[논문 리뷰]i-MIX: A DOMAIN-AGNOSTIC STRATEGY FOR CONTRASTIVE REPRESENTATION LEARNING - ICLR 2021
paper
Abstract
contrastive self-supervised learing은 unlabeled data로 좋은 성능을 보였지만 vision 분야는 data augmentation에 의존적이다.
i-mix는 domain-agnostic 한 방법으로 성능을 향상시킨다.
각 데이터 batch에 unique virtual class를 넣는 식으로 non-parametric classifier를 학습한다.
그러면 data와 virtual label space가 섞어서 augmentation을 만든다.
1. Introduction
contrastive representation learning은 domain에 대한 지식이 필요하고 domain별로 inductive bias에 의존한다.
data augmentation을 만들기 힘든 분야가 있기 때문(nlp, tabular)
게다가 최신의 연구는 엄청나게 많은 unlabeled data가 있다고 가정하지만 현실에서는 그렇지 않을 때도 많다.
이때 mixup은 data augmentation으로 supervised learning으로 학습하는 대부분의 분야에서 좋은 성능을 보였는데

이 논문에서는 질문을 한다. mixup은 unsupervised, self-supervised, contrastive learning 분야에서도 learning에서도 다양한 domain에 효과적일 수 있을까?
이를 위해 instance-mix(i-mix)를 제시한다.
domain agnostic regularization strategy for contrastive representation learning
키 아이디어는 batch에 virtual label을 넣고 input data와 label의 space에 virtual label을 섞는 것이다.(mixup)
i-mix는
1. training data size small
2. domain knowledge is small
인 상황에서 잘 작동한다.
3. Approach
이고
loss-function에 모델의 param은 제외되었다.
3.1 MIXUP IN SUPERVISED LEARNING
cross-entropy로 학습할 때 overfitting을 줄이기 위해서 다양한 방법이 제시 되었는데(label-smoothing 등) mixup은 computational overhead 거의 없이 좋은 성능 향상을 가져다 주었다.
mixup은 input data와 label을 linear하게 섞는 것인데 mixup loss는 다음과 같다.
mixup은 task의 generalization을 늘릴 뿐만 아니라 robustness도 증가시켜준다.
3.2 i-MIX IN CONTRASTIVE LEARNING
간단하게 contrastive learning을 설명해야 하는데
만약 batch
가 있을 때 는 anchor이고 는 positive이다.
그리고 는 negative sample이다.
이때 label 으로 설정이 가능한데 이는 positive sample=1이고 나머지(negative sample)는 0을 가르키는 virtual label로 볼 수 있다.
이 각 이미지와 virtual label을 섞어서 학습을 진행한다.
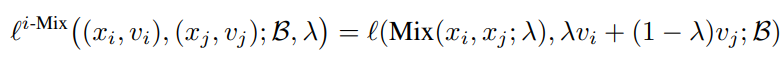
SimCLR
위 내용을 SimCLR에 적용해보자
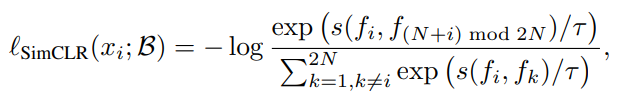
SimCLR의 loss는 위와 같다.
크기 N의 batch에 각 view를 2개 적용해서 positive, negative 총 2N의 크기로 만들고 positive를 분자에 자신 제외 나머지를 분모에 넣어서 학습한다.
여기서 문제점은 virtual label이 없기에 cutmix와 같은 방법으로 섞을 수가 없다.
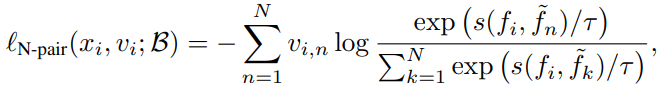
그렇기 때문에 아래와 같이 바꾸는데 이는 anchor와 나머지 view의 sample을 분리해서 N으로 크기를 고정한 것이다.
보면 이제 anchor에 따른 virtual label을 가질 수 있기에 i-mix를 적용할 수 있다. 코드로 보면 이해가 쉬운데 위와 같다.
코드로 보면 이해가 쉬운데 위와 같다.
각 view를 batch에 통과시켜서 a와 b를 만든다.
이때 b는 건드리지 않고 a를 이제 i-mix를 이용해서 섞는데
randperm은 random permutation이다.
random permutation을 통해 a를 a의 다른 이미지와 섞고 그 label도 lambda 비율로 섞어준다.
이후 loss는 lambda*기존의 loss + (1-lambda)*mixup loss 로 구성한다.
a를 섞었기 때문에 b를 곱한 값의 loss도 일정 부분 섞어서 진행한다.
즉 다음 그림과 같다.
MoCo
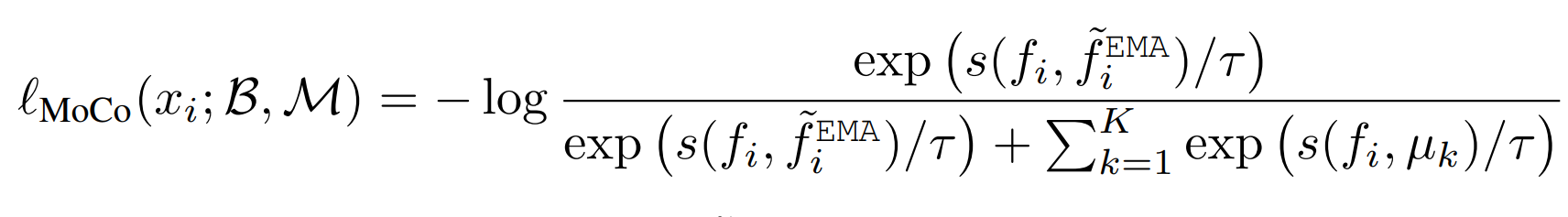 MoCo에도 적용이 가능한데 원래 MoCo의 수식은 위와 같다.
MoCo에도 적용이 가능한데 원래 MoCo의 수식은 위와 같다.
momentum queue가 K개의 sample을 가지고 있는 것이다.
이를 바꿔서
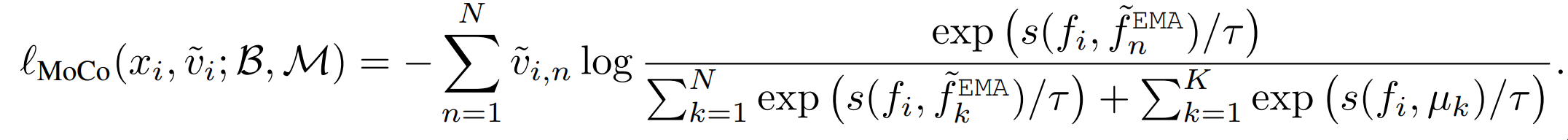 이렇게 각 현재 batch에 대한 다른 anchor을 negative pair에 전부 넣고 positive-negative pair의 식으로 바꾸면 이제 virtual label 을 넣을 수 있고 mix-up이 가능해진다.
이렇게 각 현재 batch에 대한 다른 anchor을 negative pair에 전부 넣고 positive-negative pair의 식으로 바꾸면 이제 virtual label 을 넣을 수 있고 mix-up이 가능해진다.
즉 원래는 queue에 batch의 sample을 다 비교한 이후에 넣었다면 batch의 virtual label을 만들기 위해서 이제는 batch sample을 queue에 다 넣고 진행하는 것과 비슷하다.
이때 로 구성이 된다.
BYOL
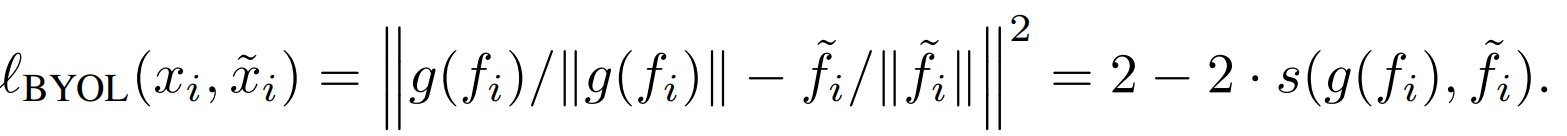 이렇게 구성된 loss에
이렇게 구성된 loss에
아래와 같이 오른쪽 view를 수정해서 각 positive sample에 따른 으로 구성이 가능하다.
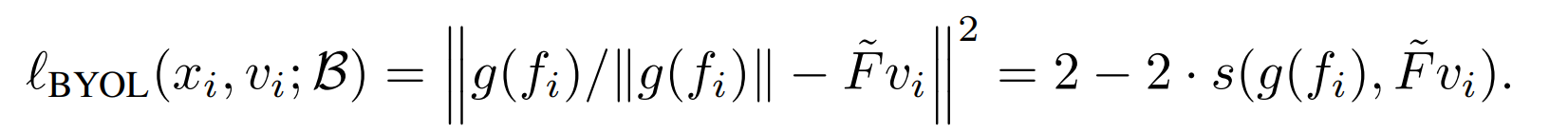 이때 으로 l2 norm vector의 집합으로 구성이 가능하다.
이때 으로 l2 norm vector의 집합으로 구성이 가능하다.
3.3 InputMIX
data augmentation을 적용하기에 domain knowledge가 부족한 경우 InputMix를 i-Mix와 함께 적용하는 것을 제시한다.
InputMix는 label은 섞지 않고 input의 data만 섞는 것이다.
4. Experiments
i-Mix의 성능을 실험
contrastive representation learning으로 진행 5번의 학습 평균 값으로 산출
1차로 contrastive learning을 진행하고 projection head를 classifier로 바꿔서 fine-tune
따로 말이 없으면 를 따른다
기존 학습보다 i-Mix를 사용하였을 때 성능 향상이 존재하였음.
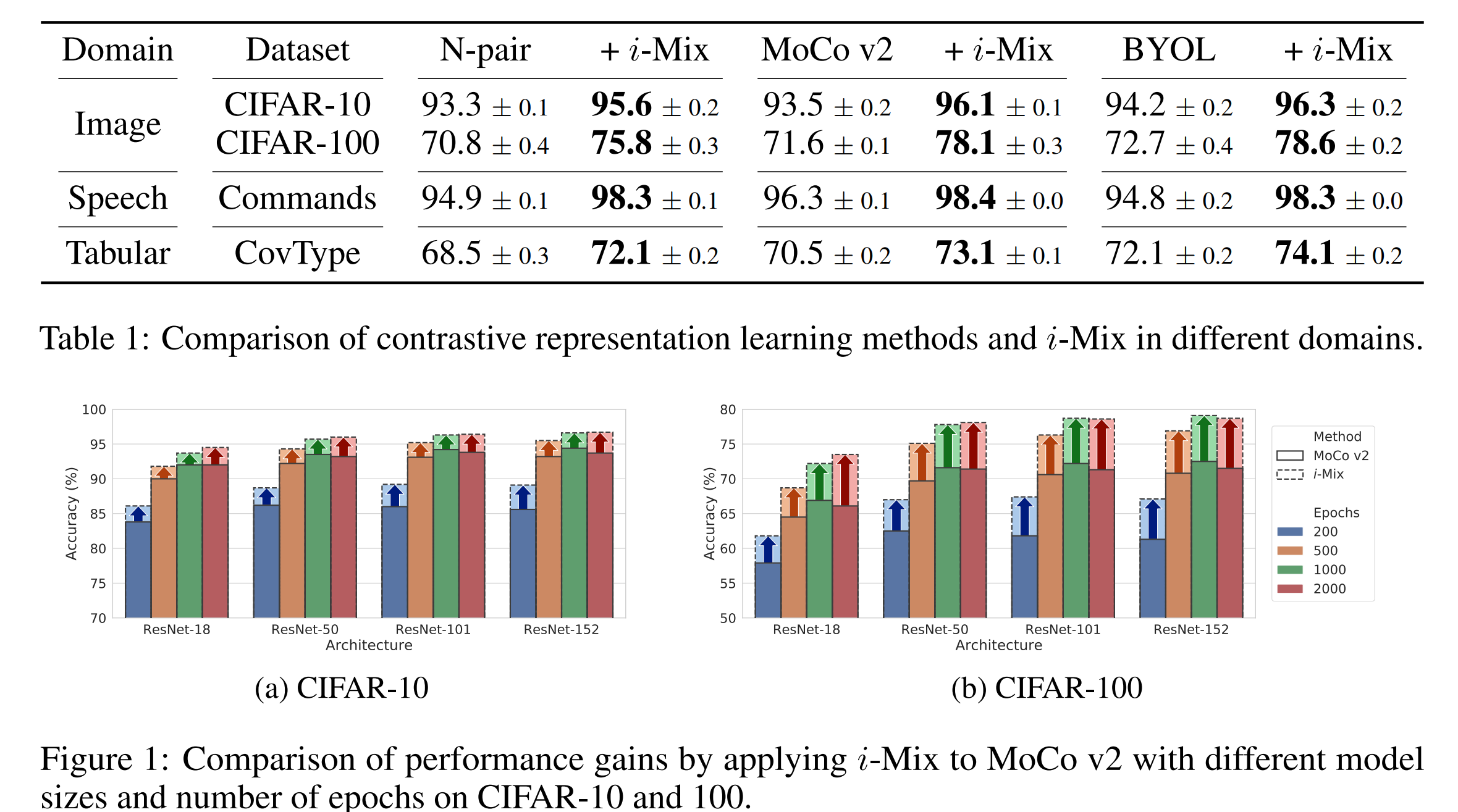
이때 tabular data는 domain knowledge가 부족해서 augmentation에 probability 0.2의 masking을 사용
4.2 main results
MoCo의 경우 6.5%의 상승이 있을 정도로 많은 상승을 보임.
그런데 신기했던 부분은 representation learning을 하고 linear classifier를 올리는데 이 pretrain한 표현 부분을 downstream task에 fine-tune을 하지 않고도 처음부터 끝까지 supervised learn을 진행한 모델과 비슷하고 심지어 더 좋은 성능을 보일 때가 있음.
4.3 REGULARIZATION EFFECT OF i-MIX
regularization의 기능은 더 깊고 긴 epoch의 학습에서도 더 좋은 성능을 이끌어 낼 때가 존재함.
위 figure 1 이미지를 보면 MoCo v2를 학습할 때 더 깊고 긴 epoch의 학습에서도 더 좋은 성능을 이끌어내는 모습을 보여줌.
이후 데이터 size에 따른 영향을 테스트 하였는데
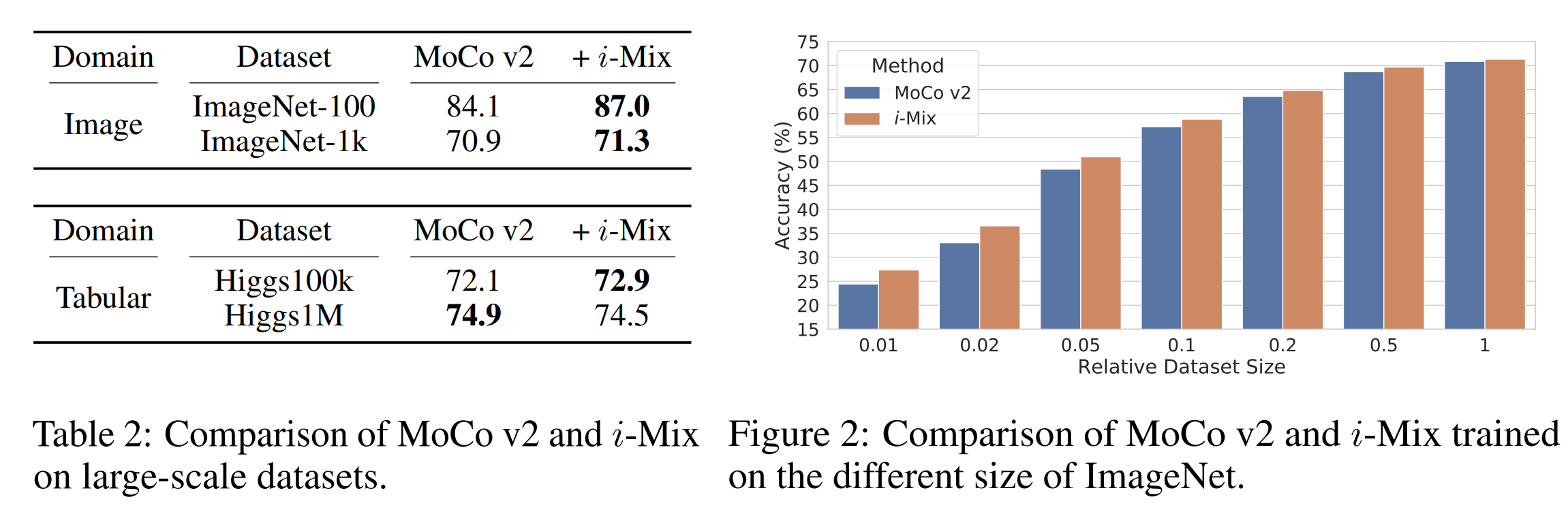 위 결과와 같이 dataset의 size가 더 적은 상황에서도 더 좋은 성능을 보여줌.
위 결과와 같이 dataset의 size가 더 적은 상황에서도 더 좋은 성능을 보여줌.
오른쪽 그림을 보면 특히 데이터의 크기가 적으면 적을수록 더 좋은 성능을 만든다는 것을 알 수 있음.
4.4 CONTRASTIVE LEARNING WITHOUT DOMAIN-SPECIFIC DATA AUGMENTATION
사실 이 부분이 논문을 읽은 이유인데 domain knowledge가 없어서 적절한 data augmentation이 없는 상황에서 학습을 하는 경우 어떻게 될까에 대한 이야기이다.
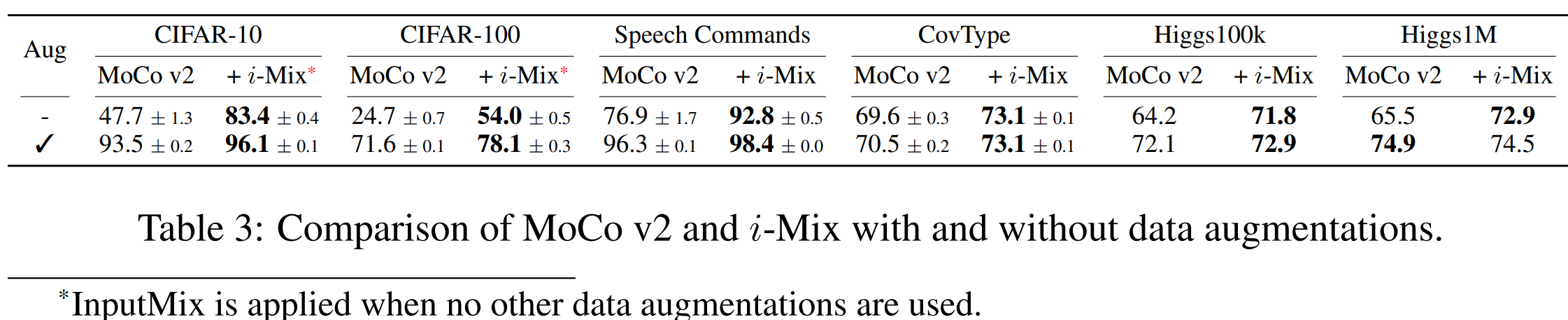 이때 이미지의 경우 inputMix가 진행이 되었는데 매우 큰 성능의 보존이 가능하였다.
이때 이미지의 경우 inputMix가 진행이 되었는데 매우 큰 성능의 보존이 가능하였다.
inputMix는 0.5, 0.5로 섞었다고 한다.
InputMix가 domain knowledge가 없는 상황에서 performance의 증가에 영향을 끼친다는 것을 알 수 있다.
InputMix가 없으면 cifar10의 경우 75.1%였고 cifar100의 경우 50.7%라고 한다. i-mix 자체만으로도 성능의 보존의 효과가 크다.
의문이 augmentation이 주어지지 않으면 contrastive learning을 어떻게 진행한거지? 그냥 쌩으로 같은 이미지 2개 넣어서 진행한건가?
4.5 TRANSFERABILITY OF i-MIX
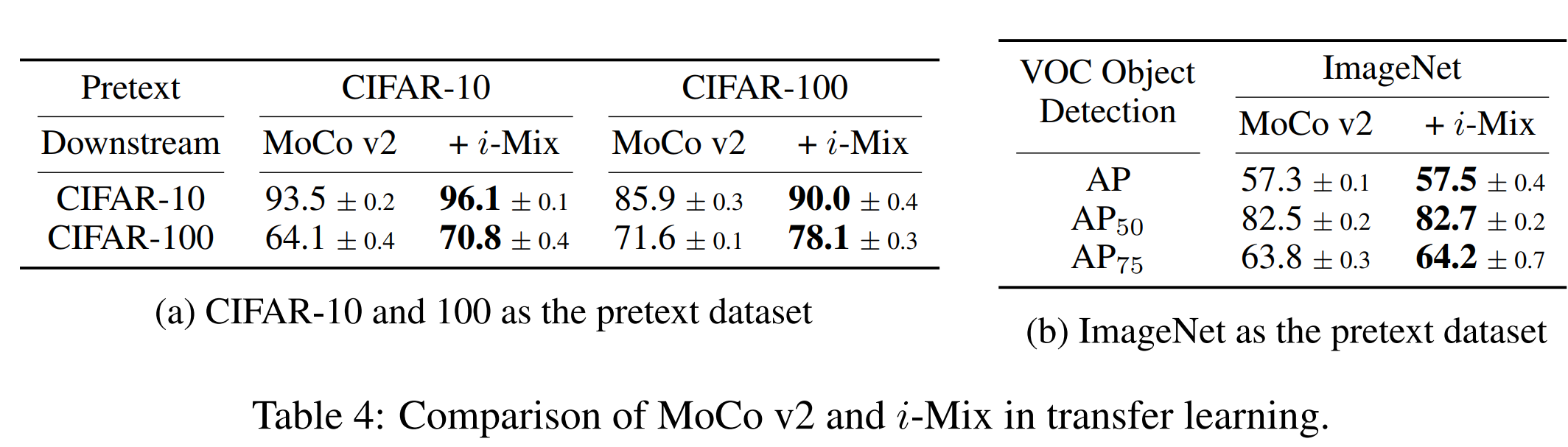 transfer learning을 하는 경우에도 i-mix를 추가하면 효과가 좋았다.
transfer learning을 하는 경우에도 i-mix를 추가하면 효과가 좋았다.
