
환경은 간단하게
Carracing v2로 실험을 해보았다.
위 이미지는
학습 도중에 빼서 찍은 사진이다.
코드는 개인 깃허브에서 볼 수 있습니다.
내용은 만들다보니 dreamer v1,v2,v3의 내용이 조금 섞여 있습니다...
그래도 큰 흐름(env를 학습하고 가상의 환경에서 agent를 학습하기)은 동일하니 편한 마음으로 보시면 좋을 것 같습니다.
모델
model은 dreamer v2의 내용을 대부분 가져왔다.
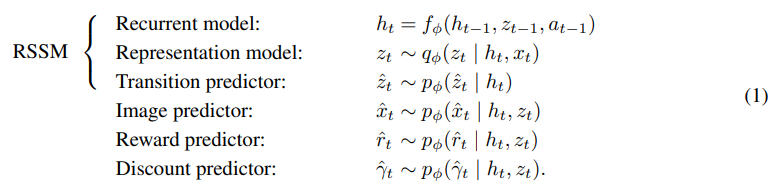 여기에서 추가로 encoder과 buffer이 있다.
여기에서 추가로 encoder과 buffer이 있다.
recurrent

PlaNet의 구현을 참고하였다.
class RSSM(nn.Module):
def __init__(self, args, action_size):
super(RSSM, self).__init__()
self.action_size = action_size
self.stoch_size = args.state_size
self.determinisic_size = args.deterministic_size
self.rnn_input = nn.Sequential(
nn.Linear(args.state_size + self.action_size, args.hidden_size),
nn.ELU()
)
self.rnn = nn.GRUCell(input_size=args.hidden_size, hidden_size=self.determinisic_size)
def forward(self, state, action, hidden):
x = torch.cat([state, action], dim=-1)
x = self.rnn_input(x)
hidden = self.rnn(x, hidden)
return hidden
def init_hidden(self, batch_size):
return torch.zeros(batch_size, self.determinisic_size)
def init_state(self, batch_size):
return torch.zeros(batch_size, self.stoch_size)그냥 간단한 MLP+rnn 구조이다.
Representation, Transition
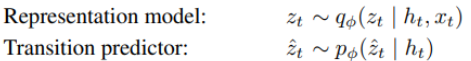 dreamer v2논문은 categorical state를 가지기는데 시간 관계상 다 구현하지는 못하였고 실험에는 stochastic한 state로 진행하였다.
dreamer v2논문은 categorical state를 가지기는데 시간 관계상 다 구현하지는 못하였고 실험에는 stochastic한 state로 진행하였다.
모델 자체는 간단한 MLP 구조이다.
class RepresentationModel(nn.Module):
def __init__(self, args):
super(RepresentationModel, self).__init__()
self.args = args
self.state_size = args.state_size
self.category_size = args.categorical_size
self.class_size = args.class_size
self.MLP = nn.Sequential(
nn.Linear(args.deterministic_size + args.observation_size, args.hidden_size),
nn.ELU(),
nn.Linear(args.hidden_size, args.hidden_size),
nn.ELU(),
nn.Linear(args.hidden_size, args.hidden_size),
nn.ELU(),
nn.Linear(args.hidden_size, 2 * self.state_size if args.rssm_continue else self.state_size),
)
def forward(self, hidden, obs):
x = torch.cat([hidden, obs], dim=-1)
logits = self.MLP(x)
if self.args.rssm_continue:
mean, std = torch.chunk(logits, 2, dim=-1)
std = F.softplus(std) + 0.1
dist = Normal(mean, std)
return dist, dist.rsample()
else:
return get_categorical_state(logits, self.category_size, self.class_size)
def stop_grad(self, hidden, obs):
x = torch.cat([hidden, obs], dim=-1)
logits = self.MLP(x)
if self.args.rssm_continue:
logits = logits.detach()
mean, std = torch.chunk(logits, 2, dim=-1)
std = F.softplus(std) + 0.1
dist = Normal(mean, std)
return dist, dist.rsample()
else:
return get_dist_stopgrad(logits, self.category_size, self.class_size)
class TransitionModel(nn.Module):
def __init__(self, args):
super(TransitionModel, self).__init__()
self.args = args
self.state_size = args.state_size
self.category_size = args.categorical_size
self.class_size = args.class_size
self.MLP = nn.Sequential(
nn.Linear(args.deterministic_size, args.hidden_size),
nn.ELU(),
nn.Linear(args.hidden_size, args.hidden_size),
nn.ELU(),
nn.Linear(args.hidden_size, args.hidden_size),
nn.ELU(),
nn.Linear(args.hidden_size, 2 * args.state_size if args.rssm_continue else args.state_size),
)
def forward(self, hidden):
logits = self.MLP(hidden)
if self.args.rssm_continue:
mean, std = torch.chunk(logits, 2, dim=-1)
std = F.softplus(std) + 0.1
dist = Normal(mean, std)
return dist, dist.rsample()
else:
return get_categorical_state(logits, self.category_size, self.class_size)
def stop_grad(self, hidden):
logits = self.MLP(hidden)
if self.args.rssm_continue:
logits = logits.detach()
mean, std = torch.chunk(logits, 2, dim=-1)
std = F.softplus(std) + 0.1
dist = Normal(mean, std)
return dist, dist.rsample()
else:
return get_dist_stopgrad(logits, self.category_size, self.class_size)
Encoder, Decoder

환경이 원래는 (3,96,96)이었는데 (3,64,64)로 resize를 해주었다.
encoder은 그냥 바로 observation은 vector로 압축하고
decoder은 deterministic, state를 받고 이를 복구한다.
이때 decoder은 분포를 반환하기 때문에 Normal dist를 반환한다.
class Encoder2D(nn.Module):
def __init__(self, args, obs_channel=3):
super(Encoder2D, self).__init__()
self.observation_size = args.observation_size
self.encoder = nn.Sequential(
nn.Conv2d(obs_channel, 32, 4, stride=2), # 64x64x3 -> 31x31x32
nn.ELU(),
nn.Conv2d(32, 64, 4, stride=2), # 31x31x32 -> 14x14x64
nn.ELU(),
nn.Conv2d(64, 128, 4, stride=2), # 14x14x64 -> 6x6x128
nn.ELU(),
nn.Conv2d(128, 256, 4, stride=2), # 6x6x128 -> 2x2x256
nn.Flatten(),
nn.Linear(1024, self.observation_size),
)
def forward(self, obs):
return self.encoder(obs)
class Decoder2D(nn.Module):
def __init__(self, args, obs_channel=3):
super(Decoder2D, self).__init__()
self.layers = nn.Sequential(
nn.Linear(args.state_size + args.deterministic_size, 1024),
nn.ELU(),
nn.Unflatten(1, (256, 2, 2)),
nn.ConvTranspose2d(256, 128, 4, stride=2), # 2x2x256 -> 6x6x128
nn.ELU(),
nn.ConvTranspose2d(128, 64, 4, stride=2), # 6x6x128 -> 14x14x64
nn.ELU(),
nn.ConvTranspose2d(64, 32, 4, stride=2), # 14x14x64 -> 31x31x32
nn.ELU(),
nn.ConvTranspose2d(32, obs_channel, 4, stride=2), # 31x31x32 -> 64x64x3
nn.Upsample(size=(64, 64), mode='bilinear', align_corners=False),
)
def forward(self, state, deterministic):
x = torch.cat([state, deterministic], dim=-1)
shape = x.shape
x = x.reshape(-1, shape[-1])
pred = self.layers(x)
# (batch*seq, obs_channel, 64, 64)
pred_shape = pred.shape
pred = pred.reshape(*shape[:-1], *pred_shape[1:])
m = Normal(pred, 1)
dist = Independent(m, 3)
return distreward model, discount model

둘의 구조가 deter과 state를 받는 MLP로 비슷해서 같이 올린다.
단 reward는 normal분포, discount는 베르누이 분포를 가진다.
class RewardModel(nn.Module):
def __init__(self, args):
super(RewardModel, self).__init__()
self.reward = nn.Sequential(
nn.Linear(args.state_size + args.deterministic_size, args.hidden_size),
nn.ELU(),
nn.Linear(args.hidden_size, args.hidden_size),
nn.ELU(),
nn.Linear(args.hidden_size, 1),
)
def forward(self, state, deterministic):
x = torch.cat([state, deterministic], dim=-1)
shape = x.shape
x = x.reshape(-1, shape[-1])
pred = self.reward(x)
pred = pred.reshape(*shape[:-1], -1)
dist = Normal(pred, 1)
dist = Independent(dist, 1)
return dist
class DiscountModel(nn.Module):
def __init__(self, args):
super(DiscountModel, self).__init__()
self.discount = nn.Sequential(
nn.Linear(args.state_size + args.deterministic_size, args.hidden_size),
nn.ELU(),
nn.Linear(args.hidden_size, args.hidden_size),
nn.ELU(),
nn.Linear(args.hidden_size, 1),
)
def forward(self, state, deterministic):
x = torch.cat([state, deterministic], dim=-1)
shape = x.shape
x = x.reshape(-1, shape[-1])
pred = self.discount(x)
pred = pred.reshape(*shape[:-1], -1)
dist = Bernoulli(logits=pred)
return distActor, critic
Actor
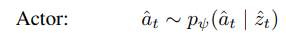 state, deterministic을 받고 확률에 따라서 행동을 결정한다.
state, deterministic을 받고 확률에 따라서 행동을 결정한다.
actor은 std도 같이 학습해서 행동을 결정한다.
class ActionContinuous(nn.Module):
def __init__(self, args, action_dim):
super().__init__()
self.args = args
self.seq = nn.Sequential(
nn.Linear(args.state_size + args.deterministic_size, args.hidden_size),
nn.ELU(),
nn.Linear(args.hidden_size, args.hidden_size),
nn.ELU(),
nn.Linear(args.hidden_size, args.hidden_size),
nn.ELU(),
)
self.mu = nn.Linear(args.hidden_size, action_dim)
self.std = nn.Linear(args.hidden_size, action_dim)
def forward(self, state, deterministic, training=True):
x = self.seq(torch.cat([state, deterministic], dim=-1))
mu = self.mu(x)
std = self.std(x)
std = F.softplus(std + 5.) + self.args.min_std
mu = mu / self.args.mean_scale
mu = torch.tanh(mu)
mu = mu * self.args.mean_scale
action_dist = Normal(mu, std)
action_dist = torch.distributions.TransformedDistribution(
action_dist, torch.distributions.TanhTransform())
action_dist = Independent(action_dist, 1)
action = action_dist.rsample()
return action_dist, actionCritic
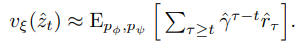 dreamer v3 논문에 critic은 사용할 때에는 mean을 사용해서 deterministic하게 진행을 하지만 학습은 분포로 진행
dreamer v3 논문에 critic은 사용할 때에는 mean을 사용해서 deterministic하게 진행을 하지만 학습은 분포로 진행
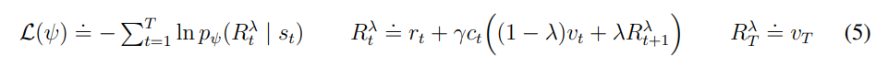
class Value(nn.Module):
def __init__(self, args):
super(Value, self).__init__()
self.seq = nn.Sequential(
nn.Linear(args.state_size + args.deterministic_size, args.hidden_size),
nn.ELU(),
nn.Linear(args.hidden_size, args.hidden_size),
nn.ELU(),
nn.Linear(args.hidden_size, 1)
)
def forward(self, state, deterministic):
x = torch.cat([state, deterministic], dim=-1)
shape = x.shape
x = x.reshape(-1, shape[-1])
pred = self.seq(x)
pred = pred.reshape(*shape[:-1], -1)
dist = Normal(pred, 1)
dist = Independent(dist, 1)
return dist
buffer
버퍼의 구조는 간단한게 중요한 부분은
버퍼에서 샘플링을 진행할 때 episode가 끝난 부분이 중간에 있으면 안된다.
seq_start, episode done, seq_end 이렇게 되면 모델이 중간부터 다시 시작하는 잘못된 내용을 학습할 수 있기에
끝을 제대로 보지 못한다.
그렇기 때문에
seq_start, seq_end, episode_done 과 같은 구조가 되어야 한다.
이는
cross_border = True
while cross_border:
initial_index = np.random.randint(len(self) - chunk_length + 1)
final_index = initial_index + chunk_length - 1
cross_border = np.logical_and(initial_index <= episode_borders,
위와 같이 구현이 되었다.
class ReplayBufferSeq:
def __init__(self, capacity, observation_shape, action_dim):
self.capacity = capacity
self.observations = np.zeros((capacity, *observation_shape), dtype=np.float32)
self.actions = np.zeros((capacity, action_dim), dtype=np.float32)
self.rewards = np.zeros((capacity, 1), dtype=np.float32)
self.next_observations = np.zeros((capacity, *observation_shape), dtype=np.float32)
self.done = np.zeros((capacity, 1), dtype=np.int8)
self.index = 0
self.is_filled = False
def push(self, observation, action, reward, next_observation, done):
self.observations[self.index] = observation
self.actions[self.index] = action
self.rewards[self.index] = reward
self.next_observations[self.index] = next_observation
self.done[self.index] = done
if self.index == self.capacity - 1:
self.is_filled = True
self.index = (self.index + 1) % self.capacity
def sample(self, batch_size, chunk_length):
episode_borders = np.where(self.done)[0]
sampled_indexes = []
for _ in range(batch_size):
try_ = 0
cross_border = True
while cross_border:
initial_index = np.random.randint(len(self) - chunk_length + 1)
final_index = initial_index + chunk_length - 1
cross_border = np.logical_and(initial_index <= episode_borders,
episode_borders < final_index).any()
try_ += 1
if try_ > 100:
break
sampled_indexes += list(range(initial_index, final_index + 1))
sampled_observations = self.observations[sampled_indexes].reshape(
batch_size, chunk_length, *self.observations.shape[1:])
sampled_actions = self.actions[sampled_indexes].reshape(
batch_size, chunk_length, self.actions.shape[1])
sampled_rewards = self.rewards[sampled_indexes].reshape(
batch_size, chunk_length, 1)
sampled_next_observation = self.next_observations[sampled_indexes].reshape(
batch_size, chunk_length, *self.next_observations.shape[1:])
sampled_done = self.done[sampled_indexes].reshape(
batch_size, chunk_length, 1)
return sampled_observations, sampled_actions, sampled_rewards, sampled_next_observation, sampled_done
def __len__(self):
return self.capacity if self.is_filled else self.index
world model training
dreamer v1의 구현을 따라서 진행

seed episode
seed는 간단하게 그냥 랜덤하게 action을 골라서 획득
def seed_episode(env, replay_buffer, num_episode):
print("Collecting seed data...")
for _ in tqdm(range(num_episode)):
obs, _ = env.reset()
obs = normalize_obs(obs)
done = False
experience = []
while not done:
action = env.action_space.sample()
next_obs, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
next_obs = normalize_obs(next_obs)
experience.append((obs, np.array(action), reward, next_obs, done))
obs = next_obs
for exp in experience:
replay_buffer.push(*exp)
collect data
env에서 학습한 모델로 데이터를 획득하는 내용이다.
사실상 위와 동일한데 action을 actor가 고르기 위해서 determinant를 구하고 obs를 embedding으로 바꾸고 이를 이용해서 posterior를 구하는 과정이 들어가서
길어보이는 것이다.
def collect_data(args, env, obs_shape, action_dim, num_episode, world_model, actor, replay_buffer, device):
encoder, recurrent, representation, transition, decoder, reward, discount = world_model
print("Collecting data...")
total_reward = 0
with torch.no_grad():
for i in tqdm(range(num_episode)):
obs, info = env.reset()
obs = normalize_obs(obs)
done = False
prev_deter = recurrent.init_hidden(1).to(device)
prev_state = recurrent.init_state(1).to(device)
prev_action = torch.zeros(1, action_dim).to(device)
while not done:
obs_embed = encoder(torch.tensor(
obs, dtype=torch.float32).to(device).unsqueeze(0))
deter = recurrent(prev_state, prev_action, prev_deter)
_, posterior = representation(deter, obs_embed)
_, action = actor(posterior, deter)
next_obs, reward, terminated, truncated, info = env.step(action[0].cpu().numpy())
next_obs = normalize_obs(next_obs)
done = terminated or truncated
replay_buffer.push(obs, action[0].cpu(), np.array(reward), next_obs, done)
obs = next_obs
prev_deter = deter
prev_state = posterior
prev_action = action
total_reward += reward
return total_reward / num_episodetrain world model
이 부분은 본격적인 부분으로 코드가 매우 길어서 짧게 잘라서 설명을 하겠다.
우선 replay buffer에서 sampling 한 batch를 가지고 학습을 한다.
batch의 구조는 으로 구성이 되어있다.
우선 간단하게 world model과 가져온 batch를 나누고 초기 state, deter을 설정한다.
def train_world(args, batch, world_model, world_optimizer, world_model_params, device):
encoder, recurrent, representation, transition, decoder, reward, discount = world_model
obs_seq, action_seq, reward_seq, next_obs_seq, done_seq = batch
# (batch, seq, (item))
obs_seq = torch.tensor(obs_seq, dtype=torch.float32).to(device)
action_seq = torch.tensor(action_seq, dtype=torch.float32).to(device)
reward_seq = torch.tensor(reward_seq, dtype=torch.float32).to(device)
next_obs_seq = torch.tensor(next_obs_seq, dtype=torch.float32).to(device)
done_seq = torch.tensor(done_seq, dtype=torch.float32).to(device)
batch_size = args.batch_size
seq_len = args.batch_seq
deter = recurrent.init_hidden(batch_size).to(device)
state = recurrent.init_state(batch_size).to(device)
states = torch.zeros(batch_size, seq_len, args.state_size).to(device)
deters = torch.zeros(batch_size, seq_len, args.deterministic_size).to(device)
이후 obs를 embedding으로 전부 바꿔주고 discount를 학습할 binary cross entropy를 설정한다.
obs_embeded = encoder(obs_seq.view(-1, *obs_seq.size()[2:])
).view(batch_size, seq_len, args.observation_size)
discount_criterion = nn.BCELoss()sequence 진행, kl_loss
이후 batch의 sequence를 따라서 진행을 하면서
determinant와 state를 구한다.
이때 prior과 posterior의 분포를 저장한다.
for t in range(1, seq_len):
deter = recurrent(state, action_seq[:, t - 1], deter)
prior_dist, _ = transition(deter)
posterior_dist, state = representation(deter, obs_embeded[:, t])
prior_mean.append(prior_dist.mean)
prior_std.append(prior_dist.scale)
posterior_mean.append(posterior_dist.mean)
posterior_std.append(posterior_dist.scale)
deters[:, t] = deter
states[:, t] = state우선 앞서 저장한 prior과 posterior의 분포로 kl loss를 구한다.
kl loss는 dreamer v2의 balanced loss이다.
def kl_balance_loss(prior_mean, prior_std, posterior_mean, posterior_std, alpha, freebits):
prior_dist = torch.distributions.Normal(prior_mean, prior_std)
prior_dist = torch.distributions.Independent(prior_dist, 1)
posterior_dist = torch.distributions.Normal(posterior_mean, posterior_std)
posterior_dist = torch.distributions.Independent(posterior_dist, 1)
prior_dist_sg = torch.distributions.Normal(prior_mean.detach(), prior_std.detach())
prior_dist_sg = torch.distributions.Independent(prior_dist_sg, 1)
posterior_dist_sg = torch.distributions.Normal(posterior_mean.detach(), posterior_std.detach())
posterior_dist_sg = torch.distributions.Independent(posterior_dist_sg, 1)
kl_loss = alpha * torch.max(torch.distributions.kl.kl_divergence(posterior_dist_sg, prior_dist).mean(), torch.tensor(freebits)) + \
(1 - alpha) * torch.max(torch.distributions.kl.kl_divergence(posterior_dist,
prior_dist_sg).mean(), torch.tensor(freebits))
return kl_loss
prior_mean = torch.stack(prior_mean, dim=1)
prior_std = torch.stack(prior_std, dim=1)
posterior_mean = torch.stack(posterior_mean, dim=1)
posterior_std = torch.stack(posterior_std, dim=1)
kl_loss = kl_balance_loss(prior_mean, prior_std, posterior_mean,
posterior_std, args.kl_alpha, args.free_bit)그렇게 구한 state와 deter의 흐름을 토대로
reward, observation, discount를 예측하고 이렇게 나온 distribution을 토대로 -log_prob를 구해서 loss를 구한다.
-log_prob가 낮아지면 log_prob가 높아져야 하고 prob가 높아져야 하기에 예측이 잘 이루어진다.
obs_pred_dist = decoder(states[:, 1:], deters[:, 1:])
reward_pred_dist = reward(states[:, 1:], deters[:, 1:])
discount_pred_dist = discount(states[:, 1:], deters[:, 1:])
obs_loss = obs_pred_dist.log_prob(obs_seq[:, 1:]).mean()
reward_loss = reward_pred_dist.log_prob(reward_seq[:, 1:]).mean()
discount_loss = discount_criterion(discount_pred_dist.probs, 1 - done_seq[:, 1:]).mean()
이렇게 구한 loss들을 다 더해주고
optimizer를 이용해서 학습을 진행해준다.
total_loss = -obs_loss - reward_loss + discount_loss + args.kl_beta * kl_loss
world_optimizer.zero_grad()
total_loss.backward()
nn.utils.clip_grad_norm_(world_model_params, args.clip_grad)
world_optimizer.step()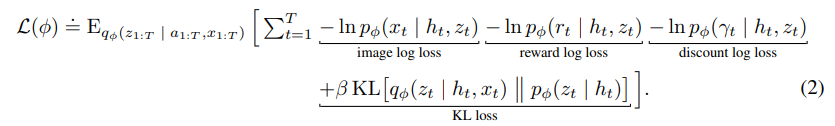 loss는 위 그림과 동일한 구조이다.
loss는 위 그림과 동일한 구조이다.
discount의 경우 베르누이 분포라서 binary cross entropy를 활용하여서 학습을 하였기에 바로 loss가 나오기 때문에 +로 해주었다.
training actor, critic
actor과 critic은 위에서 구한 states, deters를 토대로 예측을 실시한다.
training world model 끝의 return 값으로 다음과 같이 grad를 끊고 넘겨준다.
states = states[:, 1:].detach()
deters = deters[:, 1:].detach()
return loss, states, deters
이후 actor_critic 학습 함수에서
이를 수평으로 펴서 (batch*seq, state_dim)으로 만든 다음에 학습을 진행한다.
학습을 위해 imagine 값들을 담을 공간을 만든다.
def train_actor_critic(args, states, deters, world_model, actor, critic, target_net, actor_optim, critic_optim, device):
encoder, recurrent, representation, transition, decoder, reward, discount = world_model
states = states.reshape(-1, states.size(-1))
deters = deters.reshape(-1, deters.size(-1))
imagine_states = []
imagine_deters = []
imagine_action_log_probs = []
imagine_entropy = []이제 horizon을 돌면서 미래를 예측하는데
action을 예측하고 이를 토대로 다음 deter과 state를 예측하고
다시 action을 예측하고 ... 식으로 빈복을 한다.
이때 prior과 determinant을 담고 나중에 이를 이용해서 reward, discount, value를 예측한다.
for t in range(args.horizon):
epsilon = 1e-6
action_dist, action = actor(states, deters)
action = action.clamp(-1 + epsilon, 1 - epsilon)
action_log_prob = action_dist.log_prob(action)
entropy = action_dist.base_dist.base_dist.entropy()
deters = recurrent(states, action, deters)
_, states = transition(deters)
imagine_states.append(states)
imagine_deters.append(deters)
imagine_action_log_probs.append(action_log_prob)
imagine_entropy.append(entropy)이렇게 만든 imagine값들을 정리해서
(horizon,batch*seq)로 만들어준다.
imagine_states = torch.stack(imagine_states, dim=0)
imagine_deters = torch.stack(imagine_deters, dim=0)
imagine_action_log_probs = torch.stack(imagine_action_log_probs, dim=0)
imagine_entropy = torch.stack(imagine_entropy, dim=0)```
이를 토대로 lambda return을 구하는데
```python
lambda_return_ = lambda_return(
imagine_rewards, imagine_values_target, imgaine_discounts, args.lambda_)이제 reward의 target value, discount를 예측한다.
predicted_rewards = reward(imagine_states, imagine_deters).mean
target_values = target_net(imagine_states, imagine_deters).mean
discount_pred = discount(imagine_states, imagine_deters).mean
lambda return은 dreamer v3 논문에서 다음과 같다.
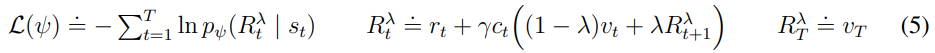 이를 토대로 만들었다.
이를 토대로 만들었다.
간단하게 논문의 말 그대로 재귀를 활용해서 구축하였다.
def lambda_return(rewards, values, discounts, gamma, lambda_):
# rewards: (T, B, 1), values: (T, B, 1), discounts: (T, B, 1)
T, B, item = rewards.size()
lambda_return = torch.zeros(*rewards.shape).to(rewards.device)
lambda_return[-1] = values[-1]
for t in reversed(range(T - 1)):
lambda_return[t] = rewards[t + 1] + gamma * discounts[t + 1] * \
((1 - lambda_) * values[t + 1] + lambda_ * lambda_return[t + 1])
return lambda_return이제 actor과 ciritc의 loss를 구해야 하는데
ciritc의 경우 위 dreamer v3처럼 분포로 구한다.
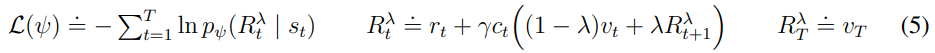
actor의 경우 dreamer v2에서 reinforce+dynamic+entropy로 학습을 하는데
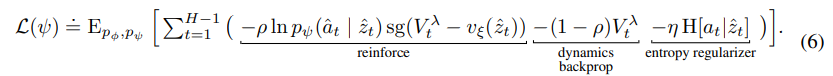
이를 반영하여서 만든 loss는 다음과 같다.
value_dist = critic(imagine_states[:-1].detach(), imagine_deters[:-1].detach())
critic_loss = -torch.mean(value_dist.log_prob(lambda_return_[:-1].detach()))
actor_loss = -args.reinforce_coef * (imagine_action_log_probs[1:].unsqueeze(-1) * (lambda_return_[:-1] - target_values[:-1]).detach()).mean() -\
(1 - args.reinforce_coef) * lambda_return_[:-1].mean() -\
args.entropy_coef * imagine_entropy[1:].mean()논문에서 마지막 값은 critic의 값과 동일하다고 해서 제외하였다.
이제 이를 미분해서 학습을 진행한다.
actor_optim.zero_grad()
actor_loss.backward()
nn.utils.clip_grad_norm_(actor.parameters(), args.clip_grad)
actor_optim.step()
critic_optim.zero_grad()
critic_loss.backward()
nn.utils.clip_grad_norm_(critic.parameters(), args.clip_grad)
critic_optim.step()
main

main 함수는 위 그림과 같이 구성했으며 그냥 함수들을 돌린다.
다음과 같다.
(여기에서 알아야할 부분은 target net을 moco와 같이 EMA로 weight update를 해주어야 한다.)
def main():
args = parse_args()
env = gym.make("CarRacing-v2", render_mode="rgb_array")
env = gym.wrappers.ResizeObservation(env, (64, 64))
set_seed(args.seed)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
action_dim = 3
obs_shape = env.observation_space.shape
obs_shape = obs_shape[-1:] + obs_shape[:2]
print("action_dim:", action_dim, "obs_shape:", obs_shape)
encoder = Encoder2D(args, obs_shape[0]).to(device)
recurrent = RSSM(args, action_dim).to(device)
representation = RepresentationModel(args).to(device)
transition = TransitionModel(args).to(device)
decoder = Decoder2D(args, obs_shape[0]).to(device)
reward = RewardModel(args).to(device)
discount = DiscountModel(args).to(device)
model_params = list(encoder.parameters()) + list(recurrent.parameters()) + \
list(representation.parameters()) + list(transition.parameters()) + \
list(decoder.parameters()) + list(reward.parameters()) + list(discount.parameters())
actor = ActionContinuous(args, action_dim).to(device)
critic = Value(args).to(device)
target_net = Value(args).to(device)
for param_p, paran_k in zip(target_net.parameters(), critic.parameters()):
param_p.data.copy_(paran_k.data)
param_p.requires_grad = False
model_optim = optim.Adam(model_params, lr=args.model_lr)
actor_optim = optim.Adam(actor.parameters(), lr=args.actor_lr)
critic_optim = optim.Adam(critic.parameters(), lr=args.critic_lr)
replay_buffer = ReplayBufferSeq(args.buffer_size, obs_shape, action_dim)
logger = Logger(args.logdir)
world_model = (encoder, recurrent, representation, transition, decoder, reward, discount)
seed_episode(env, replay_buffer, args.seed_episode)
for episode in range(args.total_episode):
for step in range(args.train_step):
batch = replay_buffer.sample(args.batch_size, args.batch_seq)
loss, states, deters = train_world(
args, batch, world_model, model_optim, model_params, device)
logger.log(episode * args.train_step + step, epoch=episode, **loss)
loss = train_actor_critic(args, states, deters, world_model,
actor, critic, target_net, actor_optim, critic_optim, device)
logger.log(episode * args.train_step + step, epoch=episode, **loss)
for param_p, paran_k in zip(target_net.parameters(), critic.parameters()):
param_p.data.copy_(args.target_momentum * param_p.data +
(1 - args.target_momentum) * paran_k.data)
train_score = collect_data(args, env, obs_shape, action_dim, args.collect_episode,
world_model, actor, replay_buffer, device)
logger.log(episode * args.train_step + step, epoch=episode, train_score=train_score)
if episode % args.eval_step == 0:
test_score = evaluate(args, env, obs_shape, action_dim, 1,
world_model, actor, replay_buffer, device, is_render=True)
logger.log(episode * args.train_step + step, epoch=episode, test_score=test_score)
if episode % args.save_step == 0:
save_model(args, world_model, actor, critic)
if __name__ == "__main__":
main()학습 결과
train score
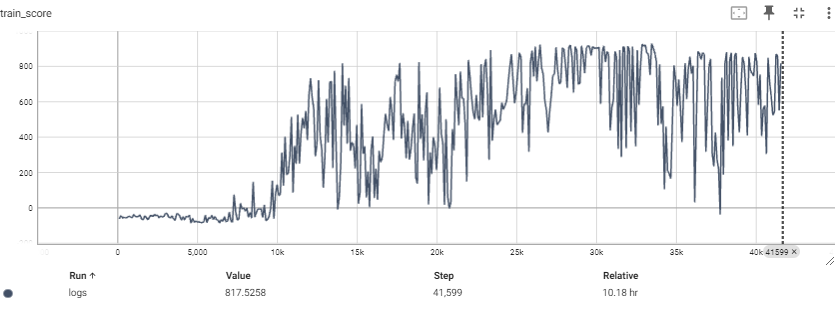
얼마 안돌렸는데 (400episode 정도) 매우 잘 증가하는 것을 알 수 있다.
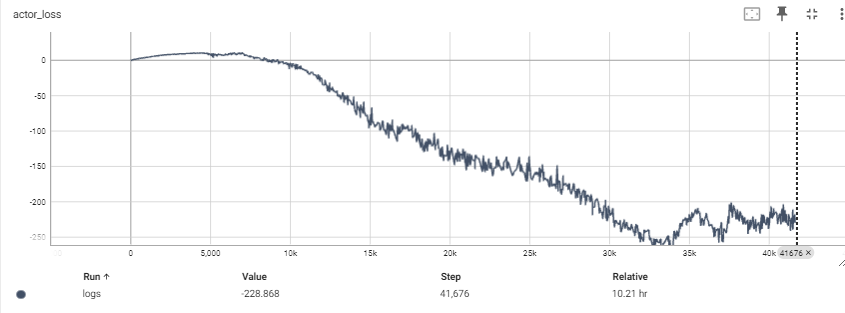
actor loss도 감소하는 것을 알 수 있다.
