2024년 10월 8일 그러니까 작성 시점에서 2일 전에 마이크로소프트에서 나온 따끈따끈한 논문인데
되게 재밌는 논문이다.
시험기간도 겹치고 연구실에서 하는 일도 있느라 바빠서 논문을 다 읽어보지는 못했고
핵심 아이디어만 간단하게 적어보겠다.
나중에 시간이 되면 글 수정해서 더 작성하도록 하겠다.
소개
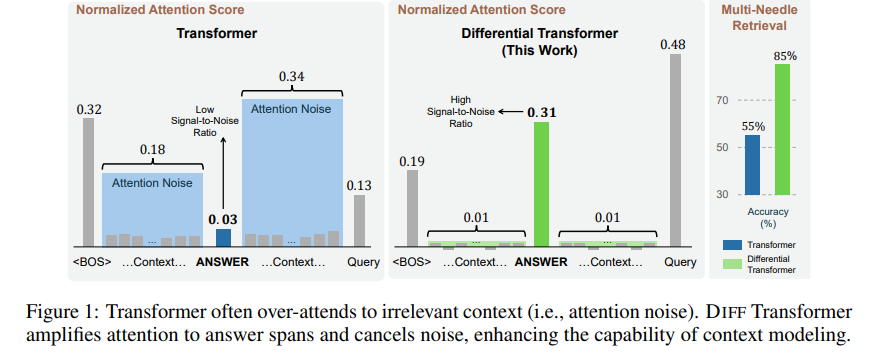 기존 transformer는 over attend 즉 쓸모없는 noise attention이 너무 많았다. 이러한 경향 때문에 예측이 불안정해짐.
기존 transformer는 over attend 즉 쓸모없는 noise attention이 너무 많았다. 이러한 경향 때문에 예측이 불안정해짐.
Differential Transformer는 이러한 Noise를 제거하는 획기적인 방법을 제시함.
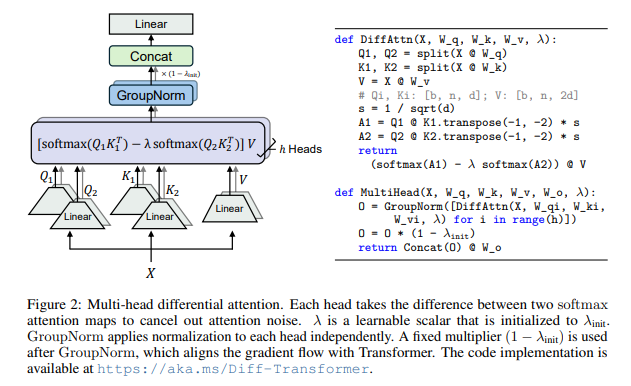
Differential Attention
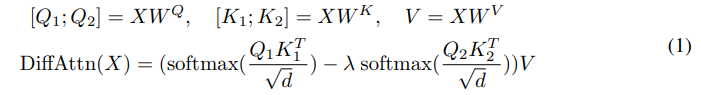 이는 Query와 Key를 기존과는 다르게 2개로 쪼갠다.
이는 Query와 Key를 기존과는 다르게 2개로 쪼갠다.
이를 통해서 각각의 query와 key를 계산하고 이를 빼는데
이러한 과정에서 Noise가 제거된다고 한다.
이떄 lambda는 learnable param으로 구성이 되어있고 위의 학습하는 과정과 맞추기 위해서 아래와 같이 식을 구성한다.
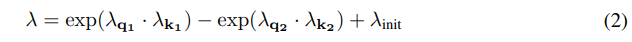
은 초기 값을 설정해주기 위함.
def lambda_init_fn(depth):
return 0.8 - 0.6 * math.exp(-0.3 * depth)공식 깃허브 들어가보면 이렇게 간단하게 구현이 되어있다.
원리는 Noise canceling을 생각하면 쉬운데
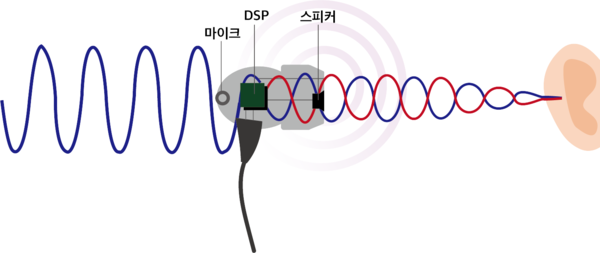
위와 같이 Noise가 있는 상태의 Q1,V1과 Q2,V2가 있을 것인데 둘 다 특정 feature에 집중을 할 것이고 나머지는 Noise로 가지고 있을 것이다. 이를 빼주는 과정에서 Noise는 상쇄되어 사라지는 것이라고 한다.
의사 코드는 아래와 같다.
결과
되게 재밌었던 부분은
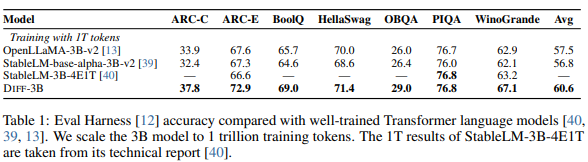
이렇게 Noise를 제거해주기만 해도 엄청 성능이 향상이 된다.
심지어 Noise 때문에 앞부분에 attention이 약해져서 문맥을 까먹는 것도 완화가 된다고 하고 할루시네이션도 해결이 된다고 한다.
