Abstract
이 논문은 BEiT를 소개한다.
BEiT는 Bidirectional Encoder representation from Image Transformers라는 의미이다.
BERT의 Masked Language Modeling을 vision transformer에 적용하였다.
Pretraining 과정에서 이미지는 2개의 view로 구성이 되는데
1. image patch: 즉 16x16의 patch 단위로 잘라서 구성
2. visual token
먼저 original image를 visual token으로 tokenize한다. (NLP와 비슷하게)
이후 이미지 patch를 random하게 masking을 하고 이를 transformer에 넣는다.
학습의 목적은 masking된 이미지를 가지고 원본 token을 복구하는 것이다.
사실 Masking을 한 이미지 patch로 원본을 복구하는 측면에서는 MAE(Masked Autoencoders Are Scalable Vision Learners)와 거의 비슷한 내용으로 보인다. 그러나 MAE는 원본 이미지를 복구하지만 BEiT는 token을 복구한다.
1 Introduction
Transformer는 좋은 성능을 보이지만 막상 convolution보다 많은 데이터가 학습에 필요하다. 이를 해결하기 위해서 self-supervised learning이 중요하다.
이 논문은 BERT가 masking 된 sequence에서 masking된 내용을 예측하는 것을 토대로 vision 분야의 transformer에 적용을 하였다.
이때 중요한 차이점은 BERT의 경우 token을 예측할 때 softmax와 같은 방식으로 classification의 방식으로 예측을 하는데 우선 Vision transformer에는 이러한 vocabulary가 없어 softmax를 적용할 수 없다.
이 때문에 regression problem으로 바꾸어서 보았다.
이때 regression에서 복구하는 내용이 원본 이미지일 수도 있고 encoding된 token일 수 있는데 원본 이미지의 복구는 modeling cost의 낭비가 심해서 이를 극복하는 것이 중요하다. 이 논문에서는 token을 예측하는 것으로 극복하였다.
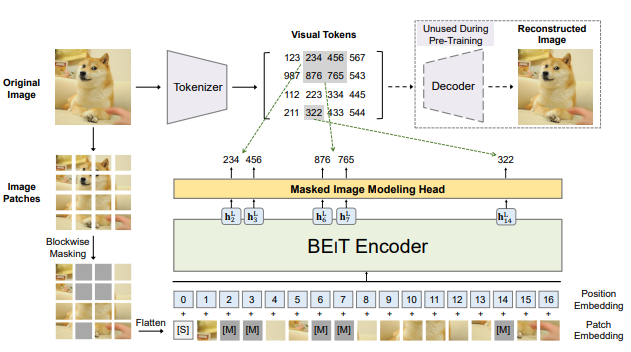
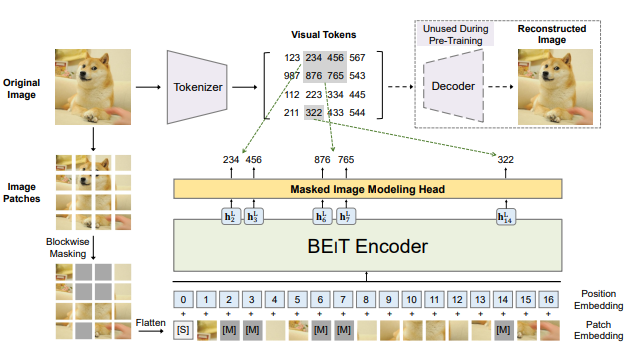
이때 tokenize는 VAE로 tokenizing을 학습을 해서 적용을 한다.
위 그림과 같이 이미지를 patch 단위로 자르고 masking을 하고 transformer에 넣은 뒤 원본을 예측한다.
사실상 input이 이미지라는 것만 제외하면 tokenizing부터 모든 과정이 BERT와 똑같다.
2 Methods
위 그림처럼 이미지 가 주어졌을 때 BEiT는 contextualized vector representation으로 encode한다.
이후 task를 학습할 때에는 BEiT encoder 위에 task layer를 올려서 fine-tune을하였다.
2.1 Image Representations
이미지는 2개의 view가 있다 image patch와 visual tokens.
2개는 각각 input과 output으로 pre-train에 활용이 된다.
2.1.1 Image Patch
그냥 간단하게 의 구조에서 일 때
로 구성을 한다.
이후 각 patch는 flatten되고 BERT의 work embedding과 비슷하게 linearly projection 된다.
2.1.2 Visual Token
NLP와 비슷하게 이미지 patch를 image tokenizer의 token으로 표현을 한다.
이미지 를 의 token으로 바꾸는데
로 각 token이 들어있는 vocabulary로 구성을 한다.
이는 dVAE로 가능하다고 한다.
dVAE는 encoder와 decoder로 이루어져 있는데 encoder는 로 구성이 되며 이미지 픽셀 를 codebook에 있는 로 mapping을 시킨다고 한다.
이후 decoder는 로 token들을 원본 이미지로 복구시킨다고 한다.
를 학습하는게 우리의 목적이다.
latent token은 discrete하기 때문에 미분이 불가능해서 Gumble-softmax를 사용해서 학습을 하였다고 한다.
이 논문에서는 이미지의 14x14의 이미지 토큰들로 분해해서 만들었다고 한다.
224x224를 16x16의 patch로 나누어서 14x14로 구성
이때 visual token의 숫자와 patch의 숫자는 동일하다.
Voca size 로 사용하였다고 한다.
2.2 Backbone Network: Image Transformer
backbone은 VIT를 사용
간단하게 patch를 만들고 이를 핀 다음 앞에 [S]토큰을 붙이고 positional embedding을 더하고 학습
2.3 Pre-Training BEIT: Masked Image Modeling
앞서 설명한 바와 같이 Input patch를 masking을 하고 이를 예측한다.
1. 이미지를 patch로 나눈다.
2. N개의 Visual token으로 만든다.
3. 40% 정도의 patch를 masking한다.
4. 이렇게 masking하는 patch를 학습가능한 embedding 로 바꾼다.
5. 이렇게 구성한 patch들을 transformer에 넣는다.
6. 마지막 vector 은 patch의 encoded representation으로 간주한다.
7. 각 masked patch의 encoded representation을 가지고 softmax classifier를 사용하여 원본의 token을 예측한다. .
여기에서 이고 이다.
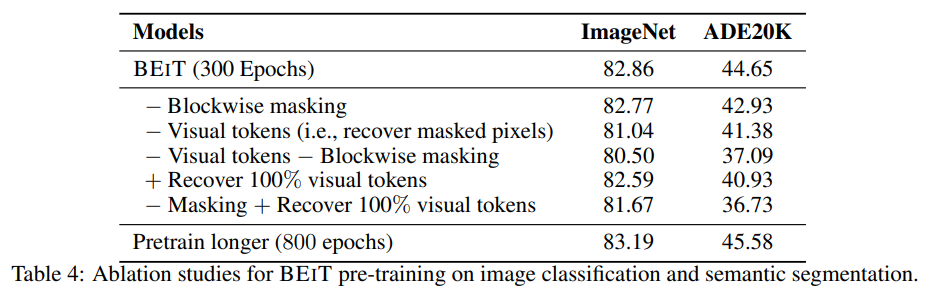
결국 pretraining의 학습 목표는 masked token을 가지고 visual token을 잘 예측하는 것이다.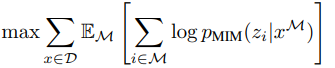 이때 masking을 random하게 patch의 위치를 고르는 것이 아니라 blockwise masking을 사용하였다.
이때 masking을 random하게 patch의 위치를 고르는 것이 아니라 blockwise masking을 사용하였다.
 위 코드를 보면 이해가 쉬운데 s는 block에 들어있는 patch의 숫자이다. 최소 16~최대 0.4N-|M|으로 구성
위 코드를 보면 이해가 쉬운데 s는 block에 들어있는 patch의 숫자이다. 최소 16~최대 0.4N-|M|으로 구성
r은 block의 종횡비, a는 block의 높이 b는 block의 너비 (a*b하면 s가 나옴)
이후 t는 block의 세로 위치 시작지점 l은 가로 위치 시작지점.
이를 토대로 M에 추가.
pixel level의 auto encoding은 model이 short-range dependency와 high-frequency detail에 집중하게 만든다.
BEiT는 이를 discrete visual token을 만들어서 이미지의 디테일을 high-level abstraction으로 만들어서 해결하였다.
2.4 From the Perspective of Variational Autoencoder
BEiT는 VAE의 관점에서 볼 수 있다.
원본 이미지는 , masked image는 , 는 visual token.
masking된 이미지를 복원하는 확률 의 lower bound를 학습하는 것으로 다음과 같이 수식을 볼 수 있다.
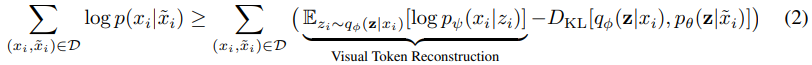 는 image tokenizer이고 는 visual token을 original image로 복구한다.
는 image tokenizer이고 는 visual token을 original image로 복구한다.
는 masking된 image로부터 visual token을 복구한다.
간단하게 Reconstruction이 잘되면 의 값이 높아져서 lower bound가 높아질 것이다.
또한 가 의 분포와 비슷하다는 것은 원본을 더 잘 복구했다는 것을 의미하고 KL divergence가 낮게 나오는 것으로 lower bound가 높아질 것이다.
그리고 위 loss는 2개의 step으로 이루어진다.
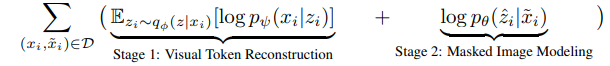 step1은 dVAE를 학습해서 visual token이 원본으로 잘 복원이 되느냐.
step1은 dVAE를 학습해서 visual token이 원본으로 잘 복원이 되느냐.
step2는 tokenizer 와 decoder 를 고정하고 encoder 를 학습해서 Masked된 이미지가 잘 복원이 되느냐.
여기에서 를 로 표현을 할 수 있으니 제거하면 위와 같이 표현이 된다.
이게 BEiT의 학습 목표이다.
2.6 Fine-Tuning BEIT on Downstream Vision Tasks
특이하게 Image classification의 과정에서
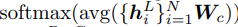 위와 같이 모든 encoded representation에 동일한 linear layer를 곱한 것들의 평균을 가지고 softmax를 진행을 하였다.
위와 같이 모든 encoded representation에 동일한 linear layer를 곱한 것들의 평균을 가지고 softmax를 진행을 하였다.
3 Experiments
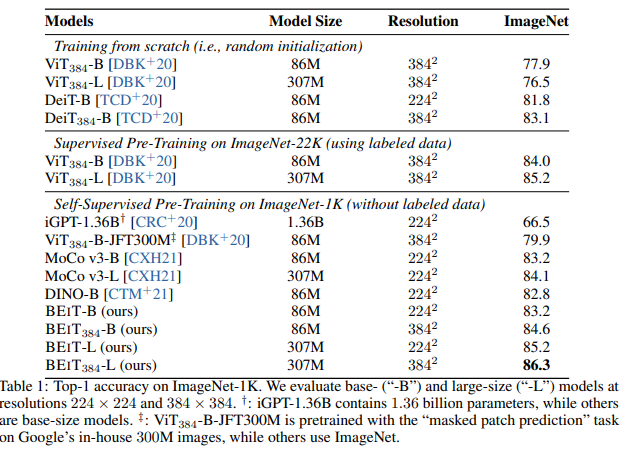 심지어 supervised 학습된 model보다도 더 좋은 성능을 보였다.
심지어 supervised 학습된 model보다도 더 좋은 성능을 보였다.
그리고 모델이 B -> L이 될때 supervised보다 BEiT이 더 큰 성능의 향상이 존재하였다. 즉 모델의 크기가 커질수록 BEiT의 이점이 커진다.
결국 모델의 크기에 비해서 label된 data의 크기가 적은 경우에서 self-supervised leanring을 통해 충분한 양의 데이터를 학습할 수 있다.
되게 특이한건 BEiT으로 한번 학습을 한것만으로도 supervised보다 더 좋은 성능을 보였지만 이후 fine-tune을 조금 더 진행하면 더욱 좋은 성능을 보여준다.
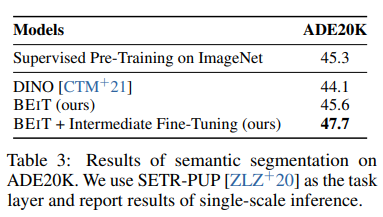
아래는 추가 실험 내용이다.
 attention map은 마지막 layer에서 각 patch를 고르고 그 patch를 query로 두고 key를 나머지 patch로 해서 어느 patch에 주의를 기울이는지를 그리는 식으로 그렸고 결과는 위와 같이 매우 신기하게 물체들을 잘 분리하는 것을 알 수 있다.
attention map은 마지막 layer에서 각 patch를 고르고 그 patch를 query로 두고 key를 나머지 patch로 해서 어느 patch에 주의를 기울이는지를 그리는 식으로 그렸고 결과는 위와 같이 매우 신기하게 물체들을 잘 분리하는 것을 알 수 있다.
