Abstract
이 논문에서는 고차원의 환경 input에서 control policy를 성공적으로 학습한 방법을 제시함
모델은 CNN으로 구축되었고 Q-learning으로 학습됨.
input은 raw-pixel이고 output은 미래의 value 예측값
1. Introduction
이전의 고차원 환경에서 잘 작동하는 control policy는 손으로 직접 추출한 feature와 linear value function 또는 policy representation의 조합에 의존하였다.
결국 이러한 방법은 좋은 feature 추출에 의존한다.
딥러닝은 feature 추출을 자동으로 해주기 때문에 이러한 특성을 강화학습에 이용할 수 있을 것 같다.
하지만 몇가지 제한사항이 존재하는데
1. 기존의 딥러닝은 많은 양의 hand-labeled data가 필요. 그러나 강화학습 알고리즘은 noise가 많고 sparse하며 delayed( ~ 수천 step) 된 scala reward를 받음.
2. 대부분 딥러닝의 알고리즘은 데이터가 independent하다고 가정함.
그러나 강화학습은 sequence의 state들은 높은 관계를 가짐.
3. 학습이 진행하며 새로운 action을 시도해보는 등으로 data의 distribution이 바뀜.
이 논문은 CNN이 위의 제한사항을 극복하고 raw video로부터 좋은 성능을 낼 수 있음을 보여줌.
알고리즘은 Q-lenarning으로 진행이 되었으며 sgd로 weight가 업데이트 된다.
experience replay mechanism
위 문제의 2. correlation과 3. non-stationary distribution을 극복하기 위해서
experience replay mechanism을 사용하였다.
이는 이전의 transition (s,a,r,s')을 많이 저장하고 있음.
이를 랜덤으로 추출해서 correlation을 줄였고 분포를 안정화 시킴.
이 방법을 통해 아타리 게임을 학습했는데
사람처럼 video의 view와 가능한 action, reward signal 만 보고 매우 잘 학습을 하였다.
2. Background
게임은 MDP에 따른 강화학습을 적용할 수 있음
- reward가 주어짐
- 종료가 있음
- state - action의 sequence()를 학습 가능
input은 게임의 화면을 받는다.
agent의 목적은 게임의 화면을 받아서 추후 reward를 최대화할 수 있는 action을 하는 것이다.
즉 지금부터 끝까지의 로 감쇄된 reward의 합을 최대화
이를 위해 optimal action-value function을 정의하는데
를 토대로 가장 reward를 많이 주는 action을 고른다.
s,a의 상황의 값은 다음 state 에서 가장 value를 많이 가지는 action 를 고르는 것이다.
이 아이디어를 통해서 업데이트를 진행하는데
를 반복해서 업데이트를 해서 에 근사한다.
그러나 를 얻는 것은 매우 많은 노력이 필요하다.
왜냐하면 각 sequence가 매우 불규칙적이기도 하고 space가 너무 크면 고려해야할 state가 너무 많기 때문이다.
그렇기 때문에 avtion-value function으로 근사해서 사용한다.
보통 linear function approximator를 사용하지만 이 논문에서는 deep-learning model을 이용한 non-linear function approximator을 이용하였다.
수식과 같이 이전의 로 다음의 을 근사하는 것을 이용해서
이를 target에 넣고 MSE loss 함수에 넣어서 학습을 하였다.
gradient 수식은 다음과 같다.
이를 이용해서 SGD를 진행한다.
4. Deep Reinforcement Learning
experience replay를 사용하였는데
을 으로 담고있는 queue 형태의 자료구조이다.
여기에서 sample을 batch로 꺼내서 학습한다.
explore시 action은 -greedy로 선택한다.

여기에서 는 history 데이터의 state를 압축하는 역할을 한다.
(회색으로 만들어서 rgb -> 1차원으로 만들고 화면 size를 줄이고 등)
이러한 방식은 online Q-learning에 비해서 다음과 같은 이점을 준다.
1. 과거의 experience를 재활용해서 많은 weight를 업데이트할 수 있다. 즉 데이터 효율적이다.
2. 데이터의 correlation을 줄여서 update의 variance를 줄여 딥러닝 학습을 더 편하게 만든다.
3. on-policy로 학습할 때는 현재의 param이 매개변수가 학습할 다음 데이터 샘플을 결정한다.
만약 왼쪽으로 가는 것이 최고의 action이면 param이 왼쪽으로 가도록 만들 것이다. 만약 이게 noise를 통해 오른쪽으로 바뀌게 된다면 데이터의 분포가 즉시 오른쪽으로 바뀔 것이다.
이는 불필요한 loop를 만들게 되거나 local-minimum에 빠지게 만드는데 replay queue를 사용하면 과거의 분포가 평균화가 되어서 한번 튀는 noise가 생겨도 강건하게 학습이 된다.
이때 experience replay를 사용하게 된다면 당연하 off-policy를 사용해야 한다.
현재의 정책과 과거의 정책이 다르기 때문.
4.1 Preprocessing and Model Architecture
위에서 말했던 preprocessing 과정이다.
기본 atari iamge가 에 각 128개의 색을 가지기 때문에 너무 값이 크다.
이를 해결하기 위해 RGB를 회색으로 바꿨으며 로 다운샘플링을 진행하였다.
이후 플레이하는 영역만 잘라서 의 이미지로 최종 구성하였다.
이 논문에서 실험을 위해서 사용한 알고리즘 는 마지막 4개의 frame을 합쳐서 위와 같이 만들고 이를 반환하는 방식이다.
(4,84,84)
또한 모델에 로 구성해서 각각 action에 따른 value를 계산하는 것보다.
로 구성해서 한번에 모든 action의 value를 계산해서 빠르게 max action value를 계산할 수 있도록 구성하였다.
5. Experiments
여러개의 게임을 테스트하다 보니까 모든 증가하는 score는 +1이고 감소하는 score는 -1로 안바뀌면 0으로 reward를 구성하였다.
-greedy는 [1.0~0.1]로 첫 100만개의 frame을 구성을 하였고 나머지는 0.1 고정으로 진행하였다.
그리고 agent는 frame skipping을 통해 보고 action을 고르는 과정이 번째 frame만 보고 진행이 된다. 보통 로 진행하였다. 그리고 그 사이의 frame은 이전의 action을 선택
space invader는 으로 진행하였다. 면 레이저가 반짝이는 프레임 간격과 겹쳐서 안보였다고 한다.
5.1 Training and Stability
 학습을 하며 평균 점수가 점진적으로 오르는 것을 알 수 있다.
학습을 하며 평균 점수가 점진적으로 오르는 것을 알 수 있다.
5.2 Visualizing the Value Function
 오른쪽 그림 A, B, C의 각각 value
오른쪽 그림 A, B, C의 각각 value
5.3 Main Evaluation
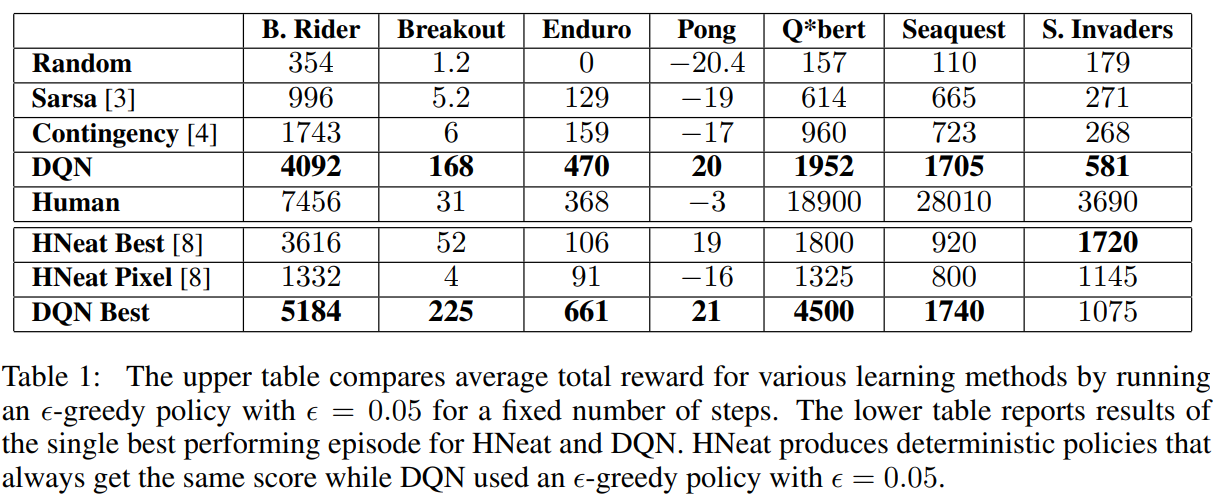 다른 방법들과 비교한 점수
다른 방법들과 비교한 점수
특정 부분에서 사람(2시간 정도 플레이한 사람의 중간값)을 넘는 것을 보여줌.
구현
class DQN(nn.Module):
def __init__(self, data_len, device):
super().__init__()
self.fc1 = nn.Linear(4, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, 2)
self.data = deque(maxlen=data_len)
self.gamma = 0.99
self.device = device
self.optimizer = optim.Adam(self.parameters(), lr=0.001)
self.buffer = ReplayBuffer(data_len, device)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def action(self, state, epsilon):
if random.random() < epsilon:
return random.randint(0, 1)
else:
state = state.to(self.device)
with torch.no_grad():
return torch.argmax(self.forward(state)).item()
def input_data(self, transition):
# data는 (state, action, reward, next_state, done)으로 이루어진다.
self.buffer.push(transition)
def train(self, batch_size, target_net):
if len(self.buffer) < batch_size:
return
batch_state, batch_action, batch_reward, batch_next_state, batch_done = self.buffer.sample(
batch_size)
q = self.forward(batch_state)
q = q.gather(1, batch_action)
max_q = target_net.forward(batch_next_state).detach().max(1)[0].view(-1, 1)
target = batch_reward + (1 - batch_done) * self.gamma * max_q
loss = F.mse_loss(q, target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss.item()
def main():
args = parse_args()
random.seed(args.seed)
torch.manual_seed(args.seed)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print("using device: ", device)
logger = Logger(args.logdir)
logger.log(0, is_tensor_board=False, **vars(args))
env = gym.make('CartPole-v1')
agent = DQN(50000, device).to(device)
score = 0
target_update = 10
target = copy.deepcopy(agent)
for i_episode in range(args.total_episode):
if i_episode % target_update == 0:
target = copy.deepcopy(agent)
observation = env.reset()
done = False
while not done:
# env.render()
epsilon = max(0.05, 0.25 - 0.01 * i_episode / 100)
action = agent.action(torch.tensor(observation), epsilon)
next_observation, reward, done, info = env.step(action)
done = 1 if done else 0
agent.input_data((observation, action, reward, next_observation, done))
observation = next_observation
score += reward
if len(agent.buffer) > 2000:
agent.train(args.batch_size, target)
if done == 1:
break
if i_episode % args.logging_step == 0:
logger.log(i_episode, score=score / args.logging_step, epsilon=epsilon)
score = 0
env.close()
print('save_model to ', args.output)
torch.save(agent, args.output)
