- 우선 논문이 총 3페이지로 매우매우 짧다.
이전에 MoCo로 늘린 dictionary size에 SimCLR에서 제기된 projection head, strong augmentation를 넣은 것이다.
구체적인 정보를 보고 싶다면 각각의 논문 리뷰를 읽는 것이 좋을 것 같다.
Abstract
SimCLR의 2가지 design improvement를 MoCo에 적용을 해보았다.
- MLP projection head
- more data augmentation
이 과정에서 적은 batch size로 SimCLR의 성능을 넘겼다.
1. Introduction
논문 구성이 짧아서 간단하게 설명만 하겠다.
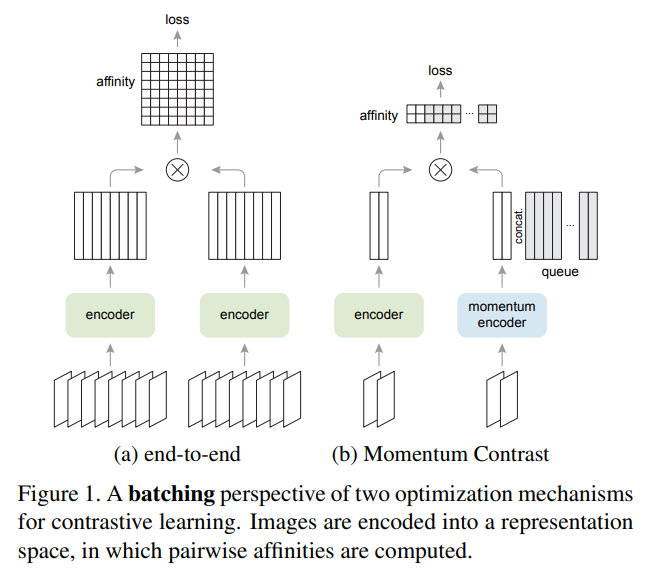
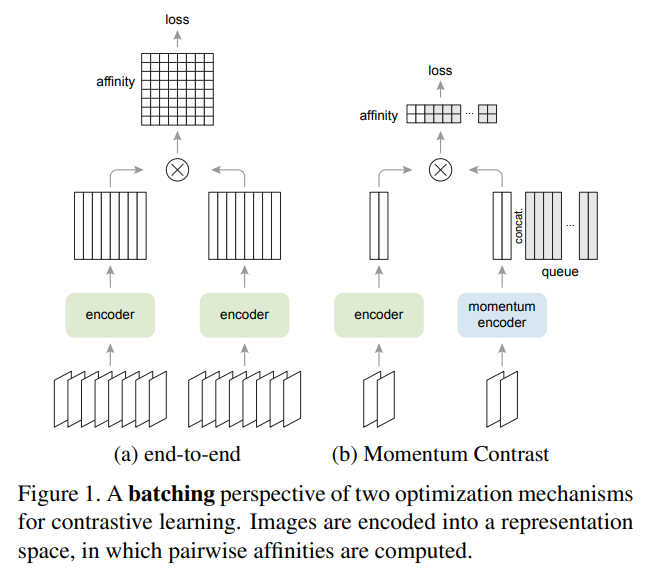 왼쪽은 SimCLR의 구조, 오른쪽은 MoCo의 구조라고 생각하면 될 것 같다.
왼쪽은 SimCLR의 구조, 오른쪽은 MoCo의 구조라고 생각하면 될 것 같다.
구체적인 내용은 첫문단에 적은 각 논문의 리뷰를 확인하면 될 것 같다.
loss는 다음과 같다.
contastive learning을 위해서 InfoNCE를 사용하였다. positive sample은 가깝게 하고 negative sample은 멀리 만든다.
q는 query, k는 key이고 k+는 positive k-는 negative sample이다. 는 hyper param이다.
Improved designs
간단하게 MoCo에 SimCLR의 projection head와 strong augmentation을 추가하였다.
3. Experiments
2개의 세팅으로 평가
1. imagenet linear classification: feature은 얼리고 마지막에 linear layer만 학습
2. transfer to VOC detection: transfer learning을 진행(fine tune end to end)
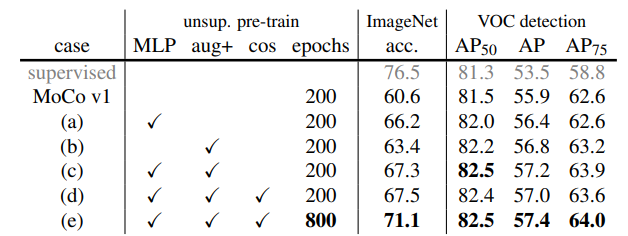
결과를 요약하면 위와 같다.
MLP는 mlp projection head이고 Aug+는 augmentation 추가, cos는 cos lr scheduler이다.
마지막은 epoch 증가이다.
점점 정확도가 증가한다.
MLP head
- imagenet linear classification 정확도
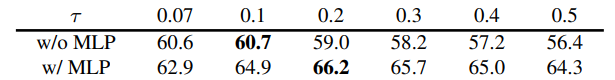
우선 MoCo의 head를 1개의 hidden(2048-d, ReLU)를 가진 MLP로 바꾸었더니 성능이 향상이 되었다.
차이는 생각보다 엄청 컸다. 59->66.2의 경우도 존재
그러나 2. detection 부분에서는 상승이 적게 일어났다.
Augmentation
처음 section에서 보인 table의 내용에서 기본 -> Aug+를 보면 성능의 향상이 이루어졌음을 알 수 있다.
특이한건 imagenet linear classifier에서의 성능향상보다 detection에서의 향상이 더 컸는데
논문에서는 각각 정확도의 증가가 비례관계가 아닌 것 같다고 적었다.
MLP와 섞어서 같이 사용하면 더욱 향상이 이루어졌다.
vs SimCLR
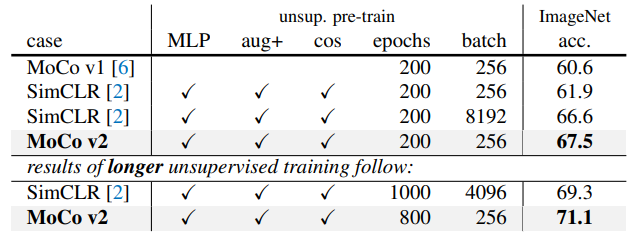 MoCo가 적은 batch로도 더욱 좋은 성능을 보였다.
MoCo가 적은 batch로도 더욱 좋은 성능을 보였다.
computational cost
마지막으로 계산량과 메모리 역시 MoCo가 더욱 적게 사용을 하였다.
같은 batch에서 성능이 더 뛰어나기 때문에 이 부분에서는 MoCo가 압도적인 성능을 보이는 것을 알 수 있다.
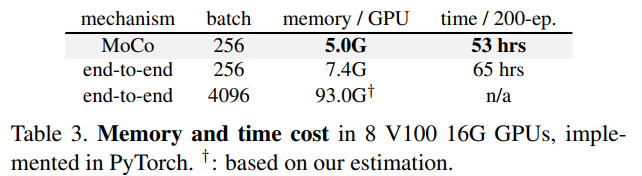
이러한 이유는 batch가 적은 것도 있겠지만 MoCo의 k-encoder에는 propagation이 일어나지 않기 때문도 있다.
구현
링크를 참조하자
