요약
Transformer를 Dreamer에 사용해볼 수 있을까? 에 대한 논문이다.
Transformer를 그냥 넣는게 아니라 어떻게 잘 넣어서 transformer의 장점들(병렬 학습, long-term dependency 등)을 살리면서 Dreamer에 넣을 수 있을까 고민을 해본 논문.
그리고 long term dependency를 test하기 위한 task도 제시하였다.
transformer를 넣는 방법을 간단하게 요약하자면
RNN을 transformer로 대체하고 Representation을 로 바꾸어서 모든 계산을 병렬적으로 진행할 수 있게 만들어주었다.
Abstract
dreamer는 MBRL 강화학습의 다양한 장점인
- sample efficiency
- reusable knowledge
- safe planning
등을 제공한다.
그러나 구현 과정에서 기존의 rnn의 한계점도 상속받는다.
이 논문은 transformer를 dreamer에 사용해서 이점을 얻을 수 있을까? 에 관한 논문이다.
결론적으로 transformer를 world model에 사용해서 Transformer State-Space model을 소개하고. 이 world model을 transformer based policy network를 이용해서 안정성을 얻는다.
이를 통해서 rnn에 비해서 transformer가 얻는 장점인 long-range memory access를 얻을 수 있었다고 한다.
-
참고로 추후 논문으로 Facing Off World Model Backbones: RNNs, Transformers, and S4이라는 논문도 존재하는데 이는 state space model S4를 이용하여 말도안되게 더 깊은 long-range memory를 얻었다는 내용이다.
state space model의 장점 중 하나가 long range memory이기때문 (hippo부터였나? long range memory를 위한 기법이 들어가기 때문) -
그런데 개인적으로 transformer가 rnn, state-space model보다 아무래도 inference cost가 비싸기 대문에 S4같은 model이 확실히 더 좋긴 할 것 같다.
1 INTRODUCTION
dreamer는 latent representation space에서 world model을 학습하는데 다른 model-free 방법보다 뛰어난 성능과 sample-efficiency를 보임
그러나 partial observability를 해결하기 위해서 mbrl의 dynamic model은 RNN을 사용하는데 transformer는 이런 RNN보다 다양한 분야에서 뛰어난 성능을 보였다. 그렇기에 RNN대신 transformer를 어떻게 dreamer에 사용할 수 있을까? 가 이 논문의 주제이다.
이러한 과정에서 장점과 문제를 분석하였다.
이때 transformer기반의 policy network는 reward만으로 학습하기 더 어려웠다고 한다. 그러나 world model을 학습하는 것은 단순히 reward만으로 학습하는 것이 아니라 다양한 loss가 복합적으로 사용되기에 더 학습하기 쉬울 것이라고 추측한다.
이논문은 transformer기반의 dreamer인 TransDreamer를 소개한다.
이름 그대로 dreamer에 transformer를 접목해 이점을 가져오기 위한 구조이다.
이때 그냥 rnn을 transformer로 바꾸는 것이 아니라 몇가지 문제가 있는데
- prior과 posterior을 실행하기 위해서 기존 world model의 latent space에서 action을 기반으로하는 transition이 가능해야 한다.
- transformer의 장점인 병렬 학습이 가능해야 한다.
이러한 문제를 극복하고 만든 모델을 Transformer State-Space Model(TSSM)이라고 명명하였다.
이렇게 만든 TransDreamer는 transformer의 장점인 long-term memory가 필요한 문제나 complex memory interaction이 필요한 문제를 잘 해결하였고 Atari, DMC 등 long-term이 필요하지 않은 문제에서도 dreamer와 비슷한 성능을 내었다고 한다.
2 PRELIMINARIES
대부분의 내용은 dreamer에 대한 내용이기에 기존에 dreamer논문 리뷰를 v1, v2, v3 까지 싹다 올려놓았기 때문에 이를 참조하면 좋겠다.
 dreamer 구성
dreamer 구성
3 TRANSDREAMER
기존에 transformer는 NLP, Vision분야에서 RNN 대비 강력한 성능을 보였는데 이는 Transformer 구조에서 과거 state를 쌓아두고 attention을 계산하기 때문에 directly access historical state와 learn complex interactions 능력이 생기는데 이에 따라 long-term dependency 같은 능력이 생긴다.
그리고 이런 능력은 robust한 world model을 위해 매우 중요한 이점이다.
transformer에 대해서 잘 모른다면 attention is all you need 논문 리뷰 및 구현을 참고하면 좋다.
3.1 TRANSFORMER STATE SPACE MODEL (TSSM)
transformer기반의 world model을 디자인하기 위해서 필요한 몇가지 기준을 정했는데
- directly access past states
- update state of each time step in parallel during training (병렬성)
- test time에서의 trajectory imagination rollout의 가능
- stochastic latent vatiable model
기존의 RSSM은 1번과 2번 조건을 만족하지 않는다.
그냥 단순하게 RNN의 past state에서 attention을 진행해서 state를 진행할 수 있는데 이러면 1번을 만족하지만 2번 각 시간에서 state의 병렬진행이 안된다. 그러면 계산 효율성이 떨어진다. 그리고 traditional transformer는 deterministic하기 때문에 4번도 만족하지 못한다.
사실 4번 내용에서 past state에 attention을 넣는 것이 deterministic이랑 무슨 관련이 있는 건지 모르겠다.
rnn의 내부 determinastic state가 아니라 stochastic state를 attention을 넣어서 transformer decoder 느낌으로 예측하는 것인가?
우선 논문의 구성에서 중요한 부분은 아니니까 넘어가도록 하겠다.
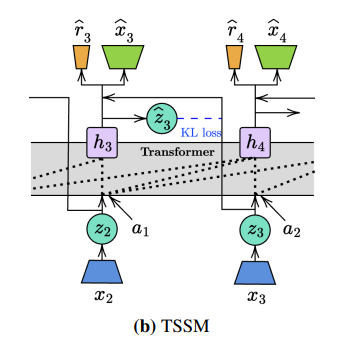
우선 RSSM의 구조를 보면
 RSSM의 모든 component가 sequential인 이유는 hidden state가 sequential(빨간 선)로 진행이 되고 이를 입력으로 받기 때문이다.
RSSM의 모든 component가 sequential인 이유는 hidden state가 sequential(빨간 선)로 진행이 되고 이를 입력으로 받기 때문이다.
이런 sequential을 지우고 transformer를 사용하는데 기존의 RNN 구조에서는 hidden state가 로 표현이 되었을 때 이 하나의 표현으로 모든 과거를 다 포함을 한다.
그러나 transformer는 sequence를 명시적으로 받고 직접적으로 사용해서 attention을 진행하기에 로 표현이 된다.
- 이렇게 모든 를 병렬로 계산할 수 있으면 를 input으로 받는 구성요소도 병렬적으로 계산할 수 있다.
Myopic Representation Model.
하지만 이렇게 생각했던 병렬 계산은 사실 안되는데 왜냐하면
에 들어가는 를 계산하기 위해서 다시 가 필요하기 떄문이다.
representation model이 이기 때문.
hidden state를 계산하기위해서는 representation이 필요한데 representation을 계산하기 위해서는 hidden state가 필요하기에 순차적으로 계산이 이루어져야 한다.
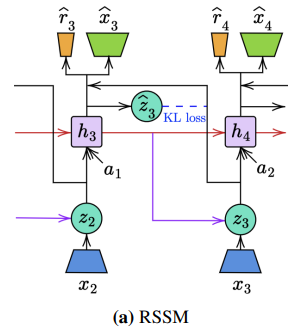
그래서 위 구조를 바꿔서 representation model을 로 근사치로 바꾼다. 이 덕분에 posterior가 각 time step에 대해서 독립적으로 계산이 된다.
결국 쉽게말하면 가 독립이 되었으니 우다다 병렬로 한번에 계산이 가능하고 을 가져와서 가 병렬적으로 우다다 계산이 가능하고 이를 통해서 각 component의 값들이 우다다 병렬적으로 한번에 계산이 가능하다.
결국 transformer의 장점인 병렬 연산을 통한 매우 빠른 tranining이 가능해졌다.
posterior을 독립적으로 보게 되었다는 것은 약간 naive baysian에서 계산 편리성을 위해서 각 사건을 독립적으로 가정한 느낌같다.
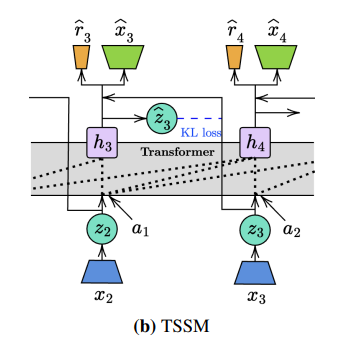 그래서 위와 같은 구조가 되었다.
그래서 위와 같은 구조가 되었다.
그런데 Representation에서 를 빼는 것은 과거를 빼는 것이기에 representation의 성능을 떨어트리지 않을까?
여기에서 엄청 재밌는 가설이 나오는데
- 우리가 로 모든 state를 표현한다면 그럴 수 있는데 실제로는 state를 와 deterministic 를 concat해서 표현한다. 즉 가 모자란 시간에 대한 정보를 채워줄 수 있다고 가정한다.
따라서 sequential한 정보를 deterministic이 주기 때문에 representation에서 의 정보는 필수적이지 않다는 것이다.
심지어 trajectory imagination 과정에서는 representation model을 사용하지도 않고 로 바로 계산한다.
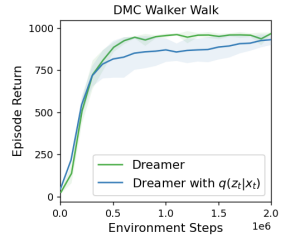 위 그림과 같이 실제로 그다지 성능이 하락하지 않았다.
위 그림과 같이 실제로 그다지 성능이 하락하지 않았다.
또 개인적인 추측은 로 encoding을 한다고 해도 decoder가 인데 이를 가깝게 하는 과정에서 decoder에 들어가는 의 정보가 encoder에도 들어갈 수 있지 않을까? 왜냐하면 encoder와 decoder가 KL divergency로 학습이 되는 구조니까 서로 가깝게 되기 때문
이때 를 모든 과거 관측에 대해서 로도 구성이 가능하기는 한데 실제로 하지는 않았다. 너무 복잡해지기 때문.
아마 이렇게 하면 모든 과거 관측-행동 을 받기 때문에 단순히 현재의 만 받는 것보다 훨씬 더 정확한 representation이 될 것 같기는 하다.
3.2 POLICY LEARNING AND IMPLEMENTATION DETAILS
사실 TransDreamer는 Introduction에서 설명했다시피 world model에 Transformer를 넣는 구조이기 때문에 agent 학습은 기존의 dreamer와 동일하다.
역시 TSSM도 fully differentiable하기 때문에 기존처럼 REINFORCE와 return sum을 이용한 학습이 가능하다.
Training Stability.
transformer는 sparse한 reward를 가진 case에서 학습 과정에 안전성 문제가 있었다고 한다.
그래서 GTrXL의 경우 GRU gate를 추가해서 문제를 해결했다고 하는데 TransDreamer에서는 이러한 문제가 나타나지 않는다!
왜냐하면 Agent 학습 과정에서 Transformer의 param이 고정이 되어있기 때문이다. Transformer는 world model의 학습에서 image, reward, discount의 prediction에서만 활용이 된다.
Prioritized Replay.
agent는 학습 과정에서 reward predictor에 의존을 한다.
reward predictor은 agent가 좋은 policy를 가지고 reward를 가진 trajectory를 수집하는데 의존한다.(특히 reward가 sparse한 경우)
이를 위해서 replay buffer를 random sampling하는 것이 아니라 weight를 주어서 더 많은 reward를 가진 sample이 더 잘 추출될 수 있게 설정하였다.
특정 비율 만큼 reward가 있는 trajectory를 sample하고 나머지는 uniform으로 뽑는다.
Number of Imagination Trajectories.
Transformer를 넣음으로써 memory requirement가 RNN보다 더 증가하였기에 imagination을 하기 더욱 어려워졌다.
그래서 replay buffer에서 sample된 sate에서 imagine을 진행하는 것이 아니라 개의 더 작은 하위 subset을 뽑은 다음 imagine을 진행한다.
이는 imagine trajectory의 숫자를 줄이지만 그래도 Dreamer 만큼의 성능이 나온다.
5 EXPERIMENTS
long-term memory와 reasoning이 필요한 task부터 short-term만으로 풀 수 있는 task까지 dreamer와 비교해보았다.
- TransDreamer와 Dreamer가 long-term memory가 필요한 task에 어떻게 작동할까?
- 어떻게 둘의 world model을 비교할까?
- short-term memory가 필요한 task도 TransDreamer가 dreamer만큼 잘할까?
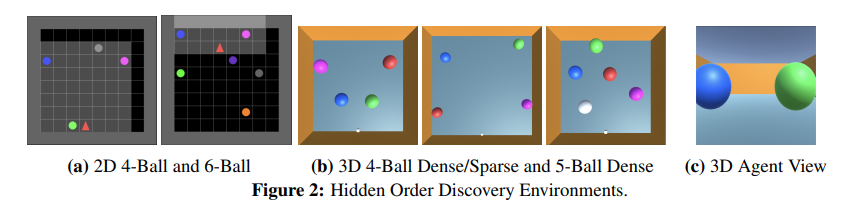
1번을 위해서 Hidden Order Discovery를 만들었다. 이는 2D와 3D로 만들어졌는데 2D는 top-down view를 보는데 3D는 agent가 partial observation을 보고 진행한다. 이는 장기 기억력이 필요하다. (task에 대한 구체적 설명은 밑에 하겠다.)
2번째 질문은 world model을 분석한다.
3번째 밀문은 DMC, Atari를 가지고 비교하였다.
5.1 HIDDEN ORDER DISCOVERY IN 2D OBJECT ROOM
2D 버전에서는 agent는 위 그림에서 빨간 세모이고 밝게 칠해진 부분만 볼 수 있다. 이를 통해 partially observable environment를 구축하였다.
각 episode에서 공의 수집에 대한 hidden order가 존재하고 agent는 정확한 순서로 공을 주워야 한다.
만약 잘못 주우면 map이 초기화되고 agent는 첫번째 공부터 시작해야한다.
- 이때 map이 초기화되는 것은 agent의 위치와 hidden order은 초기화가 되지 않지만 모든 공이 처음 위치로 초기화가 된다.
공을 올바른 순서로 collect하면 +3의 reward를 가지지만 만약 잘못된 순서로 가지면 reset되고 이전에 주운 공들의 reward는 0이된다.
- 이는 agent가 그냥 첫번째 공만 계속 주워서 reeward를 쌓는 것을 방지.
올바른 순서로 모든 공을 다 주우면 map과 reward가 reset된다.
그리고 각 episode마다 hidden order은 랜덤하게 정해진다.
이 문제를 해결하기 위해서 agent는 과거에 공을 수집한 경험을 기억해서 현재 적용을 해야한다. 이를 통해 long-term dependency를 평가할 수 있다.
실제 환경
- 4, 5, 6 ball
- 8x8 grid environment
- agent have 100 time to collect as much reward possible
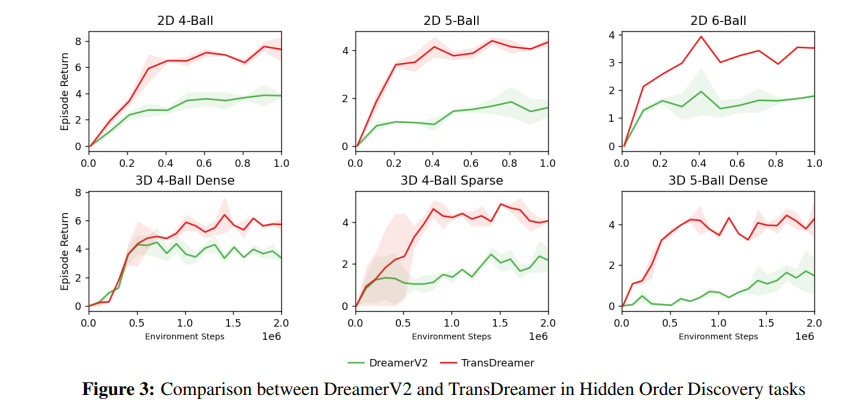 위와 같이 TransDreamer가 outperform하는 것을 볼 수 있다.
위와 같이 TransDreamer가 outperform하는 것을 볼 수 있다.
+3의 의미는 평균적으로 첫번째 공은 잘 줍는 다는의미이다.
+6의 의미는 평균적으로 두번째 공까지 잘 줍는다는 의미이다.
그리고 episode를 성공하는 비율도 확인을 해보았는데 이는 최소 1번은 모든 ball을 얻는 확률이다.
4-Ball에서 TransDreamer는 23%로 성공하였는데 Dreamer는 7%만 성공하였다.
 확실하게 TransDreamer가 더 잘한다.
확실하게 TransDreamer가 더 잘한다.
5.2 HIDDEN ORDER DISCOVERY IN 3D OBJECT ROOM
3D 환경에서의 실험인데
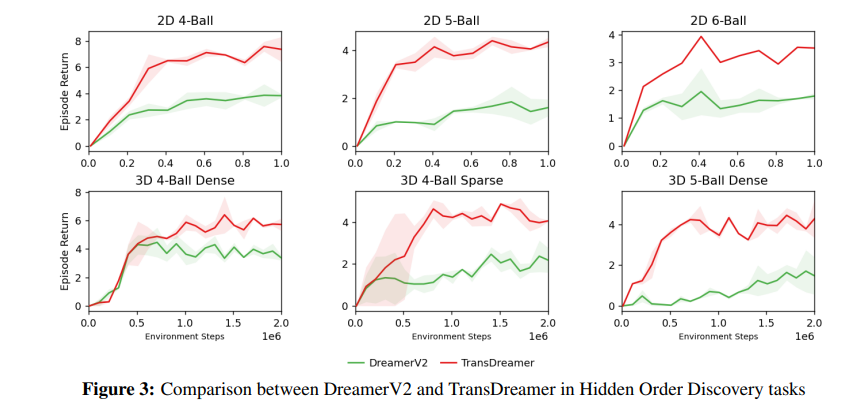 위 그림의 아랫부분이 결과이다.
위 그림의 아랫부분이 결과이다.
Dense와 Sparse의 차이는 공의 간격인데 Dense는 최소 1개의 공만큼 거리를 두는 것이고 Sparse는 최소 3개의 공만큼 거리를 두는 것이다.
역시 TransDreamer가 더욱 잘한다.
5.3 WORLD MODEL - QUANTITATIVE RESULTS
world model의 비교인데 3D 5-Ball Dense 환경이 기준으로 비교하였다.
예측한 image의 MSE와 reward의 정확도를 측정하였다.
Image Generation
동등한 비교를 위해서 policy training 없이 동일한 trajectory를 기반으로 학습이 이루어짐.
context length에 따른 generation quality와 이미지의 MSE를 측정
여기에 나온 MSE는 foreground object(공 등등)에 관한 내용이다. 왜냐하면 대부분의 중요한 정보가 공에 있기 때문이고 MSE 차이의 60%가 공에서 나오기 때문
- 이때 재밌는 부분은 공은 실제 이미지에서 작은 부분만 차지하지만 대부분의 차이와 정보가 거기에 있다.
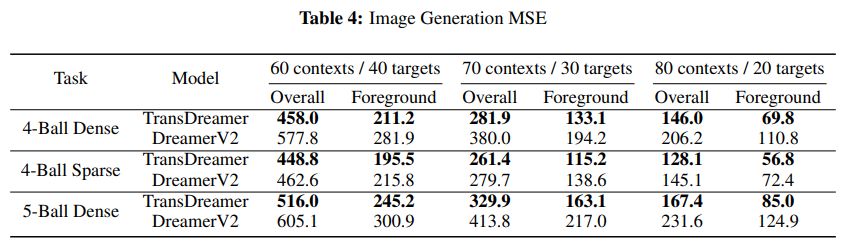
foreground object만 따로 정리하면 아래와 같다.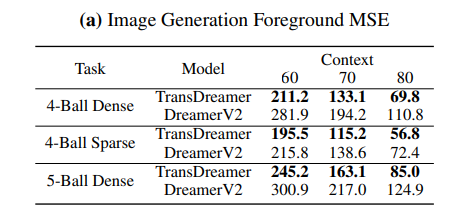
TransDreamer의 MSE가 더욱 낮다.
그런데 4-Ball Sparse에서는 비슷한데 sparse하기 때문에 object를 덜 자주 보기 때문으로 추측한다.
Reward Prediction.
reward의 예측은 대부분 0이기 때문에 3을 예측하는 것이 중요한데 reward 예측의 경우 연속적인 값이기 때문에 이면 accuracy에 정답으로 포함하였다.
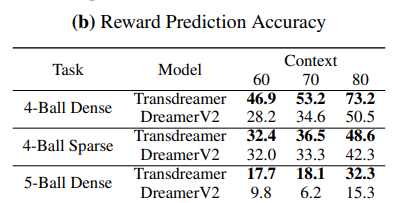 위가 결과인데 역시 TransDreamer가 더욱 잘한다.
위가 결과인데 역시 TransDreamer가 더욱 잘한다.
재밌는건 Dreamer V2의경우 5-Ball Dense에서 60->70에서 점수가 하락했는데 TransDreamer의 경우 점수가 증가하였다.
이는 Dreamer가 context length 증가의 이점을 다 못누린다는 것을 의미한다.
5.4 WORLD MODEL - QUALITATIVE COMPARISON
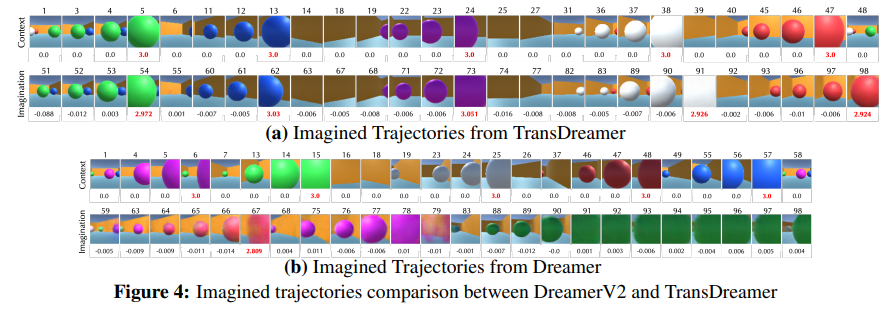 context를 모든 공을 수집하고 다시 reset해서 처음으로 돌아간 상황(48 for TransDreamer, 58 for dreamer)에서 이후를 상상한다. 이때 context에 올바른 공의 순서가 있기 때문에 다시 그 순서대로 찾아가면 된다.
context를 모든 공을 수집하고 다시 reset해서 처음으로 돌아간 상황(48 for TransDreamer, 58 for dreamer)에서 이후를 상상한다. 이때 context에 올바른 공의 순서가 있기 때문에 다시 그 순서대로 찾아가면 된다.
이때 위 이미지를 보면 TransDreamer는 기존의 context를 활용해서 정답 순서를 제대로 방문하고 reward(각 사진 아래)를 제대로 예측하는 반면에 Dreamer는 제대로 찾아가질 못하고 reward 예측도 이상하다.
5.5 SHORT-TERM MEMORY TASKS IN DMC AND ATARI
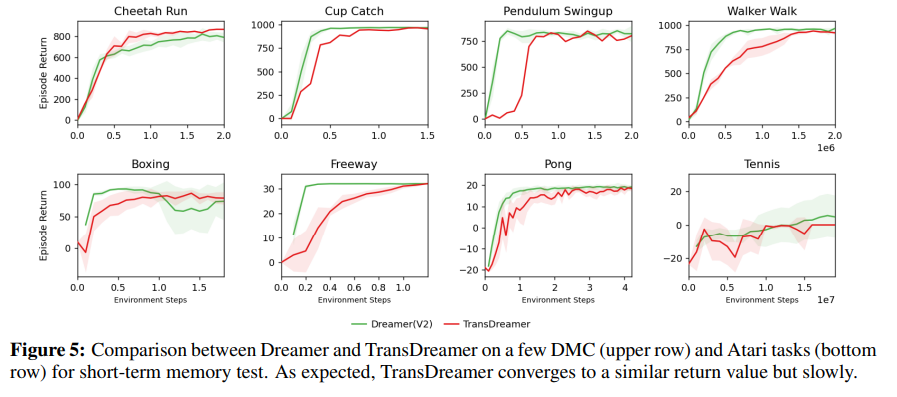 간단하게 Short term을 비교하기 위해서 DMC와 Atari를 진행해보았는데 원래 short-term에서 Dreamer가 빨리 학습할 줄 알았지만 반대로 TransDreamer가 더 빠르게 학습하는 경우도 있었다.
간단하게 Short term을 비교하기 위해서 DMC와 Atari를 진행해보았는데 원래 short-term에서 Dreamer가 빨리 학습할 줄 알았지만 반대로 TransDreamer가 더 빠르게 학습하는 경우도 있었다.
