Abstract
말그대로
Masked Autoencoders are Scalable Vision Learner이다.
patch를 random하게 masking한다. 그리고 masking 된 이미지를 토대로 원본을 재구축하는 task를 학습한다.
이때 2가지의 주요 디자인이 들어간다.
- 비대칭 encoder, decoder 구조
- encoder는 masking된 patch는 버리고 나머지로만 representation을 구축한다. 이후 작은 크기의 decoder이 이를 복원한다.
- 높은 비율의 masking
- masking을 거의 75%의 patch에 적용한다. 이를 통해 작업을 어렵게 만든다.
이 두가지 조합으로 매우 큰 모델을 효과적으로 학습할 수 있었다.
1. Introduction
기존 NLP 분야에서는 데이터의 특정 부분을 지우고 예측하는 masked autoencoding을 활용한 self-supervised pretraining이 사용이 되고 있었다.(BERT나 GPT)
이를 통해 nlp는 수백 billion의 param을 가진 모델을 효과적으로 학습할 수 있게 만들어주었는데(pretrain -> finetune 과정을 통해)
vision 분야도 이런 masked autoencoding을 적용하려는 시도는 있었지만 nlp 만큼의 성능이 나오지 못하였다.
nlp 분야와 vision 분야의 차이점이 무엇일까?
논문의 저자는 다음과 같은 차이점을 생각해보았다.
- 모델의 차이: 최근까지 image분야는 cnn, nlp분야는 transformer가 기반이었다. 그러나 image도 최근 transformer를 사용하기에(ViT) 차이점이 적어졌다.
- cnn은 격자로 이동하며 진행하기에 indicatior(masked token, positional embedding 등)을 network에서 통합하여 처리하기 쉽지 않다.
- 정보의 밀도의 차이: 보통 이미지 1개의 patch는 큰 의미가 없다. 그러나 단어는 1개가 큰 의미를 가진다.
- 그렇기 때문에 몇개의 단어를 지우고 예측하는 문제는 문장 전체를 이해해야 하기 때문에 언어 자체의 이해를 돕는다.
- 그러나 이미지 patch 몇 개를 지우고 예측하는 문제는 별 도움이 안된다. 전체를 이해하지 않고도 주변 patch만을 통해서 이미지를 이해할 수 있기 때문
- 이를 해결하기 위해 다수의(75%) patch를 masking하였다.
- Autoencoder의 decoder가 text와 vision은 다른 역할을 한다.
- vision은 decoder가 pixel단위로 재구성한다. 이때 각 pixel은 적은 정보를 가지고 있기에 cosnition task보다 낮은 sementic level을 가진다. nlp는 각각의 단어가 많은 정보를 담고 있기에 BERT와 같이 빈칸을 맞추는 문제가 매우 간단하다. 그러나 이미지는 다르다.
이러한 분석을 토대로 masked autoencoder 구조를 제시한다.
각 patch를 높은 비율로 masking하고 이를 재구성하는 것이다.
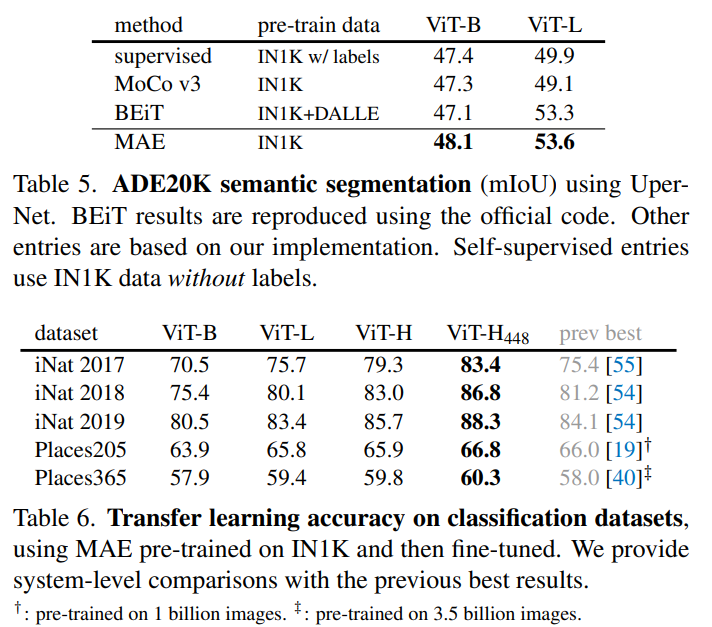
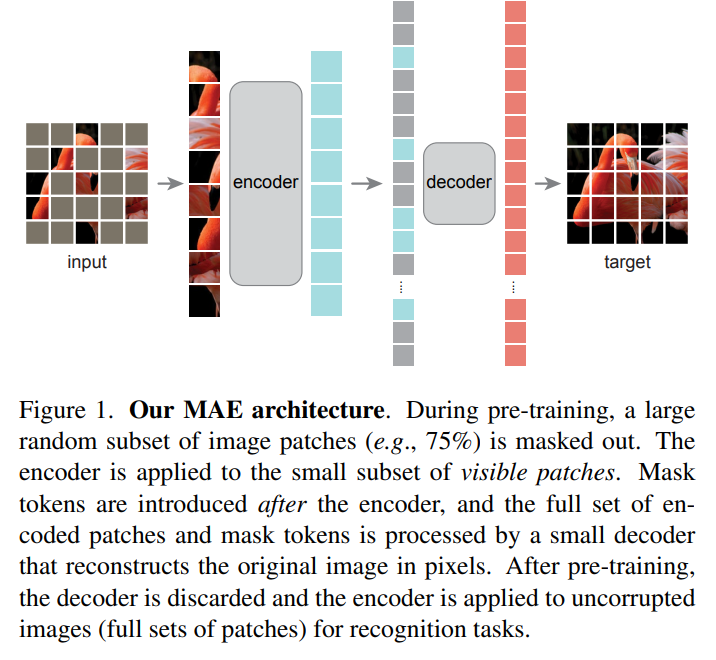 이때 많은 비율을 masking함으로써 computational cost를 줄일 수 있다. 또한 매우 좋은 성능을 보임.
이때 많은 비율을 masking함으로써 computational cost를 줄일 수 있다. 또한 매우 좋은 성능을 보임.
3. Approach
Masking
높은 확률로 patch를 masking한다.
많이 지우지 않으면 근처 patch로 예측하기 너무 쉬워진다.
MAE Encoder
ViT를 사용 이때 visible한 patch만 넣는다.
이 덕분에 적은 비용으로 많은 양의 데이터를 학습 가능.
MAE Decoder
input은 2가지로 구성
1. encoded visible tokens
2. masked tokens
이때 각 masked token은 공유된다. missing vector를 표현하기 위해 학습된 vector가 사용이 됨. 이후 모든 token에 positional embedding을 더해줌
이때 masked token은 위치 그 이상의 정보는 제공하지 않음.
decoder는 transformer block의 또다른 series 이다.
이때 decoder는 pretrain 단계에서만 사용이 되고 그렇기 때문에 decoder design은 encoder와 독립적으로 구성할 수 있다.
이 논문에서는 매우 얕고 작게 디자인해서 encoder의 10%의 computational cost로 학습하였다.
Reconstruction target
decoder는 각 patch에서 input의 pixel을 prediction 하는 방식으로 진행
decoder의 마지막 linear layer의 channel은 input patch의 pixel 값과 동일하다. reshape를 통해 이미지를 만든다.
loss는 이렇게 예측한 이미지와 실제 이미지 사이의 MSE로 구성
이때 BERT와 같이 loss는 오직 making된 patch에 대해서만 구성
또한 target을 normalized pixel로 구성해보기도 하였는데
이때 더 나은 representation을 보여줌.
simple implementation
- input patch에 대해서 token을 만든다.(linear layer + positional embedding)
이후 모든 patch을 list에 넣고 섞고 masking ratio에 따라서 뒷부분을 삭제(75%) - 이후 encoding을 진행하고 masking token을 list에 넣어줌. 이후 unshuffle을 진행
- 이렇게 만든 full list에 positional embedding을 더하고 decoder를 적용
4. ImageNet Experiments
end-to-end fine-tuning과 linear evaluation 진행
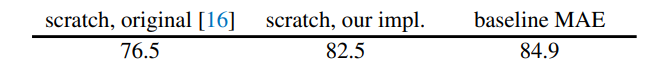 ViT-Large로 학습을 하였는데 논문에서 다양한 regularization 기법을 넣음으로 성능 향상이 있었고 MAE를 넣었을 때 또 성능향상이 존재했다.
ViT-Large로 학습을 하였는데 논문에서 다양한 regularization 기법을 넣음으로 성능 향상이 있었고 MAE를 넣었을 때 또 성능향상이 존재했다.
이때 fine-tuning은 50epoch진행 (scratch는 200 epoch)
4.1. Main Properties
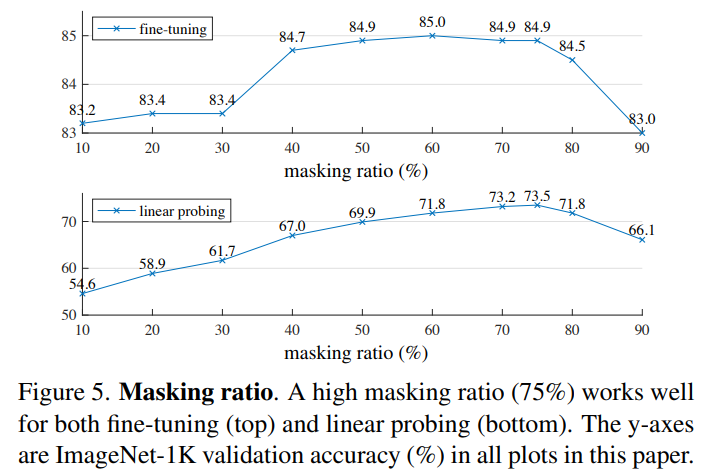 masking하는 비율에 대해서 성능의 차이가 존재하는데
masking하는 비율에 대해서 성능의 차이가 존재하는데
linear probing과 fine-tune에서의 양상이 다르다.
 masking되는 비율이 많을수록 이미지의 원본을 예측하기 힘들기 때문에 task가 어려워지는 것으로 보인다.
masking되는 비율이 많을수록 이미지의 원본을 예측하기 힘들기 때문에 task가 어려워지는 것으로 보인다.
이때 너무 많으면 원본에 대한 정보가 거의 없기 때문에 이상한 이미지가 나오기에 적절한 비율이 중요하다.
Decoder design
 decoder의 block과 dim의 차이에 따른 결과이다.
decoder의 block과 dim의 차이에 따른 결과이다.
linear probing에서는 깊은게 좋은데 이는 pixel reconstruction과 recognition task의 차이로 설명이 가능하다.
깊은 구조는 latent space를 더욱 추상화할 수 있어서 reconstruction에 좋다.
그러나 fine-tune은 recognition task를 위해서 encoder의 last layer가 업데이트 되기 때문에 decoder의 depth와는 큰 영향이 없다.
신기한건 fine-tune시에는 single block만 사용해도 매우 좋은 성능을 보임. 이를 통해 속도 향상을 보일 수 있음.
dim은 512로 두는 것이 fine-tune과 linear prob 모두에서 좋았다.
또한 좁은 dim도 fine-tune에서 좋은 성능을 보임.
논문의 기본 decoder는 8 block에 512-dim으로 light하게 구성
ViT-L(24 block, 1024-dim)의 9%의 computation cost가 소모됨
Mask token
encoder에 mask token을 넣냐 안넣냐 실험
 그림을 보면 넣지 않을 것이 fine-tune과 linear test 모두 좋은 성능을 보임.
그림을 보면 넣지 않을 것이 fine-tune과 linear test 모두 좋은 성능을 보임.
특히 linear에서 매우 큰 차이를 보였는데
이는 pre-training과 deploying의 차이로 보인다.
pre-training에서 encoder의 input에 masked token을 넣게 되면 이는 원본 이미지에 없는 token들이라 대부분의 token이 원본에 없는 구조가 된다.
그러나 deploying에서는 masked token이 들어오지 않기에 이 차이가 정확도 차이를 만든다고 본다.
masked token을 넣지 않으면 deploying과 동일하게 항상 실제 이미지 patch를 보기 때문에 정확도가 보존된다고 본다.
Reconstruction target
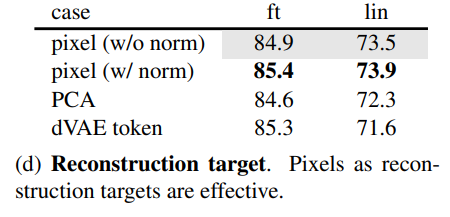 재구성의 목표 pixel이 per-patch normalize 되어있으면 조금 더 좋은 성능을 보임
재구성의 목표 pixel이 per-patch normalize 되어있으면 조금 더 좋은 성능을 보임
아마 재구성 과정에서 더 편하게 재구성할 수 있기 때문으로 보임.
또한 dVAE token과 같이 token의 형식으로 cross-entropy를 예측하는 식으로도 가능한데 이러면 성능이 올라가긴 하지만 linear 평가에서는 성능이 떨어진다.
Data augmentation
 augmentation은 crop만으로도 잘 작동했는데 rand size crop이 제일 성능이 좋았다.
augmentation은 crop만으로도 잘 작동했는데 rand size crop이 제일 성능이 좋았다.
color jitter을 넣으면 오히려 성능이 떨어짐.
특이한건 contrastive learning과는 다르게 none으로도 상당한 성능을 보여주었음.
아마 MAE에서는 random patch selectioin이 view의 기능을 해서 그런 것으로도 보임.
Mask sampling strategy
 단순하게 random이 가장 성능이 잘나옴.
단순하게 random이 가장 성능이 잘나옴.
block과 grid는 아래와 같음. block은 random보다 task가 더 어렵기 때문으로 추측 50%까지는 괜찮은데 75%가 되면 성능저하 발생 재구축한 결과도 blur가 더 많다.
block은 random보다 task가 더 어렵기 때문으로 추측 50%까지는 괜찮은데 75%가 되면 성능저하 발생 재구축한 결과도 blur가 더 많다.
grid는너무 쉽다. train loss가 적음.
Training schedule
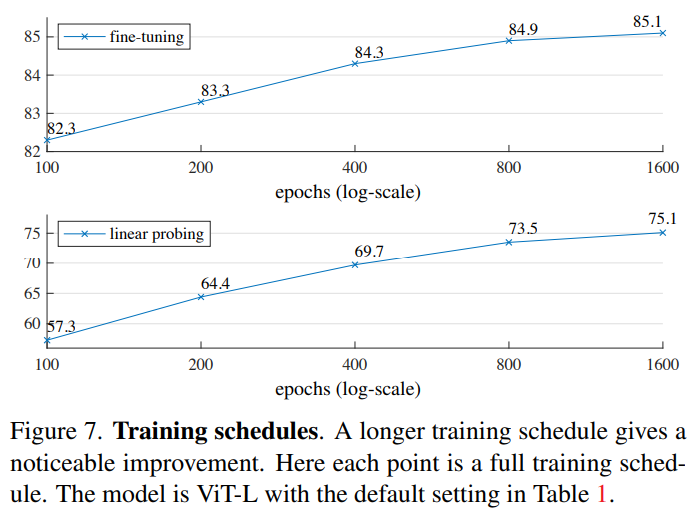 길게 학습할수록 성능이 잘나옴.
길게 학습할수록 성능이 잘나옴.
1600epoch에 가서도 saturation이 발생하지 않음.
MoCo v3의 경우 300 epoch에 가면 saturation이 발생
4.2. Comparisons with Previous Results
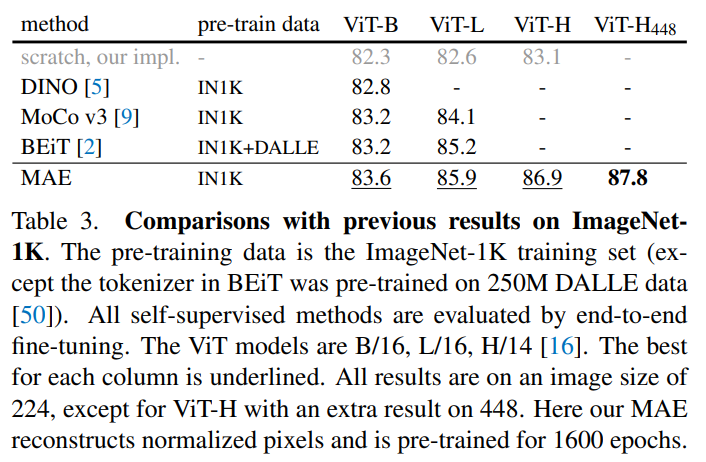 pretrain한 encoder를 end-to-end finetune을 진행해서 평가
pretrain한 encoder를 end-to-end finetune을 진행해서 평가
몯,ㄴ 경우에서 좋은 성적을 보임
4.3. Partial Fine-tuning
위 실험 결과는 fine-tune과 linear를 제외한 나머지 레이어를 얼리거나 얼리지 않거나 2가지 상황으로만 가정을 하였음.
그런데 이렇게 된다면 linear하지 않은 feature을 학습하는 기회를 놓치게 됨.
그렇기 때문에 마지막의 몇개의 layer를 얼리지 않을지 선택해서 학습 진행.
 결과는 위와 같은데 0->1이 제일 차이가 크고 나머지는 점차 수렴하는데 대체적으로 많은 block을 fine-tune시에 좋은성능을 보임.
결과는 위와 같은데 0->1이 제일 차이가 크고 나머지는 점차 수렴하는데 대체적으로 많은 block을 fine-tune시에 좋은성능을 보임.
특이한건 1개의 block을 더 학습할 때 그 block의 절반 즉 MLP 부분만 더 학습해도 성능이 79.1%로 많이 상승하였음.
5. Transfer Learning Experiments
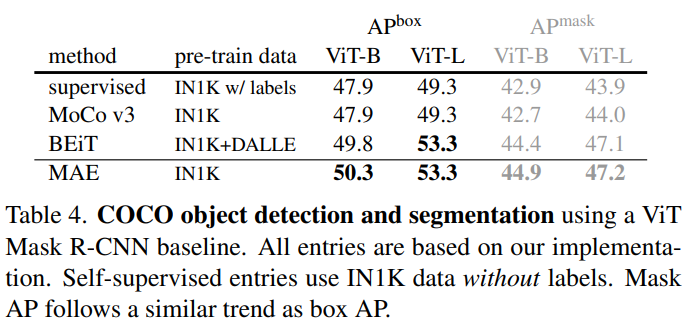
transfer learning 분야도 좋은 성능을 보임.