
Abstract
이 논문에서는 이전 Unsupervised Visual Representation Learning by Context Prediction 논문과 비슷하게 이미지의 맥락을 이용하지만 직쏘 퍼즐을 푸는 방식으로 self-supervised learning의 문제를 정의하였다.
다른 task와의 호환성을 위해 9개의 쌍둥이 CNN으로 구성된 Context-free network(CFN)을 제시하였는데 CFN은 각각의 input tile을 받고 receptive field를 줄인다.
CFN으로 직쏘퍼즐을 학습하면 Object part의 feature mapping과 그 부분의 정확한 정렬을 배운다.
또한 실험을 통해 알아낸 바에 따르면 이렇게 학습한 feature은 비슷한 이미지를 가진 것끼리 가깝게 표현이 된다.
1. Introduction
visual 분야에서 labeled data를 활용한 접근법은 성공적으로 연구가 되었지만 최근 labeling의 cost 때문에 unsupervised learning 연구가 대두되고 있다.
이러한 방법을 중에는 이전 논문리뷰에서 언급한 내용과 같이 이미지의 자체의 구조에서 정보를 얻어서 학습을 하는 self-supervised learning이 제시가 되었고 이 논문에서는 이와 비슷하게 Jigsaw puzzle을 모델에게 풀게 함으로써 self-supervised learning을 성공적으로 진행하였다.
Jigsaw puzzle을 모델에게 풀게 하는 과정에서 onject가 부분들로 구성이 되고 각 부분이 어떻게 구성이 되는지 학습하게 된다고 한다.
또한 이전의 Unsupervised Visual Representation Learning by Context Prediction 논문에서 문제가 되었던 색수차나 pixel 전처리를 해주어야하는 문제도 해결이 되었다고 한다.
색수치나 전처리 문제는 논문에서 언급이 되는데
직쏘 퍼즐을 풀면서 part의 localization을 학습하기 때문에 위 이미지와 같이 주로 비슷한 shape를 기준으로 학습이 진행이 되기 때문에 색이나 질감과 같은 부분은 별로 영향이 없다고 한다.
 (a)에서 이미지를 저렇게 추출하고 (b)와 같이 섞고 문제를 푼다.
(a)에서 이미지를 저렇게 추출하고 (b)와 같이 섞고 문제를 푼다.
여기에서 중요한 부분은 (c)를 봤을 때 이전에 중간에 1개의 타일을 주고 다른 타일의 위치를 찾는 문제에서 (c)의 왼쪽 제일 위와 옆의 타일을 보면 너무 비슷해서 사람이 보기에도 구별하기가 쉽지 않다.
이러한 문제는 (b)와 같이 다른 타일들을 함께 봄으로써 해결이 가능하다고 주장한다.
3. Solving Jigsaw Puzzles
아마 직쏘 퍼즐을 푸는 가장 직관적인 방법은 9개의 채널 방향으로 tile을 겹쳐서 input에 넣는 것일거다. (input에 1개의 patch는 3개의 채널이니까 3x9 channel)
그리고 CNN을 따라 진행하는 구조일건데
이러한 방법의 문제점은 모든 patch를 같이 보기 때문에 network가 high-level에서 보는 것이 아니라 texture이나 boundary 등 low-level texture의 관계에 집중을 하게 된다는 것이다.
이러한 부분들은 사람도 실제로 활용을 할 정도로 매우 간단한 요소이기 때문이다.
network가 이렇게 세세한 부분에 집중을 하는 것은 전체 object의 구조를 이해하지 못하게 하기 때문에 방해가 된다.
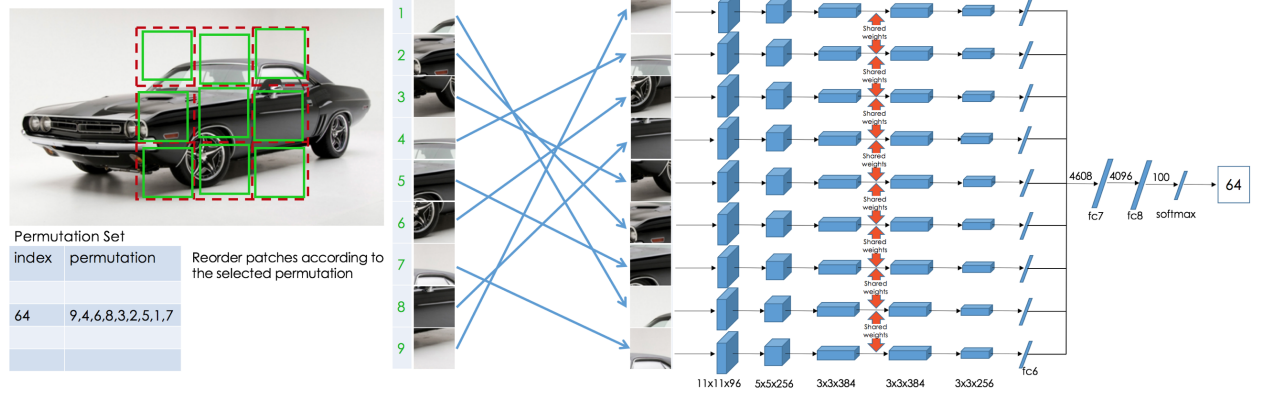
그렇기 때문에 논문에서는 이렇게 위와 같이 각각 input을 독립적으로 처리하고 종합적으로 보는 것을 최대한 미루는 CFN(context-free-network)를 제시한다. 각 patch 내부에서 최대한 feature 연산을 진행하고 마지막에 이러한 정보를 종합해서 진행을 하는 것이다.
3.1 The Context-Free Architecture
앞서 그림으로 간단하게 설명을 했는데 CFN은 각 9개의 공유하는 Alex-Net의 fc6까지의 구조를 병렬적으로 가진 network이다. fc6들의 값은 concat되어서 fc7로 들어간다.
여기에서 중요한 부분은 fc6까지의 동일한 구조는 모두 weight를 공유한다.
3.2 The Jigsaw Puzzle Task
퍼즐은 9!만큼의 숫자가 가능한데 이는 362880개로 매우 많다.
그렇기에 특정 개수만큼 permutation을 정해두고(1000개 정도) 이 정한 permutation으로 random으로 섞고 무슨 permutation으로 섞었는지 맞추게 된다.
ex) S = (3, 1, 2, 9, 5, 4, 8, 7, 6)이렇게 tile의 순서를 정한다.
3.3 Training the CFN
CFN의 결과는 아래의 수식과 같이 조건부 확률로 볼 수 있다.
여기에서 S는 위와 같이 permutation label이고 각 Ai는 input으로 들어온 i번째 part이다.
F는 CFN에서 나온 feature이다.
이와 같은 구조로 각 A가 F로 바귀고 F를 토대로 S를 찾는 확률로 볼 수 있다.
우리의 목적은 CFN의 feature F가 object의 상대적인 공간 정보를 잘 표현할 수 있게 만드는 것이다.
shortcut
만약 직쏘퍼즐의 permutation이 1가지라면 그냥 input의 순서가 결과이다. 이러면 는 아무런 2D 위치적인 의미만 가지고 구조적, texture의 의미를 가지지 못할 것이다.
이 외에도 edge, boundary, 색수차, 색 분포 등 세세한 정보로 우리의 목표가 아닌 잘못된 해답으로 문제를 푸는 것을 short cut이리고 부른다.
solution
이러한 shortcut을 해결하기 위해 1000개의 permutation을 사용할 때 보통 1장의 이미지로 평균 69개를 만들어서 input에 넣었다고 한다.
이 때 조금만 바꿔서 넣으면 의미가 없기에 Hamming distance를 크게 줬다고 한다.
여기에서 hamming distance는 몇개를 바꾸어야 이전과 같은지를 나타낸다.
ex) 1234, 1324 ->2개, 1234, 4123 -> 4개 즉 각 자리에서 다른 요소의 개수이다.
이는 CFN이 low-level cue로 문제를 푸는 것을 막을 수 있다.
그리고 이미지를 얻을 때 225x225로 resize하고 75x75 patch 3x3이 나오는데 이를 각 window의 64x64의 random region을 골라서 jitter를 주었다. 이를 통해 edge boundary 등으로 푸는 것을 막고
렌즈의 색수차로 문제를 푸는 것을 막기 위해 color channel jitter을 넣고 gray scale도 넣었다.
4. Experiment
4.1 Transfer Learning
CFN을 위 방법으로 사전학습하고 이 weight를 토대로 AlexNet을 initialization 후 fine-tuning을 진행하고 테스트를 진행하였다.
(이때 jigsaw의 학습에는 첫번째 cnn이 stride를 2 쓰지만 alexnet으로 가져올 때에는 원본과의 비교를 위해 stride를 4 사용하였다.)
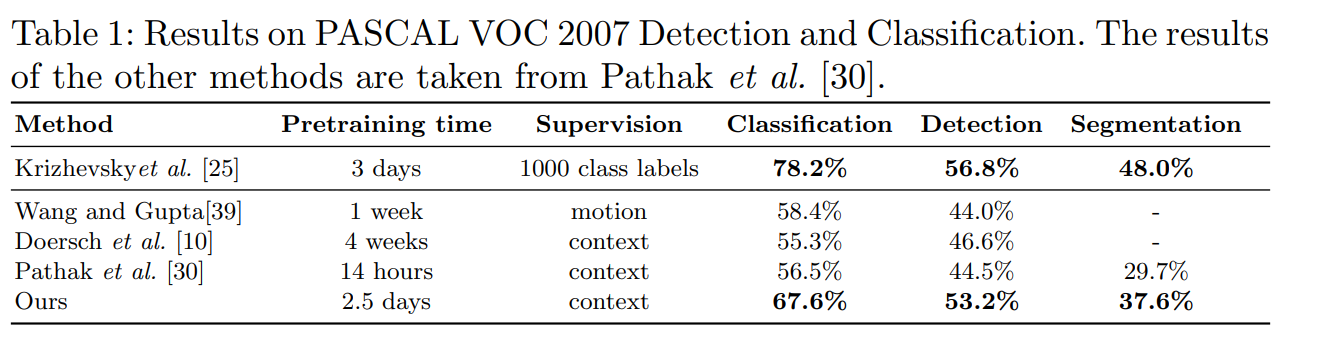 제일 위는 supervising으로 pre-train 된 것이고 아래는 self-supervised로 pre-train 된 것인데 지금 제시한 방법이 매우 높은 성능을 보여주고 supervising으로 된 것과의 차이를 많이 줄였다.
제일 위는 supervising으로 pre-train 된 것이고 아래는 self-supervised로 pre-train 된 것인데 지금 제시한 방법이 매우 높은 성능을 보여주고 supervising으로 된 것과의 차이를 많이 줄였다.
weight lock
그리고 이 부분이 신기했는데
object 분류 문제를 풀 때 앞부분의 conv layer는 feature을 추출하는 부분이고 뒤쪽의 convlayer는 domain specific 한 layer라는 연구 결과가 있었다고 한다.
그렇기에 논문의 저자도 테스트를 진행하였는데
pretrain한 모델의 conv layer를 각각 conv1 부터 conv j까지 weight를 lock을 하고 이후 layer는 초기화 후 다시 학습을 진행하였다.
이 때 conv4 까지는 큰 성능저하가 없는데 마지막 layer인 conv5 까지 lock을 진행하고 학습을 하면 domain specific한 성능이 떨어져 확실하게 떨어진다.
그리고 하나 더 conv4까지 적은 성능저하로 보았을 때 object classification과 직쏘 퍼즐의 feature은 관련이 되어있다고 판단하였다.

4.2 Ablation Studies
permutation set
permutation set은 task의 모호함을 결정한다.
만약 permutation이 비슷하면 직쏘퍼즐은 더욱 어려워지고 모호해진다.
예를들어 2개의 permutation의 차이가 오직 2개의 타일의 위치 차이이고 2개의 타일이 비슷하게 생겼으면 문제를 푸는 것은 불가능할 것이다.
저자는 permutation set을 3가지 기준으로 테스트 하였는데
-
cardinality: permutation set의 크기가 커지면 문제가 더욱 어려워지고 모델의 성능이 증가해진다고 보았다.
-
average hamming distance: hamming distance의 평균 거리도 직쏘 퍼즐의 어려움에 영향을 주었다고 한다. distance가 높아지면 모델이 문제를 더 잘풀고 fine-tune에서도 적은 error를 보였다고 한다.
-
minimal hamming distance: 최소 hamming 거리도 영향을 주었는데 less ambiguous를 준다. 그러나 minimum이 커지면 가능한 permutation의 숫자가 줄어들어서 적절한 선택이 필요하다.
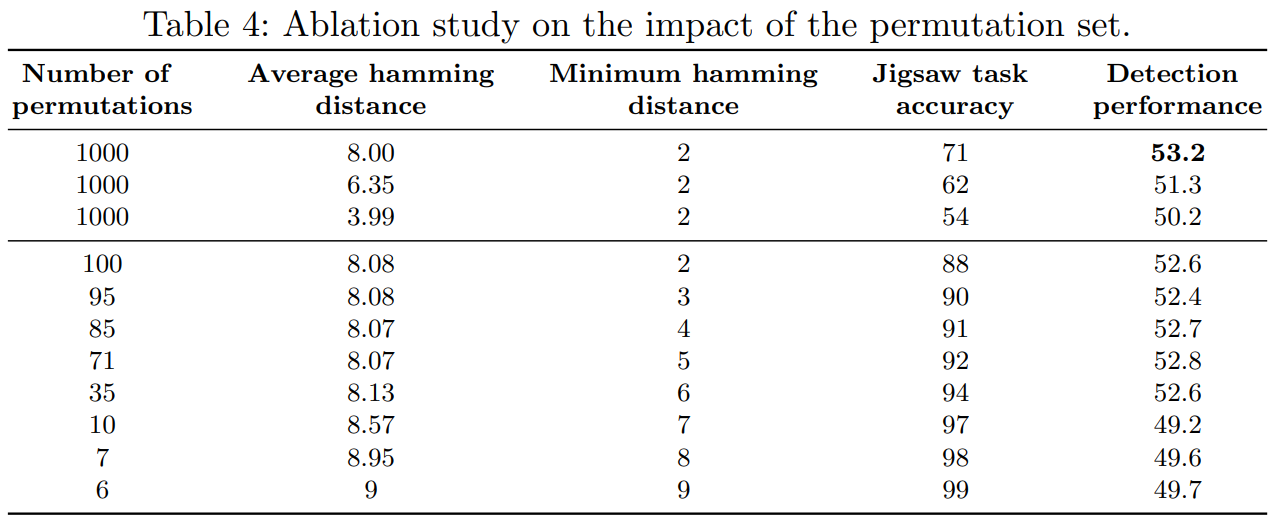
위 결과를 종합적으로 저자는 다음과 같이 말한다.
좋은 self-supervised task는 쉽거나 모호하면 안된다.
4.3 CFN filter activations
이 부분에서는 CNN의 출력을 연구하였는데
CNN이 잘 나타내는 category가 존재한다고 한다.
각 layer별로 잘 나타내는 category를 확인하기 위해 imagenet의 patch를 넣고 각 layer의 출력을 L1 norm으로 (절댓값이 가장 큰 것)골라서 가장 출력 output 값이 높은 것을 골랐다.
이때 각 layer의 출력 채널을 여러개니까 이 중 6개의 채널을 손으로 골라서 각 채널을 잘 나타내는 16개의 이미지를 골라서 표현을 해보았다.
 각 채널별로 잘 나타내는 category가 얼굴, 강아지, 패턴 등으로 나누어서 정리가 되어있는 것을 알 수 있다.
각 채널별로 잘 나타내는 category가 얼굴, 강아지, 패턴 등으로 나누어서 정리가 되어있는 것을 알 수 있다.
