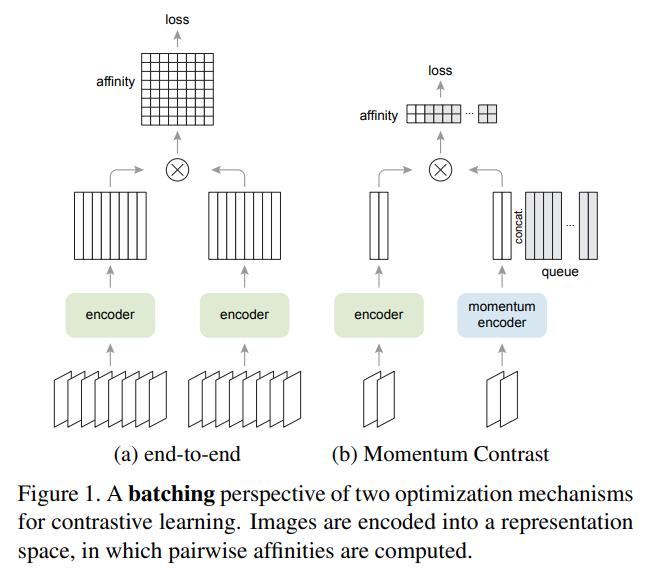
MoCo의 내용을 구현하는 과정을 가져보자.
구현은 여기에서 확인할 수 있다.
간단하게 기존에 작성하던 fine-tune과 호환이 가능하게 1개의 Class에 들어있는 모델과 같은 형식으로 만들었다
forward 구현
 직접적으로 학습이 되는 코드는 논문에 따르면 위와 같다.
직접적으로 학습이 되는 코드는 논문에 따르면 위와 같다.
def forward(self, query, key):
# X: N, C, H, W
query = self.query_encoder(query)
query = nn.functional.normalize(query, dim=1)
with torch.no_grad():
self.update_key()
key = self.key_encoder(key)
key = nn.functional.normalize(key, dim=1)
# (N, 128)
l_pos = torch.bmm(query.view(query.size(0), 1, -1),
key.view(key.size(0), -1, 1)).squeeze(-1) # (N,1,128) (N,128,1) -> (N,1,1) -> (N,1)
# (N,1)
l_neg = torch.mm(query, self.queue.clone().detach())
# (N,128) (128,queue_size) -> (N,queue_size)
# (N,1)+(N,queue_size) -> (N,queue_size+1)
logits = torch.cat([l_pos, l_neg], dim=-1) / self.tau
labels = torch.zeros(logits.size(0)).long().to(
logits.device) # 0번이 positive니까
self.dequeue_and_enqueue(key)
return logits, labels내가 작성한 코드는 논문의 내용을 거의 그대로 옮긴 것과 비슷하다.
MoCo의 내용을 이해하고 있다면 내용을 이해하기는 어렵지 않을 것이다.
x에 각기다른 augmentation을 적용해서 query와 key를 만들고
각자 query encoder, key encoder를 통과시켜서 encoding한다.
이후 SimCLR에 따르면 norm을 적용하는 것이 성능을 높혀준다고 하기에 norm을 적용하고
각각 dot product를 통해 유사도를 구한다.
그럼 (N, 1+Queue_size)의 크기의 tensor가 나오게 되는데
여기에다가 label이 0(positive가 0번째이기 때문)을 나타내기 위해서 zeros (N)을 만들어준다.
여기에다가 cross_entropy loss를 통해
이렇게 적용할 수 있다.
사실 이렇게 보면 어렵지 그냥 (N,65536)의 cross-entropy loss classifier이다. 그런데 label이 positive sample(0)이다.
모델 초기 설정
위와 같은 진행을 위해서 설정해야할 것들이 존재한다.
이것도 하나씩 본다면 간단하다.
우선 encoder을 각각 불러오고 projection head를 만들어준다.
self.query_encoder = load_model(args.model, class_num=dim)
self.query_encoder = self.query_encoder.to(device)
self.key_encoder = load_model(args.model, class_num=dim)
self.key_encoder = self.key_encoder.to(device)
dim_mlp = self.query_encoder.out.weight.shape[1]
self.key_encoder.out = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp),
nn.ReLU(),
nn.Linear(dim_mlp, dim),
)
self.query_encoder.out = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp),
nn.ReLU(),
nn.Linear(dim_mlp, dim),
)나 같은 경우에 기존에 만들었던 모델의 self.out이 마지막 layer로 만들었기 때문에 위와 같이 수정해주었다.
이후 key의 weight를 query와 동일하게 만들어주고 학습이 이루어지기 않기 때문에 grad를 꺼준다.
for param_q, param_k in zip(self.query_encoder.parameters(), self.key_encoder.parameters()):
param_k.data.copy_(param_q.data)
param_k.requires_grad = Falsedata augmentation은 dataset.py 파일에 다음과 같이 구현하였다.
아래처럼 구현됨에 따라서 위 forward에 query, key 2개가 input으로 들어오게 된다.
pretrain_transform = [
transforms.RandomResizedCrop(32, antialias=True),
transforms.RandomHorizontalFlip(),
transforms.RandomApply([transforms.ColorJitter(
brightness=0.4, contrast=0.4, saturation=0.4, hue=0.1)], p=0.8),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
class PretrainSplitter():
def __init__(self, transform):
self.augment = transforms.Compose(transform)
def __call__(self, x):
q = self.augment(x)
k = self.augment(x)
return [q, k]
if pretrain:
transform = PretrainSplitter(pretrain_transform)
dataset = dataset_class(root=root, train=train,
download=True, transform=transform)queue는 다음과 같이 구현하였다.
self.register_buffer("queue", torch.randn(dim, queue_size))
self.queue = nn.functional.normalize(self.queue, dim=0)
self.register_buffer("queue_ptr", torch.zeros(1, dtype=torch.long))
def dequeue_and_enqueue(self, keys):
batch_size = keys.size(0)
assert self.queue_size % batch_size == 0
ptr = int(self.queue_ptr)
# self.queue[:, ptr:ptr + batch_size].data = keys.T <- error 복사가 이루어지지 않음
self.queue[:, ptr:ptr + batch_size] = keys.T
ptr = (ptr + batch_size) % self.queue_size
self.queue_ptr[0] = ptr이때 self.queue에 세밀한 설정이 필요한데
self.queue[:, ptr:ptr + batch_size] = keys.T
이렇게 할당을 시켜주기 위해서는 in-place 연산이기 때문에 negative 연산에 바꾸어주어야 한다.
l_neg = torch.mm(query, self.queue.clone().detach())
즉 위와 같이 .clone().detach()를 작성해서 queue와 동떨어진 복사된 tensor를 사용해서 미분 과정에 포함되지 않게 만든다.만약 l_neg = torch.mm(query, self.queue.detach())로
표현을 하고 싶다면
self.queue[:, ptr:ptr + batch_size].data = keys.T
이렇게 하면 원본 queue에 복사가 되지 않기 때문에
self.queue.data[:, ptr:ptr + batch_size] = keys.T
이렇게 data를 안으로 넣어야 정상적으로 queue에 복사가 이루어진다.indexing을 진행하고 .data를 하면 배열이 복사되기에 제대로 이루어지지 않는 것 같다.
종합
class MoCo(torch.nn.Module):
def __init__(self, device, args, dim=128, queue_size=65536, m=0.999, tau=0.07):
super().__init__()
self.dim = dim
self.m = m
self.tau = tau
self.queue_size = queue_size
self.query_encoder = load_model(args.model, class_num=dim)
self.query_encoder = self.query_encoder.to(device)
self.key_encoder = load_model(args.model, class_num=dim)
self.key_encoder = self.key_encoder.to(device)
# in the paper moco use encoder with average pool layer as output
dim_mlp = self.query_encoder.out.weight.shape[1]
self.key_encoder.out = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp),
nn.ReLU(),
nn.Linear(dim_mlp, dim),
)
self.query_encoder.out = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp),
nn.ReLU(),
nn.Linear(dim_mlp, dim),
)
for param_q, param_k in zip(self.query_encoder.parameters(), self.key_encoder.parameters()):
param_k.data.copy_(param_q.data)
param_k.requires_grad = False
self.register_buffer("queue", torch.randn(dim, queue_size))
self.queue = nn.functional.normalize(self.queue, dim=0)
self.register_buffer("queue_ptr", torch.zeros(1, dtype=torch.long))
def forward(self, query, key):
# X: N, C, H, W
query = self.query_encoder(query)
query = nn.functional.normalize(query, dim=1)
with torch.no_grad():
self.update_key()
key = self.key_encoder(key)
key = nn.functional.normalize(key, dim=1)
# (N, 128)
l_pos = torch.bmm(query.view(query.size(0), 1, -1),
key.view(key.size(0), -1, 1)).squeeze(-1) # (N,1,128) (N,128,1) -> (N,1,1) -> (N,1)
# (N,1)
l_neg = torch.mm(query, self.queue.clone().detach())
# (N,128) (128,queue_size) -> (N,queue_size)
# (N,1)+(N,queue_size) -> (N,queue_size+1)
logits = torch.cat([l_pos, l_neg], dim=-1) / self.tau
labels = torch.zeros(logits.size(0)).long().to(
logits.device) # 0번이 positive니까
self.dequeue_and_enqueue(key)
return logits, labels나머지 method
나머지는 key의 weight를 update하고 모델을 저장하는 것이다.
눈으로 보고 이해할 수 있는 간단한 내용이기에 따로 설명하지 않겠다.
@torch.no_grad()
def update_key(self):
for param_q, param_k in zip(self.query_encoder.parameters(), self.key_encoder.parameters()):
param_k.data = param_k.data * self.m + param_q.data * (1. - self.m)
def save_model(self, output):
torch.save(self.query_encoder, output)최종 코드
class MoCo(torch.nn.Module):
def __init__(self, device, args, dim=128, queue_size=65536, m=0.999, tau=0.07):
super().__init__()
self.dim = dim
self.m = m
self.tau = tau
self.queue_size = queue_size
self.query_encoder = load_model(args.model, class_num=dim)
self.query_encoder = self.query_encoder.to(device)
self.key_encoder = load_model(args.model, class_num=dim)
self.key_encoder = self.key_encoder.to(device)
# in the paper moco use encoder with average pool layer as output
dim_mlp = self.query_encoder.out.weight.shape[1]
self.key_encoder.out = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp),
nn.ReLU(),
nn.Linear(dim_mlp, dim),
)
self.query_encoder.out = nn.Sequential(
nn.Linear(dim_mlp, dim_mlp),
nn.ReLU(),
nn.Linear(dim_mlp, dim),
)
for param_q, param_k in zip(self.query_encoder.parameters(), self.key_encoder.parameters()):
param_k.data.copy_(param_q.data)
param_k.requires_grad = False
self.register_buffer("queue", torch.randn(dim, queue_size))
self.queue = nn.functional.normalize(self.queue, dim=0)
self.register_buffer("queue_ptr", torch.zeros(1, dtype=torch.long))
def forward(self, query, key):
# X: N, C, H, W
query = self.query_encoder(query)
query = nn.functional.normalize(query, dim=1)
with torch.no_grad():
self.update_key()
key = self.key_encoder(key)
key = nn.functional.normalize(key, dim=1)
# (N, 128)
l_pos = torch.bmm(query.view(query.size(0), 1, -1),
key.view(key.size(0), -1, 1)).squeeze(-1) # (N,1,128) (N,128,1) -> (N,1,1) -> (N,1)
# (N,1)
l_neg = torch.mm(query, self.queue.detach())
# (N,128) (128,queue_size) -> (N,queue_size)
# (N,1)+(N,queue_size) -> (N,queue_size+1)
logits = torch.cat([l_pos, l_neg], dim=-1) / self.tau
labels = torch.zeros(logits.size(0)).long().to(
logits.device) # 0번이 positive니까
self.dequeue_and_enqueue(key)
return logits, labels
@torch.no_grad()
def dequeue_and_enqueue(self, keys):
batch_size = keys.size(0)
assert self.queue_size % batch_size == 0
ptr = int(self.queue_ptr)
self.queue.data[:, ptr:ptr + batch_size] = keys.T # <- error 복사가 이루어지지 않음
#self.queue[:, ptr:ptr + batch_size] = keys.T
ptr = (ptr + batch_size) % self.queue_size
self.queue_ptr[0] = ptr
@torch.no_grad()
def update_key(self):
for param_q, param_k in zip(self.query_encoder.parameters(), self.key_encoder.parameters()):
param_k.data = param_k.data * self.m + param_q.data * (1. - self.m)
def save_model(self, output):
torch.save(self.query_encoder, output)학습은 기존과 같이 진행하면 된다.
그런데 label을 model의 output과 함께 나오는 부분으로 바꿔주어야 한다.
(label이 0으로 바뀌기 때문에)
그리고 criterion은 cross_entropy_loss이다.
for idx, data in tqdm(enumerate(trainloader, start=0)):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs, labels = model(inputs)
loss = criterion(outputs, labels)
loss.backward()평가
evaluate는 다음과 같이 진행이 되었는데
trainset의 모든 데이터를 encoder를 이용해서 representation을 표현한다.
이후 test set의 batch 각각 trainset의 모든 부분과 거리를 계산해 KNN(k=1)의 label을 골라서 predict를 진행한다.
이후 정확도를 계산한다.
@torch.no_grad()
def eval_pretrain_model(model, trainloader, dataloader, device, pretrain):
acc = 0
if pretrain == "moco":
model = model.query_encoder
train_feature = []
train_labels = []
print("make train feature")
for data in tqdm(trainloader):
inputs, labels = data[0].to(device), data[1].to(device)
outputs = model.extract_features(inputs)
train_feature.append(outputs)
train_labels.append(labels)
train_feature = torch.cat(train_feature, dim=0)
train_labels = torch.cat(train_labels, dim=0)
# KNN으로 분류
print("comparing feature")
for idx, data in tqdm(enumerate(dataloader, start=0)):
inputs, labels = data[0].to(device), data[1].to(device)
outputs = model.extract_features(inputs)
# output이 (batch, 128) trainfeature가 (train, 128)이므로 cdist를 사용하여 거리 계산
dist = torch.cdist(outputs, train_feature)
knn = torch.topk(dist, k=1, dim=1, largest=False).indices
pred = train_labels[knn.squeeze()]
acc += torch.sum(pred == labels).item()
return acc / len(dataloader.dataset)결과
resnet18을 encoder로 사용하고 dict를 65536으로 정하였을 때
CUDA_VISIBLE_DEVICES=1 python3 main.py \
--pretrain moco \
--model resnet18 \
--dataset cifar10 \
--optimizer adamw \
--lr 0.003 \
--weight_decay 0.0001 \
--scheduler cos_annealing \
--T_max 200 \
--batch_size 256 \
--logging_step 1 \
--epoch 200 \
--logdir ./log_moco_resnet18_0.01_65536dict/ \
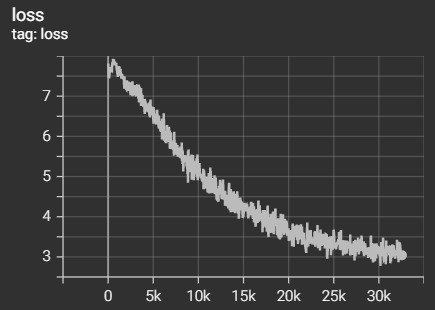
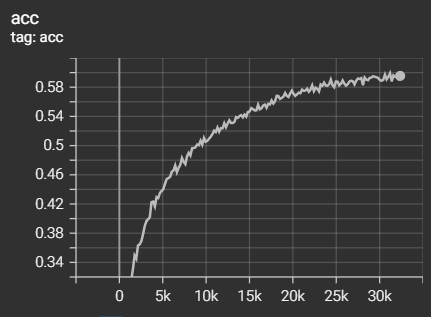
아래는 결과인데 대강 160epoch 정도 학습 도중에 캡쳐한 것이다.
self-supervised learning만으로
대략 cifar10기준 60% 정도의 정확도가 나왔다!
loss는 다음과 같다. 초반에 높아지는건 queue가 점점 채워지기 때문으로 생각된다.