[논문 리뷰]d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning
paper
이 논문도 자세히 적지는 않고 핵심만 작성하도록 하겠다.
Abstract
간단하게 최근 deepseek R1처럼 LLM에 강화학습을 진행하는 framework가 활발하게 진행이 되지만 Discrete diffusion 즉,dLLM에서는 강화학습이 연구되지 않기에 강화학습 방법론을 제시한다.
Introduction
 실제 R1처럼 SFT + 강화학습으로 위와 같은 reasoning task의 성능을 올렸다고 한다.
실제 R1처럼 SFT + 강화학습으로 위와 같은 reasoning task의 성능을 올렸다고 한다.
3 d1: Adapting Pre-trained Masked dLLMs to Reasoning Models
기존 deepseek R1에서 사용된 GRPO의 수식을 보면 다음 수식과 같이 진행이 되는데
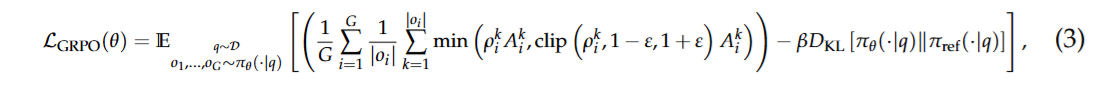 이를 dLLM에 적용할 때의 문제는 dLLM은 여러 step에 나눠서 순서가 없이 generation이 이루어지기에
이를 dLLM에 적용할 때의 문제는 dLLM은 여러 step에 나눠서 순서가 없이 generation이 이루어지기에
- 각 token별 prob(for PPO part)
- 문장 전체의 prob(for KL)
위 2가지 분야의 확률을 측정하기 힘들어진다.
이 논문은 simple하게 해결을 하였는데
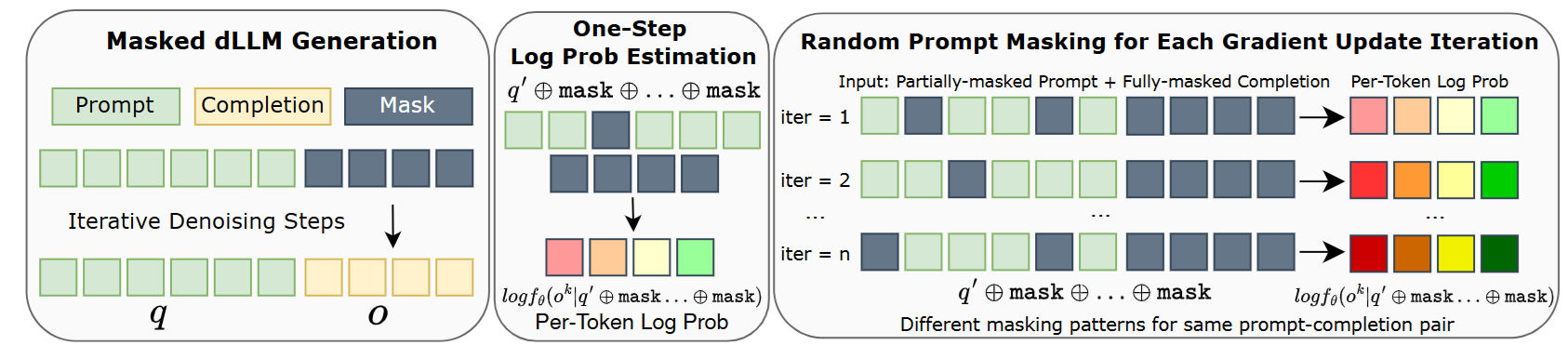
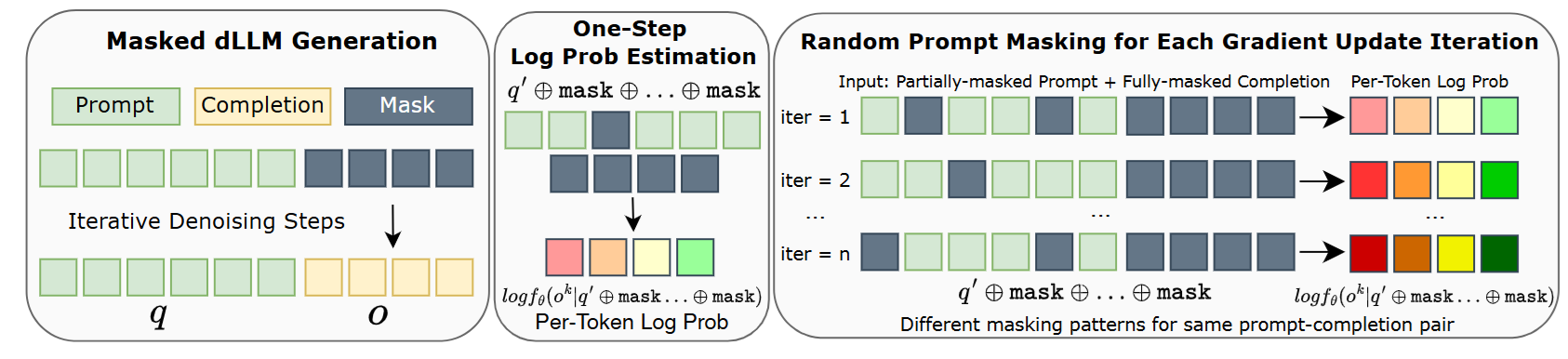 위 그림을 보고
위 그림을 보고
다음 수식을 보자
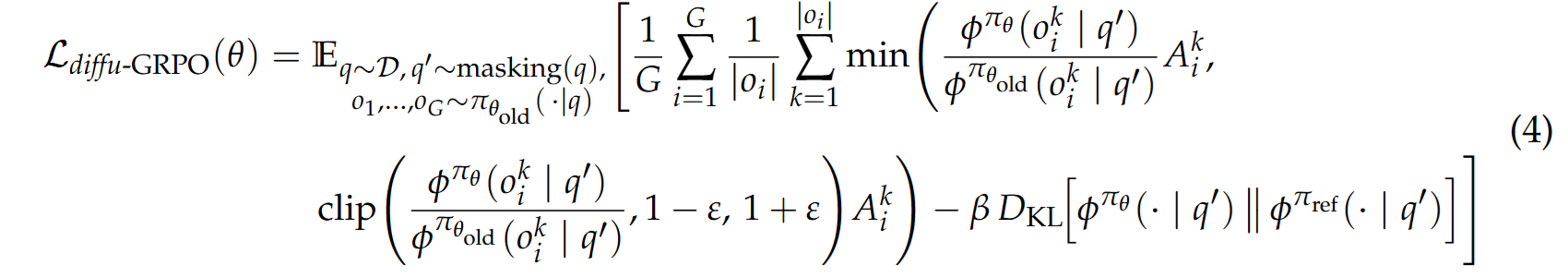
쉽게 설명하겠다.
1. 우선 주어진 prompt를 토대로 전체 답을 생성한다.(그림의 왼쪽 부분)
2. 이제 prompt에서 특정 부분을 partial masking을 진행하고 answer 부분의 log-prob를 앞에서 생성한 답의 확률로 측정한다.
3. 이렇게 각각 token별로 만든 log-prob를 활용해서 PPO part를 진행하고 전체 prob를 활용해 KL part에 사용한다.
이때 prompt를 partial masking하는 것은 data augmentation 효과가 있어서 기존 GRPO에서는 1개의 batch에서 2번 학습 진행하였는데 여러번 진행해도 괜찮은 효과를 준다고 한다.
결과
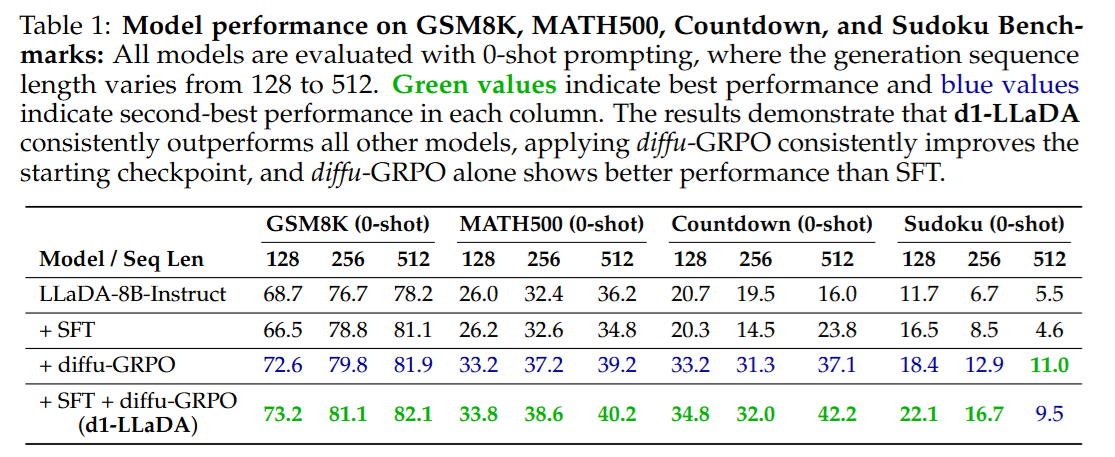
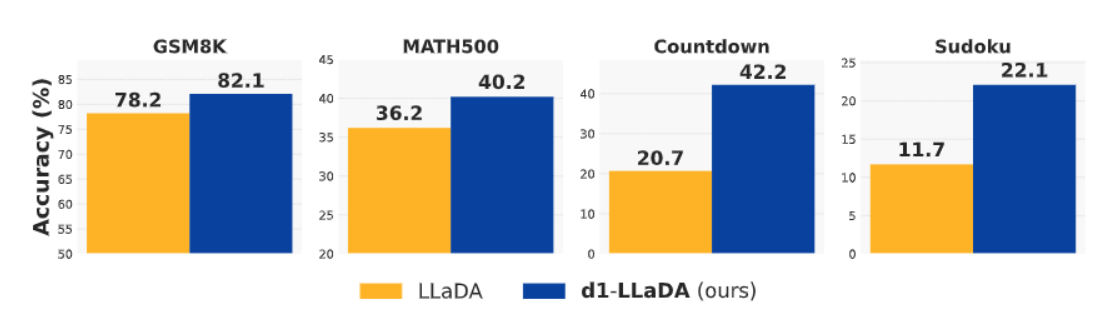
강화학습을 하니 이전 R1과 같이 성능이 상승한다.
추가로 R1의 "aha moment" 그러니까 답이 틀렸다고 판단하고 다른 방법을 시도하는 것도 나왔다고 하는데... 사실 이 부분은 SFT에 backtracking 등의 데이터가 이미 들어가있어서 나온게 맞는 것 같다.
실제 결과
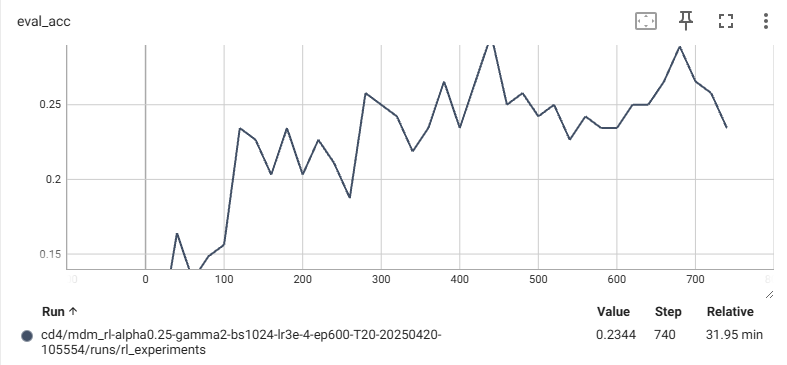
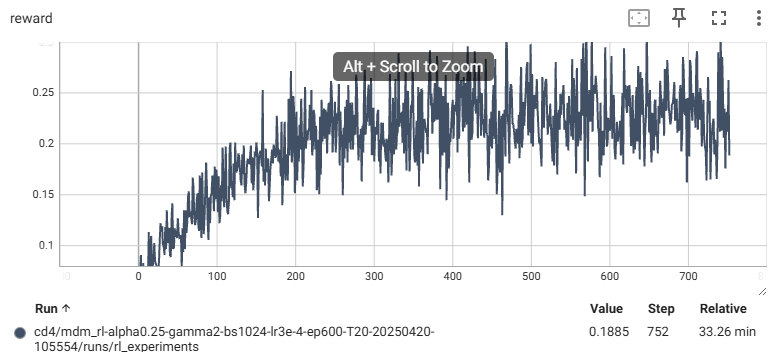
코드를 작성해서 실제로 countdown을 학습해보니 reward와 acc가 증가한다.
