step을 밟으면서 제거해나가는 것이다.
만약 이전 step에서 denoising이 된 token이 없어 다음 step과 동일하다면 xθ(zt1:L)처럼 시간에 independent한 모델을 사용할 때 그 output을 cache를 하고 이전에 미리 계산된 값을 다시 사용해서 진행할 수 있다.
4.2 Semi-Autoregressive Masked Diffusion Language Models
처음 x~1:L을 생성하고 L′만큼 뒤에 추가로 생성하고 싶다면
앞에서 생성한 token x~L−L′:L을 prefix로 달고 zsl∼pθ(zsl∣ztL:L+L′)의 생성을 진행한다.
이를 계속 반복하면 autoregressive하게 생성이 가능하다.
