요약
BEiT + DINO이다.
encoder에 3-layer MLP header 구조인데 MLP는 8192차원으로 dVAE와는 다르게 여러개의 분포로 만드는 tokenizer와 비슷한 기능을 한다.
이후 DINO의 1개는 global, 1개는 local의 구조를 iBOT에서는 1개는 원본, 1개는 maksing된 이미지로 보고 CLS token을 이용해서 전체 구조를 통해 tokenizer를 학습하고
BEiT의 masking을 복원하는 내용은 각 encoded masked patch에 header를 이용해서 원본 patch의 softmax 분포와 같게 만들도록 학습을 하였다.
이 두 학습을 합친 것이 iBOT이다.
Abstract
NLP분야에서 transformer의 성공의 큰 요소는 MLM(masked language modeling)에 있다.
이 논문에서는 MIM(masked image modeling)을 제시하고 이의 이점과 의미있는 visual tokenizer를 사용하는데에 있어서의 어려움에 대해서 나타낸다.
이 논문은 iBOT을 제시하는데 masked prediction을 online tokenizer를 이용해서 학습하는 방법을 제시한다.
구체적으로 self-distillation을 masked patch token에 실행하고 teacher network를 online tokenizer로 활용해서 시각적 의미를 위해서 class token에 대해서도 self-distillation을 사용해서 학습을 진행한다.
이때 이전의 BEiT의 논문과는 다르게 online tokenizer가 학습 도중에 학습이 되기 때문에 multi stage training의 pipeline이 있다고 생각할 수 있다.
이렇게 학습한 IBOT은 SOTA를 달성하였고 data corruption에 매우 robust했다고 한다.
1 INTRODUCTION
MLM(masked language modeling)은 nlp분야의 사실상의 표준이 되었고 dataset의 scalability를 만들며 매우 좋은 성능을 보였다. 그러나 image 분야에서는 자세히 탐구되지 않았다.
최근 이미지는 그냥 단순히 global view를 활용한 내용이 대부분이고 MLM과 같은 이미지의 내부 구조를 간과한다.
이 논문은 MIM(masked image modeling)을 이용하여 NLP와 비슷한 방법으로 vision transformer를 학습하는 방법을 제시한다.
MLM의 가장 중요한 요소는 lingual tokenizer이다. 이는 language를 meaning ful token으로 나눈다.
비슷하게 MIM의 중요한 요소 역시 visual tokenzier이다. 이때 visual tokenizer는 maksed patch를 target model의 supervisory signal로 만든다.
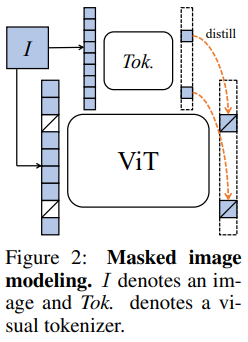
이거를 보다가 궁금한 부분이 nlp의 tokenizer는 의미를 단위로 유동적으로 자르는데 현재 Image 분야는 VQ-VAE의 구조로 이미지를 고정된 patch 단위로 잘라서 mapping을 한다.
이런 상황에서 이미지의 크기도 유동적으로 자르면 더 의미 있는 부분은 더 많이 잘라서 더 잘 학습하지 않을까?
하지만 언어적인 의미는 word frequency에 대한 분석을 통해 자연적으로 나오지만 visual semantic은 연속적인 특성 때문에 쉽게 나올 수 없다.
- 실질적으로 visual semantic은 왜곡된 이미지 view의 유사성을 통해서 만들어진다.(Simclr 등등)
이러한 이미지의 특정은 이전 BEiT의 논문과도 같이 semantic rich tokenizer를 먼저 학습하고 그 다음 target model을 학습하는 구조로 만든다.
하지면 visual semantic을 학습하는 것은 tokenizer와 model 모두의 목표이다.
결국 single pipeline이 연구되고 있다.
몇몇 pipeline에 대한 방법은 visual tokenizer에 itentity mapping을 사용해서 raw pixel을 예측하도록 하였는데 이는 high-frequency datail을 modeling하는데 capacity 낭비 뿐만 아니라 semantic understanding에 낮은 성능을 보였다.
BEiT는 VAE를 이용하여 abstraction을 얻어 low-level semantic을 capture할 수 있었다. 하지만 tokenizer은 고정된 architecture로 extra dataset을 이용하여 offline pre-train이 되어야 하였다. 이는 MIM을 다른 domain에 이용하는 것에 limit을 줄 수 있다.
이 논문은 iBOT을 제시한다. 이는 image BERT pre-training
with Online Tokenizer이라는 의미이고 MIM을 앞서 언급한 문제를 해결한 tokenizer를 이용하여 진행한다.
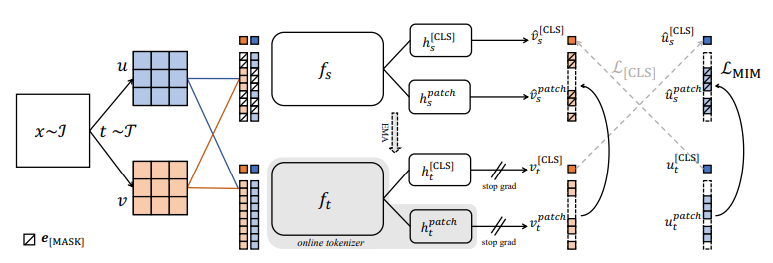
iBOT는 MIM을 knowledge distillation으로 만들어서 tokenizer에서 distill을 진행하고 twin-teacher(DINO 같은 구조)을 통해서 MIM을 수행한다.
target network는 masked image를 input으로 받고 online tokenizer는 original image를 받는다. 목적은 target network가 tokenizer의 output을 복구하는 것이다.
이때 tokenizer는 2가지의 문제를 해결해야하는데
1. class token의 유사성을 가깝게 하면서 high level visual semantics를 학습한다.
2. MIM + momentum update를 이용해서 pre-processing setup없이 online으로 학습이 되어야 한다.
이러한 구조로 매우 뛰어난 성능을 얻었다.
2 PRELIMINARIES
2.1 MASKED IMAGE MODELING AS KNOWLEDGE DISTILLATION
MIM은 이미지를 token sequence 으로 만드는 것이다.
이후 random mask를 특정 비율로 만들고 이를 masking token 로 대체한다.
masked token은 다음과 같다.
로 구축한다.
이렇게 이를 이용해서 masked token을 복구한다.
로 이를 최대화 해야한다.
는 원본을 복구할 확률인데 masking 일 때만 증가해야 하니까 로 표현이 가능하다.
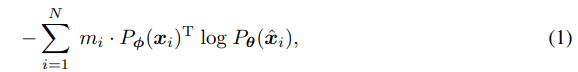 BEiT에는 위와 같이 구성이 되는데 는 dVAE이다.
BEiT에는 위와 같이 구성이 되는데 는 dVAE이다.
one-hot encoding이기 때문에 간단하게 vocabulary에서 값을 복구하는 것으로 볼 수 있고 masking된 image로 원본과 확률을 동등하게 맞추는 즉 복구하는 것이다.
논문의 저자는 이 구조가 knowledge distillation과 비슷하다고 보았다.
왜냐하면 teacher이 이미지를 사전학습한 tokenizer이고 여기에 담긴 내용을 target network가 학습을 하는 것과 비슷하기 때문.
2.2 SELF-DISTILLATION
DINO 논문에서 제시된 Self-distillation은 이전 iteration의 model 자신을 teacher가 목표로 학습이 되며 discriminative object로 설정이 된다.
1개의 이미지에 대해서 2개의 다른 view 를 만들고 이를 각각 teacher-student framework에 넣는다. 이후 [CLS] token으로부터 categorical distribution을 예측한다.
여기에서 teacher과 student는 같은 구조를 공유하고 각각 projector head 를 가진다.
teacher의 weight는 EMA(Exponentially Moving Average)로 학습이 된다.
loss는 두 view에 대해서 각각 바꿔서 수행하는 식으로 대칭이다.
3 IBOT
본격적인 시작인데 앞서 이야기했던 2개의 loss의 조합으로 표현이 된다.
2개의 view 를 만들고 이를 masking한 로 표현이 된다.
이때 student는 를 받아서 patch token을 로 만들어지고 teacher network는 온전한 input을 가지고 새로운 patch token을 다음 수식과 같이 만든다.
이제 iBOT의 MIM 목표는 다음과 같다.
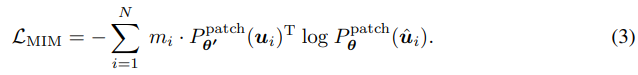 간단하게 masking 된 patch에 대해서 student network는 teacher network의 output을 학습하는 것이다.
간단하게 masking 된 patch에 대해서 student network는 teacher network의 output을 학습하는 것이다.
이를 뿐만 아니라 에 대해서도 동일하게 수행하고 loss를 평균화해서 대칭으로 만든다.
backbone과 연결된 teacher network의 projection head 는 각 masked patch token의 online token 분포를 만드는 tokenizer로 볼 수 있다.
iBOT의 tokenizer는 MIM을 진행하면서 online으로 학습이 된기 때문에 사전학습할 필요가 없다. 또한 이러한 특징 덕분에 domain knowledge가 특정 dataset에 고정되는 것이 아니라 현재의 dataset에서 distilled 될 수 있다.
online-tokenizer가 semantically-meaningful하기 위해서 이 논문에서는 DINO, Simclr 등의 방법과 같이 2개의 view에 대해서 self-distillation을 [CLS] token에 적용을 하였다.
이 논문에서는 DINO의 방법을 골랐는데 가 아니라 으로 masking된 cls token를 student에 넣는 방법을 이용해서 진행하였다.
이때 CLS 토큰을 이용해서 학습하는 semantic abstraction 효과를 다른 patch에도 적용을 할 수 있게하기 위해서 나머지 patch token들과 동일한 param을 사용하였다.
, 논문의 저자들은 실제로 이렇게 사용하는 것이 더 좋은 성능을 보였다고 한다.
저자는 projector의 사용에 대해서 다음과 같이 말한다.
"토큰화된 단어는 의미가 거의 확실한 반면, 이미지 패치는 그 의미가 모호합니다. 따라서 원-핫(one-hot) 이산화 방식으로 토큰화하는 것은 이미지에 대해 최적이 아닐 수 있습니다. iBOT에서는 원-핫 토큰 ID 대신 소프트맥스(softmax) 후의 토큰 분포를 감독 신호로 사용하며, 이는 표 18에서 보여지듯이 iBOT 사전 학습에서 중요한 역할을 합니다."
이부분 역시 dVAE를 사용한 BEiT와의 큰 차이점이라고 본다.
3.2 IMPLEMENTATION
Architecture
backbone으로는 ViT 시리즈를 사용
image의 크기는 224x224, patch의 크기는 16x16, patch의 숫자는 196
projection head에는 3-layer MLP + l2 normalized bottleneck을 사용
patch head와 CLS head의 전략을 다양하게 연구해보았지만 공유가 제일 좋았다.
공유된 head의 출력 차원은 8192로 설정하였다.
pretraining setup
- ImageNet-1K data 사용.
- AdamW
- batch 1024
- ViT-S/16: 800 epoch, ViT-B/16: 400 epoch, ViT-L/16:250 epoch, Swin-T: 300epoch
- MIM masking ratio uniform [0.1, 0.5]
- Log는 CLS+MIM으로 no scaling
4 EXPERIMENT
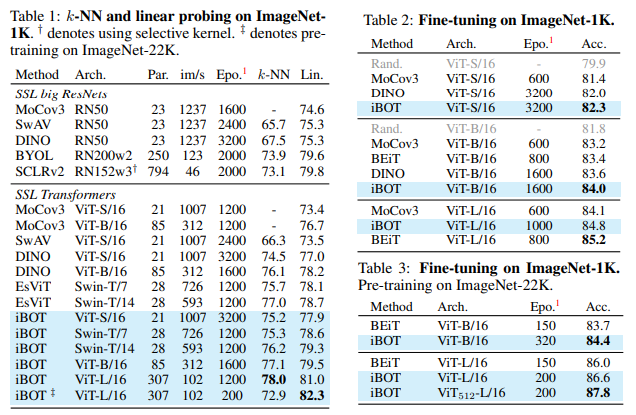 SOTA의 매우 좋은 성능을 보였다.
SOTA의 매우 좋은 성능을 보였다.
4.3 PROPERTIES OF VIT TRAINED WITH MIM
4.3.1 DISCOVERING THE PATTERN LAYOUT OF IMAGE PATCHES
What Patterns Does MIM Learn?

projection head는 token의 distribution을 그린다. MIM이 학습하는 pattern을 이해하기 위해서 ImageNet-1K의 validation set에서 가장 자신감이(예측하는 확률이) 높은 36개의 patch를 시각화 하였다.
각 16x16의 patch에 5 5의 context를 시각화 하였다.(오렌지 색)
몇몇 patch는 clear semantic meaning을 가지는 그룹으로 묶여있다.(개의 귀나 자동차 head light 등).
이런 내용은 BEiT과 같이 대부분의 의미를 low-level detail을 압축하는 offline tokenizer와는 뚜렷하게 다르다.
 이러한 특성 뿐만 아니라 low-level의 의미를 모아주는 cluster도 목격이 되었다고 한다.
이러한 특성 뿐만 아니라 low-level의 의미를 모아주는 cluster도 목격이 되었다고 한다.
How Does MIM Help Image Recognition?
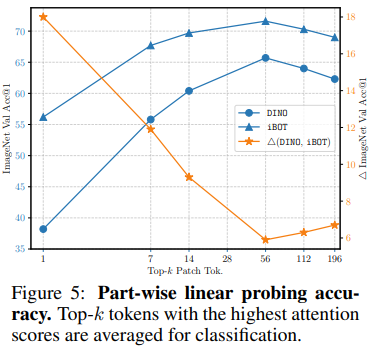
CLS token 대신 patch token을 가지고 linear eval을 하였는데 k의 의미는 attention score 상위 K개 token을 평균내서 사용을 하였다고 한다.
CLS 토큰을 사용하였을 때에는 iBOT과 DINO의 차이는 0.9%로 거의 차이가 나지 않지만 실제로 patch를 사용하였을 때에는 차이가 매우 컸다.
이러한 의미는 iBOT의 patch token에 많은 semantic 정보가 포함되어 있음을 보여주며 이는 모델이 local 세부사항의 변경에 더욱 강하다는 것을 보여준다.
4.3.2 DISCRIMINATIVE PARTS IN SELF-ATTENTION MAP
attention을 head마다 다르게 그리면 object를 성공적으로 나눠서 그리는 것을 알 수 있었다.
 이러한 능력이 iBOT이 사물을 인식하는 능력이라고 본다.
이러한 능력이 iBOT이 사물을 인식하는 능력이라고 본다.
4.3.3 ROBUSTNESS
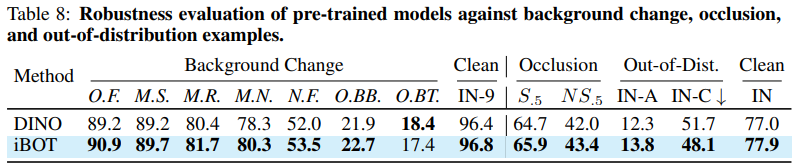 3가지 측면으로 진행하였고 위 표와 같다.
3가지 측면으로 진행하였고 위 표와 같다.
4.4 ABLATION STUDY ON TOKENIZER
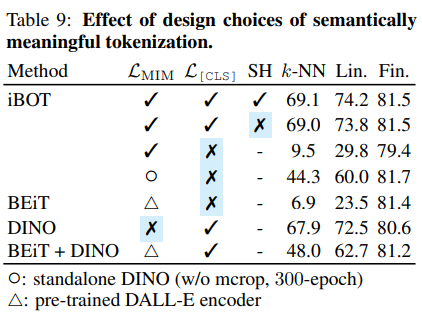 결과에서 재밌는 부분은 L[CLS]없이믄 9.5%로 학습이 되지 않는다는 것이다.
결과에서 재밌는 부분은 L[CLS]없이믄 9.5%로 학습이 되지 않는다는 것이다.
MIM만으로는 제대로 학습할 수 없다.
또한 독립적인 DINO를 사용했을 때에도 44.3%로 괜찮은 결과를 보이지는 못하였다.
